Frustum PointNets for 3D Object Detection from RGB-D Data 原文 + 阅读笔记
Abstract
In this work, we study 3D object detection from RGB-D data in both indoor and outdoor scenes. While previous methods focus on images or 3D voxels, often obscuring natural 3D patterns and invariances of 3D data, we directly operate on raw point clouds by popping up RGB-D scans. However, a key challenge of this approach is how to efficiently localize objects in point clouds of large-scale scenes (region proposal). Instead of solely relying on 3D proposals, our method leverages both mature 2D object detectors and advanced 3D deep learning for object localization, achieving efficiency as well as high recall for even small objects. Benefited from learning directly in raw point clouds, our method is also able to precisely estimate 3D bounding boxes even under strong occlusion or with very sparse points. Evaluated on KITTI and SUN RGB-D 3D detection benchmarks, our method outperforms the state of the art by remarkable margins while having real-time capability.
之前方法的不足/局限:通常的三维目标(用图像获得,3D体素)检测方法忽略了3D目标的自然状态和3D数据的不变性;
论文中所采用的主要方法:直接在原始点云上操作
该方法应用上的主要难点:怎样在一个较大的场景点云表示中高效地定位三维目标
论文中方法的优越性:达到了对目标的高效定位,并且对很小的目标也有很高的回调率(recall);即使在强遮挡和点云十分稀疏的情况下,也能够准确地估计出3D bounding box;具有很好的实时性
1. Introduction
Recently, great progress has been made on 2D image understanding tasks, such as object detection [10] and instance segmentation [11]. However, beyond getting 2D bounding boxes or pixel masks, 3D understanding is eagerly in demand in many applications such as autonomous driving and augmented reality (AR). With the popularity of 3D sensors deployed on mobile devices and autonomous vehicles, more and more 3D data is captured and processed. In this work, we study one of the most important 3D perception tasks – 3D object detection, which classifies the object category and estimates oriented 3D bounding boxes of physical objects from 3D sensor data.
背景:2维图像理解方面工作的进展飞速,3维理解方面的工作在许多应用领域如自动驾驶和AR方面也是迫切需要。
前提:3D sensor提供了大量可供处理的三维数据
While 3D sensor data is often in the form of point clouds, how to represent point cloud and what deep net architectures to use for 3D object detection remains an open problem. Most existing works convert 3D point clouds to images by projection [30, 21] or to volumetric grids by quantization [33, 18, 21] and then apply convolutional networks. This data representation transformation, however, may

obscure natural 3D patterns and invariances of the data. Recently, a number of papers have proposed to process point clouds directly without converting them to other formats. For example, [20, 22] proposed new types of deep net architectures, called PointNets, which have shown superior performance and efficiency in several 3D understanding tasks such as object classification and semantic segmentation.
While PointNets are capable of classifying a whole point cloud or predicting a semantic class for each point in a point cloud, it is unclear how this architecture can be used for instance-level 3D object detection. Towards this goal, we have to address one key challenge: how to efficiently propose possible locations of 3D objects in a 3D space. Imitating the practice in image detection, it is straightforward to enumerate candidate 3D boxes by sliding windows [7] or by 3D region proposal networks such as [27]. However, the computational complexity of 3D search typically grows cubically with respect to resolution and becomes too expensive for large scenes or real-time applications such as autonomous driving.
Instead, in this work, we reduce the search space following the dimension reduction principle: we take the advantage of mature 2D object detectors (Fig. 1). First, we extract the 3D bounding frustum of an object by extruding 2D bounding boxes from image detectors. Then, within the 3D space trimmed by each of the 3D frustums, we consecutively perform 3D object instance segmentation and amodal 3D bounding box regression using two variants of PointNet. The segmentation network predicts the 3D mask of the object of interest (i.e. instance segmentation); and the regression network estimates the amodal 3D bounding box (covering the entire object even if only part of it is visible).
之前相关工作中对于三维点云的处理方法:
投影/通过quantization得到体积网络 -> 应用CNN
问题:没有充分体现3D目标的自然状态,和3D数据的不变性
直接处理3D点云的方法:PointNet
在该研究方向上的局限/问题:对于是否能应用于instance-level的3D目标检测尚不明确
针对传统方法的高计算复杂度的问题:
本文中降低搜索区域的方法:
1)通过2D目标检测,提取3D的目标锥形点云区域;
2)两个变化的PointNet网络模型实现分割和目标检测;分割网络实现实例分割,回归网络估计目标的三维框的位置;
由于投影矩阵是已知的,这样就可以从二维图像区域得到三维截锥了.
In contrast to previous work that treats RGB-D data as 2D maps for CNNs, our method is more 3D-centric as we lift depth maps to 3D point clouds and process them using 3D tools. This 3D-centric view enables new capabilities for exploring 3D data in a more effective manner. First, in our pipeline, a few transformations are applied successively on 3D coordinates, which align point clouds into a sequence of more constrained and canonical frames. These alignments factor out pose variations in data, and thus make 3D geometry pattern more evident, leading to an easier job of 3D learners. Second, learning in 3D space can better exploits the geometric and topological structure of 3D space. In principle, all objects live in 3D space; therefore, we believe that many geometric structures, such as repetition, planarity, and symmetry, are more naturally parameterized and captured by learners that directly operate in 3D space. The usefulness of this 3D-centric network design philosophy has been supported by much recent experimental evidence.
Our method achieves leading positions on KITTI 3D object detection [1] and bird’s eye view detection [2] benchmarks. Compared with the previous state of the art [5], our method is 8.04% better on 3D car AP with high efficiency (running at 5 fps). Our method also fits well to indoor RGB-D data where we have achieved 8.9% and 6.4% better 3D mAP than [13] and [24] on SUN-RGBD while running one to three orders of magnitude faster. The key contributions of our work are as follows:
- We propose a novel framework for RGB-D data based 3D object detection called Frustum PointNets.
- We show how we can train 3D object detectors under our framework and achieve state-of-the-art performance on standard 3D object detection benchmarks.
- We provide extensive quantitative evaluations to validate our design choices as well as rich qualitative results for understanding the strengths and limitations of our method
论文的主要工作:
- 使用2D目标检测器检测结果,生成对应的3D的平头锥形区域实现目标检测
- 从原始点云中直接分割出3D目标的mask和回归3D bounding box
- 该方法具有较高的检测精度和较高的执行效率
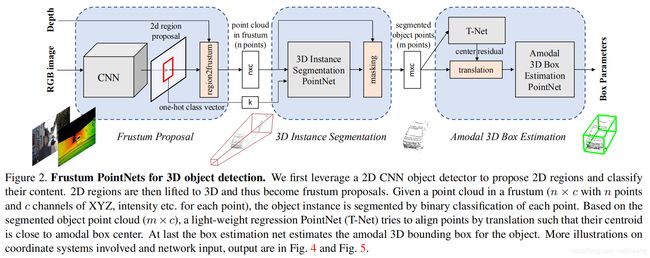
2. Related Work
3D Object Detection from RGB-D Data Researchers have approached the 3D detection problem by taking various ways to represent RGB-D data.
- Front view image based methods:* [3, 19, 34] take monocular RGB images and shape priors or occlusion patterns to infer 3D bounding boxes. [15, 6] represent depth data as 2D maps and apply CNNs to localize objects in 2D image. In comparison we represent depth as a point cloud and use advanced 3D deep networks (PointNets) that can exploit 3D geometry more effectively.
- Bird’s eye view based methods:* MV3D [5] projects LiDAR point cloud to bird’s eye view and trains a region proposal network (RPN [23]) for 3D bounding box proposal. However, the method lags behind in detecting small objects, such as pedestrians and cyclists and cannot easily adapt to scenes with multiple objects in vertical direction.
- 3D based methods:* [31, 28] train 3D object classifiers by SVMs on hand-designed geometry features extracted from point cloud and then localize objects using sliding-window search. [7] extends [31] by replacing SVM with 3D CNN on voxelized 3D grids. [24] designs new geometric features for 3D object detection in a point cloud. [29, 14] convert a point cloud of the entire scene into a volumetric grid and use 3D volumetric CNN for object proposal and classification. Computation cost for those method is usually quite high due to the expensive cost of 3D convolutions and large 3D search space. Recently, [13] proposes a 2D-driven 3D object detection method that is similar to ours in spirit. However, they use hand-crafted features (based on histogram of point coordinates) with simple fully connected networks to regress 3D box location and pose, which is sub-optimal in both speed and performance. In contrast, we propose a more flexible and effective solution with deep 3D feature learning (PointNets).
Deep Learning on Point Clouds Most existing works convert point clouds to images or volumetric forms before feature learning. [33, 18, 21] voxelize point clouds into volumetric grids and generalize image CNNs to 3D CNNs. [16, 25, 32, 7] design more efficient 3D CNN or neural network architectures that exploit sparsity in point cloud. However, these CNNs based methods still require quantization of point clouds with certain voxel resolution. Recently, a few works [20, 22] propose a novel type of network architectures (PointNets) that directly consumes raw point clouds without converting them to other formats. While PointNets have been applied to single object classification and semantic segmentation, our work explores how to extend the architecture for the purpose of 3D object detection.
3. Problem Definition
Given RGB-D data as input, our goal is to classify and localize objects in 3D space. The depth data, obtained from LiDAR or indoor depth sensors, is represented as a point cloud in RGB camera coordinates. The projection matrix is also known so that we can get a 3D frustum from a 2D image region. Each object is represented by a class (one among k predefined classes) and an amodal 3D bounding box. The amodal box bounds the complete object even if part of the object is occluded or truncated. The 3D box is parameterized by its size h, w, l, center cx, cy, cz, and orientation θ, φ, ψ relative to a predefined canonical pose for each category. In our implementation, we only consider the heading angle θ around the up-axis for orientation.
4. 3D Detection with Frustum PointNets
As shown in Fig. 2, our system for 3D object detection consists of three modules: frustum proposal, 3D instance segmentation, and 3D amodal bounding box estimation. We will introduce each module in the following subsections. We will focus on the pipeline and functionality of each module and refer readers to supplementary for specific architectures of the deep networks involved.
整个结构包含的三个步骤(模块):
1)锥形建议区域;2)3D实例分割;3)3D模态目标估计;
4.1. Frustum Proposal
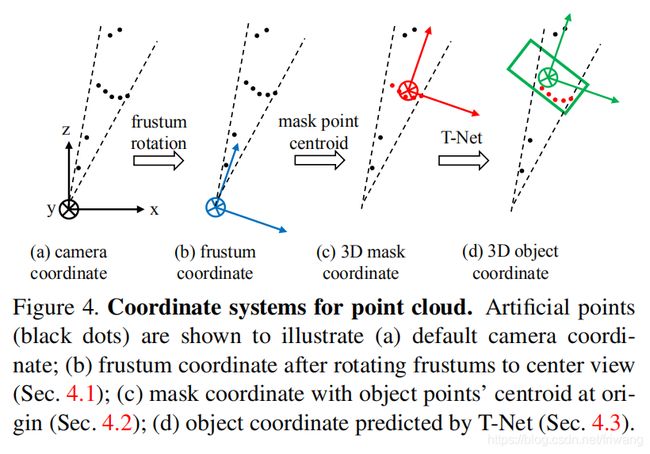
The resolution of data produced by most 3D sensors, especially real-time depth sensors, is still lower than RGB images from commodity cameras. Therefore, we leverage mature 2D object detector to propose 2D object regions in RGB images as well as to classify objects. With a known camera projection matrix, a 2D bounding box can be lifted to a frustum (with near and far planes specified by depth sensor range) that defines a 3D search space for the object. We then collect all points within the frustum to form a frustum point cloud. As shown in Fig 4 (a), frustums may orient towards many different directions, which result in large variation in the placement of point clouds. We therefore normalize the frustums by rotating them toward a center view such that the center axis of the frustum is orthogonal to the image plane. This normalization helps improve the rotation-invariance of the algorithm. We call this entire procedure for extracting frustum point clouds from RGB-D data frustum proposal generation. While our 3D detection framework is agnostic to the exact method for 2D region proposal, we adopt a FPN [17] based model. We pre-train the model weights on ImageNet classification and COCO object detection datasets and further fine-tune it on a KITTI 2D object detection dataset to classify and predict amodal 2D boxes. More details of the 2D detector training are provided in the supplementary.
解读:
大概思路:
当下3D传感器,尤其是实时的深度传感器,所能够提供的数据的分辨率仍然低于商业相机所拍摄的RGB图像 -> 因此,首先利用成熟的二维目标检测器来得到RGB图像中大概的目标区域并对目标进行分类
方法可行性:
给定一个已知的相机投影矩阵,一个二维的区域就可以转换程一个三维的平头锥形区域,该区域就决定了对该目标的三维搜索空间 -> 采集该区域内的所有点得到一个平头锥点云(frustum point cloud)
一些问题:
平头锥区域可能有很多不同的朝向 -> 点云的位置可能发生很大的变化
解决方案:
将圆台旋转到一个中心视图,使圆台的中心轴垂直于图像平面,从而将圆台标准化 -> 提升了目标的旋转不变性(原因:多种目标旋转过来进行学习,测试过程中能够检测来自多个方向)

4.2. 3D Instance Segmentation
Given a 2D image region (and its corresponding 3D frustum), several methods might be used to obtain 3D location of the object: One straightforward solution is to directly regress 3D object locations (e.g., by 3D bounding box) from a depth map using 2D CNNs. However, this problem is not easy as occluding objects and background clutter is common in natural scenes (as in Fig. 3), which may severely distract the 3D localization task. Because objects are naturally separated in physical space, segmentation in 3D point cloud is much more natural and easier than that in images where pixels from distant objects can be near-by to each other. Having observed this
fact, we propose to segment instances in 3D point cloud instead of in 2D image or depth map. Similar to Mask-RCNN [11], which achieves instance segmentation by binary classification of pixels in image regions, we realize 3D instance segmentation using a PointNet-based network on point clouds in frustums. Based on 3D instance segmentation, we are able to achieve residual based 3D localization. That is, rather than regressing the absolute 3D location of the object whose offset from the sensor may vary in large ranges (e.g. from 5m to beyond 50m in KITTI data), we predict the 3D bounding box center in a local coordinate system – 3D mask coordinates as shown in Fig. 4 ©.
3D Instance Segmentation PointNet. The network takes a point cloud in frustum and predicts a probability score for each point that indicates how likely the point belongs to the object of interest. Note that each frustum contains exactly one object of interest. Here those “other” points could be points of non-relevant areas (such as ground, vegetation) or other instances that occlude or are behind the object of interest. Similar to the case in 2D instance segmentation, depending on the position of the frustum, object points in one frustum may become cluttered or occlude points in another. Therefore, our segmentation PointNet is learning the occlusion and clutter patterns as well as recognizing the geometry for the object of a certain category. In a multi-class detection case, we also leverage the semantics from a 2D detector for better instance segmentation. For example, if we know the object of interest is a pedestrian, then the segmentation network can use this prior to find geometries that look like a person. Specifically, in our architecture we encode the semantic category as a one-hot class vector (k dimensional for the pre-defined k categories) and concatenate the one-hot vector to the intermediate point cloud features. More details of the specific architectures are described in the supplementary. After 3D instance segmentation, points that are classified as the object of interest are extracted (“masking” in Fig. 2).
Having obtained these segmented object points, we further normalize its coordinates to boost the translational invariance of the algorithm, following the same rationale as in the frustum proposal step. In our implementation, we transform the point cloud into a local coordinate by subtracting XYZ values by its centroid. This is illustrated in Fig. 4 ©. Note that we intentionally do not scale the point cloud, because the bounding sphere size of a partial point cloud can be greatly affected by viewpoints and the real size of the point cloud helps the box size estimation. In our experiments, we find that coordinate transformations such as the one above and the previous frustum rotation are critical for 3D detection result as shown in Tab. 8.
解读:
之前的一些方法:
使用2D的CNN直接从深度图中回归得到3D目标的位置(比如通过一个3D包围框)
之前方法存在的问题:
考虑到在自然场景中遮挡和杂乱的背景是很常见,而这可能会对3D定位造成比较严重的干扰。
论文中所用的方法:
利用基于PointNet的网络结构直接对上一步中得到的平头锥点云进行实例分割, 在得到这些分割的目标点后,进一步对其坐标进行归一化,以提高算法的平移不变性。
方法可行性/正确性:
由于物体在物理空间中是自然分离的,而在二维图像中,代表来自距离很远的两个物体的像素却有可能离得很近 -> 因此在三维点云中直接进行实例分割而不是在二维图像上操作会更加容易

4.3. Amodal 3D Box Estimation
Given the segmented object points (in 3D mask coordinate), this module estimates the object’s amodal oriented 3D bounding box by using a box regression PointNet together with a preprocessing transformer network.
解读:得到经由实例分割得来的点云,该模块主要通过利用一个box regression PointNet 和一个预处理的迁移网络来估计目标物体的定向3D边界框
Learning-based 3D Alignment by T-Net Even though we have aligned segmented object points according to their centroid position, we find that the origin of the mask coordinate frame (Fig. 4 ©) may still be quite far from the amodal box center. We therefore propose to use a light-weight regression PointNet (T-Net) to estimate the true center of the complete object and then transform the coordinate such that the predicted center becomes the origin (Fig. 4 (d)). The architecture and training of our T-Net is similar to the T-Net in [20], which can be thought of as a special type of spatial transformer network (STN) [12]. However, different from the original STN that has no direct supervision on transformation, we explicitly supervise our translation network to predict center residuals from the mask coordinate origin to real object center.
解读:
进行实例分割后存在的问题:掩模坐标系的中心坐标可能仍然距离真实框比较远(图4(c))
解决方法:使用轻量级回归PointNet(T-Net)来估计整个目标的真实中心,然后变换坐标,使预测的中心成为原点。(与之前STN不同的是,在训练网络时加以监督)
Amodal 3D Box Estimation PointNet The box estimation network predicts amodal bounding boxes (for entireobject even if part of it is unseen) for objects given an object point cloud in 3D object coordinate (Fig. 4 (d)). The network architecture is similar to that for object classification [20, 22], however the output is no longer object class scores but parameters for a 3D bounding box. As stated in Sec. 3, we parameterize a 3D bounding box by its center (cx, cy, cz), size (h, w, l) and heading angle θ (along up-axis). We take a “residual” approach for box center estimation. The center residual predicted by the box estimation network is combined with the previous center residual from the T-Net and the masked points’ centroid to recover an absolute center (Eq. 1). For box size and heading angle, we follow previous works [23, 19] and use a hybrid of classification and regression formulations. Specifically, we pre-define NS size templates and NH equally split angle bins. Our model will both classify size/heading (NS scores for size, NH scores for heading) to those pre-defined categories as well as predict residual numbers for each category (3×NS residual dimensions for height, width, length, NH residual angles for heading). In the end the net outputs 3 + 4 × NS + 2 × NH numbers in total.

4.4. Training with Multi-task Losses
We simultaneously optimize the three nets involved (3D instance segmentation PointNet, T-Net and amodal box estimation PointNet) with multi-task losses (as in Eq. 2). L c1-reg is for T-Net and Lc2-reg is for center regression of box estimation net. Lh-cls and Lh-reg are losses for heading angle prediction while Ls-cls and Ls-reg are for box size. Softmax is used for all classification tasks and smooth-l1 (huber) loss is used for all regression cases.

解读:
依次为:实例分割损失、中心估计损失两个(c1是对于T-Net的,c2是box中心回归损失)、航向角预测和回归两个、尺度预测和回归两个,一个角损失。
Corner Loss for Joint Optimization of Box Parameters While our 3D bounding box parameterization is compact and complete, learning is not optimized for final 3D box accuracy – center, size and heading have separate loss terms. Imagine cases where center and size are accurately predicted but heading angle is off – the 3D IoU with ground truth box will then be dominated by the angle error. Ideally all three terms (center, size, heading) should be jointly optimized for best 3D box estimation (under IoU metric). To resolve this problem, we propose a novel regularization loss, the corner loss:

解读:
问题:中心,大小和朝向具有单独的损耗项,而理想状况下,应该对三者进行联合优化,以实现最佳估计。
解决办法:引入新的正则化损失(Corner Loss):定义8个角和Ground truth的距离偏差之和。(其中Pk**是带翻转的ground truth)
In essence, the corner loss is the sum of the distances between the eight corners of a predicted box and a ground truth box. Since corner positions are jointly determined by center, size and heading, the corner loss is able to regularize the multi-task training for those parameters. To compute the corner loss, we firstly construct NS × NH “anchor” boxes from all size templates and heading angle bins. The anchor boxes are then translated to the estimated box center. We denote the anchor box corners as Pkij , where i, j, k are indices for the size class, heading class, and (predefined) corner order, respectively. To avoid large penalty from flipped heading estimation, we further compute distances to corners Pk**) from the flipped ground truth box and use the minimum of the original and flipped cases. δij , which is one for the ground truth size/heading class and zero else wise, is a two-dimensional mask used to select the distance term we care about.
5. Experiments
(略,有时间再搬上来)
References
[1] Kitti 3d object detection benchmark leader board. http://www.cvlibs.net/datasets/kitti/ eval_object.php?obj_benchmark=3d. Accessed: 2017-11-14 12PM. 2
[2] Kitti bird’s eye view object detection benchmark leader board. http://www.cvlibs.net/datasets/ kitti/eval_object.php?obj_benchmark=bev. Accessed: 2017-11-14 12PM. 2
[3] X. Chen, K. Kundu, Z. Zhang, H. Ma, S. Fidler, and R. Urtasun. Monocular 3d object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2147–2156, 2016. 2, 6
[4] X. Chen, K. Kundu, Y. Zhu, A. G. Berneshawi, H. Ma, S. Fidler, and R. Urtasun. 3d object proposals for accurate object class detection. In Advances in Neural Information Processing Systems, pages 424–432, 2015. 6
[5] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia. Multi-view 3d object detection network for autonomous driving. In IEEE CVPR, 2017. 2, 5, 6
[6] Z. Deng and L. J. Latecki. Amodal detection of 3d objects: Inferring 3d bounding boxes from 2d ones in rgb-depth images. In Conference on Computer Vision and Pattern Recognition (CVPR), volume 2, 2017. 2
[7] M. Engelcke, D. Rao, D. Z. Wang, C. H. Tong, and I. Posner. Vote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks. In Robotics and Automation (ICRA), 2017 IEEE International Conference on, pages 1355–1361. IEEE, 2017. 1, 2
[8] A. Geiger, P. Lenz, C. Stiller, and R. Urtasun. Vision meets robotics: The kitti dataset. The International Journal of Robotics Research, 32(11):1231–1237, 2013. 5
[9] A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In Conference on Computer Vision and Pattern Recognition (CVPR), 2012. 5
[10] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages 580–587. IEEE, 2014. 1
[11] K. He, G. Gkioxari, P. Dollar, and R. Girshick. Mask r-cnn. ´ arXiv preprint arXiv:1703.06870, 2017. 1, 4, 7 [12] M. Jaderberg, K. Simonyan, A. Zisserman, et al. Spatial transformer networks. In NIPS 2015. 4
[13] J. Lahoud and B. Ghanem. 2d-driven 3d object detection in rgb-d images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4622– 4630, 2017. 2, 7
[14] B. Li. 3d fully convolutional network for vehicle detection in point cloud. arXiv preprint arXiv:1611.08069, 2016. 2, 5, 6
[15] B. Li, T. Zhang, and T. Xia. Vehicle detection from 3d lidar using fully convolutional network. arXiv preprint arXiv:1608.07916, 2016. 2
[16] Y. Li, S. Pirk, H. Su, C. R. Qi, and L. J. Guibas. Fpnn: Field probing neural networks for 3d data. arXiv preprint arXiv:1605.06240, 2016. 2
[17] T.-Y. Lin, P. Dollar, R. Girshick, K. He, B. Hariharan, and ´ S. Belongie. Feature pyramid networks for object detection. arXiv preprint arXiv:1612.03144, 2016. 3
[18] D. Maturana and S. Scherer. Voxnet: A 3d convolutional neural network for real-time object recognition. In IEEE/RSJ International Conference on Intelligent Robots and Systems, September 2015. 1, 2
[19] A. Mousavian, D. Anguelov, J. Flynn, and J. Kosecka. 3d bounding box estimation using deep learning and geometry. arXiv preprint arXiv:1612.00496, 2016. 2, 5
[20] C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2017. 1, 2, 4, 5
[21] C. R. Qi, H. Su, M. Nießner, A. Dai, M. Yan, and L. Guibas. Volumetric and multi-view cnns for object classification on 3d data. In Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2016. 1, 2
[22] C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv preprint arXiv:1706.02413, 2017. 1, 2, 4, 5, 7
[23] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems, pages 91–99, 2015. 2, 5
[24] Z. Ren and E. B. Sudderth. Three-dimensional object detection and layout prediction using clouds of oriented gradients. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1525–1533, 2016. 2, 7
[25] G. Riegler, A. O. Ulusoys, and A. Geiger. Octnet: Learning deep 3d representations at high resolutions. arXiv preprint arXiv:1611.05009, 2016. 2
[26] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 7
[27] S. Song, S. P. Lichtenberg, and J. Xiao. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 567–576, 2015. 1, 5, 7
[28] S. Song and J. Xiao. Sliding shapes for 3d object detection in depth images. In Computer Vision–ECCV 2014, pages 634–651. Springer, 2014. 2
[29] S. Song and J. Xiao. Deep sliding shapes for amodal 3d object detection in rgb-d images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 808–816, 2016. 2, 7
[30] H. Su, S. Maji, E. Kalogerakis, and E. G. Learned-Miller. Multi-view convolutional neural networks for 3d shape recognition. In Proc. ICCV, 2015. 1
[31] D. Z. Wang and I. Posner. Voting for voting in online point cloud object detection. Proceedings of the Robotics: Science and Systems, Rome, Italy, 1317, 2015. 2
[32] P.-S. Wang, Y. Liu, Y.-X. Guo, C.-Y. Sun, and X. Tong. O-cnn: Octree-based convolutional neural networks for 3d 926shape analysis. ACM Transactions on Graphics (TOG), 36(4):72, 2017. 2
[33] Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1912–1920, 2015. 1, 2
[34] Y. Xiang, W. Choi, Y. Lin, and S. Savarese. Data-driven 3d voxel patterns for object category recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1903–1911, 2015. 2
[35] S.-L. Yu, T. Westfechtel, R. Hamada, K. Ohno, and S. Tadokoro. Vehicle detection and localization on birds eye view elevation images using convolutional neural network. 2017 IEEE International Symposium on Safety, Security and Rescue Robotics (SSRR), 2017. 5, 6
相关链接
论文链接:http://openaccess.thecvf.com/content_cvpr_2018/papers/Qi_Frustum_PointNets_for_CVPR_2018_paper.pd
其他相关分析链接:https://zhuanlan.zhihu.com/p/41634956
(分析了论文方法的优缺点和一些改进方向,很有启发)