365天深度学习训练营-第P7周:咖啡豆识别
第P7周:咖啡豆识别
本文为365天深度学习训练营 内部限免文章
参考本文所写记录性文章,请在文章开头注明以下内容,复制粘贴即可
- 本文为365天深度学习训练营 中的学习记录博客
- 参考文章:Pytorch实战 | 第P7周:咖啡豆识别(训练营内部成员可读)
- 原作者:K同学啊|接辅导、项目定制
要求:
自己搭建VGG-16网络框架
调用官方的VGG-16网络框架
如何查看模型的参数量以及相关指标
拔高(可选):
验证集准确率达到100%
使用PPT画出VGG-16算法框架图(发论文需要这项技能)
探索(难度有点大)
在不影响准确率的前提下轻量化模型
目前VGG16的Total params是134,276,932
我的环境:
语言环境:Python3.8
编译器:Jupyter Lab
深度学习环境:Pytorch
torch1.12.1+cu113
torchvision0.13.1+cu113
一、 前期准备
1. 设置GPU
如果设备上支持GPU就使用GPU,否则使用CPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
warnings.filterwarnings("ignore") #忽略警告信息
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type='cuda')
2. 导入数据
import os,PIL,random,pathlib
data_dir = './data/7-data/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[2] for path in data_paths]
classeNames
['Dark', 'Green', 'Light', 'Medium']
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
# transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
test_transform = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder("./data/7-data/",transform=train_transforms)
total_data
Dataset ImageFolder
Number of datapoints: 1200
Root location: ./data/7-data/
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=None)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
total_data.class_to_idx
{'Dark': 0, 'Green': 1, 'Light': 2, 'Medium': 3}
3. 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_dataset, test_dataset
(,
)
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
Shape of X [N, C, H, W]: torch.Size([32, 3, 224, 224])
Shape of y: torch.Size([32]) torch.int64
二、手动搭建VGG-16模型
1. 搭建模型
import torch.nn.functional as F
class vgg16(nn.Module):
def __init__(self):
super(vgg16, self).__init__()
# 卷积块1
self.block1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 卷积块2
self.block2 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 卷积块3
self.block3 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 卷积块4
self.block4 = nn.Sequential(
nn.Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 卷积块5
self.block5 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 全连接网络层,用于分类
self.classifier = nn.Sequential(
nn.Linear(in_features=512*7*7, out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=4)
)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = vgg16().to(device)
model
vgg16(
(block1): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
(block2): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
(block3): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): ReLU()
(6): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
(block4): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): ReLU()
(6): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
(block5): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): ReLU()
(6): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU()
(2): Linear(in_features=4096, out_features=4096, bias=True)
(3): ReLU()
(4): Linear(in_features=4096, out_features=4, bias=True)
)
)
2. 查看模型详情
# 统计模型参数量以及其他指标
import torchsummary as summary
summary.summary(model, (3, 224, 224))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 224, 224] 1,792
ReLU-2 [-1, 64, 224, 224] 0
Conv2d-3 [-1, 64, 224, 224] 36,928
ReLU-4 [-1, 64, 224, 224] 0
MaxPool2d-5 [-1, 64, 112, 112] 0
Conv2d-6 [-1, 128, 112, 112] 73,856
ReLU-7 [-1, 128, 112, 112] 0
Conv2d-8 [-1, 128, 112, 112] 147,584
ReLU-9 [-1, 128, 112, 112] 0
MaxPool2d-10 [-1, 128, 56, 56] 0
Conv2d-11 [-1, 256, 56, 56] 295,168
ReLU-12 [-1, 256, 56, 56] 0
Conv2d-13 [-1, 256, 56, 56] 590,080
ReLU-14 [-1, 256, 56, 56] 0
Conv2d-15 [-1, 256, 56, 56] 590,080
ReLU-16 [-1, 256, 56, 56] 0
MaxPool2d-17 [-1, 256, 28, 28] 0
Conv2d-18 [-1, 512, 28, 28] 1,180,160
ReLU-19 [-1, 512, 28, 28] 0
Conv2d-20 [-1, 512, 28, 28] 2,359,808
ReLU-21 [-1, 512, 28, 28] 0
Conv2d-22 [-1, 512, 28, 28] 2,359,808
ReLU-23 [-1, 512, 28, 28] 0
MaxPool2d-24 [-1, 512, 14, 14] 0
Conv2d-25 [-1, 512, 14, 14] 2,359,808
ReLU-26 [-1, 512, 14, 14] 0
Conv2d-27 [-1, 512, 14, 14] 2,359,808
ReLU-28 [-1, 512, 14, 14] 0
Conv2d-29 [-1, 512, 14, 14] 2,359,808
ReLU-30 [-1, 512, 14, 14] 0
MaxPool2d-31 [-1, 512, 7, 7] 0
Linear-32 [-1, 4096] 102,764,544
ReLU-33 [-1, 4096] 0
Linear-34 [-1, 4096] 16,781,312
ReLU-35 [-1, 4096] 0
Linear-36 [-1, 4] 16,388
================================================================
Total params: 134,276,932
Trainable params: 134,276,932
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 218.52
Params size (MB): 512.23
Estimated Total Size (MB): 731.32
----------------------------------------------------------------
三、 训练模型
1. 编写训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
2. 编写测试函数
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
3. 正式训练
model.train()、model.eval()训练营往期文章中有详细的介绍。
如果将优化器换成 SGD 会发生什么呢?请自行探索接下来发生的诡异事件的原因。
import copy
optimizer = torch.optim.Adam(model.parameters(), lr= 1e-4)
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
epochs = 40
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
# 保存最佳模型到 best_model
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,
epoch_test_acc*100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
print('Done')
Epoch: 1, Train_acc:24.8%, Train_loss:1.388, Test_acc:24.2%, Test_loss:1.387, Lr:1.00E-04
Epoch: 2, Train_acc:28.0%, Train_loss:1.335, Test_acc:29.6%, Test_loss:1.191, Lr:1.00E-04
Epoch: 3, Train_acc:58.5%, Train_loss:0.896, Test_acc:60.0%, Test_loss:0.726, Lr:1.00E-04
Epoch: 4, Train_acc:67.6%, Train_loss:0.642, Test_acc:64.6%, Test_loss:0.725, Lr:1.00E-04
Epoch: 5, Train_acc:70.9%, Train_loss:0.606, Test_acc:76.2%, Test_loss:0.472, Lr:1.00E-04
Epoch: 6, Train_acc:79.4%, Train_loss:0.449, Test_acc:78.3%, Test_loss:0.446, Lr:1.00E-04
Epoch: 7, Train_acc:80.3%, Train_loss:0.430, Test_acc:81.2%, Test_loss:0.403, Lr:1.00E-04
Epoch: 8, Train_acc:82.7%, Train_loss:0.357, Test_acc:85.0%, Test_loss:0.311, Lr:1.00E-04
Epoch: 9, Train_acc:92.4%, Train_loss:0.177, Test_acc:87.9%, Test_loss:0.311, Lr:1.00E-04
Epoch:10, Train_acc:93.0%, Train_loss:0.207, Test_acc:92.5%, Test_loss:0.212, Lr:1.00E-04
Epoch:11, Train_acc:94.7%, Train_loss:0.141, Test_acc:95.4%, Test_loss:0.149, Lr:1.00E-04
Epoch:12, Train_acc:96.7%, Train_loss:0.090, Test_acc:98.3%, Test_loss:0.045, Lr:1.00E-04
Epoch:13, Train_acc:98.2%, Train_loss:0.046, Test_acc:97.9%, Test_loss:0.089, Lr:1.00E-04
Epoch:14, Train_acc:99.5%, Train_loss:0.020, Test_acc:98.8%, Test_loss:0.047, Lr:1.00E-04
Epoch:15, Train_acc:98.4%, Train_loss:0.044, Test_acc:95.8%, Test_loss:0.151, Lr:1.00E-04
Epoch:16, Train_acc:97.7%, Train_loss:0.061, Test_acc:94.6%, Test_loss:0.179, Lr:1.00E-04
Epoch:17, Train_acc:95.5%, Train_loss:0.145, Test_acc:94.6%, Test_loss:0.107, Lr:1.00E-04
Epoch:18, Train_acc:99.0%, Train_loss:0.031, Test_acc:94.2%, Test_loss:0.143, Lr:1.00E-04
Epoch:19, Train_acc:95.7%, Train_loss:0.124, Test_acc:95.0%, Test_loss:0.187, Lr:1.00E-04
Epoch:20, Train_acc:96.1%, Train_loss:0.114, Test_acc:97.9%, Test_loss:0.068, Lr:1.00E-04
Epoch:21, Train_acc:99.3%, Train_loss:0.021, Test_acc:99.2%, Test_loss:0.025, Lr:1.00E-04
Epoch:22, Train_acc:99.8%, Train_loss:0.008, Test_acc:99.2%, Test_loss:0.018, Lr:1.00E-04
Epoch:23, Train_acc:99.2%, Train_loss:0.024, Test_acc:94.2%, Test_loss:0.291, Lr:1.00E-04
Epoch:24, Train_acc:97.4%, Train_loss:0.081, Test_acc:97.5%, Test_loss:0.082, Lr:1.00E-04
Epoch:25, Train_acc:99.1%, Train_loss:0.024, Test_acc:98.8%, Test_loss:0.034, Lr:1.00E-04
Epoch:26, Train_acc:99.8%, Train_loss:0.010, Test_acc:99.2%, Test_loss:0.016, Lr:1.00E-04
Epoch:27, Train_acc:99.1%, Train_loss:0.026, Test_acc:98.3%, Test_loss:0.078, Lr:1.00E-04
Epoch:28, Train_acc:93.5%, Train_loss:0.202, Test_acc:94.6%, Test_loss:0.154, Lr:1.00E-04
Epoch:29, Train_acc:97.8%, Train_loss:0.062, Test_acc:97.5%, Test_loss:0.116, Lr:1.00E-04
Epoch:30, Train_acc:99.5%, Train_loss:0.016, Test_acc:98.8%, Test_loss:0.026, Lr:1.00E-04
Epoch:31, Train_acc:98.9%, Train_loss:0.032, Test_acc:97.5%, Test_loss:0.065, Lr:1.00E-04
Epoch:32, Train_acc:99.8%, Train_loss:0.008, Test_acc:99.2%, Test_loss:0.019, Lr:1.00E-04
Epoch:33, Train_acc:100.0%, Train_loss:0.002, Test_acc:100.0%, Test_loss:0.008, Lr:1.00E-04
Epoch:34, Train_acc:100.0%, Train_loss:0.001, Test_acc:100.0%, Test_loss:0.005, Lr:1.00E-04
Epoch:35, Train_acc:100.0%, Train_loss:0.000, Test_acc:99.6%, Test_loss:0.006, Lr:1.00E-04
Epoch:36, Train_acc:100.0%, Train_loss:0.000, Test_acc:99.6%, Test_loss:0.007, Lr:1.00E-04
Epoch:37, Train_acc:100.0%, Train_loss:0.000, Test_acc:99.6%, Test_loss:0.007, Lr:1.00E-04
Epoch:38, Train_acc:100.0%, Train_loss:0.000, Test_acc:99.6%, Test_loss:0.006, Lr:1.00E-04
Epoch:39, Train_acc:100.0%, Train_loss:0.000, Test_acc:99.6%, Test_loss:0.005, Lr:1.00E-04
Epoch:40, Train_acc:100.0%, Train_loss:0.000, Test_acc:99.6%, Test_loss:0.006, Lr:1.00E-04
Done
四、 结果可视化
1. Loss与Accuracy图
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

output_29_0.png
2. 指定图片进行预测
from PIL import Image
classes = list(total_data.class_to_idx)
def predict_one_image(image_path, model, transform, classes):
test_img = Image.open(image_path).convert('RGB')
plt.imshow(test_img) # 展示预测的图片
test_img = transform(test_img)
img = test_img.to(device).unsqueeze(0)
model.eval()
output = model(img)
_,pred = torch.max(output,1)
pred_class = classes[pred]
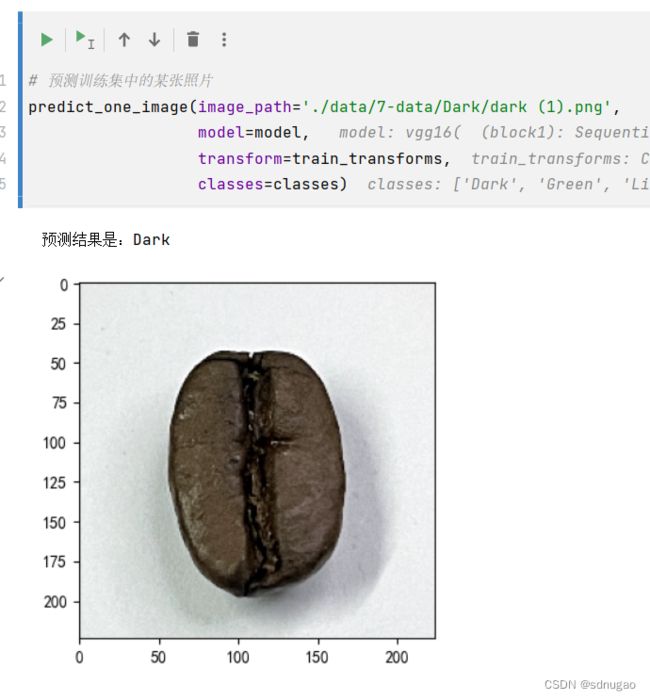
print(f'预测结果是:{pred_class}')
# 预测训练集中的某张照片
predict_one_image(image_path='./data/7-data/Dark/dark (1).png',
model=model,
transform=train_transforms,
classes=classes)
3. 模型评估
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
epoch_test_acc, epoch_test_loss

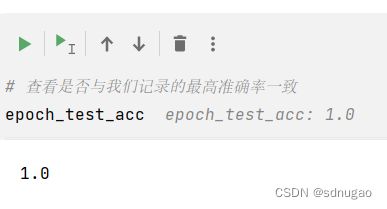
# 查看是否与我们记录的最高准确率一致
epoch_test_acc
附录:
1. VGG原理
1.网络结构
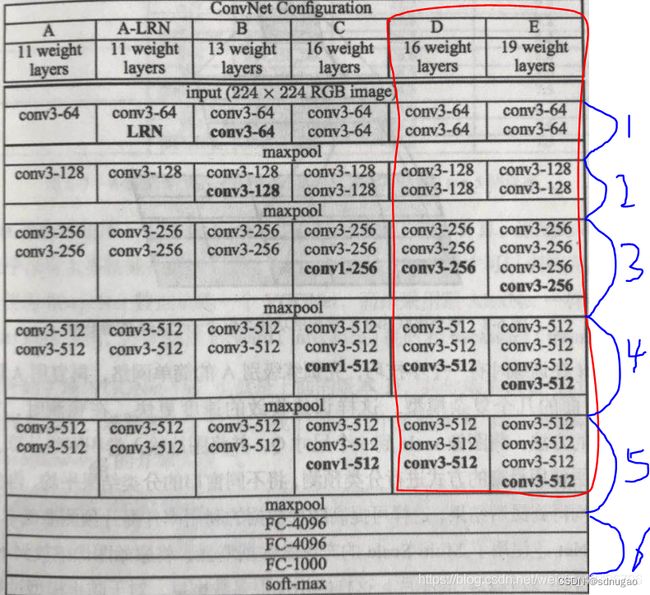
根据卷积核大小和卷积层数,VGG共有6中配置,分别为A,A-LRN,B,C,D,E,其中D和E两种最为常用,即i我们所说的VGG16和VGG19。看下图红色框所示。具体为:
- 卷积-卷积-池化-卷积-卷积-池化-卷积-卷积-卷积-池化-卷积-卷积-卷积-池化-卷积-卷积-卷积-池化-全连接-全连接-全连接 。
- 通道数分别为64,128,512,512,512,4096,4096,1000。卷积层通道数翻倍,直到512时不再增加。通道数的增加,使更多的信息被提取出来。全连接的4096是经验值,当然也可以是别的数,但是不要小于最后的类别。1000表示要分类的类别数。
- 所有的激活单元都是Relu 。
- 用池化层作为分界,VGG16共有6个块结构,每个块结构中的通道数相同。如下图蓝色所示。因为卷积层和全连接层都有权重系数,也被称为权重层,其中卷积层13层,全连接3层,池化层不涉及权重。所以共有13+3=16层。
- 对于VGG16卷积神经网络而言,其13层卷积层和5层池化层负责进行特征的提取,最后的3层全连接层负责完成分类任务。
2.VGG16的卷积核
卷积层全部都是33的卷积核,用上图中conv3-xxx表示,xxx表示通道数。其步长为1,用padding=same填充。
池化层的池化核为22
3. 卷积计算
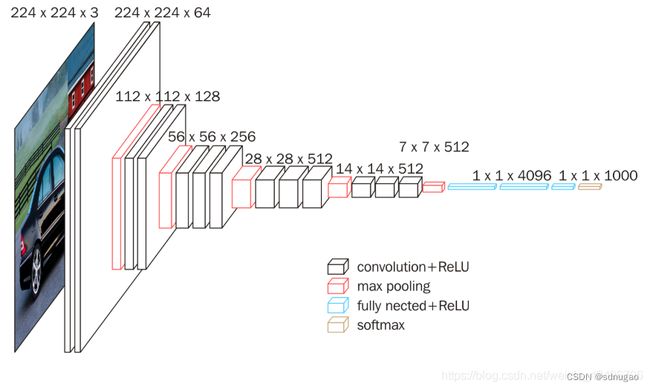
1)输入图像尺寸为224x224x3,经64个通道为3的3x3的卷积核,步长为1,padding=same填充,卷积两次,再经ReLU激活,输出的尺寸大小为224x224x64
2)经max pooling(最大化池化),滤波器为2x2,步长为2,图像尺寸减半,池化后的尺寸变为112x112x64
3)经128个3x3的卷积核,两次卷积,ReLU激活,尺寸变为112x112x128
4)max pooling池化,尺寸变为56x56x128
5)经256个3x3的卷积核,三次卷积,ReLU激活,尺寸变为56x56x256
6)max pooling池化,尺寸变为28x28x256
7)经512个3x3的卷积核,三次卷积,ReLU激活,尺寸变为28x28x512
8)max pooling池化,尺寸变为14x14x512
9)经512个3x3的卷积核,三次卷积,ReLU,尺寸变为14x14x512
10)max pooling池化,尺寸变为7x7x512
11)然后Flatten(),将数据拉平成向量,变成一维51277=25088。
11)再经过两层1x1x4096,一层1x1x1000的全连接层(共三层),经ReLU激活
12)最后通过softmax输出1000个预测结果
- 权重参数(不考虑偏置)
1)输入层有0个参数,所需存储容量为224x224x3=150k
2)对于第一层卷积,由于输入图的通道数是3,网络必须要有通道数为3的的卷积核,这样的卷积核有64个,因此总共有(3x3x3)x64 = 1728个参数。
所需存储容量为224x224x64=3.2M
计算量为:输入图像224×224×3,输出224×224×64,卷积核大小3×3。所以Times=224×224×3x3×3×64=8.7×107
3)池化层有0个参数,所需存储容量为 图像尺寸x图像尺寸x通道数=xxx k
4)全连接层的权重参数数目的计算方法为:前一层节点数×本层的节点数。因此,全连接层的参数分别为:
7x7x512x4096 = 1027,645,444
4096x4096 = 16,781,321
4096x1000 = 4096000
按上述步骤计算的VGG16整个网络总共所占的存储容量为24M*4bytes=96MB/image 。所有参数为138M
VGG16具有如此之大的参数数目,可以预期它具有很高的拟合能力;但同时缺点也很明显:
即训练时间过长,调参难度大。
需要的存储容量大,不利于部署。
-
时间复杂度
1)卷积层的时间复杂度大致是同一数量级的
2)随着网络深度加深,卷积层的空间复杂度快速上升(每层的空间复杂度是上层的两倍)
3)全连接层的空间复杂度比卷积层的最后一层还大 -
特点
1)小的卷积核 :3x3的卷积核
2)小的池化核 :2x2的池化核
3)层数更深特征图更宽 :基于前两点外,由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,计算量缓慢的增加;
4)全连接转卷积 :网络测试阶段将训练阶段的三个全连接替换为三个卷积,测试重用训练时的参数,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入。 -
感受野
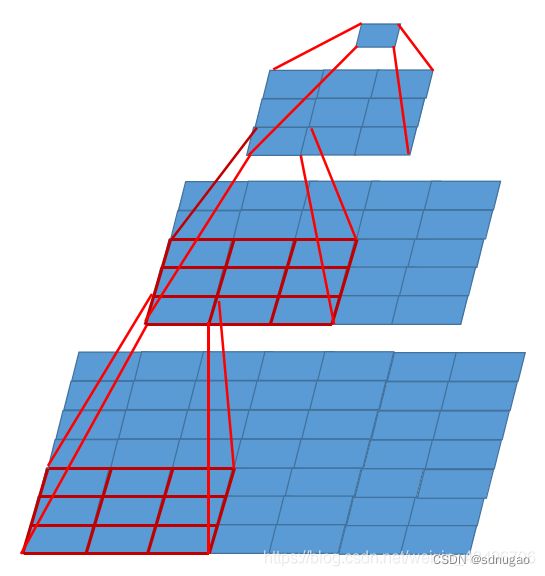
VGG主要使用较小的卷积核代替较大的卷积核。在VGG16中,作者认为两个3x3的卷积堆叠获得的感受野大小,相当一个5x5的卷积;而3个3x3卷积的堆叠获取到的感受野相当于一个7x7的卷积。这样做一方面可以减少参数,增加了网络深度,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合/表达能力。

1)替代性
下图为2个3x3的卷积核代替1个5x5

下图为3个3x3的卷积核代替1个7x7
2)参数减少
对于2个3x3卷积核,所用的参数总量为2x(3x3)xchannels, 对于1个5x5卷积核为5x5xchannels
对于3个3x3卷积核,所用的参数总量为3x(3x3)xchannels, 对于1个7x7卷积核为7x7xchannels
因此可以显著地减少参数的数量。
————————————————
版权声明:本文为CSDN博主「飞」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_43496706/article/details/101210981
2.全面理解VGG16模型
VGG16的结构层次
介绍结构图
VGG16模型所需要的内存容量
介绍卷积中的基本概念
1.从input到conv1:
2.从conv1到conv2之间的过渡:
3.conv2到conv3:
4.进入conv3:
5.从conv3到conv4之间的过渡:
6.最后到三层全连接FC层
结论
VGG16的结构层次
vgg16总共有16层,13个卷积层和3个全连接层,第一次经过64个卷积核的两次卷积后,采用一次pooling,第二次经过两次128个卷积核卷积后,再采用pooling,再重复两次三个512个卷积核卷积后,再pooling,最后经过三次全连接。附上,官方的vgg16网络结构图:
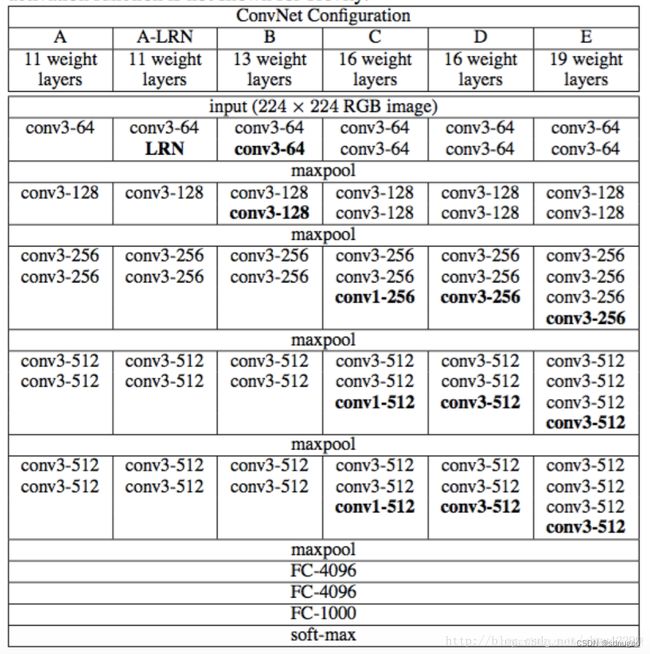
介绍结构图
首先需要看懂上图中的一些式子含义,如conv3-64,conv3-125
conv3-64 :是指第三层卷积后维度变成64,同样地,conv3-128指的是第三层卷积后维度变成128;
input(224x224 RGB image) :指的是输入图片大小为224244的彩色图像,通道为3,即2242243;
maxpool :是指最大池化,在vgg16中,pooling采用的是22的最大池化方法(如果不懂最大池化,下面有解释);
FC-4096 :指的是全连接层中有4096个节点,同样地,FC-1000为该层全连接层有1000个节点;
padding:指的是对矩阵在外边填充n圈,padding=1即填充1圈,5X5大小的矩阵,填充一圈后变成7X7大小;
最后补充,vgg16每层卷积的滑动步长stride=1,padding=1,卷积核大小为333;
VGG16模型所需要的内存容量
此处引用大佬的一张图片来说明:

上图,非常清晰地展示了每经过一次卷积或pooling后,所需要占用的内存,以及需要传送的权重值个数。
介绍卷积中的基本概念
什么是卷积? 最直观的解释,直接上图(引用网上最火的图片)

image为需要进行卷积的图片,而convolved feature为卷积后得到的特征图;那么什么是卷积的过滤器也就是filter呢?图中黄色矩阵即为filter,image为5X5大小的一维图像,filter为3X3大小的一维矩阵;卷积过程是:filter与image对应位置相乘再相加之和,得到此时中心位置的值,填入第一行第一列,然后在移动一个格子(stride=1),继续与下一个位置卷积…最后得到是3X3X1的矩阵。
——这里需要注明:卷积后的结果矩阵维度=(image矩阵维数-filter矩阵维数+2xpad)/2+1,对应上图即宽width:3=(5-3+2x0)/1+1,高height:3=(5-3+2x0)/1+1;
如果还不懂,请接着看下图(为博主自己手写的卷积过程图)

在这里补充经过padding填充,那么卷积后图片大小不会发生改变,如5X5的图像大小,padding=1变成7X7,再用3X3的filter进行卷积,那么卷积后的宽高为(7-3+2x1)/1+1=7。
什么是maxpool? 最大池化就是取filter对应区域内最大像素值替代该像素点值,其作用是降维。在这里,池化使用的滤波器都是2*2大小,因此池化后得到的图像大小为原来的1/2。下图为最大池化过程:

介绍完基本概念之后,就开始进入到理解VGG16的网络模型了
1.从input到conv1:
由于224不太好计算,那么这里使用input图片大小为300x300x3举例:
图片:

首先两个黄色的是卷积层,是VGG16网络结构十六层当中的第一层(Conv1_1)和第二层(Conv1_2),合称为Conv1。
那么,第一层怎么将300x300x3的矩阵变成一个300x300x64的呢??

假设RGB图像为蓝色框,橙色方块为3x3x3的卷积核(即filter),那么卷积后得到的图像应为298x298x1(此处没有进行padding,步长为1),但是经过填充一圈的矩阵,所以得到的结果为300x300x1,在这层中有64个卷积核,那么原来的300x300x1就变成了300x300x64。
2.从conv1到conv2之间的过渡:
在上面的结构图可以看到,第一层卷积后要经过pooling,才到第二层,那么:
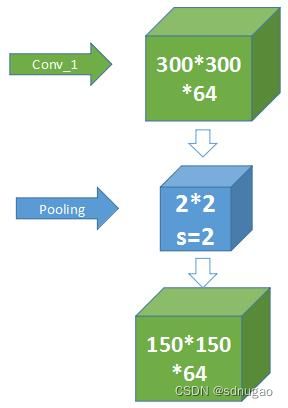
这层,pooling使用的filter是2x2x64,且步长为2,那么得到的矩阵维数刚好为原来的一半,第三个维度64不改变,因为那个指的是filter个数。
3.conv2到conv3:
我们从上面的过程中知道了,input为300x300x3的图片,经过第一层之后变成150x150x64,那么第二层里面有128个卷积核,可以推出经过第二层后得到是75x75x128。
4.进入conv3:

可知,第三层有256个卷积核,那么得到就是75x75x256
5.从conv3到conv4之间的过渡:

这里75是奇数,经过pad之后变成偶数76,那么就得到结果为38x38x256
其余的过程与上述一样,最终得到10x10x512。
6.最后到三层全连接FC层
在全连接层中的每一个节点都与上一层每个节点连接,把前一层的输出特征都综合起来。在VGG16中,第一个全连接层FC1有4096个节点,上一层pool之后得到是10x10x512=51200个节点,同样第二个全连接层FC2也有4096个节点,最后一个FC3有1000个节点。
结论
上述对VGG16进行了初步深入的理解,还有很多知识点没写,不足之处请多多原谅。另外本博文也参考了其他文章,图片来源于网络。
参考文章:
[1]: (https://blog.csdn.net/gbyy42299/article/details/78969261]
[2]: [http://mini.eastday.com/mobile/180329080222874.html#]
[3]: https://www.jianshu.com/p/a4b8b0fc7d21
————————————————
版权声明:本文为CSDN博主「Florrie Zhu」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Resume_f/article/details/92800997