论文阅读笔记——A deep tree-based model for software defect prediction
本论文相关内容
- 论文下载地址——Web Of Science
- 论文中文翻译——A deep tree-based model for software defect prediction
- 论文阅读笔记——A deep tree-based model for software defect prediction
文章目录
- 本论文相关内容
- 前言
- 基于DeepTree的软件缺陷预测模型
-
- 摘要
- 1 引言
- 2 动机示例
- 3 方法
- 4 模型构建
-
- 4.1 解析源代码
- 4.2 嵌入AST节点
- 4.3 缺陷预测模型
- 5 模型训练
-
- 5.1 训练树-LSTM
- 5.2 训练缺陷预测模型
- 6 评估
-
- 6.1 数据集
- 6.2 性能测试
- 6.3 结果
-
- 6.3.1 项目内预测
- 6.3.2 跨项目预测
- 6.4 有效性的威胁
- 7 相关工作
-
- 7.1 缺陷预测
- 7.2 代码建模中的深度学习
- 8 结论和未来工作
- 总结
前言
本文是A deep tree-based model for software defect prediction论文的阅读笔记,此论文使用的仍然是LSTM网络,但是其又利用了代码的AST关系树,可以更好地捕获源码中的语义关系,为缺陷预测提高准确性与说服力。本篇论文仍然是不可多得的一篇好文,给我们提供了一种对于缺陷预测的新思路和新方法。下面就是本片论文的全部核心总结内容!
基于DeepTree的软件缺陷预测模型
摘要
摘要部分内容总结为如下四点:
- 作者首先介绍了当前软件缺陷检测模型的一个很重要的特点:大多专注于设计与潜在缺陷代码相关的特性(例如复杂性度量),但是这些方法不能充分捕捉源代码的语法和不同层次的语义。
- 所以基于这个问题,本文提出了一种可以自动学习源代码的特征,结合代码的语法和语义去检测缺陷。
- 此模型建立在基于DeepTree的长短期记忆网络上,并将待检测源代码的抽象语法树与LSTM网络匹配,从而得到检测的结果。
- 最后使用来自Samsung和PROMISE提供的数据集对此模型进行评估,从而验证了此模型的有效性。
1 引言
在引言部分作者首先还是谈论了一下老生常谈的问题,就是如今软件中的缺陷对我们产生的重大影响,我们如何准确高效的识别软件中的缺陷是我们目前关注的问题。
随后作者又简单介绍了当前机器学习是如何应用到缺陷检测的。主要是从中提取特征,定义为预测因子,将其提供给例如朴素贝叶斯、支持向量机或随机森林等分类器,从而判断有无缺陷。但是这些特征都是“表面特征”,并没有从代码的语法和语义的角度出发。所以最后导致检测结果在某个特定的数据集表现良好,而换个数据集的表现可能不尽人意。另外,自然语言处理技术也被应用到源代码的缺陷检测,虽然自然语言处理技术可能在一定程度上处理代码的语法和语义之间的关系,但是并没有对代码的结构和语义进行完全编码,例如。无法识别“for”和“while”之间的语义关系。虽然检测性能有一定程度的提高,但是仍没有达到人们的预期。
针对以上问题,本文提出了一种新的基于DeepTree的缺陷预测模型。利用LSTM长短期记忆网络(可以看到,我们最近精读的论文中,都使用了这种方法,所以这种方法值得学习,最近找时间好好学一下这个算法)。捕获代码中的长期上下文关系,因为有依赖的代码关系可能分散的很远。利用抽象语法树(AST)来表示代码中的语法和不同层次的语义。所以说LSTM的网络结构也是树状的,其中一个AST节点对应于一个LSTM单元。本文所作贡献如下:
- 构建了源代码的基于DeepTree的LSTM模型。有效地保留了程序的语法和结构信息。通过AST节点嵌入机制,代码标记表示保留了它们的语义关系。
- 基于此模型,构建了一种缺陷预测系统。将表示源文件的“原始”抽象语法树作为输入,并预测该文件是否有缺陷或无缺陷。通过LSTM模型自动学习特征,从而消除了传统方法中占用大部分精力的手动特征工程的需要。
- 使用Samsung和PROMISE存储库提供的真实开源项目进行的广泛评估证明了本文缺陷预测模型的经验优势。
本文随后结构如下:
- 第2节:动机示例
- 第3节:概述本文所提出的方法
- 第4节:基于此方法构建预测模型
- 第5节:训练和实施模型
- 第6节:评估模型有效性
- 第7节:总结和相关工作
- 第8节:概述模型局限性和未来的工作
2 动机示例
下图显示了两个用Java编写的简单示例。这就是很简单的栈的弹出功能,可以看到列表1的缺陷:如果给定 s t a c k stack stack的大小小于 10 10 10,当 s t a c k stack stack为空并执行 p o p pop pop操作时,可能会发生下溢异常。而列表2通过在调用 p o p pop pop操作之前检查 s t a c k stack stack是否不是空的来纠正这个问题。

通过以上示例,可以看到现有的缺陷预测技术面临的问题:
-
类似的软件度量:两个代码列表在代码行、条件、变量、循环和分支的数量方面是相同的。所以无法将软件度量作为特征,因为我们无法判断是否有缺陷。
-
类似的代码标记和频率:此方法将术语-频率用作缺陷预测的预测因子。例如 i n t int int出现的频率。但是如上图所示:两个代码列表中的代码标记及其频率是相同的。所以我们也不能利用这个方法判断是否有缺陷。
-
句法和语义结构:我们应该如何构建分散距离较远的代码间的语义是目前面临的问题,因为代码元素不总是遵循特定的顺序,例如,在代码列表1中,可以在不改变代码行为的情况下交换第5行和第6行。
-
语义代码标记:每个代码元素都有自己的语义,而且有些代码元素在语义上是相似的,比如上述代码列表中的 w h i l e while while循环可以替换为 f o r for for循环,而不改变代码行为。而现有的方法经常忽略代码标记的那些语义。
针对以上问题,本文使用抽象语法树(AST)来表示源代码中的语法和不同层次的语义,利用基于DeepTree的LSTM神经网络,以对源代码的抽象语法树进行建模,可以有效地保留代码的语法和语义信息,从而用于缺陷检测。
3 方法
最终训练出来的模型返回值还是和之前一样:1表示有缺陷,0表示无缺陷。也就是二分类分类函数 p r e d i c t ( x ) predict(x) predict(x)。
此模型基于长短期记忆网络,但是此模型为LSTM单元的树状结构网络,可以高效的反应源码中的语法和多层次语义。不仅可以在项目内预测还可以跨项目预测缺陷。此模型的关键步骤如下所示:
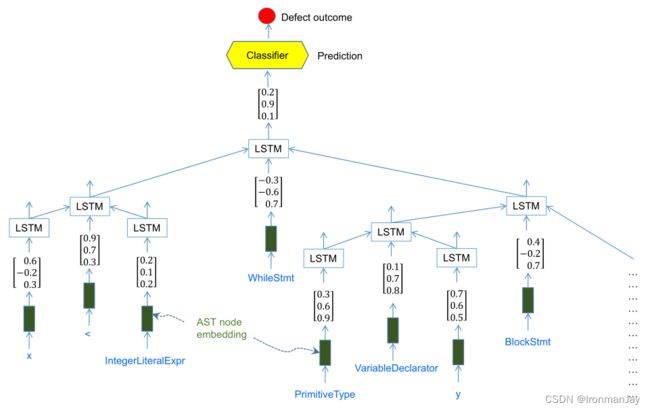
具体包括三个主要步骤:
- 将源代码文件解析为抽象语法树
- 将AST节点映射到称为嵌入的连续值向量
- 将AST嵌入输入到基于树的LSTM网络,以获得整个AST的矢量表示。将该向量输入到传统分类器(如Logistic回归或随机森林),以预测缺陷结果
4 模型构建
4.1 解析源代码
在将源代码解析为抽象语法树(AST)时,对以下内容忽略:
- 注释
- 空行
- 分隔符(例如大括号、分号和括号)
对于如何解析源代码可见下图。其中AST的根表示一个完整的源文件,如图中的 w h i l e while while循环,循环内部元素和判断条件都作为子节点出现,其中要注意常量整数、实数、指数表示法、十六进制数和字符串表示为其类型的AST节点,而不是其本身,例如下图中的整数 10 10 10表示为 I n t e g e r L i t e r a l E x p r IntegerLiteralExpr IntegerLiteralExpr节点。
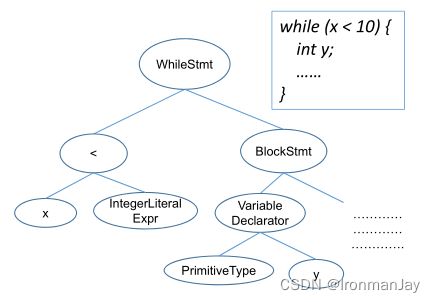
按照此标准对语料库中的所有源代码构建为AST树,从而形成词汇表。固定大小的词汇表 V \mathscr{V} V基于出现次数前 N N N个(流行)的标记构建,将出现次数少(不流行)的标记分配给 ⟨ u n k ⟩ ⟨unk⟩ ⟨unk⟩。
4.2 嵌入AST节点
因为LSTM单元只接受向量,所以要将每个AST节点映射为固定长度的连续向量,此嵌入过程称为 a s t 2 v e c ast2vec ast2vec。此过程需要使用到嵌入矩阵:
M ∈ R d × ∣ V ∣ \mathcal{M} \in \mathbb{R}^{d \times|\mathscr{V}|} M∈Rd×∣V∣
- d d d是AST节点嵌入向量的大小
- ∣ V ∣ |\mathscr{V}| ∣V∣是词汇表 V \mathscr{V} V的大小
- AST节点标签 i t h i^{t h} ith被映射到矩阵 M \mathcal{M} M中的列向量 i t h i^{t h} ith
可见图2, W h i l e S t m t WhileStmt WhileStmt节点被嵌入到向量 [ − 0.3 , − 0.6 , 0.7 ] [−0.3, −0.6,0.7] [−0.3,−0.6,0.7]中,而 I n t e g e r L i t e r a l E x p r IntegerLiteralExpr IntegerLiteralExpr映射到向量 [ 0.2 , 0.1 , 0.2 ] [0.2,0.1,0.2] [0.2,0.1,0.2]中。此过程包括两个优点:
- 嵌入向量的维数低于一个热向量(即 d < ∣ V ∣ d<|\mathscr{V}| d<∣V∣)
- 具有相似语义的代码元素距离很近
4.3 缺陷预测模型
缺陷预测的过程可见如下算法:

-
将源文件解析为AST(第2行)
-
将AST的根传入LSTM网络获得向量表示 h root \boldsymbol{h}_{\text {root }} hroot (第 3 3 3行)
-
将此向量传入到传统分类器,得到源文件有缺陷的概率(第4行)
- 如果概率不小于0.5:返回1,表示有缺陷(第5-6行)
- 如果概率小于0.5:返回0,表示无缺陷(第7-8行)
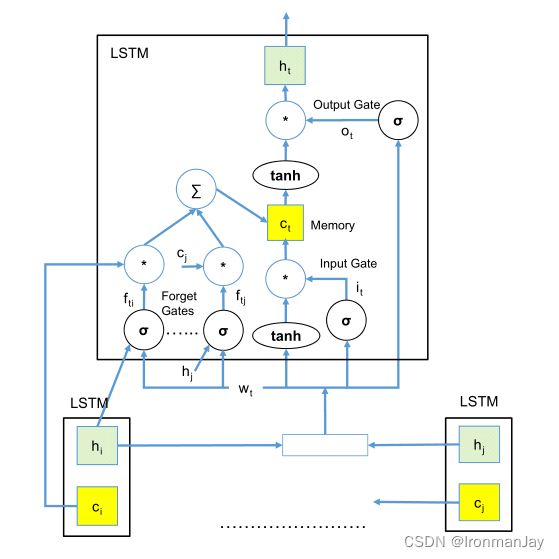
其中的核心步骤为函数 t − l s t m ( ) t-lstm() t−lstm(),此过程的关键步骤可见下图:
-
获取AST节点 t t t的嵌入 w t \boldsymbol{w}_{t} wt,使用 a s t 2 v e c ast2vec ast2vec(第12行)
-
获取节点 t t t的所有子节点 C ( t ) C(t) C(t)(第13行)
-
每个子节点 k ∈ C ( t ) k∈ C(t) k∈C(t)被馈入LSTM单元以获得每个子节点的一对隐藏输出状态和上下文向量 ( h k , c k ) \left(\boldsymbol{h}_{k}, \boldsymbol{c}_{k}\right) (hk,ck)(第14行)
-
利用以上信息计算父节点的一对隐藏输出状态和上下文向量 ( h k , c k ) \left(\boldsymbol{h}_{k}, \boldsymbol{c}_{k}\right) (hk,ck)(第16行)
需要注意的是,一个LSTM单元由输入门(表示为 i t \boldsymbol{i}_{t} it)、输出门( o t \boldsymbol{o}_{t} ot)和多个遗忘门(每个子节点 k k k的一个 f t k \boldsymbol{f}_{tk} ftk)构成,其中的参数意义如下所示:
- ( W f o r W_{for} Wfor、 U f o r U_{for} Ufor、 b f o r b_{for} bfor)用于遗忘门
- ( W i n W_{in} Win、 U i n U_{in} Uin、 b i n b_{in} bin)用于输入门
- ( W o u t W_{out} Wout、 U o u t U_{out} Uout、 b o u t b_{out} bout)用于输出门
之后就要利用以上信息计算父节点的一对隐藏输出状态和上下文向量 ( h k , c k ) \left(\boldsymbol{h}_{k}, \boldsymbol{c}_{k}\right) (hk,ck):
- 使用 s i g m o i d sigmoid sigmoid函数计算子节点 k k k的遗忘门,遗忘门 f t k \boldsymbol{f}_{tk} ftk的值介于0和1之间(第17行)
- 将子节点的最终输出组合起来作为父-LSTM单元的输入(第19行)
- 利用 s i g m o i d sigmoid sigmoid函数计算输入门 i k \boldsymbol{i}_{k} ik(第20行)
- 使用 t a n h tanh tanh函数创建一个新的候选值 c t ~ \tilde{\boldsymbol{c}_{t}} ct~的向量(第21行)
- 将每个孩子的旧记忆乘以 f t k \boldsymbol{f}_{tk} ftk来更新新记忆,然后对所有子节点求和,之后将其与第3步和第4步计算的数据相加的数据存入存储单元中(第22行)
- 使用 s i g m o i d sigmoid sigmoid函数得到输出门 o t \boldsymbol{o}_{t} ot的数据(第23行)
- 使用 t a n h tanh tanh函数将存储单元的值缩放到-1和1之间,并乘以 s i g m o i d sigmoid sigmoid门的输出,最终得到隐藏输出状态 h k \boldsymbol{h}_{k} hk(第24行)
- 最后返回父节点的一对隐藏输出状态和上下文向量 ( h k , c k ) \left(\boldsymbol{h}_{k}, \boldsymbol{c}_{k}\right) (hk,ck)(第25行)
5 模型训练
5.1 训练树-LSTM
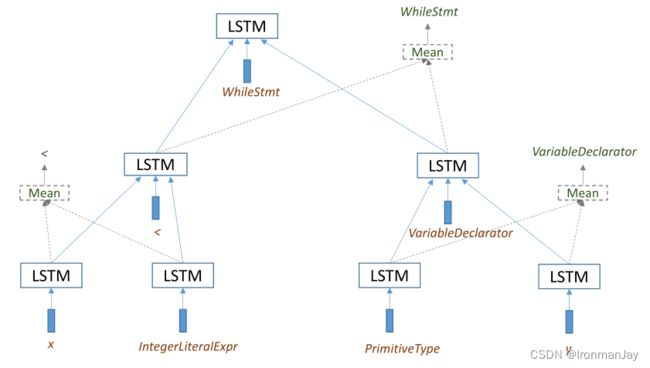
使用无监督学习方式训练树-LSTM单元,利用子代的标签名称预测父代的标签名称。比如“<”和“VariableDeclarator”的父级是“WhileStmt”,而“x”和“IntegerLiteralExpr”的父亲是“<”。
在补充一下有监督学习和无监督学习的概念:
- 有监督学习: 指数据的输入和输出已知,也就是事先知道输入和输出之间的关系,有监督学习算法就是要发现和总结这种“关系”。
- 无监督学习:无监督学习是指对无标签数据的一类学习算法,也就是说事先并不知道输入和输出之间的关系。因为没有标签信息,意味着需要从数据集中发现和总结模式或者结构。
利用AST节点的 w t \boldsymbol{w}_{t} wt的每个子节点 c k ∈ C ( t ) c_{k}∈ C(t) ck∈C(t)的输出状态 h k h_{k} hk和以下公式来预测父节点的标签名称:
P ( w t = w ∣ w c 1.. c k ) = exp ( U t h ~ t ) ∑ w ′ exp ( U w ′ h ~ t ) P\left(w_{t}=w \mid w_{c 1 . . c k}\right)=\frac{\exp \left(U_{t} \tilde{h}_{t}\right)}{\sum_{w^{\prime}} \exp \left(U_{w^{\prime}} \tilde{h}_{t}\right)} P(wt=w∣wc1..ck)=∑w′exp(Uw′h~t)exp(Uth~t)
其中 U k U_k Uk是一个自由参数并且 h ~ t = 1 ∣ C ( t ) ∣ ∑ k = 1 ∣ C ( t ) ∣ h k \tilde{h}_{t}=\frac{1}{|C(t)|} \sum_{k=1}^{|C(t)|} h_{k} h~t=∣C(t)∣1∑k=1∣C(t)∣hk
后面的工作就是随机初始化参数进行模型的训练,我们需要随机初始化的参数包括:嵌入矩阵 M \mathcal{M} M和权重矩阵( W f o r W_{for} Wfor、 U f o r U_{for} Ufor、 b f o r b_{for} bfor)、( W i n W_{in} Win、 U i n U_{in} Uin、 b i n b_{in} bin)、( W c e W_{ce} Wce、 U c e U_{ce} Uce、 b c e b_{ce} bce)和( W o u t W_{out} Wout、 U o u t U_{out} Uout、$ b_{out}$)。训练过程具体分为三步:
- 将训练数据中的AST分支输入到LSTM单元,以获得该分支中父节点的标签名称的预测
- 比较预测结果和实际结果之间的差值 δ δ δ
- 调整模型参数的值,使得差值 δ δ δ最小化。此过程对训练数据中的所有文件进行迭代
为了使模型训练精度提高,作者定义损失函数 L ( θ ) L(θ) L(θ),如何将损失函数 L ( θ ) L(θ) L(θ)的值降到最小呢?本文为了解决这个问题采用了RMSprop梯度下降方法与反向传播,在训练的过程中需要注意:
- 模型参数 θ θ θ沿损失函数 L ( θ ) L(θ) L(θ)梯度的相反方向更新
- 学习速率 η η η用于控制我们朝着最佳参数前进的快慢
为了防止过拟合,本方法还采用了dropout机制,最终确定了dropout率设置为0.5,也就是说:在前向传播的时候,让某个神经元的激活值以0.5的概率停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。最终使用困惑度来作为选择最佳模型和提前停止的评估指标。
在这里补充困惑度的概念:困惑度是用来衡量语言概率模型优劣的一个方法,困惑度越小,我们想要的句子出现的概率越大,语言模型越好。假设 W = w 1 w 2 . . . w N W=w_{1}w_{2}...w_{N} W=w1w2...wN为测试集,困惑度的计算公式如下所示:
PP ( W ) = P ( w 1 w 2 … w N ) − 1 N = 1 P ( w 1 w 2 … w N ) N = ∏ i = 1 N 1 P ( w i ∣ w 1 … w i − 1 ) N = ∏ i = 1 N 1 P ( w i ∣ w i − 1 ) N \begin{aligned}\operatorname{PP}(W) &=P\left(w_{1} w_{2} \ldots w_{N}\right)^{-\frac{1}{N}} \\&=\sqrt[N]{\frac{1}{P\left(w_{1} w_{2} \ldots w_{N}\right)}} \\&=\sqrt[N]{\prod_{i=1}^{N} \frac{1}{P\left(w_{i} \mid w_{1} \ldots w_{i-1}\right)}} \\&=\sqrt[N]{\prod_{i=1}^{N} \frac{1}{P\left(w_{i} \mid w_{i-1}\right)}}\end{aligned} PP(W)=P(w1w2…wN)−N1=NP(w1w2…wN)1=Ni=1∏NP(wi∣w1…wi−1)1=Ni=1∏NP(wi∣wi−1)1
- W W W表示某句代码
- N N N为某句代码长度
- P ( w i ∣ w i − 1 ) P(w_i|w_{i-1}) P(wi∣wi−1)是某句代码中第 i i i个词在第 i − 1 i-1 i−1个词的条件下的概率
5.2 训练缺陷预测模型
通过以上过程已经可以自动为训练集中的所有源文件生成特征。然后使用这些特征训练分类器,从而得到缺陷预测模型,在这里选择Logistic回归和随机森林作为分类器,最终可以通过分类器的到缺陷预测结果。
6 评估
6.1 数据集
本文所使用的数据集分别来自Samsung贡献的开源项目和PROMISE数据集。
- Samsung贡献的开源项目:作者建立了一个由8118个用C语言编写的文件组成的数据集,其中2887个(35.6%)文件被标记为有缺陷,5231个(64.4%)被标记为无缺陷。
- PROMISE数据集:作者在此数据集中删除了一些“垃圾”条目,最终整理的数据集统计如下所示:
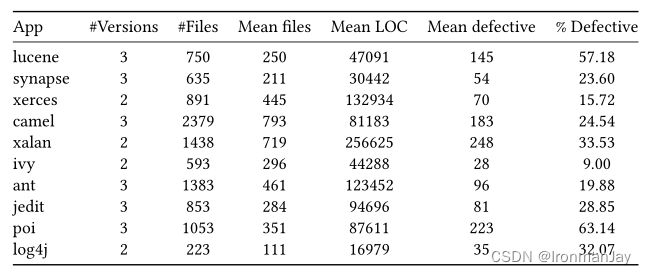
6.2 性能测试
需要了解的是,本文的数据集有缺陷的文件数量较少,导致数据集不平衡,所以最终评估的重点集中在缺陷类,因为预测有缺陷的文件更有意义。评测性能时我们要明白几个概念:
- 真阳性( t p tp tp):文件在确实有缺陷时被分类为有缺陷
- 假阳性( f p fp fp):文件在实际无缺陷时被分类为有缺陷
- 假阴性( f n fn fn):文件在实际有缺陷时被分类为无缺陷
- 真阴性( t n tn tn):文件在实际无缺陷时被分类为无缺陷
有了以上基本概念后,本文提出了以下四种评测指标用于评价最终训练出的模型的性能:
- 准确度:正确预测的缺陷文件与所有预测为缺陷的文件的比率。计算如下:
p r = t p t p + f p p r=\frac{t p}{t p+f p} pr=tp+fptp
- 召回率:正确预测的缺陷文件与所有真实缺陷文件的比率。计算如下:
r e = t p t p + f n r e=\frac{t p}{t p+f n} re=tp+fntp
- F-度量:测量准确度和召回率的加权调和平均值。计算如下:
F − measure = 2 ∗ p r ∗ r e p r + r e F-\text { measure }=\frac{2 * p r * r e}{p r+r e} F− measure =pr+re2∗pr∗re
- ROC曲线下面积(AUC)用于评估模型实现的辨别程度。AUC的值范围从0到1,随机预测的AUC为0.5。AUC的优点是它对决策阈值(如准确度和召回率)不敏感。AUC越高表示预测越好。
6.3 结果
6.3.1 项目内预测
对于同一Samsung项目数据集的训练和测试的性能如下所示,使用Logistic回归和随机森林作为分类器。可以看到使用随机森林(RF)作为分类器的四个性能指标都远高于0.9,而使用Logistic回归(LR)实现了非常高的召回率,两种分类器的AUC均远高于0.5阈值(RF为0.98,RF为0.60)。这表明了本文提出的模型性能较好。
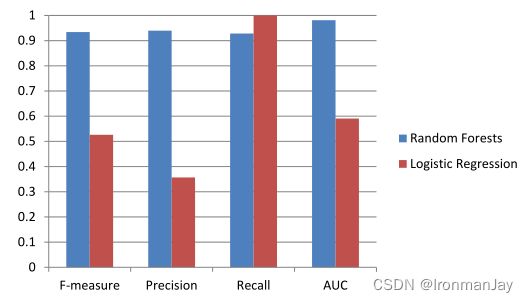
对于只使用Logistic回归(LR)作为分类器在Samsung数据集的不同数据上进行的测试性能结果如下所示,可以看到此方法在每个数据集上的召回率都是较高的。作者也提出:在预测缺陷时,高召回率通常是优选的,因为遗漏缺陷的成本远高于误报。
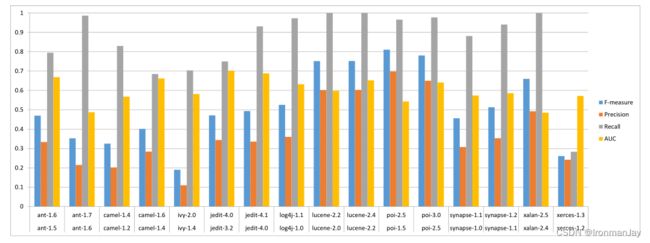
6.3.2 跨项目预测
对于跨项目预测的性能测试结果如下所示,可以看到22个案例的平均召回率为0.8,有15例召回率高于0.8,平均F-度量为0.5,平均AUC仍远高于0.5阈值。证明了本文提出的方法在预测缺陷方面的总体有效性。
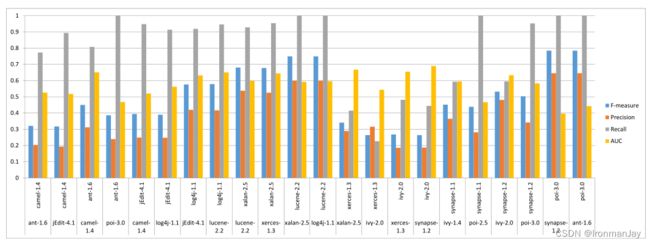
6.4 有效性的威胁
在模型的测试阶段,遇到以下几方面问题:
- PROMISE数据集不包含源文件
- Samsung数据集的警告可能包含误报
- 没有源代码来复制其他人的实验
- 本文使用的数据集可能不能代表所有类型的软件应用程序
这些问题都对本文提出的模型的有效性有一定的影响,当然,这也是未来要解决的问题。
7 相关工作
7.1 缺陷预测
在此部分作者总结了目前缺陷检测的一些研究,尤其是在关于缺陷检测的特征方面所做的研究内容,比如静态代码特征和过程特征
静态代码特征又可以细分为代码大小和代码复杂度,其中代码复杂度包括:
- Halstead特性
- McAbe特性
- CK特性
- MOOD特性
过程特征是指测量发布开发过程中的更改活动,以便构建更准确的缺陷预测模型。
同时作者对于项目内预测和跨项目预测也做了简要总结,这对未来的研究工作也十分重要
- 项目内预测使用来自同一项目的数据来构建模型
- 跨项目预测使用其他项目的历史数据来训练模型
同时作者介绍了一种称为深度信念网络(DBN)的深度学习模型来自动学习缺陷预测的特征,虽然对于预测的性能有所改进,并且DBN方法优于软件度量和单词包方法。但是DBN不能自然地捕获源代码中的顺序排列和长期依赖关系,这也导致对预测的准确性有一定的影响。为了解决这个问题可以开发包含带有缺陷标签的方法和代码行的新数据集,这也指明了未来的工作方向。
7.2 代码建模中的深度学习
在此部分作者主要说明了深度学习应用于软件缺陷检测的研究进展和前景,同时介绍了一些方法,比如:
- 基于LSTM的通用深度学习框架
- 递归神经网络(RNN)
- RNN编码器-解码器
- 卷积神经网络(CNN)
以上方法都可以应用到软件缺陷检测,但是经过作者的工作表明,LSTM是一种更有效的软件缺陷检测模型。
8 结论和未来工作
本文中作者提出了一种新的模型,将源代码表示为抽象语法树(AST)作为长短期记忆(LSTM)网络的输入,再经过传统分类器进行分类以得到软件缺陷预测结果。同时使用Samsung和PROMISE两个不同的数据集对此模型进行性能评估,评测结果表示此模型性能良好,可以应用于实践。本论文所做的贡献包括:
- 可以高效的捕获代码元素之间经常存在的长期依赖关系
- 使用树结构LSTM网络(Tree-LSTM),自然地与AST表示相匹配,从而充分地捕获了源代码中的语法和不同级别的语义
- 特征通过训练Tree-LSTM模型自动学习,省去了传统方法中需要人工进行特征工程的大部分工作
同时作者也指明了未来工作的方向:
- 将本方法应用于其他类型的应用程序(例如Web应用程序)和编程语言(例如PHP或C++)
- 扩展此方法,以预测方法和代码更改级别的缺陷
- 将此方法扩展到预测特定类型的缺陷,如代码中的安全漏洞和安全关键危害
- 将此预测模型构建成一个工具,该工具可用于支持现实环境中的软件工程师和测试人员
总结
以上就是本篇阅读笔记的全部内容。本文使用源代码的抽象语法树(AST)结合长短期记忆(LSTM)网络的方法解决软件缺陷预测问题。基本思路就是将源代码表示为抽象语法树(AST)作为长短期记忆(LSTM)网络的输入,再经过传统分类器进行分类以得到软件缺陷预测结果。
本文所提出的方法优点包括:
- 可以高效的捕获代码之间的依赖关系
- 充分的捕获代码中的语法和语义
- 节省了人类专家在定义代码特征上的巨大工作量
- 提高了软件缺陷预测的准确度
本文所提出的方法缺点包括:
- 当前的模型还不能应用于其他语言(比如C++或PHP)
- 目前模型只在两个不平衡的数据集上进行了性能检测
- 此方法还不能使用在Web应用程序