【代码精读】开山之作MVSNet PyTorch版本超详细分析
MVSNet PyTorch实现版本(非官方)
GitHub - xy-guo/MVSNet_pytorch: PyTorch Implementation of MVSNet
总体结构
对于训练核心的代码有如下几个:
-
train.py: 整体深度学习框架(参数处理、dataset和DataLoader构建、epoch batch训练、计算loss梯度下降、读取/保存模型等) -
modelsmodule.py: mvsnet所需的网络基础架构和方法(网络组成模块、投影变换homo_wraping、深度回归depth_regression)mvsnet.py: MVSNet整体Pipeline(特征提取 深度回归 残差优化网络定义、mvsnet_loss定义、核心四大步骤: 特征提取,cost volume构建、代价体正则化、深度图refine)
-
datasetsdata_yao.py: 定义MVSDataset(ref图和src图,投影矩阵,深度图真值,深度假设列表,mask)
-
utils.py: 一些小工具(logger、不同度量指标、系列wrapper方法)
项目整体文件结构
checkpoints(自己创建): 保存训练好的模型和tensorboard数据可视化所需的数据outputs(自己创建): test的时候输出的预测深度图和点云融合后的点云文件等lists: train, valid, test用的scan选择列表evaluations: dtu数据集官方提供的matlab代码,主要用于测试重建点云的质量
DTU数据集结构
共128个scan
- train: 79个
- val: 18个
- test: 22个
Train
【Cameras】
-
pair.txt: 只有一个,每个scan通用的- 每个场景49个view的配对方式
49 # 场景的总视点数 0 # ref视点 src视点总数 第十个视点 视点选取时匹配的score 第一个视点 10 10 2346.41 1 2036.53 9 1243.89 12 1052.87 11 1000.84 13 703.583 2 604.456 8 439.759 14 327.419 27 249.278 1 10 9 2850.87 10 2583.94 2 2105.59 0 2052.84 8 1868.24 13 1184.23 14 1017.51 12 961.966 7 670.208 15 657.218 2 10 8 2501.24 1 2106.88 7 1856.5 9 1782.34 3 1141.77 15 1061.76 14 815.457 16 762.153 6 709.789 10 699.921 -
train/xxxxx_cam.txt:49个 ,每个视点有一个相机参数,不同scan是一致的(与Camera根目录下的camera参数文件不一样,代码里用的是train这个)- 相机外参、相机内参、最小深度、深度假设间隔(之后还要乘以interval_scale才送去用)
【Depths】
深度图 & 深度图可视化
- 共128个scan
depth_map_00xx.pfm: 每个scan文件夹里49个视角的深度图 (深度以mm为单位)- ****
depth_visual_00xx.png: 还有49张深度图的png版本被用作mask(二值图,值为1的像素是深度可靠点,后续训练时只计算这些点的loss)
【Rectified】
原图
- 共128个scan
- 每个scan文件夹里里共49个视角*7种光照 = 343张图片
- 命名:
rect_[view]_[light]_r5000.png - 图片尺寸:640*512
Test
共有22个基准测试场景,对于每一个scan文件夹
pair.txt: 49个场景的配对信息,与train/Cameras/pair.txt是一样的,只是在每个scan里都复制了一份images/: 该场景下49张不同视角的原始图片cams/: 每个视点下的相机参数文件(❓不知道为什么有64个)
具体模块
代码中的数据维度
B: batch size 在研究数据维度时可以直接将这维去掉C: 图像特征维度 最开始是3-channels,后来通过特征提取网络变成32维Ndepth: 深度假设维度,这里是192个不同的深度假设H: 图像高度,原始是640,经过特征提取网络下采样了四倍,变成160W: 图像宽度,同上,512 -> 128
注:在后文维度中最后的H和W可能相反,只为了简单理解并不代表实际运行
dtu_yao/MVSDataset
-
MVSDataset(datapath, listfile, mode, nviews, ndepths=192, interval_scale=1.06)datapath: 数据集路径listfile: 数据列表(用哪些scan训练和测试都是提前定好的)mode: train or testnviews: 多视点总数(实现中取3=1ref+2src)ndepths: 深度假设数(默认假设192种不同的深度)interval_scale: 深度间隔缩放因子(数据集文件中定义了深度采样间隔是2.5,再把这个值乘以缩放因子,最终每隔2.5*1.06取一个不同的深度假设)
-
build_list(): 构建训练样本条目,最终的meta数组中共用27097条数据,每个元素如下:# scan light_idx ref_view src_view # 场景 光照(0~6) 中心视点(估计它的深度) 参考视点 ('scan2', 0, 0, [10, 1, 9, 12, 11, 13, 2, 8, 14, 27])read_img(): 将图像归一化到0~1(神经网络训练常用技巧,激活函数的取值范围大都是0~1,便于高效计算)- 79个不同的scan
- 7种不同的光照
- 每个scan有49个不同的中心视点
-
read_cam_file(): 相机外参、相机内参、最小深度(都为425)、深度假设间隔(都为2.5) -
getitem(): 取一组用来训练的数据-
imgs: 1ref + 2src(都归一化到0-1) (3, 3, 512, 640) 3个3channel的512*640大小的图片 -
proj_metrices: 3个4*4投影矩阵 [ R 3 , 3 t 3 , 1 0 1 ] \begin{bmatrix} R_{3,3} \ t_{3,1} \\ 0 \ 1 \end{bmatrix} [R3,3 t3,10 1] (3, 4, 4)- 这里是一个视点就有一个投影矩阵,因为MVSNet中所有的投影矩阵都是相对于一个基准视点的投影关系,所以如果想建立两个视点的关系,他们两个都有投影矩阵,可以大致理解为 B = P B − 1 P A A B = P_B^{-1}P_AA B=PB−1PAA
- 投影矩阵按理说应该是33的,这里在最后一行补了[0, 0, 0, 1]为了后续方便计算,所以这里投影矩阵维度是44
-
depth: ref的深度图 (128, 160) -
depth_values: ref将来要假设的所有深度值 (从425开始每隔2.5取一个数,一共取192个)- 2.5还要乘以深度间隔缩放因子
-
mask: ref深度图的mask(0-1二值图),用来选取真值可靠的点 (128, 160)
-
dtu_yao_eval.py/MVSDataset
-
参数与训练时完全一致
-
build_list: 构建视点匹配列表,最终meta长度为1078,每个元素如下,与train相比没有光照变化('scan1', 0, [10, 1, 9, 12, 11, 13, 2, 8, 14, 27]) -
read_cam_file(): 内参除4,最终生成的深度图也下采样4倍 -
read_img(): 裁掉下方的16个像素,图像尺寸变为1184*1600,裁剪后不需要修改内存 -
getitem():imgs: (5, 3, 1184, 1600) 测试的时候有5张图像,读的时候每张被裁剪掉了下面16像素proj_metrics: 5个投影矩阵,注意内参除了4倍depth_values: 深度假设范围,仍然是从425开始每隔2.5取一个数,一共192个filename: ref所在的文件夹名,如scan1/
train.py
-
构建训练参数
lrepochs: 训练中采用了动态调整学习率的策略,在第10,12,14轮训练的时候,让learning_rate除以2变为更小的学习率wd: weight decay策略,作为Adam优化器超参数,实现中并未使用numdepth: 深度假设数量,一共假设这么多种不同的深度,在里面找某个像素的最优深度interval_scale: 深度假设间隔缩放因子,每隔interval假设一个新的深度,这个interval要乘以这个scaleloadckpt,logdir,resume: 主要用来控制从上次学习中恢复继续训练的参数summary_freq: 输出到tensorboard中的信息频率save_freq: 保存模型频率,默认是训练一整个epoch保存一次模型
################################ args ################################ mode trainmodel mvsnet dataset dtu_yao trainpath /Data/MVS/train/dtu/ testpath /Data/MVS/train/dtu/ trainlist lists/dtu/train.txt testlist lists/dtu/test.txt epochs 16 lr 0.001 lrepochs 10,12,14:2 wd 0.0 batch_size 1 numdepth 192 interval_scale 1.06 loadckpt None logdir ./checkpoints/d192 resume False summary_freq 20 save_freq 1 seed 1 ######################################################################## -
构建
SummaryWriter(使用tensorboardx进行可视化) -
构建
MVSDataset和DatasetLoader -
构建MVSNet
model,mvsnet_loss,optimizer -
如果之前有训练模型,从上次末尾或指定的模型继续训练
-
train()-
设置milestone动态调整学习率
-
对于每个epoch开始训练
-
对于每个batch数据进行训练
- 计算当前总体step:
global_step = len(TrainImgLoader) * epoch_idx + batch_idx - train_sample()
- 输出训练中的信息(loss和图像信息)
- 计算当前总体step:
-
每个epoch训练完保存模型
-
每轮模型训练完进行测试(这里的测试应该理解为validation,因为用到了7种不同的光照,真正测试是eval,那时候只有一种光照)
DictAverageMeter()主要存储loss那些信息,方便计算均值输出到fulltest- test_sample()
-
-
train_sample()
def train_sample(sample, detailed_summary=False):
"""训练DataLoader中取出的一次数据
Args:
sample ([imgs, proj_matrices, depth, depth_values, mask]): 1ref图+2src图,3个投影矩阵,深度图真值,深度假设列表,mask
Returns:
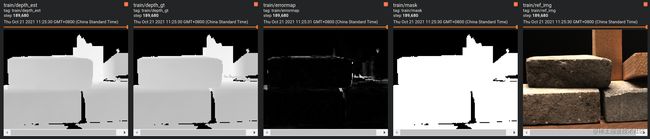
[loss, scalar_outputs, image_outputs]:
scalar_outputs: loss, abs_depth_error, thresXmm_error
image_outputs: depth_est, depth_gt, ref_img, mask, errormap
"""
model.train() # 切换到train模式
optimizer.zero_grad() # 优化器梯度清零开始新一次的训练
sample_cuda = tocuda(sample) # 将所有Tensor类型的变量放到cuda计算
depth_gt = sample_cuda["depth"] # 深度图ground truth数据
mask = sample_cuda["mask"] # mask用于将没有深度的地方筛除掉不计算loss
outputs = model(sample_cuda["imgs"], sample_cuda["proj_matrices"], sample_cuda["depth_values"]) # 将数据放到model中进行训练
depth_est = outputs["depth"] # MVSNet得到的深度估计图
loss = model_loss(depth_est, depth_gt, mask) # 计算estimation和ground truth的loss,mask用于选取有深度值的位置,只用这些位置的深度真值计算loss
loss.backward() # loss函数梯度反传
optimizer.step() # 优化器中所有参数沿梯度下降一步
scalar_outputs = {"loss": loss} # 这轮训练得到的loss
image_outputs = {
"depth_est": depth_est * mask, # 深度图估计(滤除掉本来就没有深度的位置)
"depth_gt": sample["depth"], # 深度图真值
"ref_img": sample["imgs"][:, 0], # 要估计深度的ref图
"mask": sample["mask"] # mask图(0-1二值图,为1代表这里有深度值)
}
if detailed_summary:
image_outputs["errormap"] = (depth_est - depth_gt).abs() * mask # 预测图和真值图的区别部分
scalar_outputs["abs_depth_error"] = AbsDepthError_metrics(depth_est, depth_gt, mask > 0.5) # 绝对深度估计误差(整个场景深度估计的偏差平均值) mean[abs(est - gt)]
scalar_outputs["thres2mm_error"] = Thres_metrics(depth_est, depth_gt, mask > 0.5, 2) # 整个场景深度估计误差大于2mm的偏差偏差值(认为2mm之内都是估计的可以接受的) mean[abs(est - gt) > threshold]
scalar_outputs["thres4mm_error"] = Thres_metrics(depth_est, depth_gt, mask > 0.5, 4)
scalar_outputs["thres8mm_error"] = Thres_metrics(depth_est, depth_gt, mask > 0.5, 8)
return tensor2float(loss), tensor2float(scalar_outputs), image_outputs
对于训练某个数据的输出如下:deptp_est, depth_gt, errormap, mask, ref_img即对应该函数的输出
eval.py
- 相机参数读取是内参intrinsics要除4
- 测试时参考图像用了5个视点
- 生成所有测试图片的深度图和confidence图
- 通过光度一致性和几何一致性优化深度图
save_depth(): 通过MVSNet进行test生成深度图的核心步骤
-
首先构建MVSDataset和Loader
-
对于每一条训练数据通过模型
-
输入:1ref + 4src,每个视点的投影矩阵,深度假设list
-
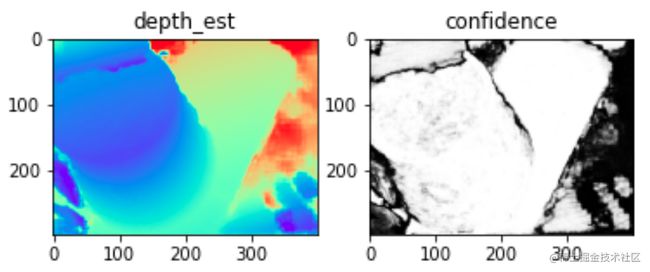
输出:深度图,photometric confidence
- 深度图里的数据都是668.08545, 559.7229这类的真实物理距离(不满足像素的取值所以在mac上直接看是一片空白的)
- 置信度里的数据是0~1之间的小数
-
-
将模型输出的两张图分别保存成pfm
reproject_with_depth(): 将ref的点投影到src上,再投影回来
- 参数:ref的深度图和内外参,src的深度图和内外参
- 返回值:重投影回来的深度图,重投影回来的x和y坐标,在src上的x和y坐标 尺寸都是(128, 160)
check_gemoetric_consistency(): 几何一致性检验,调用上面的方法进行重投影,重投影后像素偏移<1 && 深度差<1%则通过校验
-
参数:ref的深度图和内外参,src的深度图和内外参
-
返回值:
- mask: 通过几何检验的mask图
- depth_reprojected: 重投影后的深度图
- x2d_src: ref这些像素在src上的坐标
- y2d_src: ref这些像素在src上的坐标
filter_depth(): 通过光度一致性约束和几何一致性约束filter上一步得到的深度图
photo_mask: 置信度图>0.8geometric_mask: 至少3个src满足上面的几何一致性校验(重投影后像素偏移<1 && 深度差<1%)- filter每张ref的x y depth,并赋予颜色
- 最终融合生成最后的点云

module.py
-
ConvBnReLU,ConvBn,ConvBnReLU3D,ConvBn3D均为基础的网络结构,原始论文中例如特征提取中的一层即为这里的一个基础模块 -
BasicBlock,Hourglass3d在代码运行中并没使用 -
homo_warping: 将src图的特征体,根据ref和src的投影矩阵,投影到ref视角下def homo_warping(src_fea, src_proj, ref_proj, depth_values): """投影变换:将src图像的特征投影到ref图像上,融合深度假设范围,得到warped volume Args: src_fea (src图像的特征)): [B, C, H, W] 此时的C已经是32维了 src_proj (src图像的投影矩阵): [B, 4, 4] ref_proj (参考图像的投影矩阵)): [B, 4, 4] depth_values (深度假设范围数组): [B, Ndepth] Returns: [B, C, Ndepth, H, W] 最终得到的可以理解为src特征图按照不同的深度间隔投影到ref后构建的warped volume """ batch, channels = src_fea.shape[0], src_fea.shape[1] num_depth = depth_values.shape[1] height, width = src_fea.shape[2], src_fea.shape[3] with torch.no_grad(): # 阻止梯度计算,降低计算量,保护数据 proj = torch.matmul(src_proj, torch.inverse(ref_proj)) # src * ref.T rot = proj[:, :3, :3] # [B,3,3] 取左上角三行三列得到旋转变换 trans = proj[:, :3, 3:4] # [B,3,1] 取最后一列的上面三行得到平移变换 y, x = torch.meshgrid([torch.arange(0, height, dtype=torch.float32, device=src_fea.device), torch.arange(0, width, dtype=torch.float32, device=src_fea.device)]) # 按照ref图像维度构建一张空的平面,之后要做的是根据投影矩阵把src中的像素映射到这张平面上 y, x = y.contiguous(), x.contiguous() # 保证开辟的新空间是连续的(数组存储顺序与按行展开的顺序一致,transpose等操作是跟原tensor共享内存的) y, x = y.view(height * width), x.view(height * width) # 将维度变换为图像样子 xyz = torch.stack((x, y, torch.ones_like(x))) # [3, H*W] xyz = torch.unsqueeze(xyz, 0).repeat(batch, 1, 1) # [B, 3, H*W] unsqueeze先将维度变为[1, 3, H*W], repeat是为了将batch的维度引入进来 rot_xyz = torch.matmul(rot, xyz) # [B, 3, H*W] 先将空白空间乘以旋转矩阵 rot_depth_xyz = rot_xyz.unsqueeze(2).repeat(1, 1, num_depth, 1) \ * depth_values.view(batch, 1, num_depth, 1) # [B, 3, Ndepth, H*W] 再引入Ndepths维度,并将深度假设值填入这个维度 proj_xyz = rot_depth_xyz + trans.view(batch, 3, 1, 1) # [B, 3, Ndepth, H*W] 旋转变换后的矩阵+平移矩阵 -> 投影变换后的空白平面 proj_xy = proj_xyz[:, :2, :, :] / proj_xyz[:, 2:3, :, :] # [B, 2, Ndepth, H*W] xy分别除以z进行归一 proj_x_normalized = proj_xy[:, 0, :, :] / ((width - 1) / 2) - 1 # [B, Ndepth, H*W] x方向按照宽度进行归一 proj_y_normalized = proj_xy[:, 1, :, :] / ((height - 1) / 2) - 1 # y方向按照高度进行归一 @Q 这两步不太知道是干什么的? proj_xy = torch.stack((proj_x_normalized, proj_y_normalized), dim=3) # [B, Ndepth, H*W, 2] 再把归一化后的x和y拼起来 grid = proj_xy warped_src_fea = F.grid_sample(src_fea, grid.view(batch, num_depth * height, width, 2), \ mode='bilinear', padding_mode='zeros') # 按照grid中的映射关系,将src的特征图进行投影变换 warped_src_fea = warped_src_fea.view(batch, channels, num_depth, height, width) # 将上一步编码到height维的深度信息独立出来 return warped_src_fea -
depth_regression: 深度回归,根据之前假设的192个深度经过网络算完得到的不同概率,乘以深度假设,求得期望(最后在深度假设维度做了加法,所以运算后深度假设这一维度就没了)这个期望即是最终估计的最优深度,对应论文中的公式(3) D = ∑ d = d m i n d m a x d × P ( d ) D = \sum_{d=d_{min}}^{d_{max}} d \times P(d) D=∑d=dmindmaxd×P(d)
mvsnet.py
-
FeatureNet: 特征提取网络- 将三通道的特征转换为32维的高维深度特征,同时图像进行了4倍下采样
- 输入:[3, H, W]
- 输出:[32, H/4, W/4] (32, 160, 128)
-
CostRegNet: cost volume正则化网络- 先一路卷积降维,再一路反卷积升维,过程中把每步卷积和反卷积对应的volume都累加起来传播
- 输入:[B, C, D, H/4, W/4]
- 输出:[B, 1, D, H/4, W/4] (B, 1, 192, 160, 128)
-
RefineNet: 深度图边缘优化残差网络- 输入: [B, 4, H/4, W/4] 4是因为img有三通道,depth有1通道
- 输出: [B, 1, H/4, W/4] (B, 1, 160, 128)
-
MVSNet Pipeline
-
feature extraction
- 输入:每张图片[B, 3, H, W]
- 输出:特征图[B, 32, H/4, W/4]
- 通过特征提取网络之后,原始图像的3-channel变为32维的高位特征,并且图像尺寸缩减到原来的1/4
-
differential homograph, build cost volume
- 将ref的32维特征和ref投影过来的高维特征累积构成原始cost volume
- 通过公式(2) C = ∑ i = 1 N ( V i − V i ˉ ) 2 N C = \frac{\sum_{i=1}^N(V_i - \bar{V_i})^2}{N} C=N∑i=1N(Vi−Viˉ)2 计算方差得到最后的cost volume(在实现里通过 ∑ i = 1 N V i 2 N − V i ˉ 2 \frac{\sum_{i=1}^N V_i^2}{N} - \bar{V_i}^2 N∑i=1NVi2−Viˉ2公式简化计算)
- 最终的cost volume维度是[B, 32, 192, H/4, W/4]
-
cost volume regularization
这个cost网络本身是不改变维度的 只是去除噪声更加抽象,真正把32拍成1的是最后一个prob层(soft argmin),最终的物理含义是 某一个pixel的某一个深度假设位置的概率值
- 首先通过代价体正则化网络进行进一步抽象,最终得到的维度是[B, 1, 192, H/4, W/4]
- 通过squeeze将维度为1的维度去除掉,得到[B, 192, H/4, W/4]
- 通过Softmax函数,将深度维度的信息压缩为0~1之间的分布,得到概率体probability volume
- 通过深度回归depth regression,得到估计的最优深度图 [B, H, W]
- 最后进行光度一致性校验,最终得到跟深度图尺寸一样的置信度图:简单来说就是选取上面估计的最优深度附近的四个点,再次通过depth regression得到深度值索引,再通过gather函数从192个深度假设层中获取index对应位置的数据
-
depth map refinement:将原图和得到的深度图合并送入优化残差网络,输出优化后的深度图
-
-
mvsnet_loss- 根据公式(4)计算loss
- 由于是有监督学习,loss就是估计的深度图和ground truth深度图差一差的绝对值
- 唯一要注意的是,数据集中的mask终于在这发挥作用了,我们只选取mask>0.5,也就是可视化中白色的部分计算loss,只有这部分的点深度是valid的