第2章 入门必修:单、多层感知机
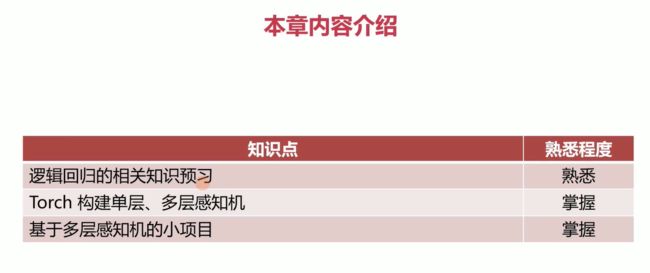
2-1 本章内容介绍
2-2 深度学习实施的一般过程
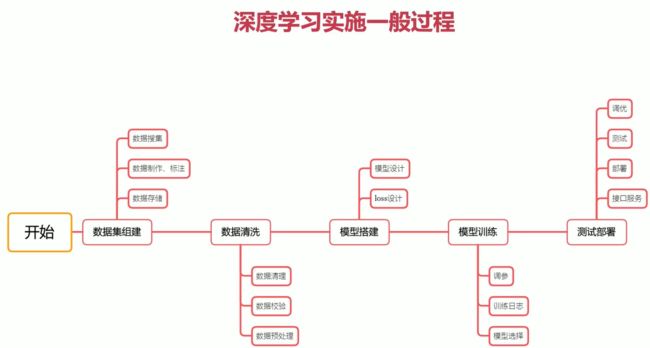
前两步可能占掉百分之七十的时间
2-3 逻辑回归

2-4 逻辑回归损失函数


这里的y(hat)是指概率,其取值从0到1,这个式子就是将每个样本预测的准确率相乘。
如果y(hat)是0.9,也就是预测1的概率是0.9,如果真实也是1,那么准确率就是0.9,
如果真实值是0,那么准确率就是1-0.9,也就是0.1。
所以这个L(w)的每一项,反映的是这个样本的准确率,每一项的准确率连成后就是L(w)本身,
即L(w)意思是:其值越大,那么整体预测的越准。
2-5 逻辑回归示例
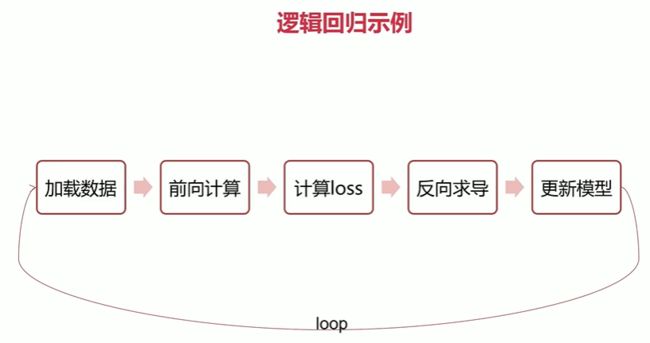
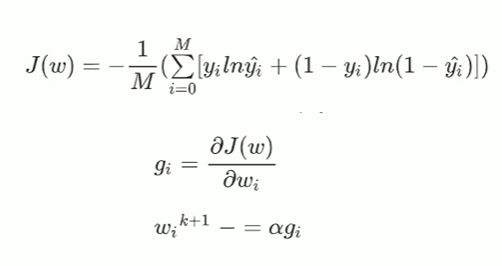
程序源码:
import torch
import torch.nn.functional as F
n_item = 1000
n_feature = 2
learning_rate = 0.001
epochs = 100
torch.manual_seed(123)
data_x = torch.randn(size=(n_item, n_feature)).float()
data_y = torch.where(torch.subtract(data_x[:, 0]*0.5, data_x[:, 1]*1.5) > 0, 1.0, 0).float()
class LogisticRegressionManually(object):
def __init__(self):
self.w = torch.randn(size=(n_feature, 1), requires_grad=True)
self.b = torch.zeros(size=(1, 1), requires_grad=True)
def forward(self, x):
y_hat = F.sigmoid(torch.matmul(self.w.transpose(0, 1), x)+self.b)
return y_hat
@staticmethod
def loss_func(y_hat, y):
return -(torch.log(y_hat)*y + (1-y)*torch.log(1-y_hat))
def train(self):
for epoch in range(epochs):
for step in range(n_item):
y_hat = self.forward(data_x[step])
y = data_y[step]
loss = self.loss_func(y_hat, y)
loss.backward()
with torch.no_grad():
self.w.data -= learning_rate * self.w.grad.data
self.b.data -= learning_rate * self.b.grad.data
self.w.grad.data.zero_()
self.b.grad.data.zero_()
print('Epoch: %03d, loss%.3f' % (epoch, loss.item()))
if __name__ == '__main__':
lrm = LogisticRegressionManually()
lrm.train()运行示例:
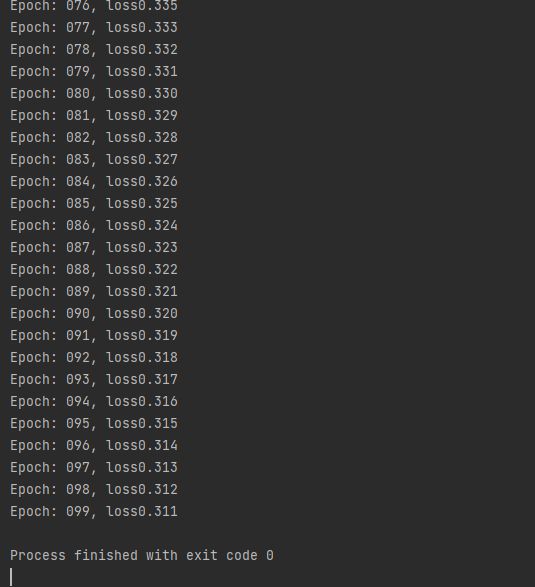
问题1:pytorch的配置
打开

运行下列代码
pip3 install torch -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
即可下载pytorch包
但这个包如何添加进pycharm环境是不清楚的,
尤其是对其中的Interpreter机制的运行。
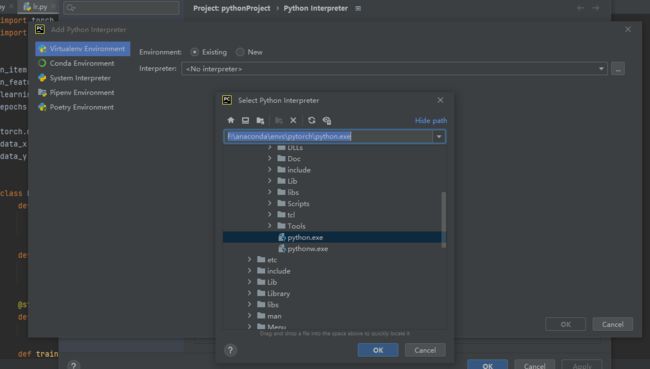
这个pytorch 其实是我将一个文件名为python的文件改名过来的,
当时我猜它下面其实是pytorch文件,
然后我把他移动到Anaconda的evs中,里面有python.exe文件
随后在Interpreter中选择这个路径就成功应用了包含pytorch的环境,
整个过程基本混乱,不清楚这个Interpreter是如何运转的。
移动并改名成pytorch的python文件如下:
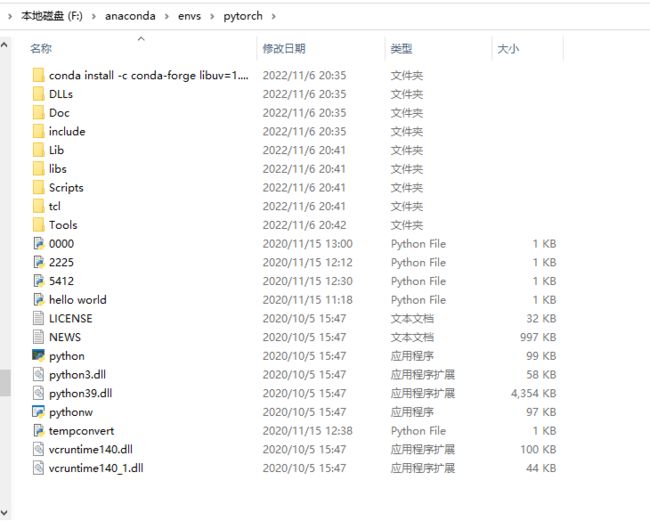
问题2:
虽然这个代码能跑但是这两行警告不清楚是什么情况。

2-6 单层、多层感知机
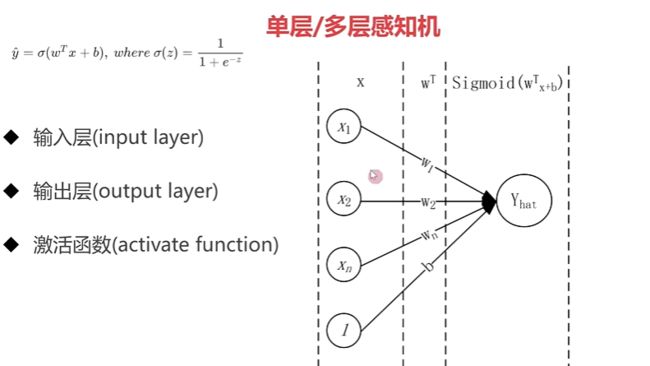
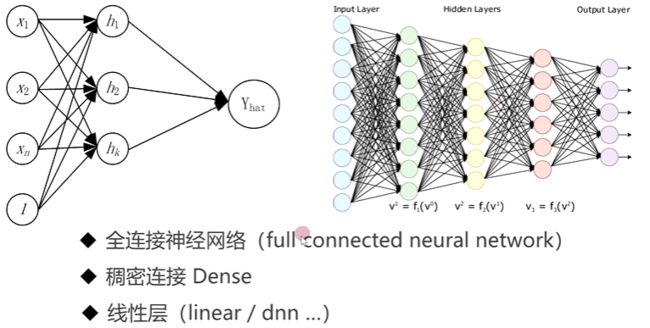
2-7 pytorch 构建单、多层感知机
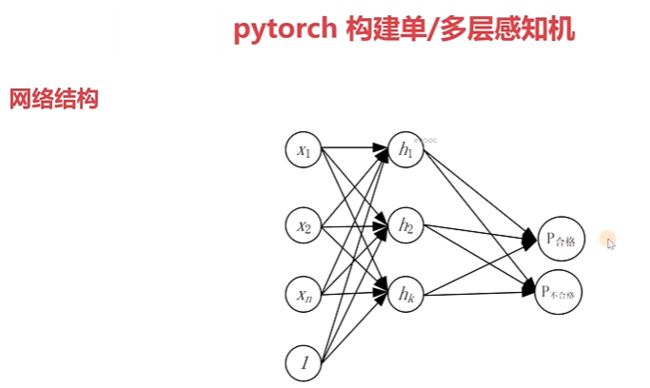
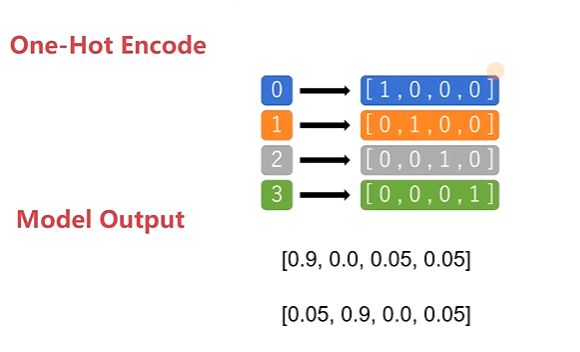
单层感知机代码示例:
import torch
from torch import nn
import torch.nn.functional as F
n_item = 1000
n_feature = 2
torch.manual_seed(123)
data_x = torch.randn(size=(n_item, n_feature)).float()
data_y = torch.where(torch.subtract(data_x[:, 0]*0.5, data_x[:, 1]*1.5) > 0, 1.0, 0).long()
data_y = F.one_hot(data_y)
class BinaryClassificationModel(nn.Module):
def __init__(self, in_feature):
super(BinaryClassificationModel, self).__init__()
self.layer_1 = nn.Linear(in_features=in_feature, out_features=2, bias=True)
def forward(self, x):
return F.sigmoid(self.layer_1(x))
learning_rate = 0.01
epochs = 100
model = BinaryClassificationModel(n_feature)
opt = torch.optim.SGD(model.parameters(), lr=learning_rate)
criteria = nn.BCELoss()
for epoch in range(1000):
for step in range(n_item):
x = data_x[step]
y = data_y[step]
opt.zero_grad()
y_hat = model(x.unsqueeze(0))
loss = criteria(y_hat, y.unsqueeze(0).float())
loss.backward()
opt.step()
print('Epoch: %03d, loss%.3f' % (epoch, loss.item()))输出示例:
太慢了就跑到这吧。。
多层感知机代码示例
import torch
from torch import nn
import torch.nn.functional as F
n_item = 1000
n_feature = 2
torch.manual_seed(123)
data_x = torch.randn(size=(n_item, n_feature)).float()
data_y = torch.where(torch.subtract(data_x[:, 0]*0.5, data_x[:, 1]*1.5) > 0, 1.0, 0).long()
data_y = F.one_hot(data_y)
class BinaryClassificationModel(nn.Module):
def __init__(self, in_feature):
super(BinaryClassificationModel, self).__init__()
self.layer_1 = nn.Linear(in_features=in_feature, out_features=128, bias=True)
self.layer_2 = nn.Linear(in_features=128, out_features=512, bias=True)
self.layer_final = nn.Linear(in_features=512, out_features=2, bias=True)
def forward(self, x):
layer_1_output = F.sigmoid(self.layer_1(x))
layer_2_output = F.sigmoid(self.layer_2(layer_1_output))
output = F.sigmoid(self.layer_final(layer_2_output))
return output
learning_rate = 0.01
epochs = 100
model = BinaryClassificationModel(n_feature)
opt = torch.optim.SGD(model.parameters(), lr=learning_rate)
criteria = nn.BCELoss()
for epoch in range(1000):
for step in range(n_item):
x = data_x[step]
y = data_y[step]
opt.zero_grad()
y_hat = model(x.unsqueeze(0))
loss = criteria(y_hat, y.unsqueeze(0).float())
loss.backward()
opt.step()
print('Epoch: %03d, loss%.3f' % (epoch, loss.item()))
输出示例:
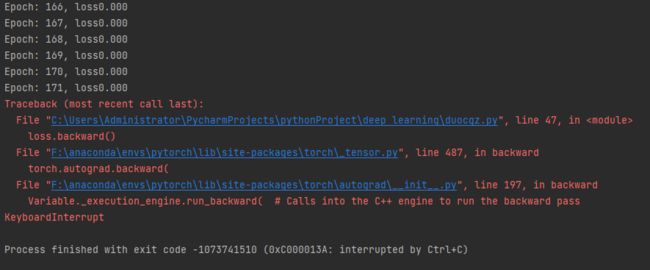
2-8 基于多层DNN假钞识别

2-9 数据集及特征分析

2-10 项目构建和模型训练
preprocess.py
import numpy as np
from config import HP
import os
trainset_ratio = 0.7
devset_ratio = 0.2
testset_ratio = 0.1
np.random.seed(HP.seed)
dataset = np.loadtxt(HP.data_path, delimiter=',')
np.random.shuffle(dataset)
n_items = dataset.shape[0]
trainset_num = int(trainset_ratio * n_items)
devset_num = int(devset_ratio * n_items)
testset_num = n_items - trainset_num - devset_num
np.savetxt(os.path.join(HP.data_dir, 'train.txt'), dataset[:trainset_num], delimiter=',')
np.savetxt(os.path.join(HP.data_dir, 'dev.txt'), dataset[trainset_num:trainset_num + devset_num], delimiter=',')
np.savetxt(os.path.join(HP.data_dir, 'test.txt'), dataset[trainset_num+devset_num:], delimiter=',')
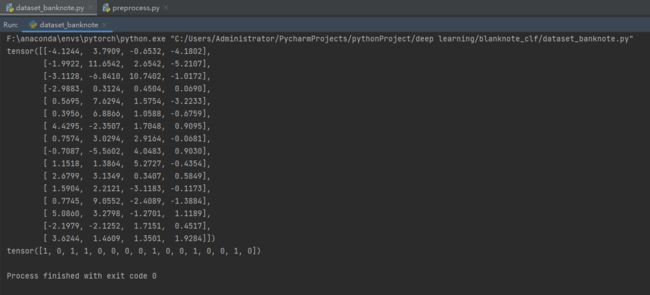
dataset_banknote.py
import torch
from torch.utils.data import DataLoader
from config import HP
import numpy as np
# class BanknoteDataset(torch.utils.data.Dataset):
#
# def __init__(self, data_path):
# """ banknote dataset
# :param data_path: dataset path: [trainset, devset, testset]
# """
# self.dataset = np.loadtxt(data_path, delimiter=',')
#
# def __getitem__(self, idx):
# item = self.dataset[idx]
# x, y = item[:HP.in_features], item[HP.in_features:]
# return torch.Tensor(x).float().to(HP.device), torch.Tensor(y).squeeze().long().to(HP.device)
#
# def __len__(self):
# return self.dataset.shape[0]
# if __name__ == '__main__':
# bkdataset = BanknoteDataset(HP.trainset_path)
# bkdataloader = DataLoader(bkdataset, batch_size=13, shuffle=True, drop_last=True)
# for batch in bkdataloader:
# x, y = batch
# print(x)
# print(y.size())
# break
class BanknoteDataset(torch.utils.data.Dataset):
def __init__(self, data_path):
self.dataset = np.loadtxt(data_path, delimiter=',')
def __getitem__(self, idx):
item = self.dataset[idx]
x, y = item[:HP.in_features], item[HP.in_features:]
return torch.Tensor(x).float().to(HP.device), torch.Tensor(y).squeeze().long().to(HP.device)
def __len__(self):
return self.dataset.shape[0]
# if __name__ == '__main__':
# bkdataset = BanknoteDataset(HP.testset_path)
# bkdataloader = DataLoader(bkdataset, batch_size=16, shuffle=True, drop_last=True)
#
# for batch in bkdataloader:
# x, y = batch
# print(x)
# print(y)
# break运行测试代码示例:
config.py
# banknote classification config
# 超参配置
# yaml
class Hyperparameter:
# ################################################################
# Data
# ################################################################
device = 'cpu' # cuda
data_dir = './data/'
data_path = './data/data_banknote_authentication.txt'
trainset_path = './data/train.txt'
devset_path = './data/dev.txt'
testset_path = './data/test.txt'
in_features = 4 # input feature dim
out_dim = 2 # output feature dim (classes number)
seed = 1234 # random seed
# ################################################################
# Model Structure
# ################################################################
layer_list = [in_features, 64, 128, 64, out_dim]
# ################################################################
# Experiment
# ################################################################
batch_size = 64
init_lr = 1e-3
epochs = 100
verbose_step = 10
save_step = 200
model.py
import torch
from torch import nn
from torch.nn import functional as F
from config import HP
# class BanknoteClassificationModel(nn.Module):
# def __init__(self,):
# super(BanknoteClassificationModel, self).__init__()
# # """ 代码过于冗余
# self.linear_layers = []
# for idx, dim in enumerate(HP.layer_list[:-1]):
# self.linear_layers.append(nn.Linear(dim, HP.layer_list[idx+1]))
# # """
# self.linear_layers = nn.ModuleList([
# nn.Linear(in_dim, out_dim) for in_dim, out_dim in zip(HP.layer_list[:-1], HP.layer_list[1:])
# ])
# pass
#
# def forward(self, input_x):
# for layer in self.linear_layers:
# input_x = layer(input_x)
# input_x = F.relu(input_x)
# return input_x
#
#
# # if __name__ == '__main__':
# # model = BanknoteClassificationModel()
# # x = torch.randn(size=(8, HP.in_features)).to(HP.device)
# # print(model(x).size())
class BanknoteClassificationModel(nn.Module):
def __init__(self, ):
super(BanknoteClassificationModel, self).__init__()
self.linear_layer = nn.ModuleList([
nn.Linear(in_features=in_dim, out_features=out_dim)
for in_dim, out_dim in zip(HP.layer_list[:-1], HP.layer_list[1:])
])
def forward(self, input_x):
for layer in self.linear_layer:
input_x = layer(input_x)
input_x = F.relu(input_x)
return input_x
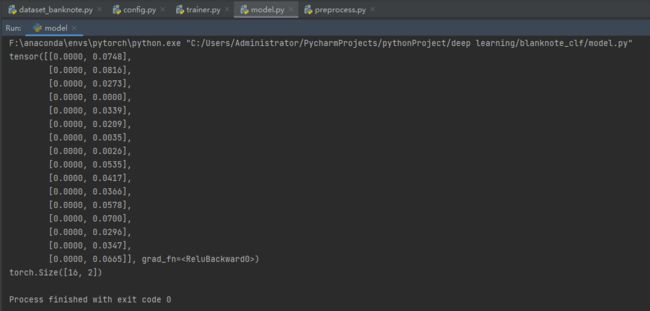
if __name__ == '__main__':
model = BanknoteClassificationModel()
x = torch.randn(size=(16, HP.in_features)).to(HP.device)
y_pred = model(x)
print(y_pred)
print(y_pred.size())
运行测试代码示例
trainer.py
import os
from argparse import ArgumentParser
import torch.optim as optim
import torch
import random
import numpy as np
import torch.nn as nn
from torch.utils.data import DataLoader
from tensorboardX import SummaryWriter
from model import BanknoteClassificationModel
from config import HP
from dataset_banknote import BanknoteDataset
# # training logger
# logger = SummaryWriter('./log')
#
# # seed init: Ensure Reproducible Result
# torch.manual_seed(HP.seed)
# random.seed(HP.seed)
# np.random.seed(HP.seed)
# torch.cuda.manual_seed(HP.seed)
#
#
# # evaluate function
# def evaluate(model_, devloader, crit):
# model_.eval()
# sum_loss = 0.
# with torch.no_grad():
# for batch in devloader:
# x, y = batch
# pred = model_(x)
# loss = crit(pred, y)
# sum_loss += loss.item()
# model_.train()
# return sum_loss/len(devloader)
#
#
# def save_checkpoint(model_, epoch_, optm, checkpoint_path):
# save_dict = {
# 'epoch': epoch_,
# 'model_state_dict': model_.state_dict(),
# 'optimizer_state_dict': optm.state_dict(),
# }
# torch.save(save_dict, checkpoint_path)
#
#
# def train():
# parser = ArgumentParser(description='Model Train')
# parser.add_argument(
# '--c',
# default=None,
# # default='./model_save/model_66_4000.pth'
# type=str,
# help='train from scratch if it is none, or resume training from checkpoint'
# )
# args = parser.parse_args()
#
# # new model instance
# model = BanknoteClassificationModel()
# model = model.to(HP.device)
#
# # new criterion loss function or customize define in "loss.py"
# criterion = nn.CrossEntropyLoss()
#
# opt = optim.Adam(model.parameters(), lr=HP.init_lr)
#
# # load train set
# trainset = BanknoteDataset(HP.trainset_path)
# train_loader = DataLoader(trainset, batch_size=HP.batch_size, shuffle=True, drop_last=True)
#
# # load dev set
# devset = BanknoteDataset(HP.devset_path)
# dev_loader = DataLoader(devset, batch_size=HP.batch_size, shuffle=True, drop_last=True)
#
# start_epoch = 0
# step = 0
# if args.c: # training resume
# checkpoint = torch.load(args.c)
# model.load_state_dict(checkpoint['model_state_dict'])
# opt.load_state_dict(checkpoint['optimizer_state_dict'])
# start_epoch = checkpoint['epoch']
# print('Resume Training From %s' % args.c)
# else:
# print('Train From Scratch.')
# step = len(train_loader)*start_epoch
#
# model.train() # set training flag
#
# # training loop
# for epoch in range(start_epoch, HP.epochs):
# print("="*33, 'Start Epoch: %d, %d iters' % (epoch, len(trainset)/HP.batch_size), "="*33)
#
# sum_loss = 0. # loss
# for batch in train_loader:
#
# x, y = batch # load data
# opt.zero_grad() # gradient clean
# pred = model(x) # froward process
# loss = criterion(pred, y) # loss calc
# sum_loss += loss.item()
# loss.backward() # backward process
# opt.step() # model weights update
#
# logger.add_scalar('Loss/Train', loss, step) # add train loss to logger
# if not step % HP.verbose_step:
# eval_loss = evaluate(model, dev_loader, criterion)
# logger.add_scalar('Loss/eval', eval_loss, step)
# print('Train loss: %.4f, Eval loss %.4f' % (loss.item(), eval_loss))
#
# if not step % HP.save_step:
# model_path = 'model_%d_%d.pth' % (epoch, step)
# save_checkpoint(model, epoch, opt, os.path.join('model_save', model_path))
# step += 1
# logger.flush()
# print("Epoch: [%d/%d], step: %d Train loss: %.4f, Dev loss: %.4f" % (epoch, HP.epochs, step, loss.item(), eval_loss))
# logger.close()
#
#
# if __name__ == '__main__':
# train()
logger = SummaryWriter('./log')
# seed init: Ensure Reproducible Result
torch.manual_seed(HP.seed)
# torch.cuda.manual_seed(HP.seed)
random.seed(HP.seed)
np.random.seed(HP.seed)
def evaluate(model_, devloader, crit):
model_.eval() # set evaluation flag
sum_loss = 0.
with torch.no_grad():
for batch in devloader:
x, y = batch
pred = model_(x)
loss = crit(pred, y)
sum_loss += loss.item()
model_.train() # back to training mode
return sum_loss / len(devloader)
def save_checkpoint(model_, epoch_, optm, checkpoint_path):
save_dict = {
'epoch': epoch_,
'model_state_dict': model_.state_dict(),
'optimizer_state_dict': optm.state_dict()
}
torch.save(save_dict, checkpoint_path)
def train():
parser = ArgumentParser(description="Model Training")
parser.add_argument(
'--c',
default=None,
type=str,
help='train from scratch or resume training'
)
args = parser.parse_args()
# new model instance
model = BanknoteClassificationModel()
model = model.to(HP.device)
# loss function (loss.py)
criterion = nn.CrossEntropyLoss()
# optimizer
opt = optim.Adam(model.parameters(), lr=HP.init_lr)
# opt = optim.SGD(model.parameters(), lr=HP.init_lr)
# train dataloader
trainset = BanknoteDataset(HP.trainset_path)
train_loader = DataLoader(trainset, batch_size=HP.batch_size, shuffle=True, drop_last=True)
# dev datalader(evaluation)
devset = BanknoteDataset(HP.devset_path)
dev_loader = DataLoader(devset, batch_size=HP.batch_size, shuffle=True, drop_last=False)
start_epoch, step = 0, 0
if args.c:
checkpoint = torch.load(args.c)
model.load_state_dict(checkpoint['model_state_dict'])
opt.load_state_dict(checkpoint['optimizer_state_dict'])
start_epoch = checkpoint['epoch']
print('Resume From %s.' % args.c)
else:
print('Training From scratch!')
model.train() # set training flag
# main loop
for epoch in range(start_epoch, HP.epochs):
print('Start Epoch: %d, Steps: %d' % (epoch, len(train_loader) / HP.batch_size))
for batch in train_loader:
x, y = batch # load data
opt.zero_grad() # gradient clean
pred = model(x) # forward process
loss = criterion(pred, y) # loss calc
loss.backward() # backward process
opt.step()
logger.add_scalar('Loss/Train', loss, step)
if not step % HP.verbose_step: # evaluate log print
eval_loss = evaluate(model, dev_loader, criterion)
logger.add_scalar('Loss/Dev', eval_loss, step)
if not step % HP.save_step: # model save
model_path = 'model_%d_%d.pth' % (epoch, step)
save_checkpoint(model, epoch, opt, os.path.join('model_save', model_path))
step += 1
logger.flush()
print('Epoch: [%d/%d], step: %d Train Loss: %.5f, Dev Loss: %.5f'
% (epoch, HP.epochs, step, loss.item(), eval_loss))
logger.close()
if __name__ == '__main__':
train()
运行测试代码示例
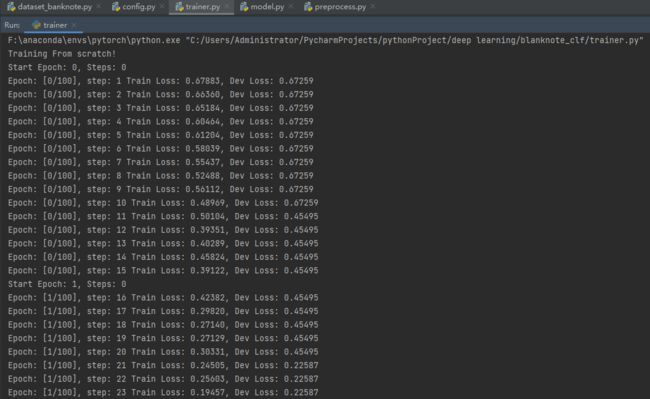
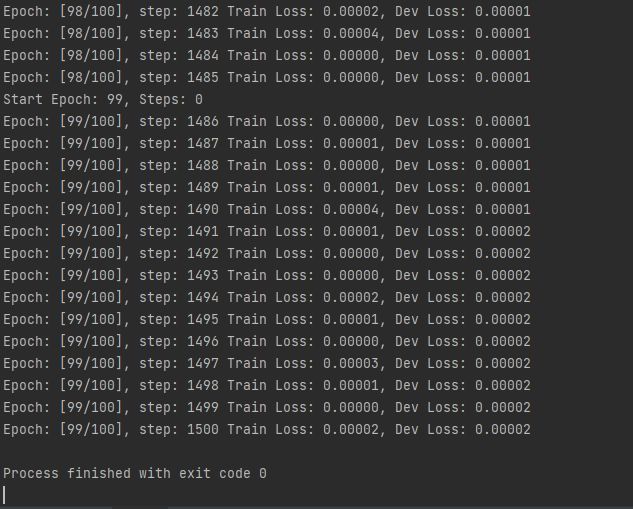
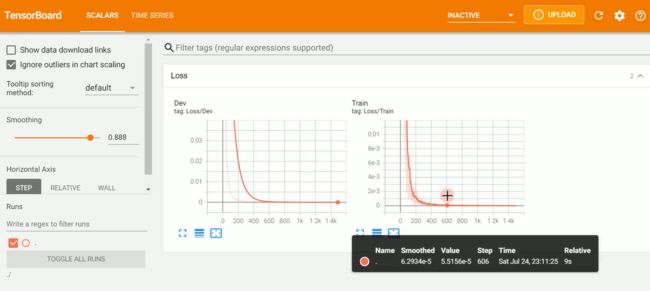
2-14 模型评估和选择

好家伙!这个链接半天搞不出来,暂时放弃。
inference.py
import torch
from torch.utils.data import DataLoader
from dataset_banknote import BanknoteDataset
from model import BanknoteClassificationModel
from config import HP
# # load model from save dir
# model = BanknoteClassificationModel()
# checkpoint = torch.load('./model_save/model_83_5000.pth')
# model.load_state_dict(checkpoint['model_state_dict'])
#
# # load test set
# testset = BanknoteDataset(HP.testset_path)
# test_loader = DataLoader(testset, batch_size=HP.batch_size, shuffle=True, drop_last=False)
#
# model.eval()
#
# total_cnt = 0
# correct_cnt = 0
# with torch.no_grad():
# for batch in test_loader:
# x, y = batch
# pred = model(x)
# total_cnt += pred.size(0)
# correct_cnt += (torch.argmax(pred, -1) == y).sum()
#
# print("Accuracy : %.3f" % (correct_cnt/total_cnt))
# new model instance
model = BanknoteClassificationModel()
checkpoint = torch.load('./model_save/model_40_600.pth')
model.load_state_dict(checkpoint['model_state_dict'])
# test set
# dev datalader(evaluation)
testset = BanknoteDataset(HP.testset_path)
test_loader = DataLoader(testset, batch_size=HP.batch_size, shuffle=True, drop_last=False)
model.eval()
total_cnt = 0
correct_cnt = 0
with torch.no_grad():
for batch in test_loader:
x, y = batch
pred = model(x)
print(pred)
total_cnt += pred.size(0)
correct_cnt += (torch.argmax(pred, 1) == y).sum()
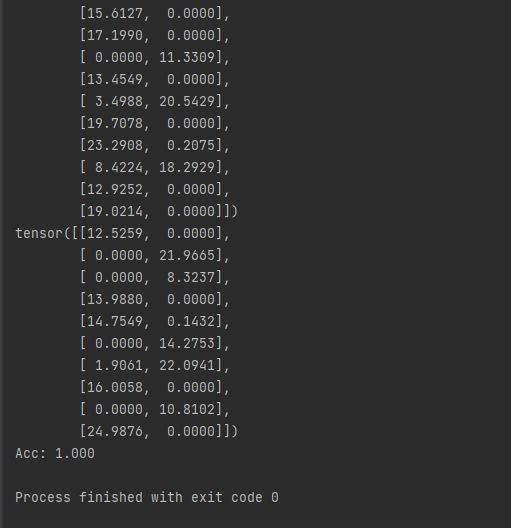
print('Acc: %.3f' % (correct_cnt / total_cnt))
运行测试代码示例:
2-15 本章总结
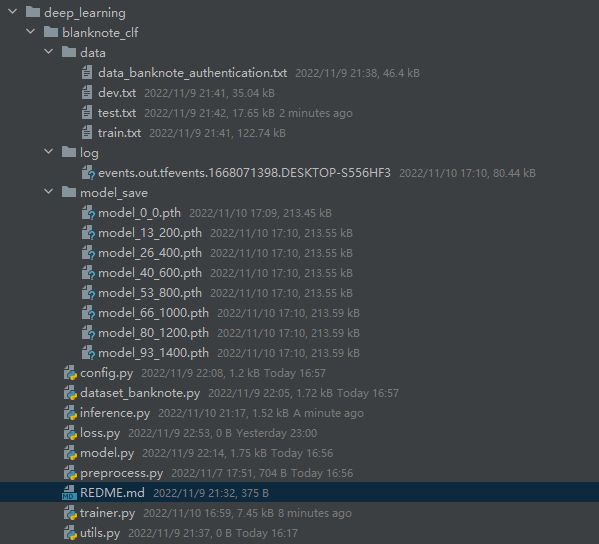
项目目录:
一脸懵逼的来,一脸懵逼的走。太多东西不清楚了,但也不能拘泥于此,先建立整体印象,很多细节下章会分解。虽说如此,一些基础的重要的内容还是需要额外花上许多时间。