深度学习笔记 5 卷积、池化
目录
1. 卷积
1.1 卷积的目的
1.2 卷积的基本属性
1.3 卷积的特点
2. 卷积分类与计算
2.1 标准卷积
2.2 反卷积
2.3 空洞卷积
2.4 深度可分离卷积
2.5 分组卷积
3. 池化
1. 卷积
卷积(Convolution),也叫褶积,通过两个函数 f 和 g 生成第三个函数的一种数学算子,表征函数 f 与 g 经过翻转和平移的重叠部分函数值乘积对重叠长度的积分。
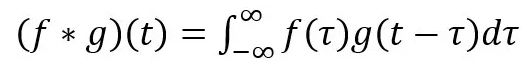
1.1 卷积的目的
卷积是为了提取图像特征,通过卷积层,可以自动提取图像的高维度且有效的特征;并且卷积核的权重是可以学习的,在高层神经网络中,卷积操作能突破传统滤波器的限制,根据目标函数提取出想要的特征。
1.2 卷积的基本属性
卷积核(Kernel):卷积操作的感受野,直观理解就是一个滤波矩阵,普遍使用的卷积核大小为3×3、5×5等;
步长(Stride):卷积核遍历特征图时每步移动的像素,如步长为1则每次移动1个像素,步长为2则每次移动2个像素(即跳过1个像素),以此类推;
填充(Padding):处理特征图边界的方式,一般有两种,一种是对边界外完全不填充,只对输入像素执行卷积操作,这样会使输出特征图的尺寸小于输入特征图尺寸;另一种是对边界外进行填充(一般填充为0),再执行卷积操作,这样可使输出特征图的尺寸与输入特征图的尺寸一致;
通道(Channel):卷积层的通道数(层数)。
1.3 卷积的特点
“局部感知,参数共享”的特点大大降低了网络参数,保证了网络的稀疏性,防止过拟合。
(1)局部视野
卷积操作在运算的过程中,一次只考虑一个窗口的大小,因此其具有局部视野的特点,局部性主要体现在窗口的卷积核的大小。
(2)权重共享
从上面的讲解可以看到,对一个输入为5∗5,卷积核为3∗3的情况下,对于每一个滑动窗口,使用的都是同一个卷积核,所以其参数共享。
(3)多个卷积核可以发现不同角度的特征,多个卷积层可以捕捉更全局的特征(处于卷积网络更深的层或者能够的单元,他们的接受域要比处在浅层的单元的接受域更大)
2. 卷积分类与计算
2.1 标准卷积
标准卷积核与目标图像矩阵进行卷积运算,多少数量的卷积核,就会对应多少的特征图。
单通道(卷积核(kernel)为3×3、步长(stride)为1、填充(padding)为0)
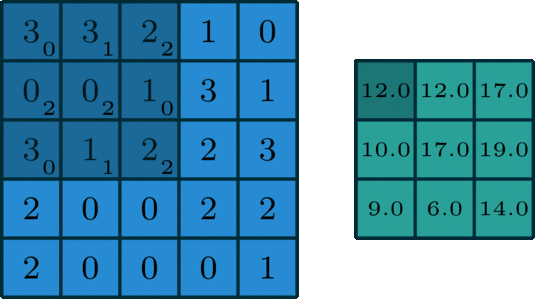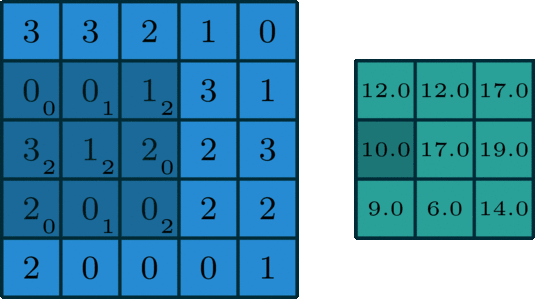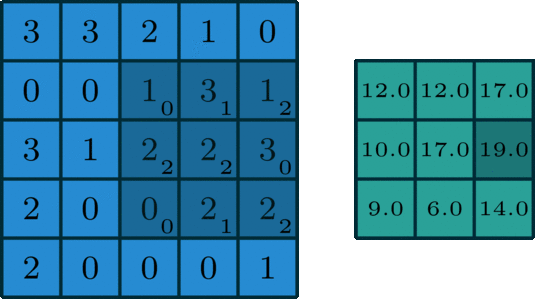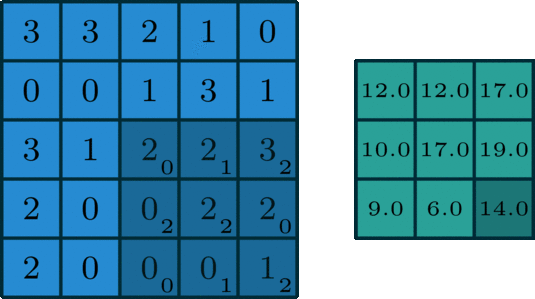
多通道 ,拥有多个通道的卷积,例如处理彩色图像时,分别对R, G, B这3个层处理的3通道卷积

多个卷积核,若有多个卷积核,对应多个feature map,也就是下一个输入层有多个通道。如下图所示
 2.2 反卷积
2.2 反卷积
反卷积是一种特殊的正向卷积,先按照一定的比例通过补0来扩大输入图像的尺寸,接着旋转卷积核(矩阵转置),再进行正向卷积。反卷积的操作只是恢复了矩阵的尺寸大小,并不能恢复的每个元素的原始值。
在卷积操作中: cx=y
在反卷积操作中: c^T y=x
这里并不是严格意义上的等于,而只是维度的相等,因为c 和 c^T都是训练,并不是直接取转置。
 2.3 空洞卷积
2.3 空洞卷积
空洞卷积或者膨胀卷积是在标准的卷积核里注入空洞,利用添加空洞扩大感受野,让原本3x3的卷积核,在相同参数量和计算量下拥有5x5(dilated rate =2)或者更大的感受野,从而无需下采样。相比原来的正常convolution,dilated convolution 多了一个超参数称之为 dilation rate(空洞率d) 指的是kernel的间隔数量(e.g. 标准卷积的空洞率是1),即在内核元素之间插入d-1个空格。当d=1时,则内核元素之间没有插入空格,变为标准卷积优点是在保持同等计算量的情况下可以扩大感受野,缺点是存在网格效应。
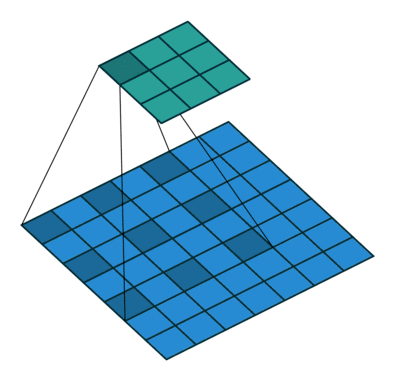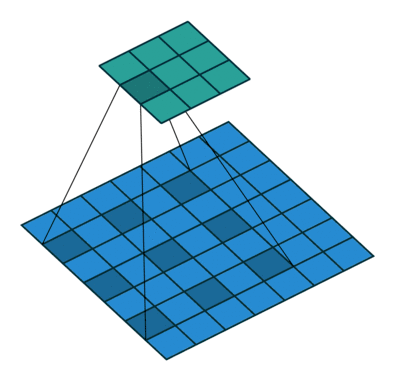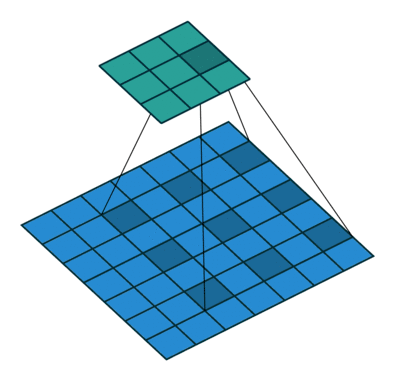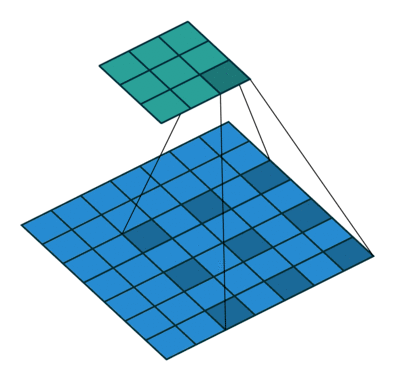
2.4 深度可分离卷积
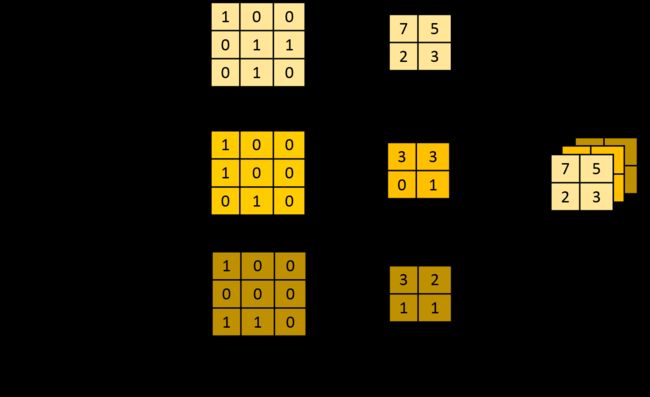
Depthwise Separable Convolution(深度可分离卷积)是将一个完整的卷积运算分解为两步运行,即Depthwise卷积 与 Pointwise卷积
逐深度卷积(滤波):将单个滤波器应用到每一个输入通道,Depthwise convolution的一个卷积核只负责一个通道,即一个通道只被一个卷积核卷积。
一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示。
 逐点卷积(组合): Pointwise 卷积运算则是常规的运算,用1*1的卷积组合不同深度卷积的输出,得到一组新的输出。卷积核的尺寸为 1×1×M,M为上一层的depth。这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个Filter就有几个Feature map,计算参数量为 1x1x3x4=12。
逐点卷积(组合): Pointwise 卷积运算则是常规的运算,用1*1的卷积组合不同深度卷积的输出,得到一组新的输出。卷积核的尺寸为 1×1×M,M为上一层的depth。这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个Filter就有几个Feature map,计算参数量为 1x1x3x4=12。
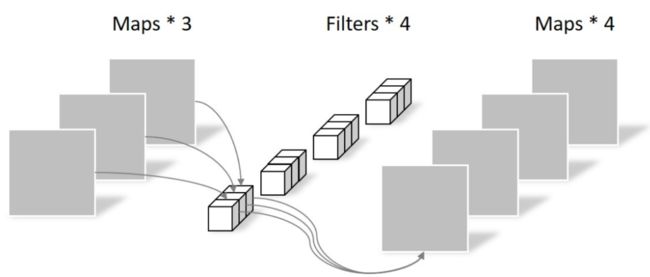
2.5 分组卷积
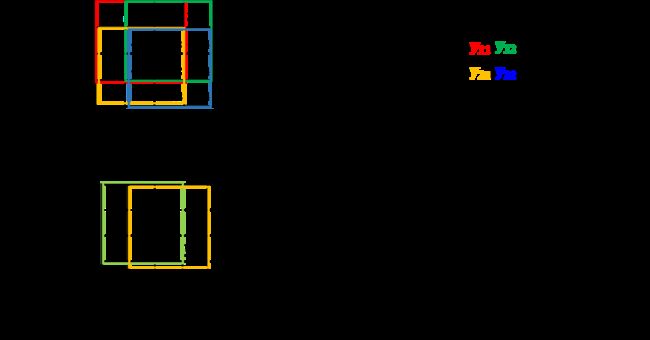
Group convolution 分组卷积,最早在AlexNet中出现,由于当时的硬件资源有限,训练AlexNet时卷积操作不能全部放在同一个GPU处理,因此作者把feature maps分给多个GPU分别进行处理,最后把多个GPU的结果进行融合。就是将特征图分成两半或几部分,卷积后再组合,组合方式一般是concate。

输入每组feature map尺寸:W x H x C/g, 共有g组
单个卷积核每组的尺寸:k x k x C/g
3. 池化
池化的定义,仿照人的视觉系统进行特征降维(降采样),常见的池化有最大池化、平均池化和随机池化。池化层不需要训练参数。
池化优点:降低模型过拟合;平移不变性,即如果物体在图像中发生一个较小的平移(不超过感受野),那么这样的位移并不会影像池化的效果,从而不会对模型的特征图提取发生影响。
最大池化:计算pooling窗口内的最大值,并将这个最大值作为该位置的值;可以获取局部信息,更好保留纹理上的特征。
平均池化:计算pooling窗口内的平均值,并将这个值作为该位置的值;平均池化往往能保留整体数据的特征,能凸出背景的信息。
随机池化:是根据概率对局部的值进行采样,采样结果便是池化结果;随机池化一方面最大化地保证了Max值的取值,一方面又确保了不会完全是max值起作用,造成过度失真。其可以在一定程度上避免过拟合。

池化的选择:
最大池化能学到图像的边缘和纹理结构。
最大池化通常用以减小估计值方差,在方差不太重要的地方可以随意选择最大池化和平均池化。
平均池化用以减小估计均值的偏移。在某些情况下平均池化可能取得比最大池化稍好一些的效果。
平均池化会弱化强激活值,而最大池化保留最强的激活值却容易过拟合。