决策树经典算法ID3——我的第一篇博客
简介
决策树是机器学习中一种常见的分类算法,属于有监督学习算法(至于什么是有监督学习,什么是无监督学习读者可以自行百度)。决策树算法有多种,ID3算法是其中一种经典的决策树算法,这种算法的核心是信息熵(至于什么是信息熵,后面会进行详细介绍)。现在已经商用的决策树算法C45,C50等都是在ID3的基础上进行改进优化而来。
一些术语
1、分类特征
比如一个数据集有A、B、C、D、E五个属性(或者说五个字段),这五个属性不是相互独立的,而是存在某种联系,基于这种联系可
以通过其中某些属性的取值,确定另外一个或多个的属性的值,例如通过属性A、B、C、D的取值就可以确定E的取值。决策树算法就是用来对这些属性间的联系进行建模,确定这种联系,此时有一条新的记录A1、B1、C1、D1,在属性E1位置的情况下就可以通过这种模型对E1的取值进行预测。这听起来是不是和回归分析的思想很像,事实上回归分析主要用来处理连续的数据,而经典的ID3算法只能用来处理离散值,基于ID3算法改进的C45和C50可以用来处理连续值。
说了这么多,那什么是分类特征呢?上述用于构建决策树的属性A、B、C、D就是分类特征,属性E的取值就是我们要确定的类别。
2、信息熵
第一次接触熵这个概念是在高中学化学的时候,好像是用来分析化学反应的能量走向,具体是怎么用的,也记不太清了。事实上化学里的熵就是由信息论中的熵——信息熵引申而来,而信息熵是由“信息论之父”香农提出的 。
信息熵是一组数据混乱程度的度量,取值范围在0-1之间,信息熵越大,数据越混乱,越没有规律,越不利于进行建模和分类。信息熵的计算公式如下:
![]()
下面以具体的例子讲解信息熵的计算方法:

上面是一组是否购买电脑的问卷调查记录,根据这组数据构建决策树,研究是否购买电脑与年龄、收入层次、是否单身、信用等级四个属性间的关系。这组数据的信息熵计算方法如下:
购买电脑的记录:9个 概率p1=9/14,不买电脑的记录5个,概率5/14,因此信息熵H=-9/14log2(9/14)-5/14log2(5/14)=0.94028。计算得到的信息熵接近于1,说明数据集的混乱程度较大,不做任何处理,直接基于这组数据集判断一个人是否购买电脑出错的可能性大。
3、信息增益
信息熵用来描述一组数据的混乱程度,而信息增益正好相反,信息增益是用来描述一组数据从状态0过渡到状态1是确定性增加程度的度量。信息增益越大,数据的确定性增加的越多。
构建决策树的过程就是对一组数据不断分类细化的过程。在对是否购买电脑那组数据进行分类时,可以考虑年龄、收入层次、是否单身、信用等级四个分类特征,但在利用这四个分类特征进行分类时应该有先后顺序,是先用年龄为参考进行分类,还是先用其它三个分类特征中的一个进行分类,判断的依据就是信息熵。
假设以年龄为分类特征,则上面这组数据可以被分为以下三类:
青少年4人:这组数据的信息熵H1=-3/5log2(3/5)-2/5log2(2/5)=0.97095

中年4人:这组数据的信息熵H2=-1log2(1)-0log2(0)=0
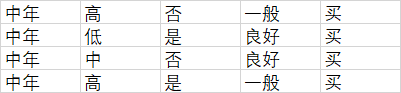
老年人5人:这组数据的信息熵H3=-3/5log2(3/5)-2/5log2(2/5)=0.97095

基于以上计算结果可知当以年龄为当前分类特征时的信息熵为H_age=5/14H1+4/14H2+5/14*H3=0.69496,由之前计算可知,不考虑任何分类特征的整体信息熵H_total=0.94028。据此可得在以年龄为当前分类特征后,数据集的信息熵变化值ΔH=H_total-H_age=0.24532,信息熵变小,数据的混乱程度降低,确定性增加,而确定性增加的度量值信息增益就等于信息熵的变化值ΔH,即年龄这个属性的信息增益就等于ΔH=0.24532。
4、最佳分类特征
根据上述信息增益的计算方式,分别计算年龄,收入层次,信用等级和是否单身的信息增益,信息增益最大的属性,对数据集的确定性增加的最多,最有利于当前的分类,应当作为当前优先考虑的特征,该属性即为当前最佳分类特征。

决策树的构建过程
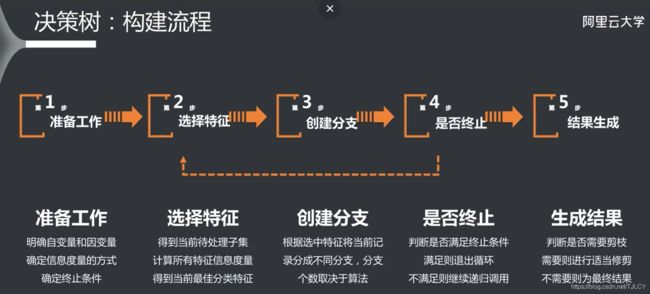
决策树的构建是一个递归调用的过程,其流程图如下:
注意事项
1、终止条件的选择
上面说过决策树的构建是一个递归调用的过程,既然是递归就必定有递归终止条件,常用的递归终止条件有以下几种
- 最小记录数:如果当前要进行递归分类的数据集记录数已经小于最小记录数比如5,此时由于记录数很小已经没有必要再继续向下进行递归分类,直接对当前的数据集进行分类统计,以记录数最多的类别为最终类别
- 数据纯度:如果当前数据集所有的记录都已经属于同一类别,则也没有继续向下递归调用,细分的必要。注意:选择数据纯度为递归终止条件,可能出现一种情况,就是当前的数据集虽然纯度不为100%,但是已经没有可以继续向下分类的属性了,即所有的属性都已经在之前作为最佳分类特征用于分类了,此时应当通过投票原则确定最后所属的类别。
- 最大递归次数:当递归深度达到了最大递归次数时,为了防止过拟合,此时通过投票原则确定当前所属的类别,停止递归。
2、训练样本不完善的处理
对于这一点,以具体的例子进行说明。下面是通过例子中的数据所构建的决策树:

在构建决策树的过程中可能出现这样一种情况:用来构建决策树的数据集即训练样本数据不完善,比如对于信用等级这个属性,训练样本中只有良好和一般这两种取值。当用测试样本对构建的决策树进行测试时,可能存在某一条记录的信用等级属性为优秀或差,由于构建的决策树根本没有这两个分支,就会造成测试样本验证出现死循环或验证错误(实际上对于这种情况,我刚开始并没有考虑到,是在算法验证的过程中程序报错,出现死循环,经过很长时间排查才发现的)。对于这种情况,我的解决办法是,在构建决策树的过程中,对每一个节点(子数据集)都进行一次投票,即不考虑继续向下细分的情况下,该节点最终所属的类别。在进行算法验证时,若一条记录找不到继续向下的子树但又没有达到递归终止条件,就以节点投票所属的类别作为该条记录最终的类别。
3、对于决策树的表示
算法实现我采用的编程语言为python,使用列表来保存最终生成决策树,结构如下?dt=[父边,根节点,投票类别,[子树1],[子树2],[子树3],…………]。还是以例子中的数据为例,最终生成的决策树结构如下:
[None, '年龄', '买', ['青少年', '是否单身', '不买', ['否', '不买', '不买', [], []], ['是', '买', '买', [], []]], ['中年', '买', '买', [], []], ['老年', '信用等级', '买', ['一般', '买', '买', [], []], ['良好', '不买', '不买', [], []]]]
算法验证
我采用的是交叉验证策略对实现的算法进行验证,数据集为car_evalution,包括buying-购买价格,maint-保养价格,doors-车门数,persons-载客数,lug-boot-后备箱容积,safety-安全性六个属性,通过这六个属性来判断一辆车的性价比type。
具体来讲就是将样本随机分为10份,其中9份样本作为训练集用来构建决策树,剩余1份样本作为测试集用来进行测试,循环进行,直到每一份样本都作为测试集进行测试,输出每一份测试集的准确率以及最后是10份样本的综合准确略,最终的结果如下:
![]()
从以上验证结果可知:构建的决策树预测的准确性较高,但有时候并不是越高越好,过高的预测准确率意味着可能存在过拟合的现象
总结
(偷点懒放一张图片吧)
代码和数据:
百度云:(https://pan.baidu.com/s/1A_J0d0rzHFpfhwLyg7Lg-Q 提取码:bdmp
CSDN:https://download.csdn.net/download/TJLCY/15111664
扯点废话
第一篇博客,从决定写到完成差不多花了一天的时间。之前在CSDN上看过很多人的博客,就想着自己哪天也在上面写点啥,但总是一拖再拖:一是因为自己很懒,文笔也很烂,怕写了大家看不懂,浪费自己时间也浪费大家时间,实在罪过。二是自己是个菜鸟,也没什么干货可以写,还是不要制造没有营养的学术垃圾了。后来想通了,写的菜就菜吧,权当是一点学习心得了,再加上寒假有时间,于是就诞生了这篇博客,很有可能是最后一篇(写博客就像记笔记一样对懒人太痛苦了)。