决策树的三种常见算法
决策树
- 用途&组成
- 构造算法
-
- 1. 特征选择
-
- metric
-
- ID3:信息增益
-
- 定义
- 使用场景
- 例子
- 缺点
- C4.5: 信息增益比
-
- 定义
- 连续数值特征的处理(转化为二分类寻找阈值的问题)
- 解决过拟合问题:剪枝
- 问题
- CART(Classification And Regression Tree):
-
- 定义
- 使用场景
- 后剪枝:基于代价复杂度
- 优劣
- 总结比较
- 算法分析
-
- 适用场景
- 问题
-
- 过拟合
- 类别不均衡
- 实现
用途&组成
决策树是一个监督学习模型,可用于分类和回归,它是一个由内节点和叶节点构成的树型结构。每个内节点对应了一个关于某种特征的测试(Decision),通过测试,可以把样本分开(split)。最后位于同一叶子节点的样本被分为某一类。
- root:
- node:对某一特征的条件测试, i f ( f e a t u r e i ⋅ ⋅ ⋅ ⋅ ) if(feature_i····) if(featurei⋅⋅⋅⋅)。
- leaf:最终的决策结果。
构造算法
决策树的构造有三个重要的步骤:
- 特征选择
- 决策树生成
- 剪枝
接下来按照这三个步骤一一阐述。
1. 特征选择
构造决策树时,一个首先需要考虑的问题是选择哪一个特征来作为划分样本的依据。为了比较不同的特征间的优劣,需要设计一个metric来衡量它们的performance。常用到的metric有三种:
- 信息增益
- 信息增益比
- Gini指数(纯净度)
metric
ID3:信息增益
定义
-
熵(Entropy):事物的不确定性,越不确定,熵越大。一个随机变量X的熵的计算如下:
E ( X ) = ∑ X = 1 n − p i l o g ( p i ) E(X)=\sum_{X=1}^{n}-\ p_i\ log(p_i) E(X)=X=1∑n− pi log(pi)
X = 1... n : X=1...n: X=1...n:随机变量X有n种不同的取值
p i : p_i: pi:每种取值对应的可能性为 p i p_i pi
随机变量均匀分布时,熵达到最大。即均匀分布的不确定性最强。而n类平均分布的熵会小于n+1类平均分布的熵。
-
联合熵:随机变量X与Y的联合熵
H ( X , Y ) = ∑ x i ∈ X ∑ y j ∈ Y − p ( x i , y j ) l o g ( p ( x i , y j ) ) = ∑ x i ∈ X ∑ y j ∈ Y − p ( x i , y j ) l o g ( p ( x i ∣ y j ) p ( y j ) ) = − ∑ x i ∈ X ∑ y j ∈ Y p ( x i , y j ) l o g ( p ( y j ) ) − ∑ x i ∈ X ∑ y j ∈ Y p ( x i , y j ) l o g ( p ( x i ∣ y j ) ) = − ∑ y j ∈ Y ∑ x i ∈ X p ( x i , y j ) l o g ( p ( y j ) ) − ∑ x i ∈ X ∑ y j ∈ Y p ( x i , y j ) l o g ( p ( x i ∣ y j ) ) = − ∑ y j ∈ Y p ( y j ) l o g ( p ( y j ) ) − ∑ x i ∈ X ∑ y j ∈ Y p ( x i , y j ) l o g ( p ( x i ∣ y j ) ) = H ( Y ) + H ( X ∣ Y ) = H ( X ) + H ( Y ∣ X ) \begin{aligned} H(X,Y)&=\sum_{x_i\in X}\sum_{y_j\in Y}-\ p(x_i,y_j)\ log(p(x_i,y_j))\\ &=\sum_{x_i\in X}\sum_{y_j\in Y}-\ p(x_i,y_j)\ log(p(x_i|y_j)p(y_j))\\ \\ &=-\sum_{x_i\in X}\sum_{y_j\in Y}\ p(x_i,y_j)\ log(p(y_j))-\sum_{x_i\in X}\sum_{y_j\in Y}\ p(x_i,y_j)\ log(p(x_i|y_j))\\ \\ &=-\sum_{y_j\in Y}\sum_{x_i\in X}\ p(x_i,y_j)\ log(p(y_j))-\sum_{x_i\in X}\sum_{y_j\in Y}\ p(x_i,y_j)\ log(p(x_i|y_j))\\ \\ &=-\sum_{y_j\in Y}\ p(y_j)\ log(p(y_j))-\sum_{x_i\in X}\sum_{y_j\in Y}\ p(x_i,y_j)\ log(p(x_i|y_j))\\ \\ &=H(Y)+H(X|Y) \\ &=H(X)+H(Y|X) \\ \end{aligned} H(X,Y)=xi∈X∑yj∈Y∑− p(xi,yj) log(p(xi,yj))=xi∈X∑yj∈Y∑− p(xi,yj) log(p(xi∣yj)p(yj))=−xi∈X∑yj∈Y∑ p(xi,yj) log(p(yj))−xi∈X∑yj∈Y∑ p(xi,yj) log(p(xi∣yj))=−yj∈Y∑xi∈X∑ p(xi,yj) log(p(yj))−xi∈X∑yj∈Y∑ p(xi,yj) log(p(xi∣yj))=−yj∈Y∑ p(yj) log(p(yj))−xi∈X∑yj∈Y∑ p(xi,yj) log(p(xi∣yj))=H(Y)+H(X∣Y)=H(X)+H(Y∣X) -
条件熵:已知一个变量Y之后,剩下的变量X的不确定性
H ( X ∣ Y ) = ∑ x i ∈ X ∑ y j ∈ Y − p ( x i , y j ) l o g ( p ( x i ∣ y j ) ) = ∑ y j ∈ Y p ( y j ) H ( X ∣ y j ) \begin{aligned} H(X|Y)&=\sum_{x_i\in X}\sum_{y_j\in Y}-\ p(x_i,y_j)\ log(p(x_i|y_j)) \\ &= \sum_{y_j\in Y}p(y_j)H(X|y_j) \end{aligned} H(X∣Y)=xi∈X∑yj∈Y∑− p(xi,yj) log(p(xi∣yj))=yj∈Y∑p(yj)H(X∣yj) -
信息增益:
已知一个变量以后,使得另外一个变量的不确定性减少,减少的幅度即为信息增益,也被称为互信息。
I ( X , Y ) = H ( X ) − H ( X ∣ Y ) I(X,Y)=H(X)-H(X|Y) I(X,Y)=H(X)−H(X∣Y)
信息增益越大,说明变量Y带来的信息越多,即越有用。
使用场景
信息增益可以用来衡量使用某特征来划分样本以后,样本的不确定性与划分前相比,下降的幅度。下降的越多,说明生成的划分越确定,即被划分到同一节点的样本越可能属于同一类别。
信息增益可以很好地选出最符合目标的特征,即:经过此特征划分后,不同类别的样本可以被分开。
计算公式:
I ( D , A ) = H ( D ) − H ( D ∣ A ) I(D, A) = H(D)-H(D|A) I(D,A)=H(D)−H(D∣A)
D : D: D:原始的样本分布。
A : A: A:某一特征测试。
D ∣ A : D|A: D∣A:经过特征测试后,新的样本分布。
例子
原始有两类样本,类0的样本数为10,类1的样本数为5。现在有两个特征,特征A有三个取值,划分之后A1的样本分布为4:0,A2为4:1,A3为2:4。特征B有两个取值,划分之后B1的样本分布为8:2,B2为2:3。
H ( D ) = − 10 15 l o g ( 10 15 ) − 5 15 l o g ( 5 15 ) = 0.92 H(D)=-\frac{10}{15}log(\frac{10}{15})-\frac{5}{15}log(\frac{5}{15})=0.92 H(D)=−1510log(1510)−155log(155)=0.92
H ( D ∣ A ) = − 4 15 ( 1 ∗ l o g ( 4 4 ) + 0 ) − 5 15 ( 4 5 ∗ l o g ( 4 5 ) + 1 5 ∗ l o g ( 1 5 ) ) − 6 15 ( 2 6 ∗ l o g ( 2 6 ) + 4 6 ∗ l o g ( 4 6 ) ) = 0.61 H(D|A)=-\frac{4}{15}(1*log(\frac{4}{4})+0)-\frac{5}{15}(\frac{4}{5}*log(\frac{4}{5})+\frac{1}{5}*log(\frac{1}{5}))-\frac{6}{15}(\frac{2}{6}*log(\frac{2}{6})+\frac{4}{6}*log(\frac{4}{6}))=0.61 H(D∣A)=−154(1∗log(44)+0)−155(54∗log(54)+51∗log(51))−156(62∗log(62)+64∗log(64))=0.61
H ( D ∣ B ) = − 10 15 ( 8 10 ∗ l o g ( 8 10 ) + 2 10 ∗ l o g ( 2 10 ) ) − 5 15 ( 2 5 ∗ l o g ( 2 5 ) + 3 5 ∗ l o g ( 3 5 ) ) = 0.8 H(D|B)=-\frac{10}{15}(\frac{8}{10}*log(\frac{8}{10})+\frac{2}{10}*log(\frac{2}{10}))-\frac{5}{15}(\frac{2}{5}*log(\frac{2}{5})+\frac{3}{5}*log(\frac{3}{5}))=0.8 H(D∣B)=−1510(108∗log(108)+102∗log(102))−155(52∗log(52)+53∗log(53))=0.8
I ( D , A ) = 0.92 − 0.61 = 0.31 I(D,A)=0.92-0.61=0.31 I(D,A)=0.92−0.61=0.31
I ( D , B ) = 0.92 − 0.8 = 0.12 I(D,B)=0.92-0.8=0.12 I(D,B)=0.92−0.8=0.12
因此可知,在这个例子中,选择特征A能使样本更好地被分类。直观地观察A与B的划分后分布也可以粗略看出这一点。
缺点
-
样本不足的情况下,ID3的信息增益法会倾向于选择取值更多的特征。
当样本量不足时,对于取值多的特征来说,其每种划分下的样本会比取值少的特征少。而根据大数定理,当样本数目不足时,用每个划分中的各类样本数量来估计各类的出现概率是不准确的。会造成估计概率和真实概率间的方差很大。举个例子,投掷硬币,正反面出现的概率应为0.5:0.5,但因为投掷次数不多(此处极端假设2次),最后得到的正反面次数是2:0。若在这种样本不足的情况下,用样本数目来近似每类的出现概率,则会得到1:0的结果,计算出的信息增益会偏大。即,估计出的概率分布更不均匀,导致其对应的熵偏小,信息增益偏大。
当然,在样本充足的情况下,ID3不会有这样的倾向。
样本不足 → 估计值的方差较大 → 估计出的分布更不均匀 → 熵偏小 → 信息增益偏大 \text{样本不足}\rightarrow \text{估计值的方差较大}\rightarrow\text{估计出的分布更不均匀}\rightarrow\text{熵偏小}\rightarrow\text{信息增益偏大} 样本不足→估计值的方差较大→估计出的分布更不均匀→熵偏小→信息增益偏大 -
无法处理数值特征。
可以看到,ID3算法计算信息增益时,只考虑了类别特征的计算方法,而对于像身高,体重等连续的数值特征却没有涵盖。 -
没有考虑特征缺失值的处理。
-
算法里没有考虑树的过拟合问题。
C4.5: 信息增益比
C4.5针对ID3的缺点做了很多优化,其中最值得一提的是用信息增益比来代替单纯的信息增益,作为特征选择的衡量标准。信息增益比能缓解在样本不足的情况下,ID3对取值更多的特征的偏好。C4.5还通过离散化连续数值特征,使得信息增益比也可以在这些特征上使用。C4.5也加入了处理缺失值的方法,以及添加了简单的正则化剪枝,以缓解过拟合的问题。
定义
-
特征熵:特征熵可以用来衡量样本在使用某特征划分后的分布的不确定性。取值数目越多,分割后各取值得到的样本分布得越均匀,则特征熵越大。可以用它作为分母,来惩罚取值多的特征,以纠正ID3的偏好。
H A ( D ) = − ∑ i = 1 n ∣ D i ∣ ∣ D ∣ l o g ( ∣ D i ∣ ∣ D ∣ ) H_A(D)=-\sum_{i=1}^n\frac{\lvert{D_i}\rvert }{\lvert D \rvert}log(\frac{\lvert{D_i}\rvert }{\lvert D \rvert}) HA(D)=−i=1∑n∣D∣∣Di∣log(∣D∣∣Di∣)
i : i: i:特征A的n种取值。
∣ D ∣ : \lvert{D}\rvert: ∣D∣:分割前的总样本数。
∣ D i ∣ : \lvert{D_i}\rvert: ∣Di∣:每个划分的样本的数目。 -
信息增益比:
I R ( D , A ) = I ( D , A ) H A ( D ) I_R(D,A)=\frac{I(D,A)}{H_A(D)} IR(D,A)=HA(D)I(D,A)
R : R: R: ratio.
H A ( D ) : H_A(D): HA(D): 特征熵,用于平衡特征取值数目对信息增益带来的影响。
连续数值特征的处理(转化为二分类寻找阈值的问题)
假设存在一个连续特征A,在样本中,其取值分别为 a 1 , a 2 , . . . a n a_1,a_2,...a_n a1,a2,...an。要处理这个特征,容易想到的思路是先将它离散化,再寻找最优分割:
- 特征A的取值排序:
假设排序结果从小到大为 a 1 , a 2 , . . . a n a_1,a_2,...a_n a1,a2,...an - 设置候选分割点:
使用相邻数值计算均值,作为待检测的分割点。即n个样本,排序分割后会产生(n-1)个分割点。 - 选择最优分割点:
每个分割点都把样本分为了两类,依据信息增益比的计算公式计算每个分割点对应的信息增益比。选择信息增益比最大的点作为此特征最终的分割点。
解决过拟合问题:剪枝
- 预剪枝
设置一定的early stop的条件,当满足条件后就不再继续分割。一般使用的条件如下:- 所有特征均已使用。
- 分割后样本数小于阈值。
- 分割后准确率反而降低。
- 后剪枝(子树替代法)
在整个决策树构建完成后,自底向上检验每棵子树是否能用叶子节点替代。如果子树的错误率大于使用单一的叶子节点的错误率,则替代。
但这个方法存在着一个很大的问题,即如何准确估计子树的错误率。在计算错误率时,若使用训练集来计算,则所得的错误率一般会比真实的值小。为了纠正这样的偏差,有三种解决的方法:- 使用验证集来计算子树的错误率。
- 悲观计算:人为地增加子树的错误样本数。
- 用confidence level来估计真实的错误率的区间。
这里讲一下第三种方法:
f:用训练集估计的错误率, = 错 误 样 本 数 量 样 本 总 数 量 =\frac{错误样本数量}{样本总数量} =样本总数量错误样本数量
p :真实的错误率
可知: p = f ± ( z ∗ f ( 1 − f ) N ) p =f\pm(z*\sqrt{\frac{f(1-f)}{N}}) p=f±(z∗Nf(1−f))
z:某一confidence level下对应的系数。例如:置信区间95%意味着,取均值左右1.96个标准差的范围( ± z ∗ σ \pm z*\sigma ±z∗σ),100次中有95次,真实的错误率就被包含在这个范围中。
e:某一confidence level下的真实错误率区间的上限, e = f + ( z ∗ f ( 1 − f ) N ) e=f+(z*\sqrt{\frac{f(1-f)}{N}}) e=f+(z∗Nf(1−f))。

如上图所示,f = 2/6, N=6时, p = 0.33 + 0.69 ∗ 0.33 ∗ 0.66 / 6 = 0.33 + 0.13 = 0.46 p = 0.33 + 0.69*\sqrt{0.33*0.66/6}=0.33+0.13=0.46 p=0.33+0.69∗0.33∗0.66/6=0.33+0.13=0.46
计算子树的错误率上限时,使用样本数加权平均每个叶子的e。
如果剪枝后的e更小,则使用单一叶子来替代整个子树。上图例子中,剪枝前e为0.51,剪枝后降低为0.46,因此执行此剪枝。
- 预剪枝 vs. 后剪枝
- 预剪枝:
+可缩短模型训练的时间,降低过拟合的风险
-可能引起欠拟合问题。虽然某一次分割不会大幅提升准确率,但是按这个分支展开,后续可能会带来性能的提升。预剪枝根据贪心策略不再继续探索某些分支,带来了欠拟合风险。 - 后剪枝:
+首先充分探索各种特征及其分割,生成一颗完整的决策树,之后再从下至上,寻找可以通过剪枝来优化的子树,欠拟合风险小
-消耗更多的计算资源,更加耗时。
- 预剪枝:
问题
- 只能用于分类。
- 在选择连续特征时需要排序,熵模型涉及许多对数运算,分割点选择需要轮流计算比较,大量耗费计算资源。
CART(Classification And Regression Tree):
- 二叉树,简化决策树的规模,提高树的生成效率,比起ID3和C4.5的多叉树来说,计算规模更小。
- 可以用作分类和回归:
- 分类:Gini指数最小化
- 回归:平方误差最小化(对每一特征生成可能分割+用平方误差选择最优分割)。每一个节点的预测值为属于此节点的所有样本的均值。
定义
-
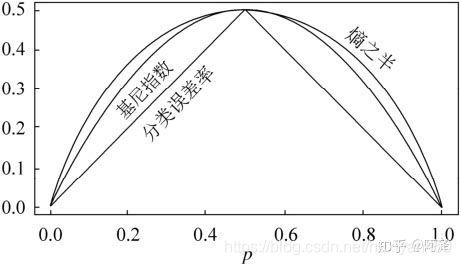
Gini指数:衡量一个分割的纯净度。Gini指数越小,说明此分割越纯净,此分割中的绝大部分样本属于同一类。随机抽取两个样本,其类别不一致的概率, 类似于 p(1-p)。
G i n i ( D i ) = ∑ k = 1 m ∣ D k ∣ ∣ D i ∣ ( 1 − ∣ D k ∣ ∣ D i ∣ ) Gini(D_i)=\sum_{k=1}^m\frac{\lvert{D_k}\rvert }{\lvert D_i \rvert}(1-\frac{\lvert{D_k}\rvert }{\lvert D_i \rvert}) Gini(Di)=k=1∑m∣Di∣∣Dk∣(1−∣Di∣∣Dk∣)
i : i: i:特征A的一个分割。
m : m: m:一共有m类样本。
∣ D i ∣ : \lvert{D_i}\rvert: ∣Di∣:此分割拥有的总样本数。
∣ D k ∣ : \lvert{D_k}\rvert: ∣Dk∣:每类的样本的数目。 -
与熵的关系:
一阶泰勒展开: l n ( x ) = − 1 + x + o ( x ) ln(x)=-1+x+o(x) ln(x)=−1+x+o(x)
H ( D i ) = − ∑ k = 1 m p k l o g ( p k ) ≈ − ∑ k = 1 m p k ( 1 − p k ) ≈ ∑ k = 1 m ∣ D k ∣ ∣ D i ∣ ( 1 − ∣ D k ∣ ∣ D i ∣ ) \begin{aligned} H(D_i)&=-\sum_{k=1}^m p_k log(p_k) \\ &\approx-\sum_{k=1}^m p_k (1-p_k) \\ &\approx \sum_{k=1}^m\frac{\lvert{D_k}\rvert }{\lvert D_i \rvert}(1-\frac{\lvert{D_k}\rvert }{\lvert D_i \rvert})\\ \end{aligned} H(Di)=−k=1∑mpklog(pk)≈−k=1∑mpk(1−pk)≈k=1∑m∣Di∣∣Dk∣(1−∣Di∣∣Dk∣)
Gini指数可以看作是熵的一阶泰勒展开。
-
特征的Gini指数:特征的每个分割的Gini指数的加权平均。
G i n i ( D ) = ∑ i = 1 n ∣ D i ∣ ∣ D ∣ ∑ k = 1 m ∣ D k ∣ ∣ D i ∣ ( 1 − ∣ D k ∣ ∣ D i ∣ ) = ∑ i = 1 n ∣ D i ∣ ∣ D ∣ G i n i ( D i ) \begin{aligned} Gini(D)&=\sum_{i=1}^n\frac{\lvert{D_i}\rvert }{\lvert D \rvert}\sum_{k=1}^m\frac{\lvert{D_k}\rvert }{\lvert D_i \rvert}(1-\frac{\lvert{D_k}\rvert }{\lvert D_i \rvert}) \\ \\ &=\sum_{i=1}^n\frac{\lvert{D_i}\rvert }{\lvert D \rvert}Gini(D_i) \end{aligned} Gini(D)=i=1∑n∣D∣∣Di∣k=1∑m∣Di∣∣Dk∣(1−∣Di∣∣Dk∣)=i=1∑n∣D∣∣Di∣Gini(Di)
i : i: i:特征A的一个分割。
n : n: n:特征A一共有n种取值。
∣ D ∣ : \lvert{D}\rvert: ∣D∣:总样本的数目。
∣ D k ∣ : \lvert{D_k}\rvert: ∣Dk∣:每种分割里的每类的样本数目。 -
回归问题的特征选择标准:假设最优特征为 a a a,其对应的最优分割为 s s s :
min a , s ( min c 1 ∑ x i ∈ D 1 ( y i − c 1 ) 2 + min c 2 ∑ x i ∈ D 2 ( y i − c 2 ) 2 ) \underset{a,s}{\min}(\underset{c_1}{\min}\sum_{x_i \in D_1}(y_i-c_1)^2+\underset{c_2}{\min}\sum_{x_i \in D_2}(y_i-c_2)^2) a,smin(c1minxi∈D1∑(yi−c1)2+c2minxi∈D2∑(yi−c2)2)
D 1 : D_1: D1:属于分割1的样本集合。
D 2 : D_2: D2:属于分割2的样本集合。
c 1 : c_1: c1:样本集合1的均值,依赖于分割点s的选取。
c 2 : c_2: c2:样本集合2的均值。
y i : y_i: yi:样本对应的真实值。
使用场景
- 分类树
- 类别特征
- 连续数值特征
- 回归树:
对于不同类型的特征的处理同上,不同的是衡量特征优劣的metric。先计算叶节点的样本均值,以此均值作为预测值,并计算每个样本的真实值与此预测值之间平方差和作为衡量标准。
后剪枝:基于代价复杂度
-
设计一个损失函数,来平衡过拟合(叶节点过多)和欠拟合问题(误差较大):
C α ( T ) = C ( T ) + α ∣ T ∣ C_\alpha(T)=C(T)+\alpha \lvert{T}\rvert Cα(T)=C(T)+α∣T∣
C ( T ) : C(T): C(T):预测误差,拟合度。
α : \alpha: α:参数,惩罚复杂模型的力度。
∣ T ∣ : \lvert{T}\rvert: ∣T∣:叶节点数目,模型复杂度,泛化能力。 -
过程:
对于每一个内节点 t t t所对应的子树 T t T_t Tt,计算剪枝前后loss的差:
C α ( T t ) − C α ( t ) = C ( T t ) + α ∣ T t ∣ − C ( t ) − α ∗ 1 = C ( T t ) − C ( t ) + α ( ∣ T t ∣ − 1 ) \begin{aligned} C_\alpha(T_t)-C_\alpha(t) &= C(T_t)+\alpha \lvert{T_t}\rvert-C(t)-\alpha*1 \\ &=C(T_t)-C(t)+\alpha(\lvert{T_t}\rvert-1) \end{aligned} Cα(Tt)−Cα(t)=C(Tt)+α∣Tt∣−C(t)−α∗1=C(Tt)−C(t)+α(∣Tt∣−1)
当 α \alpha α为0时,对于某一个确定的子树 T t T_t Tt 和叶子 t t t ,一定有 C α ( T t ) < C α ( t ) C_\alpha(T_t)
对于不同的子树来说,使剪枝前后的loss的关系反转的 α \alpha α也不同。这个临界 α \alpha α越小,说明剪枝前后error的差距越小,且子树的叶子节点越多,也就是越理想的剪枝对象(weakest link)。更形象的解释见下图。
因此在每一次剪枝中,剪掉临界 α \alpha α最小的那个子树。


这个过程之后,得到了每个可能的 α i \alpha_i αi及其对应的最优决策树(完全决策树的内节点数目有限,因此迭代次数也有限)。之后可以使用 Cross-Validation等方法选出最优的 α b e s t \alpha_{best} αbest。
优劣
CART和ID3一样,没有特征熵来均衡特征取值数目对熵的影响,因此也存在偏向细小分割的问题。
总结比较
以上介绍的便是决策树常见的三种算法,它们的不同主要体现在一下几个方面:
- 使用场景:
- 分类
- 回归
- 使用特征:
- 类别特征
- 连续数值特征
- 算法偏好
- 取值多,分割细的特征
- metric:
- 信息增益
- 信息增益比
- Gini指数
- 剪枝方法:
- 预剪枝
- 后剪枝
- 悲观剪枝(子树替代法)
- 代价复杂度
- 填补缺失值
- 基于有缺失值的样本做特征选择
- 决定有缺失值的样本属于哪一个划分
算法分析
适用场景
- 样本量:
C4.5做特征选择时涉及样本排序,分割检测和对数运算,且其本身为多叉树结构,需消耗很多计算资源,适用于小样本。而 CART 本身是一种大样本的统计方法,小样本处理下泛化误差较大。
- 分类 or 回归
- 属性取值:
ID3和CART均会偏好取值多的特征,有此情况的话需考虑C4.5算法
问题
过拟合
-
决策树算法实质上是一个多重选择过程:为存在的n个特征计算分别的score,再选择score最大的特征做测试,加入模型以提高模型的准确度。而这里存在概念的混淆:
- 特征 i 的 s c o r e i score_{i} scorei的分布:在评价函数与特征种类确定的情况下,与样本集合有关
- n个特征的 s c o r e m a x 的 分 布 score_{max}的分布 scoremax的分布 :与特征的数目有关
s c o r e i score_{i} scorei与 s c o r e m a x score_{max} scoremax根本不是同一分布的变量,因此用 s c o r e m a x score_{max} scoremax来代表某一特征的 s c o r e i score_{i} scorei从而进行选择是有问题的,这个推断是不成立的,他不能为未来的预测做任何保证。 s c o r e m a x score_{max} scoremax的分布受特征数目的影响,而决策树在使用时却没有考虑这一点。因此用此方法选择出的特征有可能有噪音。在此举个简单的例子:
选择一个预测员来预测股票走势,若他14天预测正确11次以上则中选。假设所有来应征的预测员都是骗子,他们都做随机决策,那么一个预测员能正确11次以上,即他中选的概率为0.028。现在假设有n人应征,那么从中至少能选出一人的概率为: 1 − ( 1 − 0.028 ) n 1- (1-0.028)^{n} 1−(1−0.028)n。n为10时,概率为0.253;n为30时,至少选择一人的概率为0.5。
由此可以看出,每个预测员预测正确11次以上的概率(即 s c o r e i score_{i} scorei),和n个决策员中至少一个正确11次以上的概率(即 s c o r e m a x score_{max} scoremax)是不同的。
实际上当n很大时, P ( s c o r e i > t h r e s h o l d ) = p P(score_{i} > threshold)=p P(scorei>threshold)=p 是会明显小于 P ( s c o r e m a x > t h r e s h o l d ) = 1 − ( 1 − p ) n P(score_{max} > threshold)=1-(1-p)^n P(scoremax>threshold)=1−(1−p)n的,当特征很多时,用 s c o r e m a x score_{max} scoremax会高估 s c o r e i score_{i} scorei,即选出来的特征可能包含很多噪音。 -
决策树是用的是贪婪策略,因此它倾向于寻找局部最优,而不是根据数据的所有信息全局地寻找最优点, 对样本分布非常敏感,样本的改变可能会剧烈影响决策树的结构。
-
随着决策树的不断生长,叶子节点会越来越多,这也意味着分割的粒度会越来越细。想象极限情况下,可能会为每一个样本分一个叶子节点,即一条决策路径。因此决策树生成的方式,天然决定了它很容易过拟合。
-
过拟合的解决方案:
- early stop
- pruning
- K-Fold Cross Validation
- Random Forest
类别不均衡
- CART: 先验机制来确定分类阈值,以平衡偏差数据:
N 1 ( c h i l d ) N t o t a l ( c h i l d ) > N 1 ( p a r e n t ) N t o t a l ( p a r e n t ) \frac{N_1(child)}{N_{total}(child)}>\frac{N_1(parent)}{N_{total}(parent)} Ntotal(child)N1(child)>Ntotal(parent)N1(parent)
时,child节点才能被标记为类1。即,用父节点中的类别比例来作为分类阈值。仅影响每个节点的分类选择,使得每类数据落在各节点的概率先验相等。
实现
算法的分析比较 :https://www.cnblogs.com/pinard/p/6050306.html
c3为什么倾向于特征多的属性: https://www.zhihu.com/question/22928442
优化方案:https://blog.csdn.net/xbinworld/article/details/44660339
信息熵:https://blog.csdn.net/qq280929090/article/details/78135417
C4.5剪枝:http://www.cs.bc.edu/~alvarez/ML/statPruning.html
置信区间:https://www.zhihu.com/question/26419030
Cost-Complexity-Pruning: http://mlwiki.org/index.php/Cost-Complexity_Pruning
Cost-Complexity-Pruning的原理: https://online.stat.psu.edu/stat508/lesson/11/11.8/11.8.2
多重选择过程(Multiple Comparisons): https://link.springer.com/content/pdf/10.1023/A:1007631014630.pdf