【论文精读2】MVSNet系列论文详解-RMVSNet
R-MVSNet是在MVSNet的基础上做了一些改进,主要解决的问题是代价体正则化(Cost Volume Regulazation)过程当中对内存过大的问题,主要做了三点改动:
(1)在代价体正则化步骤,使用序列化GRU来代替3D CNN
(2)将soft argmin 替换为Softmax,并将原始的回归问题改为多分类问题计算交叉熵损失
(3)为产生具有亚像素精度的深度估计,对初始网络得到的深度图进行变分深度图细化(Variational Depth Map Refinement)
MVSNet是该系列论文的基础,建议先理解后再看这些优化的模型,详见【论文精读1】MVSNet系列论文详解-MVSNet。
一、问题引入
基于代价体的MVS重建方法主要限制之一是可扩展性,即代价体正则化的内存消耗成本使学习MVS很难应用于高分辨率场景。
MVS(Multi-View Stereo)指的是在多个具有重叠特征的图像、且内外参数已知的情况下对三维物体或场景进行重建。
在该类问题当中,通常会根据多个图像的匹配特征来构建代价体,并将其正则化为概率体以推断深度图。而无论是传统方法,还是使用基于神经网络的学习方法,在正则化时若将整个代价体作为输入,都会遇到内存消耗随尺度增加而立方级增加的情况,针对于此,传统方法和基于学习的方法都做了一些尝试:
传统方法通常隐式的调整代价体,如
- 局部深度传播迭代细化深度图/点云
- 使用简单平面扫描顺序正则化代价体
- 具有深度赢家通吃的2D空间成本聚集
而基于学习的方法做了两种尝试:
- 如OctNet和O-CNN利用3D数据的稀疏性将八叉树结构引入到3D CNN中,但仍限于分辨率<512^3体素的重建。
- Surface Net和Deep MVS等将工程化的分而治之策略应用于MVS重建,但面临全局上下文信息丢失和速度减慢的问题。
二、模型结构
本文的核心思想是利用GRU(RNN神经网络变种),将普通正则化一次性在多个深度上进行的过程,转为逐个深度进行、并利用了上一个深度的输出(即将深度尺度看作循环神经网络的时间尺度),从而将原来D个深度样本时需要的内存T减小到了T/D(该数值仅为方便理解)。
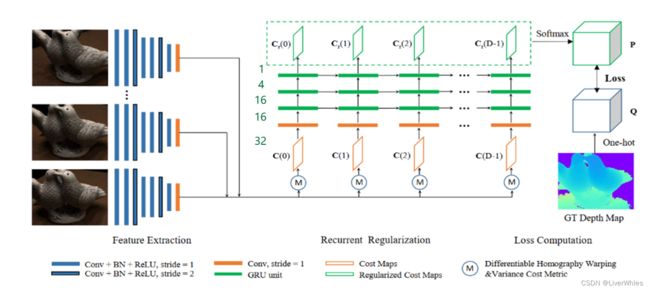
1.特征提取
与MVSNet一致
2.特征体正则化
2.1 特征图->特征体
即图中圆圈M的过程。它将N张源图像和参考图通过特征提取网络得到的N个特征图,通过深度D0对应的单应矩阵H进行变换得到N个特征体,并对这N本书(特征体)的每页(每个特征通道)上的每个特征点计算方差值,最终得到一本由方差值组成的书(代价体,即图中C0)。
该部分不理解的详见MVSNet,这是MVSNet的核心内容即可微单应变换。
2.2 特征体正则化
在正则化部分主要使用的网络结构在图中已经画出,首先是一个橙色的卷积网络来将通道数由32变为16,随后通过3层叠加的GRU分别将通道数变为16,4,1,最终输出的是一张正则化后的代价图(Cost Map),个人理解其实这时候代价图上各点的值代表了该点属于当前深度的概率值。
随后,重复2.1的过程深度计算出深度为D1时的代价体,同样输入该网络进行正则化,需要注意的是这时候在GRU层的输入不仅是该深度下的代价体,同时还利用了上一个深度D0时各GRU层的输出,即循环神经网络的思想。
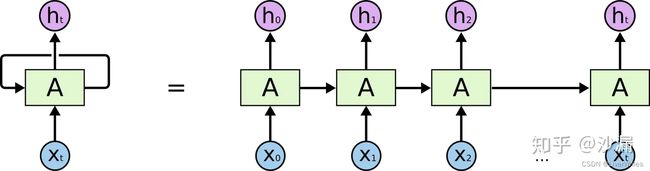
这部分是降低代价体正则化内存消耗的核心步骤,实现原因在于每次网络只对一个深度的代价体进行正则化,而非像MVSNet一样一次性对所有深度的代价体正则化,如下图所示,右边的RNN结构等同于左边,本文模型同理,即每次的内存消耗只是左边图上的一次神经网络训练消耗。
2.3 正则化代价图 -> 概率体
该部分是对MVSNet的第二个改动点,与其Soft argmin(沿深度方向求 概率*当前深度 的期望)不同,直接将各个深度正则化后的代价图(个人理解图上各点值代表该点属于当前深度的概率值)聚合成一个概率体P,并在这当中沿P的深度方向使用了Softmax,即此时各点的值沿P深度方向和为1的概率。
3.计算损失
将概率体P与真实图像所得的真实概率体Q计算交叉熵损失,即第三个改动点,将原始求概率期望的回归问题变成了一个多分类的问题。
真实概率体Q是由真实的深度图得到,具体来说深度图上各像素点都对应了一个深度值,将该深度图复制D份(深度样本数),各像素点在真实深度的那层取1,其他层取0,即一个深度方向上的One-Hot操作。
随后,对概率体P来说,深度图上的每一个点在深度方向上有D个Softmax后的概率值,即属于深度d这一“类”的概率;而真实概率体Q则相当于给出了该点所在深度“类”的标签,因此即转换为一个求交叉熵损失的多分类问题,公式如下:

三、变分深度图细化(Variational Depth Map Refinement)
该部分据论文表述是:One concern about the classification formulation is the discretized depth map output. To achieve subpixel accuracy, a variational depth map refinement algorithm is proposed in Sec. 4.2 to further refine the depth map output.,即分类方法的一个关注点是离散化的深度图输出,而为了达到亚像素精度,提出了一种变分深度图细化算法。
其实对于这个“亚像素精度”的理解还是有点模糊,是指图像亚像素点也具有对应的深度值吗?
该步骤的输入是网络得到的初始深度图,具体来讲,是对各像素点取深度值,深度值的来源是在各正则化后的Cost Map沿深度方向上观察,取概率最大的那个深度作为该点深度,进行得到一张完整的深度图。
这就是论文中所说的利用argmax的Winner-take-all(赢家通吃)策略,即直接取最有可能的那一个,而不是沿深度方向求期望等。
这也是论文提到的,在训练过程中需要计算出概率体P,但在测试时只需得到各深度下正则化后的Cost Map并使用该策略即可获取深度图。(In addition, while we need to compute the whole probability volume during training, for testing, the depth map can be sequentially retrieved from the regularized cost maps using the winner-take-all selection)
变分深度图细化的过程,其实可以看做一个对像素点不断重投影并计算、迭代减小一个特定重投影误差Error的过程,表述如下(写累了不翻译了,不过不难理解Q_Q):
Given the reference image I1, the reference depth map D1 and one source image Ii, we project Iito I1 through D1 to form the reprojected image Ii→1. The image reprojection error between I1 and Ii→1 at pixel p is defined as:
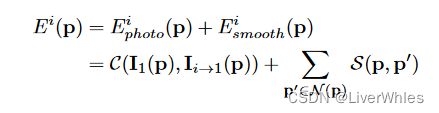
其中Ei photo 是两个像素之间的光度误差,Ei smooth 是保证深度图平滑度的正则化项。
论文用零均值归一化互相关 (ZNCC) 来测量光一致性 C(·),并使用 p 与其邻居 p’ ∈ N § 之间的双边深度平方差 S(·) 来获得平滑度。
在细化过程中,不断迭代地最小化参考图像和所有源图像之间、所有像素点的总的图像重投影误差。
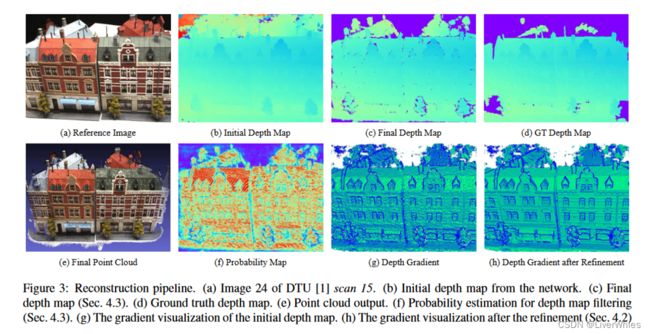
通过该过程获得了两个效果:
(1)图(g)->图(f)消除了阶梯效应(stair effect),平滑项起了作用
(2)对小范围内的深度值进行微调,达到亚像素级的深度精度
还是这个亚像素级的深度,不是很理解具体指的什么
此外论文还说It is noteworthy that the initial depth map from R-MVSNet has already achieved satisfying result.
即网络所得初始深度图就有令人满意的效果该过程只是优化来取得亚像素精度,但我寻思这个图(b)的效果和真实图(d)对比差别还是很大的吧?
四、总结
这篇R-MVSNet是Yao Yao等原班人马针对MVSNet在内存消耗上的一个改进,所以基本思想没变,主要是利用不同视角图像特征变换至同一假设深度下,通过差分来判断某特征点属于当前深度的可能性,主要是在差分后代价体正则化步骤用了RNN序列化来做,是用时间换内存空间思想的一种应用。
五、讨论
1.论文针对不同的正则化方法给出了一个描述图:

该图描述即除一次性全局正则化代价体外,几种通过深度方向顺序处理代价体的优化思路:
- 图(a)是最简单的顺序方法,即赢家通吃的平面扫描立体声,它粗略地用更好的深度值替换像素级深度值,因此会受到噪声的影响。
- 图(b)改进的代价聚合方法,在不同深度过滤匹配成本 C(d),以便为每个成本估计收集空间上下文信息。
- 图©是本项工作遵循顺序处理的思想,提出的基于卷积 GRU的更强大的循环正则化方案,能够在深度方向上收集空间以及单向上下文信息,这实现了与全空间 3D CNN相当的正则化结果,但在运行时内存中效率更高。
图a就是上文中提到过的winner-take-all原则,即在深度方向上逐个点计算,取最可能的深度值来用
图b主要增加了空间“上下文”信息,这里上下文有点歧义,其实是指空间邻域信息,而且论文中所说的“在不同深度过滤匹配成本C(d)”感觉也不对,不应该是不同深度,原文是这样的 cost aggregation methods filter the matching cost C(d) at different depths (Fig. 1 (b)) so as to gather spatial context information for each cost estimation.
图c则是本文的,逐深度来做能够考虑在深度方向、以及空间上下文的信息,并且由于每次只做一个深度层,内存消耗也是一个HxW.
图d是MVSNet为代表的直接使用3D CNN的方法,虽然直接考虑全局但由于同时操作多个深度内存消耗变为HxWxD.
个人感觉这个图画的比较复杂,但理解起来其实也怪怪的并不直观…
2.此外,论文中还提到了一个选取深度样本数D的策略——Inverse Depth,但并没有详细展开讲,之说在supplementary material里详细讲但并没有找到…
这个应该还挺重要的,因为论文中说:
Most deep stereo/MVS networks regress the disparity/depth outputs using the soft argmin operation, which can be interpreted as the expectation value along the depth direction [30]. The expectation formulation is valid if depth values are uniformly sampled within the depth range. However, in recurrent MVSNet, we apply the inverse depth to sample the depth values in order to efficiently handle reconstructions with wide depth ranges.
即沿深度求期望是当深度样本值在[Dmin,Dmax]均匀采样时才有效,但RMVSNet为了搞笑处理更广深度范围的重建而是用这个inverse depth设置,很明显不是均匀采样的,也就是关乎着单应变换时对应的具体的深度值取值的问题。
3.在训练时,论文指出
to prevent depth maps from being biased on the GRU regularization order, each training sample is passed to the network with forward GRU regularization from dmin to dmax as well as the backward regularization from dmax to dmin,
即为了防止GRU在按深度采样由小到大有偏差问题,会由大到小再训练一遍。
4.论文指出
The memory requirement of R-MVSNet is independent to the depth sample number D, which enables the network to infer depth maps with large depth range that is unable to be recovered by previous learning-based MVS methods.
即该方法的内存消耗与深度的采样数无关,这就是逐深度优化正则体的好处,但其实也就是用时间换空间。
5.对于变分深度图细化中提到的“亚像素级”这一概念,如果理解请留言…