【今日CV 计算机视觉论文速览 第147期】Tue, 23 Jul 2019
今日CS.CV 计算机视觉论文速览
Tue, 23 Jul 2019
Totally 52 papers
?上期速览✈更多精彩请移步主页

Interesting:
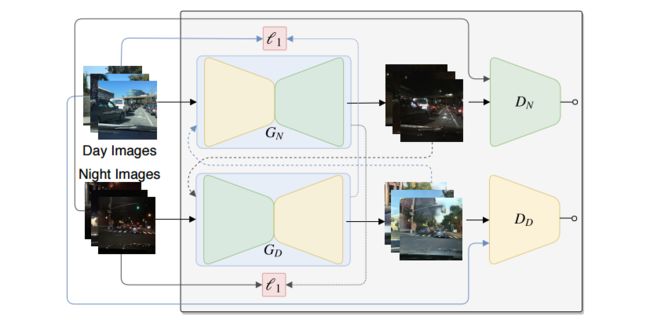
?基于图像迁移的夜间车辆检测, 提出了一种利用白天的标记数据训练夜晚无标记数据的目标检测方法,基于生成对抗网络来生成黑夜图像的标记,随后利用GAN生成的图像来训练模型进行夜间检测。(from Universidade Federal do Esp´ırito Santo)

基于cycleGAN的图像迁移模型:
一些迁移后的样本和效果:

?基于RGB-D的目标检测综述参考书, 针对传统方法和深度学习方法进行了综述(from 西澳大利亚大学)

author:http://isaacronaldward.com/
?基于深度学习目标检测综述, 分析了现有的典型检测方法和数据集,提供了针对各种方法系统同的测评,列出了各种应用场景。给出了一些开放问题和未来的发展方向。(from 西安交大)
典型应用包括安防、军事、交通、医学、家居,还包括弱监督检测、显著性检测、强调检测、边缘检测、文本检测、多域的通用能力和视频目标检测、3D位姿检测等等。未来趋势将在视频、后处理法、弱监督、多领域、3D、显著性、无监督、多任务、多传感器、移动终端、医学生物、遥感和实时检测以及GAN相关的应用中发展。
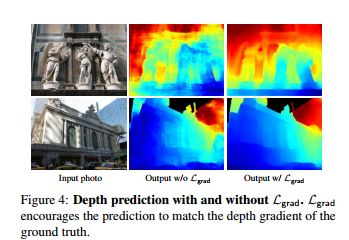
?MegaDepth单视图深度重建, 包含了一个深度数据集MegaDepth,可用于深度预测、深度图修复等。同时提出了基于图像的深度估计网络。(from 康奈尔大学)
文章中几种损失函数值得学习,包括L1,梯度匹配损失以及顺序ordinal损失

website:http://www.cs.cornell.edu/projects/megadepth/
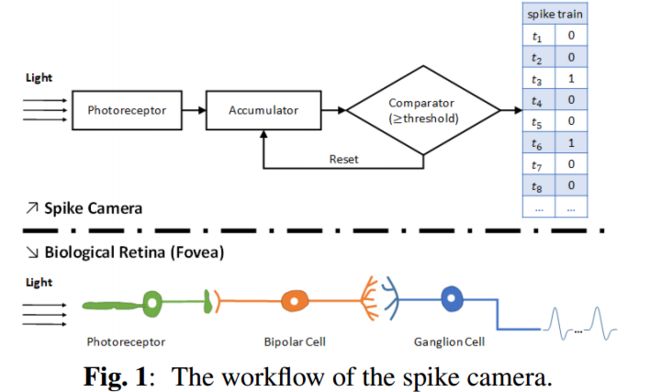
?视网膜启发的针对动态视觉传感器采样方法用于视觉纹理重建, (from 北大)
Daily Computer Vision Papers
| Automatic detection of multiple pathologies in fundus photographs using spin-off learning Authors Gwenol Quellec, Mathieu Lamard, Pierre Henri Conze, Pascale Massin, B atrice Cochener 在过去的几十年中,在糖尿病视网膜病变DR筛查网络中收集了大量的眼底照片数据集。通过深度学习,这些数据集被用于训练DR的自动检测器和一些其他常见病理,目的是自动筛查。迄今为止,一个挑战限制了这种系统的采用,自动检测器忽略了眼科医生目前检测到的罕见病症。为了解决这个限制,我们提出了一种新的机器学习ML框架,称为旋转学习,用于自动检测稀有条件。该框架扩展了针对频繁条件训练的卷积神经网络CNN,其具有用于罕见状况检测的无监督概率模型。旋转学习是基于以下观察:CNN经常感知包含相同异常的照片,即使这些CNN被训练以检测不相关的条件。这个观察是基于t SNE可视化工具,我们决定将其包含在我们的概率模型中。离散学习支持热图生成,因此可以在图像中突出显示检测到的异常以供决策支持。在来自OPHDIAT筛选网络的160,000多次筛选检查的数据集中的实验表明,脱离学习可以检测出41个中的37个条件,其中ROC曲线下面积AUC大于0.8平均AUC 0.938。特别是,离散学习明显优于其他候选ML框架,用于检测罕见条件多任务学习,转移学习和一次性学习。我们希望这些更丰富的预测能够引发自动眼病理筛查,这将彻底改变眼科临床实践。 |
| Multi-Class Lane Semantic Segmentation using Efficient Convolutional Networks Authors Shao Yuan Lo, Hsueh Ming Hang, Sheng Wei Chan, Jing Jhih Lin 车道检测在自驾车中起着重要作用。一些研究利用语义分割网络来提取稳健的泳道特征,但很少有人能够区分不同类型的泳道。在本文中,我们关注多类车道语义分割的问题。基于观察到车道是道路场景图像中的小尺寸和窄宽度物体,我们提出了两种技术,特征尺寸选择FSS和减压膨胀块DD块。 FSS允许网络使用适当的特征尺寸提取薄道特征。为了获得细粒度的空间信息,DD Block由一系列扩张的卷积构成,具有递减的扩张率。实验结果表明,与基线系统相比,所提出的技术在准确性方面提供了明显的改进,同时它们实现了相同或更快的推理速度,并且可以在高分辨率图像上实时运行。 |
| k-t NEXT: Dynamic MR Image Reconstruction Exploiting Spatio-temporal Correlations Authors Chen Qin, Jo Schlemper, Jinming Duan, Gavin Seegoolam, Anthony Price, Joseph Hajnal, Daniel Rueckert 动态磁共振成像MRI在k空间和时间上表现出高度相关性。为了加速动态磁共振成像并利用来自高度欠采样数据的k t相关,我们在此提出一种新的基于深度学习的动态MR图像重建方法,称为k t NEXT k t NEtwork with X f Transform。特别是,受k t BLAST和k t FOCUSS等传统方法的启发,我们建议从x f域中的混叠信号重建真实信号,以利用时空冗余。在此基础上,所提出的方法然后通过以迭代方式交替x f空间和图像空间之间的重建过程来学习恢复信号。这使得网络能够有效地捕获有用信息并共同利用来自两个互补域的时空相关性。在高度欠采样的短轴心脏电影MRI扫描上进行的实验表明,我们提出的方法在数量和质量上都优于现有技术的动态MR重建方法。 |
| ++卫星地表覆盖分类Satellite-Net: Automatic Extraction of Land Cover Indicators from Satellite Imagery by Deep Learning Authors Eleonora Bernasconi, Francesco Pugliese, Diego Zardetto, Monica Scannapieco 在本文中,我们通过深度学习DL解决了卫星图像土地覆盖分类的挑战。土地覆盖旨在探测领土的物理特征,并估算某类实体植被,住宅建筑,工业区,森林区,河流,湖泊等占用土地的百分比.DL是大数据分析的新范例特别是对于计算机视觉。由于高度自动化和计算性能,DL在土地覆盖目的图像分类中的应用具有很大的潜力。特别地,卷积神经网络CNN的发明是该领域的进步的基础。 1,联合国全球工作组的卫星任务组介绍了迄今为止在官方统计中使用地球观测所取得的成果。然而,在该研究中,尚未探索CNN用于图像的自动分类。这项工作调查了CNN用于估算土地覆盖指标的用途,提供了第一个有希望的结果的证据。特别是,该论文提出了一种称为卫星网的定制模型,能够在测试集上达到高达98的精度水平。 |
| A Survey of Deep Learning-based Object Detection Authors Licheng Jiao, Fan Zhang, Fang Liu, Shuyuan Yang, Lingling Li, Zhixi Feng, Rong Qu 对象检测是计算机视觉中最重要,最具挑战性的分支之一,它已被广泛应用于人们的生活中,如监视安全性,自动驾驶等,目的是定位某类语义对象的实例。随着用于检测任务的深度学习网络的快速发展,对象检测器的性能得到了极大的提高。为了更深入地了解目标检测管道的主要发展现状,本次调查首先分析了现有典型检测模型的方法,并对基准数据集进行了描述。之后,我们主要以系统的方式全面概述各种物体检测方法,包括一级和两级探测器。此外,我们列出了传统和新的应用程序。还分析了一些代表性的物体检测分支。最后,我们讨论利用这些目标检测方法构建一个有效和高效的系统的架构,并指出一套发展趋势,以更好地遵循最先进的算法和进一步的研究。 |
| +古文献图像检索Deep Learning Approaches for Image Retrieval and Pattern Spotting in Ancient Documents Authors Kelly Lais Wiggers, Alceu de Souza Britto Junior, Alessandro Lameiras Koerich, Laurent Heutte, Luiz Eduardo Soares de Oliveira 本文介绍了使用深度学习在文档图像中进行基于内容的图像检索和模式定位的两种方法。第一种方法使用预先训练的CNN模型来应对训练数据的缺乏,训练数据经过精细调整以实现查询和候选图像的紧凑但有区别的表示。第二种方法使用在ImageNet数据集的先前准备的图像对子集上训练的Siamese卷积神经网络,以提供基于相似性的特征图。在这两种方法中,学习的表示方案考虑了不同大小的特征图,这些特征图根据检索性能进行评估。使用两个公共数据集Tobacoo 800和DocExplore的强大实验方案已经表明,所提出的方法与现有技术文档图像检索和模式定位方法相比是有利的。 |
| Markerless Augmented Advertising for Sports Videos Authors Hallee E. Wong, Osman Akar, Emmanuel Antonio Cuevas, Iuliana Tabian, Divyaa Ravichandran, Iris Fu, Cambron Carter 无标记增强现实可以是具有挑战性的计算机视觉任务,尤其是在直播设置中以及缺少与视频捕获相关的信息(例如固有的相机参数)。这通常需要熟练的艺术家的帮助,以及在后期制作环境中使用高级视频编辑工具。我们提出了一种自动视频增强管道,用于识别感兴趣的纹理并将广告叠加到这些区域上。我们限制广告以美观和自然的方式放置。目的是增加场景,使不再需要商业休息。为了实现广告与原始视频的无缝集成,我们构建场景的3D表示,将广告放置在3D中,然后将其投影回图像平面。在成功放置在单个帧中之后,我们使用基于单应性的形状保持跟踪,使得广告在视频剪辑的持续时间内看起来是透视正确的。跟踪器设计用于处理平滑的摄像机运动和镜头边界。 |
| Domain-Specific Priors and Meta Learning for Low-shot First-Person Action Recognition Authors Huseyin Coskun, Zeeshan Zia, Bugra Tekin, Federica Bogo, Nassir Navab, Federico Tombari, Harpreet Sawhney 缺乏具有注释的大规模真实数据集会使学习成为视觉活动的必要条件。在此范围内,我们的目标是开发一种有效的低射击转移学习方法,用于第一次人员分类。我们利用独立训练的视觉线索来学习可以从源域提供表示的表示,只需少量示例即可提供原始动作,并提供目标域。这些视觉提示包括对象对象交互,handgrasps和区域内的运动。是手铐的功能。我们建议一个基于元学习的框架,以适当地提取部署的视觉线索的独特和域invari ant组件,以便能够跨越用不同场景配置捕获的公共数据集传输动作分类模型。我们彻底评估了我们的方法,并报告了对于同类和数据集间转移的艺术行为分类方法夸大的有希望的结果。 |
| +++恢复被遮挡的图像Visualizing the Invisible: Occluded Vehicle Segmentation and Recovery Authors Xiaosheng Yan, Yuanlong Yu, Feigege Wang, Wenxi Liu, Shengfeng He, Jia Pan 在本文中,我们提出了一个新的迭代多任务框架来完成被遮挡车辆的分割掩模并恢复其不可见部分的外观。特别是,为了提高分割完成的质量,我们提出了两个耦合鉴别器,并引入了一个辅助3D模型池,用于将真实轮廓作为对抗样本进行采样。此外,我们提出了一种具有共享网络的双路径结构,以增强外观恢复能力。通过迭代地执行分割完成和外观恢复,结果将逐步细化。为了评估我们的方法,我们提出了一个数据集,Occluded Vehicle数据集,包含合成和真实世界被遮挡的车辆图像。我们对该数据集进行了对比实验,并证明我们的模型在恢复分段掩模和闭塞车辆外观的任务方面优于现有技术水平。此外,我们还证明了我们的外观恢复方法可以使现实世界视频中的遮挡车辆跟踪受益。 作者:http://cmcs.fzu.edu.cn/website/f/teacherDetail?id=212 |
| DeepIris: Iris Recognition Using A Deep Learning Approach Authors Shervin Minaee, Amirali Abdolrashidi 在过去的几十年里,虹膜识别一直是一个活跃的研究领域,因为它在安全方面的广泛应用,从机场到国土安全边界控制。过去已经提出了用于虹膜识别的不同特征和算法。在本文中,我们提出了一种基于残差卷积神经网络CNN的虹膜识别端到端深度学习框架,可以共同学习特征表示并进行识别。我们使用来自每个类的少量训练图像在众所周知的虹膜识别数据集上训练我们的模型,并且显示出有希望的结果和对先前方法的改进。我们还提出了一种可视化技术,能够检测虹膜图像中的重要区域,这些区域主要影响识别结果。我们相信这个框架可以广泛用于其他生物识别识别任务,有助于拥有更具可扩展性和准确性的系统。 |
| +Trends in Integration of Vision and Language Research: A Survey of Tasks, Datasets, and Methods Authors Aditya Mogadala, Marimuthu Kalimuthu, Dietrich Klakow 由于来自多学科社区的兴趣激增,例如深度学习,计算机视觉和自然语言处理,近期视觉和语言任务的整合已经显着增长。在本次调查中,我们将重点放在十个不同的愿景和语言整合任务上,包括问题的制定,方法,现有的数据集,评估指标以及与相应的现有技术方法所取得的成果的比较。这超出了早期的调查,这些调查要么是任务特定的,要么只集中在一种类型的视觉内容上,即图像或视频。然后,我们通过讨论视觉和语言研究整合的未来可能方向来结束调查。 |
| An Efficient Method of Detection and Recognition in Remote Sensing Image Based on multi-angle Region of Interests Authors Hongyu Wang, Wei Liang, Guangcun Shan 目前,深度学习技术已广泛应用于图像识别领域。然而,它主要旨在识别和检测普通图片和普通场景。遥感图像作为特殊图像,与普通图像相比具有不同的拍摄角度和拍摄方式,使遥感图像在某些区域发挥着不可替代的作用。本文基于深度卷积神经网络提供图像的多层次信息,并结合RPN区域建议网络生成多角度ROIs感兴趣区域,提出了一种新的遥感图像目标检测与识别模型。在实验中,它取得了比传统方法更好的结果,这表明这里提出的模型在遥感图像识别中具有巨大的潜在应用。 |
| A-Phase classification using convolutional neural networks Authors Edgar R. Arce Santana, Alfonso Alba, Martin O. Mendez, Valdemar Arce Guevara 在NREM睡眠期间,可以在人脑电图中观察到一系列称为A期的短事件。这些事件可根据其光谱内容分为三组A1,A2和A3,并被认为在不同睡眠阶段之间的转换中起作用。相位检测和分类通常由经过培训的专家手动执行,但这是一项繁琐且耗时的任务。在过去二十年中,各种研究人员设计了自动检测和分类A阶段的算法,并取得了不同程度的成功,但问题依然存在。在本文中,提出了一种不同的方法,而不是尝试为所有主题设计一般分类器,我们建议使用尽可能少的数据为每个主题训练临时分类器,以便大大减少所需的时间量。专家。所提出的分类器基于深度卷积神经网络,使用EEG信号的对数谱图作为输入数据。结果令人鼓舞,在区分A阶段和非A阶段时达到80.31的平均准确度,在A阶段子类型中进行分类时达到71.87,其中仅有25个A阶段用于训练。当考虑额外的专家验证数据时,子类型分类准确度增加到78.92。这些结果表明,在专家的帮助下,半自动注释系统可以为全自动分类器提供更好的替代方案。 |
| +++基于概率的点云重建方法Probabilistic Point Cloud Reconstructions for Vertebral Shape Analysis Authors Anjany Sekuboyina, Markus Rempfler, Alexander Valentinitsch, Maximilian Loeffler, Jan S. Kirschke, Bjoern H. Menze 我们提出了一种用于点云PC的自动编码网络架构,能够在没有监督的情况下提取形状签名。在此基础上,我们设计了一种能够对非结构化PC上的数据差异进行建模的损失函数,并且在变量自动编码器中对潜在空间进行规范化,这两者都增加了自动编码器的描述能力,同时使其具有概率性。评估我们的建筑物的重建质量,我们使用它们来检测椎骨骨折,无需任何监督。通过学习有效地重建健康的椎骨,骨折被检测为异常重建。评估包含sim 1500椎骨的数据集,我们在ROC曲线下获得75的面积,而不使用基于强度的特征。 |
| Quadruplet Selection Methods for Deep Embedding Learning Authors Kaan Karaman, Erhan Gundogdu, Aykut Koc, A. Aydin Alatan 对具有细微差别的物体的识别已经在许多实际应用中使用,例如汽车模型识别和海上船舶识别。为了区分细粒度细节中的对象,我们通过使用多任务学习框架来关注深度嵌入学习,其中样本的分层标签粗略和精细标签用于分类和基于四元组的损失函数。为了提高学习特征的识别强度,我们提出了一种专门为四个训练样本设计的新特征选择方法。通过实验,观察到,与随机选择四联体样品相比,从相同的粗类和细类中选择具有相对容易的正样品的非常硬的负样品显着增加了细粒度数据集中的一些性能指标。通过所提出的方法学习的特征嵌入实现了针对其现有技术对应物的有利性能。 |
| RGB-D image-based Object Detection: from Traditional Methods to Deep Learning Techniques Authors Isaac Ronald Ward, Hamid Laga, Mohammed Bennamoun RGB图像的物体检测是图像处理和计算机视觉中长期存在的问题。它适用于各种领域,包括机器人,监视,人机交互和医疗诊断。随着低成本3D扫描仪的可用性,在过去几年中已经提出了大量RGB D物体检测方法。本章对该领域的最新发展进行了全面的调查。我们将本章分为两部分,第一部分的重点是基于手工制作的特征与机器学习算法相结合的技术。第二部分的重点是最近的工作,这是基于深度学习。深度学习技术,加上大型训练数据集的可用性,现在已经彻底改变了计算机视觉领域,包括RGB D物体检测,实现了前所未有的性能水平。我们调查了主要贡献,总结了最常用的管道,讨论了它们的优点和局限性,并重点介绍了未来研究的一些重要方向。 |
| +全景视觉下的计算机视觉Adapting Computer Vision Algorithms for Omnidirectional Video Authors Hannes Fassold 全向360视频非常受欢迎,因为它提供了极具沉浸感的观看体验。对于计算机视觉算法,它提出了一些挑战,例如通常采用的特殊的等角矩形投影和巨大的图像尺寸。在这项工作中,我们对这些挑战进行了高级概述,并概述了如何使计算机视觉算法适应全方位视频的具体策略。 |
| A Single Image based Head Pose Estimation Method with Spherical Parameterization Authors Hui Yuana, Mengyu Lia, Junhui Hou, Jimin Xiao 头部姿势估计在各种应用中起着至关重要的作用,例如,驾驶辅助系统,人机交互,虚拟现实技术等。我们提出了一种新颖的基于几何的算法,用于以非常低的计算成本从单个2D面部图像精确地估计头部姿势。具体地,首先将来自预定义3D面部模型的仅四个非共面特征点的直角坐标以及从2D面部图像自动手动提取的相应特征点的直角坐标归一化以排除外部因素(即比例因子和平移参数)的影响。然后,四个标准化的3D特征点以球形坐标表示,并参考唯一确定的球体。由于球面参数化,特征点的坐标可以有效地沿着直角坐标中的所有三个方向变形。最后,通过最小化归一化2D特征点与变形3D特征点的2D重新投影之间的欧几里德距离来获得指示头部姿势的旋转矩阵。两个流行的数据库,即Pointing 04和Biwi Kinect的综合实验结果表明,与现有技术的基于几何的方法相比,所提出的算法可以以更高的准确度和更低的运行时间来估计头部姿势。即使与基于艺术学习的方法的开始或具有附加深度信息的基于几何的方法相比,我们的算法仍然产生相当的性能。 |
| Image-and-Spatial Transformer Networks for Structure-Guided Image Registration Authors Matthew C.H. Lee, Ozan Oktay, Andreas Schuh, Michiel Schaap, Ben Glocker 深度神经网络的图像配准已经成为一个活跃的研究领域,也是医学成像中长期存在问题的激动人心的途径。目标是学习将输入图像对的外观映射到空间变换的参数的复杂函数,以便对准相应的解剖结构。我们争论并证明当前的直接非迭代方法是次优的,特别是如果我们寻求感兴趣的结构SoI的准确对齐。有关SoI的信息通常在培训时间提供,例如,以分段或地标的形式。我们引入了一种新颖的通用框架,Image和Spatial Transformer Networks ISTN,以利用SoI信息,使我们能够学习针对下游注册任务优化的新图像表示。由于这些表示,我们可以对转换参数采用特定于测试的迭代细化,即使在非常有限的训练数据的情况下也能产生高度准确的配准。在成对3D脑注册和说明性合成数据上展示了性能。 |
| FD-FCN: 3D Fully Dense and Fully Convolutional Network for Semantic Segmentation of Brain Anatomy Authors Binbin Yang, Weiwei Zhang 本文提出了一种基于三维补片的全密集全卷积网络FD FCN,用于快速准确地分割T1加权磁共振图像中的皮层下结构。由开创性的FCN开发,采用端到端学习方法,并由新设计的密集区块(包括密集的完全连接层)构建,所提出的FD FCN与其他基于FCN的方法不同,并且从效率和效率的角度来看都表现出优异的性能。准确性。与U形架构相比,FD FCN丢弃了模型适应度的上采样路径。为了缓解参数爆炸的问题,密集块的输入不再直接传递给后续层。 FD FCN的这种架构大大减少了训练过程中的内存和时间消耗。虽然FD FCN较小,但在模型能力方面,它比其他传统网络具有更好的密集推理能力。这得益于网络架构的构建以及重新设计的密集块的结合。多尺度FD FCN通过在最终预测中嵌入中间层输出来模拟局部和全局上下文,这鼓励在不同尺度下提取的特征之间的一致性并且在细分过程中直接嵌入细粒度信息。此外,重建密集块以扩大感受域而不显着增加参数,并且光谱坐标被用于原始输入补丁的空间上下文。实验在IBSR数据集上进行,FD FCN在53秒内对11个脑结构产生了89.81的整体Dice重叠值的准确分割结果,与现有技术的3D FCN方法相比,骰子精度至少提高了3.66。 。 |
| Polyp Detection and Segmentation using Mask R-CNN: Does a Deeper Feature Extractor CNN Always Perform Better? Authors Hemin Ali Qadir, Younghak Shin, Johannes Solhusvik, Jacob Bergsland, Lars Aabakken, Ilangko Balasingham 由于结肠镜检查期间医生的息肉漏检率约为25,因此结肠筛查非常需要自动息肉检测和分割。然而,由于结肠中的各种息肉样结构和大小,颜色,形状和纹理方面的高级间息肉变异,这种计算机化仍然是一个未解决的问题。在本文中,我们采用Mask R CNN,并利用不同的现代卷积神经网络CNN作为息肉检测和分割的特征提取器来评估其性能。我们通过向训练数据集添加额外的息肉图像来回答每个特征提取器的性能改进,以回答我们是否需要更深和更复杂的CNN或更好的数据集来进行自动息肉检测和分割的训练。最后,我们提出了一种集成方法,以进一步提高性能。我们评估了2015 MICCAI息肉检测数据集的性能。取得的最好成绩是72.59召回,80精度,70.42骰子和61.24 Jaccard。该模型实现了最先进的分割性能。 |
| Sensor Aware Lidar Odometry Authors Dmitri Kovalenko, Mikhail Korobkin, Andrey Minin 提出了一种激光雷达测距方法,将计算机中关于传感器物理知识的知识融入其中。测量误差模型使得点正态协方差的估计具有更高的精度。相邻的激光束用于异常值对应拒绝方案。该方法在KITTI的排行榜中排名为1.37定位误差。与内部数据集上的LOAM方法相比,实现了3.67。 |
| Extended Local Binary Patterns for Efficient and Robust Spontaneous Facial Micro-Expression Recognition Authors Chengyu Guo, Jingyun Liang, Geng Zhan, Zhong Liu, Matti Pietik inen, Li Liu 面部微表情ME是一种自发的,不自主的面部动作,当一个人经历情绪但故意或无意识地试图隐藏他或她的真实情感时。最近,由于其临床诊断,商务谈判,审讯和安全等潜在应用,ME认可引起了越来越多的关注。然而,构建大规模ME数据集是昂贵的,主要是由于难以自然地诱导自发ME。这限制了需要大量训练数据的深度学习技术的应用。在本文中,我们提出了一个简单,有效但强大的描述符,称为三个正交平面ELBPTOP上的扩展局部二进制模式,用于ME识别。 ELBPTOP由三个互补的二进制描述符LBPTOP和两个新的径向差分LBPTOP RDLBPTOP和角度差LBPTOP ADLBPTOP组成,它们探索ME视频序列中包含的径向和角度方向的局部二阶信息。 ELBPTOP是一个新颖的ME描述,灵感来自独特和微妙的面部动作。它具有计算效率,只是略微增加了计算LBPTOP的成本,但对ME识别非常有效。此外,通过首先将白化主成分分析WPCA引入ME识别,我们可以进一步获得更紧凑和有区别的特征表示,并实现显着的计算节省。对三种流行的自发ME数据集SMIC,CASMEII和SAMM的广泛实验评估表明,我们提出的ELBPTOP方法在所有三个评估数据集上明显优于先前的技术水平。我们提出的ELBPTOP在CASMEII上达到73.94,比该数据集上的最新技术水平高6.6。更令人印象深刻的是,ELBPTOP在SAMM数据集上将识别准确度从44.7提高到63.44。 |
| Multi-scale Cell Instance Segmentation with Keypoint Graph based Bounding Boxes Authors Jingru Yi, Pengxiang Wu, Qiaoying Huang, Hui Qu, Bo Liu, Daniel J. Hoeppner, Dimitris N. Metaxas 大多数现有方法直接处理单元实例分段问题,而不依赖于其他检测框。由于缺乏对对象的全局理解,该方法通常不能分离触摸单元。相反,基于框的实例分割通过将对象检测与分割相结合来解决该问题。然而,现有方法通常利用基于锚盒的检测器,由于类不平衡问题,这将导致较差的实例分割性能。在本文中,我们提出了一种新的基于盒子的细胞实例分割方法。特别地,我们首先通过关键点检测来检测细胞的五个预定义点。然后我们根据关键点图对这些点进行分组,然后提取每个单元格的边界框。最后,在边界框内的特征图上执行细胞分割。我们在具有不同对象形状的两个单元数据集上验证我们的方法,并且凭经验证明了我们的方法与其他实例分割技术相比的优越性。代码可在 |
| +++基于特征图学习的点云去噪Feature Graph Learning for 3D Point Cloud Denoising Authors Wei Hu, Xiang Gao, Gene Cheung, Zongming Guo 在许多最近的图谱信号恢复方案中识别反映成对相似性的适当的基础图内核是关键的,包括图像去噪,去量化和对比度增强。现有的图学习算法计算正确定义的图拉普拉斯矩阵mathbf L的最可能的条目,但需要大量的信号观察mathbf z s以获得稳定的估计。在这项工作中,我们假设每个节点i的相关特征向量mathbf f i的可用性,我们通过优化特征度量来计算最佳特征图。具体来说,我们通过最小化图拉普拉斯正则化器GLR mathbf z top mathbf L mathbf z来交替地优化马哈拉诺比斯距离矩阵mathbf M的对角线和非对角线条目,其中边缘权重是wi,j exp mathbf fi mathbf fj top mathbf M mathbf fi mathbf fj,给出一个观察mathbf z。我们通过近端梯度PG优化对角线条目,其中我们通过从Gershgorin圆定理导出的线性不等式将mathbf M约束为正定PD。为了优化非对角线条目,我们设计了一个块下降算法,它迭代地优化了mathbf M的一行和一列。为了保持mathbf M PD,我们将通过PG进行优化时将mathbf M的子矩阵mathbf M 2,2的Schur补码约束为PD。我们的算法减轻了mathbf M的完全特征分解,因此即使在特征向量mathbf f i具有高维度时也能确保快速的计算速度。为了验证其有用性,我们将特征图学习算法应用于3D点云去噪问题,与广泛实验中的竞争方案相比,产生了最先进的性能。 |
| +Real-time Background-aware 3D Textureless Object Pose Estimation Authors Mang Shao, Danhang Tang, Tae Kyun Kim 在这项工作中,我们提出了一种改进的模糊决策森林,用于基于典型模板表示的实时三维物体姿态估计。我们在决策林框架中使用额外的抢占式后台拒绝器节点,以尽早终止对背景位置的检查,从而显着提高效率。我们的方法也可以扩展到大型数据集,因为树结构自然地提供了对象数量的对数时间复杂度。最后,我们使用快速广度优先方案进一步缩短验证阶段。结果表明,我们的方法在保持相当的准确性的同时,在效率方面优于现有技术。 |
| DetectFusion: Detecting and Segmenting Both Known and Unknown Dynamic Objects in Real-time SLAM Authors Ryo Hachiuma, Christian Pirchheim, Dieter Schmalstieg, Hideo Saito 我们提供了一个RGB D SLAM系统DetectFusion,该系统可以实时运行,并且可以稳健地处理可在场景中动态移动的语义已知和未知对象。我们的系统检测,分割和分配语义类标签到场景中的已知对象,同时即使它们在单目摄像机前独立移动也跟踪和重建它们。与相关工作相比,我们通过结合二维物体检测和三维几何分割的新方法,实现了语义实例分割的实时计算性能。另外,我们提出了一种检测和分割语义未知对象运动的方法,从而进一步提高了摄像机跟踪和地图重建的准确性。我们表明,我们的方法在定位和对象重建精度方面与先前的工作相当或更好,而即使在每个帧中对象被分割,也实现大约20 FPS。 |
| Class-specific Anchoring Proposal for 3D Object Recognition in LIDAR and RGB Images Authors Amir Hossein Raffiee, Humayun Irshad 在现实生活应用的环境中检测二维设置中的对象通常是不够的,其中周围环境需要在三维3D中被准确地识别和定向,例如在自动驾驶车辆的情况下。因此,准确和有效地检测三维设置中的对象正变得越来越多地涉及广泛的工业应用,因此逐渐吸引研究人员的注意。然而,建立用于检测3D中的对象的系统是一项具有挑战性的任务,因为它依赖于来自不同来源的数据的多模态融合。在本文中,我们使用当前最先进的3D物体探测器研究锚定效应,并基于物体尺寸和基于长宽比的锚点聚类提出类特定锚定建议CAP策略。所提出的锚定策略在行人等级的简易,中等和硬设置上显着提高了7.19,8.13和8.8的检测精度,在汽车级别的简易,中等和硬设置上显着提高了2.19,2.17和1.27,并且在骑自行车者的简易设置上提高了12.1类。我们还表明,锚定过程中的聚类还可以显着提高区域提案网络在提出利益区域方面的表现。最后,我们为KITTI数据集中的每类对象提出了最佳聚类数,从而显着提高了检测模型的性能。 |
| Shallow Unorganized Neural Networks using Smart Neuron Model for Visual Perception Authors Richard Jiang, Danny Crookes 深度神经网络DNN最近的成功揭示了神经形态计算在许多具有挑战性的应用中的重要能力。尽管DNN来源于模拟生物神经元,但仍然存在对DNN是否是模仿人类智能机制的最终和最佳模型的怀疑。特别是,计算DNN模型与观察到的生物神经元事实之间存在两个差异。首先,人类神经元是随机互连的,而DNN需要精心设计的架构才能正常工作。其次,人类神经元通常具有100ms的长尖峰延迟,这意味着在做出决定时可能不涉及很多层,而DNN可能具有数百层以保证高精度。在本文中,我们提出了一种新的计算神经形态模型,即浅层无组织神经网络SUNN,与DNN相比。提出的SUNN与三个基本方面的标准ANN或DNN不同1 SUNN基于自适应神经元细胞模型Smart Neurons,它允许每个神经元自适应地响应其输入,而不是像神经元模型那样执行固定加权求和运算在人工神经网络DNNs 2 SUNNs仅使用浅层架构处理计算任务3 SUNN具有随机互连的自然拓扑结构,正如人类大脑所做的那样,并且由图灵的B型无组织机器提出。我们实施了所提出的SUNN架构,并在许多无监督的早期视觉感知任务上进行了测试。令人惊讶的是,这种浅层架构在我们的实验中取得了非常好的结果。我们的新计算模型的成功使其成为Turing s B型机器的一个工作示例,可以实现与现有技术相当的或更好的性能。 |
| TARN: Temporal Attentive Relation Network for Few-Shot and Zero-Shot Action Recognition Authors Mina Bishay, Georgios Zoumpourlis, Ioannis Patras 在本文中,我们提出了一种新的时间关注关系网络TARN,用于少数射击和零射击动作识别的问题。我们网络的核心是一种元学习方法,它学习比较可变时间长度的表示,即在少数镜头动作识别或视频和语义表示(如词向量)的情况下,两个不同长度的视频。零射击动作识别的情况。与少数镜头和零镜头动作识别中的其他作品相比,我们利用注意机制以执行时间对准,并且b在视频片段水平上学习对准的表示的深度测量。我们采用基于剧集的培训计划,并以端到端的方式培训我们的网络。所提出的方法不需要在目标域中进行任何微调或者保持额外的表示,如存储器网络的情况。实验结果表明,所提出的结构在少数镜头动作识别中优于现有技术,在零镜头动作识别中取得了有竞争力的效果。 |
| ImageNet-trained deep neural network exhibits illusion-like response to the Scintillating Grid Authors Eric D. Sun, Ron Dekel 用于计算机视觉的深度神经网络DNN模型现在能够进行人类物体识别。因此,DNN的性能和脆弱性与人类视觉的相似性引起了极大的兴趣。在这里,我们描述了VGG 19 DNN对闪烁网格视觉错觉图像的响应,其中白点被认为是部分黑色。我们观察到与闪烁网格中VGG 19表征相异性和点白度之间的预期单调关系的显着偏差。也就是说,点白度的线性增加导致非线性增加,然后显着地减少代表性不相似性中的非单调性。在对照图像中,观察到代表性差异和点白度之间的大多数单调关系。此外,对应于最大代表性不相似性的点白度等级,即非单调性不相似性的开始与对应于人类观察者中的幻觉感知的开始的那些紧密匹配。因此,DNN中的非单调响应是与人类幻觉感知相关的潜在模型。 |
| signADAM: Learning Confidences for Deep Neural Networks Authors Dong Wang, Yicheng Liu, Wenwo Tang, Fanhua Shang, Hongying Liu, Qigong Sun, Licheng Jiao 在本文中,我们提出了一种新的一阶梯度算法来训练深度神经网络。我们首先在基于符号的方法中引入随机梯度的符号运算,例如,将SIGN SGD引入ADAM,其被称为signADAM。此外,为了使每个特征的拟合速率更接近,我们定义了置信度函数来区分梯度的不同分量并将其应用于我们的算法。它可以生成比现有算法更稀疏的梯度。我们称这种新算法为signADAM。特别是,我们的算法都易于实现,并且可以加速各种深度神经网络的训练。 signADAM的动机优选地是通过更新大的和有用的梯度来从最不同的样本学习特征,而不管随机梯度中的无用信息。我们还为算法建立了理论收敛保证。各种数据集和模型的经验结果表明,我们的算法比许多最先进的算法(包括SIGN SGD,SIGNUM和ADAM)产生更好的性能。我们还从多个角度分析绩效,包括损失情况,并开发一种自适应方法,以进一步改善泛化。源代码可在以下位置获得 |
| Image Classification with Hierarchical Multigraph Networks Authors Boris Knyazev, Xiao Lin, Mohamed R. Amer, Graham W. Taylor 图形卷积网络GCN是一类可以从图形结构化数据中学习的通用模型。尽管是一般性的,但是当应用于视觉任务时,GCN被认为不如卷积神经网络CNN,主要是由于缺乏硬编码到CNN中的领域知识,例如空间定向的平移不变滤波器。然而,GCN的一个很大的优点是能够处理不规则输入,例如图像的超像素。这可以显着降低图像推理任务的计算成本。 GCN固有的另一个关键优势是对多关系数据进行建模的自然能力。基于这两个有前途的特性,在这项工作中,我们展示了在某些情况下设计用于图像分类的GCN的最佳实践,甚至优于MNIST,CIFAR 10和PASCAL图像数据集上的CNN。 |
| ++可解释的压缩分类An Interpretable Compression and Classification System: Theory and Applications Authors Tzu Wei Tseng, Kai Jiun Yang, C. C. Jay Kuo, Shang Ho Lawrence Tsai 该研究提出了一种低复杂度的可解释分类系统。所提出的系统包含三个主要模块,包括特征提取,特征减少和分类。所有这些都是线性的。由于线性属性,提取和缩减的特征可以反转到原始数据,如线性变换,例如傅里叶变换,从而可以量化和可视化各个特征对原始数据的贡献。此外,降低的特征和可逆性自然地承受了所提出的系统数据压缩能力。该系统可以在压缩数据和原始数据之间具有小的百分比偏差的情况下显着压缩数据。同时,当压缩数据用于分类时,仍然可以实现高测试精度。此外,我们观察到所提出的系统的提取特征可以近似为不相关的高斯随机变量。因此,经典的估计和检测理论可以应用于分类。这促使我们建议使用MAP最大后验分类方法。结果,提取的特征和相应的性能具有统计意义并且在数学上可解释。仿真结果表明,与传统方案相比,所提出的分类系统不仅大大减少了训练和测试时间,而且测试精度也很高。 |
| Automated Muscle Segmentation from Clinical CT using Bayesian U-Net for Personalization of a Musculoskeletal Model Authors Yuta Hiasa, Yoshito Otake, Masaki Takao, Takeshi Ogawa, Nobuhiko Sugano, Yoshinobu Sato 我们提出了一种从临床CT中自动分割个体肌肉的方法。该方法使用具有U Net架构的贝叶斯卷积神经网络,使用蒙特卡洛压差,除了分割标签之外还推断出不确定性度量。我们使用两个数据集20髋和大腿区域的完全注释的CT和18个部分注释的CT来评估所提出方法的性能,这些CT可从The Cancer Imaging Archive TCIA数据库公开获得。实验表明,在20组CT中,19个肌肉的Dice系数DC为0.891 0.016 mean std,平均对称表面距离ASD为0.994±0.230 mm。与现有技术的分层多图谱方法相比,这些结果是统计学上显着的改进,其导致0.845 0.031 DC和1.556 0.444 mm ASD。我们评估了多类器官分割问题中不确定性度量的有效性,并证明了具有高不确定性的像素与分割失败之间的相关性。证明了不确定性度量在主动学习中的一种应用,并且所提出的查询像素选择方法显着降低了用于扩展训练数据集的手动注释成本。所提出的方法允许在临床常规中对个体肌肉形状进行准确的患者特异性分析。这将开辟各种应用,包括生物力学模拟的个性化和肌肉萎缩的定量评估。 |
| An Efficient 3D CNN for Action/Object Segmentation in Video Authors Rui Hou, Chen Chen, Rahul Sukthankar, Mubarak Shah 卷积神经网络基于CNN的图像分割近年来取得了很大进展。然而,由于其高计算复杂性,视频对象分割仍然是具有挑战性的任务。大多数先前的方法采用双流CNN框架来分别处理空间和运动特征。在本文中,我们提出了一种端到端编码器解码器样式3D CNN,用于同时聚合视频对象分割的空间和时间信息。为了有效地处理视频,我们为金字塔池模块和解码器提出了3D可分卷积,这在保持性能的同时大大减少了操作次数。此外,我们还通过添加额外的分类器来预测视频中演员的动作标签,从而将我们的框架扩展到视频动作分段。对几个视频数据集的广泛实验证明,与现有技术相比,所提出的动作和对象分割方法具有优越的性能。 |
| ++人体抽取和场景转换Human Extraction and Scene Transition utilizing Mask R-CNN Authors Asati Minkesh, Kraittipong Worranitta, Miyachi Taizo 物体检测是计算机视觉的一个时髦分支,特别是在人类识别和行人检测方面。认识到一个人的完整身体一直是一个难题。多年来,研究人员提出了各种方法,最近,作为Mask R CNN的一个突破进入了光明。基于更快的R CNN,掩码R CNN能够为每个实例生成分段掩码。我们提出了一个应用程序来提取多个人并使用Mask R CNN将它们放入新的背景图像中。掩码R CNN从图像中检测所有类型的对象掩码。然后我们的算法仅考虑目标人并且仅在没有障碍的情况下提取人,例如在人面前的狗,并且用户也可以选择多个人作为他们的期望。我们的算法对图像和视频都有效,无论其长度如何。此外,提取这些人并将他们放入新的背景。我们的算法不会为Mask R CNN增加任何开销,以5 fps运行。我们展示了一个图像中的瑜伽人和舞蹈视频帧中的舞者的例子。我们希望我们简单有效的方法可以作为替换图像背景和帮助简化未来研究的基线。 |
| Construct Dynamic Graphs for Hand Gesture Recognition via Spatial-Temporal Attention Authors Yuxiao Chen, Long Zhao, Xi Peng, Jianbo Yuan, Dimitris N. Metaxas 我们提出了一种基于动态图的空间时间注意DG STA方法,用于手势识别。关键思想是首先从手骨架构建一个完全连通的图形,然后通过在空间和时间域中执行的自我关注机制自动学习节点特征和边缘。我们进一步建议利用关节位置的空间时间线索来保证在具有挑战性的条件下的可靠识别。此外,应用新颖的空间时间掩模以显着降低99的计算成本。我们在基准DHG 14 28和SHREC 17上进行了广泛的实验,证明了我们的方法与现有技术方法相比的优越性能。源代码可以在 |
| Unsupervised Segmentation of Hyperspectral Images Using 3D Convolutional Autoencoders Authors Jakub Nalepa, Michal Myller, Yasuteru Imai, Ken ichi Honda, Tomomi Takeda, Marek Antoniak 高光谱图像分析已成为遥感界广泛研究的重要课题。这种图像的分类和分割有助于理解扫描场景中的基础材料,因为高光谱图像传达了在多个光谱带中捕获的详细信息。尽管深度学习已经确立了该领域的最新技术水平,但由于缺乏地面实况数据,培养良好的推广模型仍然具有挑战性。在这封信中,我们解决了这个问题,并提出了一种以完全无监督的方式分割高光谱图像的端到端方法。我们介绍了一种新的深度架构,它将3D卷积自动编码器与聚类相结合。我们针对基准和现实生活数据进行的多方面实验研究表明,我们的方法提供了高质量的分割,而无需任何先前的类别标签。 |
| Order Matters: Shuffling Sequence Generation for Video Prediction Authors Junyan Wang, Bingzhang Hu, Yang Long, Yu Guan 预测自然视频序列中的未来帧是一项新的挑战,在计算机视觉社区中越来越受到关注。然而,当预测序列很长时,现有模型遭受严重的时间信息丢失。与以往专注于生成更真实内容的方法相比,本文广泛研究了序列信息对视频生成的重要性。提出了一种新的Shuffling sEquence gEneration网络SEE Net,它可以学习通过改组视频帧并将它们与真实视频序列进行比较来区分不自然的顺序。在具有合成和现实世界视频的三个数据集上的系统实验表明在我们提出的模型中用于视频预测的改组序列生成的有效性,并且通过定性和定量评估展示了现有技术性能。源代码可在以下位置获得 |
| Recurrent Connections Aid Occluded Object Recognition by Discounting Occluders Authors Markus Roland Ernst, Jochen Triesch, Thomas Burwick 当部分刺激被遮挡时,视觉皮层中的反复连接被认为有助于物体识别。在这里,我们调查人工神经网络中的复发连接是否以及如何同样有助于对象识别。我们系统地测试和比较由自下而上B,横向L和自上而下T连接组成的架构。在新颖的立体遮挡对象识别数据集上评估性能。该任务包括识别伪3D环境中由多个遮挡器数字遮挡的一个目标数字。我们发现循环模型的性能明显优于前馈模型,后者在参数复杂度方面具有匹配性。此外,我们分析了由于经常性连接,网络对刺激的表示如何随时间演变。我们表明,经常性连接倾向于将网络对被遮挡数字的表示移向其未被遮挡的版本。我们的结果表明,大脑和人工神经网络都可以利用循环连接来帮助遮挡对象识别。 |
| Automated Surgical Activity Recognition with One Labeled Sequence Authors Robert DiPietro, Gregory D. Hager 先前的工作已经证明了运动数据在机器人辅助手术中自动识别活动的可行性。然而,这些努力假设了大量密集注释序列的可用性,这必须由专家手动提供。这个过程繁琐,昂贵且容易出错。在本文中,我们在稀缺注释的假设下提出了第一个分析,其中只有一个注释序列可用于训练。我们在这个具有挑战性的环境中证明了自动识别的可行性,并且我们表明,在识别阶段之前以无人监督的方式学习表示会导致性能的显着提高。此外,我们的论文对社区提出了新的挑战,我们还能在这个重要但相对未开发的制度中进一步推动绩效 |
| PH-GCN: Person Re-identification with Part-based Hierarchical Graph Convolutional Network Authors Bo Jiang, Xixi Wang, Bin Luo 人物识别Re ID任务需要鲁棒地提取人物图像的特征表示。最近,已经广泛研究了基于部分的表示模型,用于提取人物图像的更紧凑和稳健的特征表示以改善人Re ID结果。然而,现有的基于部分的表示模型大多独立地提取不同部分的特征,忽略了不同部分之间的关系信息。为克服这一局限性,本文提出了一种新的深度学习框架,称为基于部分的分层图卷积网络PH GCN,用于人员Re ID问题。给定人物图像,PH GCN首先构造分层图以表示不同部分之间的成对关系。然后,通过在PH GCN中传递的消息执行本地和全局特征学习,其将其他节点信息考虑用于部分特征表示。最后,采用感知器层进行最终人物部位标签预测和重新识别。提出的框架提供了一种通用解决方案,可在统一的端到端网络中同时集成本地,全局和结构特征学习。对几个基准数据集的大量实验证明了基于PH GCN的Re ID方法的有效性。 |
| Pan-tilt-zoom SLAM for Sports Videos Authors Jikai Lu, Jianhui Chen, James J. Little 我们提供了一个在线SLAM系统,专门用于跟踪高度动态运动中的云台变焦PTZ摄像机,如篮球和足球比赛。在这些游戏中,PTZ摄像机旋转速度非常快,玩家可以覆盖大型图像区域。为了克服这些挑战,我们建议使用一种新颖的相机模型来跟踪和使用光线作为映射中的地标。光线克服了纯旋转相机中缺失的深度。我们还开发了一个在线云台森林,用于绘图并引入移动物体的探测器,以减轻前景物体的负面影响。我们在合成和真实数据集上测试我们的方法。实验结果表明,该方法优于以往的在线PTZ摄像机姿态估计方法。 |
| +++基于图像迁移额黑夜车辆检测Cross-Domain Car Detection Using Unsupervised Image-to-Image Translation: From Day to Night Authors Vinicius F. Arruda, Thiago M. Paix o, Rodrigo F. Berriel, Alberto F. De Souza, Claudine Badue, Nicu Sebe, Thiago Oliveira Santos 深度学习技术使得最先进模型的出现能够解决对象检测任务。然而,这些技术是数据驱动的,将准确性委托给训练数据集,训练数据集必须类似于目标任务中的图像。获取数据集涉及注释图像,这是一个艰巨而昂贵的过程,通常需要时间和手动工作。因此,当应用的目标域没有可用的注释数据集时,出现了具有挑战性的情况,使得在这种情况下的任务依赖于不同域的训练数据集。共享此问题,对象检测是自动驾驶车辆的重要任务,其中大量驾驶场景产生若干应用领域,需要用于训练过程的注释数据。在该工作中,提出了一种用于训练具有来自源域日图像的注释数据的汽车检测系统的方法,而不需要目标域夜间图像的图像注释。为此,探索了基于生成对抗网络GAN的模型,以便能够生成具有相应注释的人工数据集。创建人工数据集假数据集,将图像从日间域转换为夜间域。然后使用包括仅目标域夜间图像的注释图像的伪数据集来训练汽车检测器模型。实验结果表明,所提出的方法实现了显着且一致的改进,包括与仅具有可用注释数据即日图像的训练相比,增加了超过10的检测性能。 |
| VIFIDEL: Evaluating the Visual Fidelity of Image Descriptions Authors Pranava Madhyastha, Josiah Wang, Lucia Specia 我们解决了评估图像描述生成系统的任务。我们为此任务VIFIDEL提出了一种新颖的图像感知度量。它基于图像中描绘的对象的标签与描述中的单词之间的语义相似性来估计生成的标题相对于实际图像的内容的忠实度。该度量还能够在评估期间考虑人参考描述中提到的对象的相对重要性。即使这些人工参考描述不可用,VIFIDEL仍然可以可靠地评估系统描述。该指标与两个众所周知的数据集上的人类判断高度相关,并且与依赖于人类参考的指标竞争 |
| Artificial Neural Network Algorithm based Skyrmion Material Design of Chiral Crystals Authors B.U.V Prashanth, Mohammed Riyaz Ahmed 本研究中提出的模型预测了理想的手性晶体,并提出了设计手性晶体的新方向。 Skyrmions受拓扑保护,结构不对称的材料具有异国情调的旋转成分。这项工作提出了手性晶体的skyrmion材料设计的深度学习方法。本文提出了一种从真假手性数据集构建概率分类器和人工神经网络ANN的方法,该数据集由具有A和B型元素的手性和非手性化合物组成。示出了形成手性晶体的准确度的定量预测器。通过与probalistic分类器方法的比较,综合测试了ANN方法的可行性。在整个手稿中,我们提出了深度学习算法设计与材料的建模和模拟。这项研究工作阐明了开发复杂软件工具以制作水晶设计指标的方法。 |
| Automatic Radiology Report Generation based on Multi-view Image Fusion and Medical Concept Enrichment Authors Jianbo Yuan, Haofu Liao, Rui Luo, Jiebo Luo 生成放射学报告非常耗时,并且需要在实践中具有广泛的专业知识。因此,非常需要可靠的自动放射学报告生成来减轻工作量。虽然深度学习技术已经成功应用于图像分类和图像字幕任务,但是在理解和链接复杂的医学视觉内容与准确的自然语言描述方面,放射学报告生成仍然是具有挑战性的。此外,包含配对医学图像和报告的开放访问数据集的数据规模仍然非常有限。为了应对这些实际挑战,我们提出了一种生成编码器解码器模型,并专注于胸部X射线图像和报告,并进行了以下改进。首先,我们使用大量胸部X射线图像预编码编码器,以准确识别14个常见的射线照相观察,同时通过强制执行交叉视图一致性来利用多视图图像。其次,我们以后期融合方式基于句子级注意机制合成多视图视觉特征。此外,为了丰富解码器的描述性语义并强制确定医学相关内容的正确性,如提及器官或诊断,我们根据训练数据中的放射学报告提取医学概念,并微调编码器以提取来自x射线图像的最常见的医学概念。这些概念通过词级关注模型与每个解码步骤融合。在印第安纳大学胸部X射线数据集上进行的实验结果表明,与其他基线方法相比,所提出的模型实现了最先进的性能。 |
| Scene-and-Process-Dependent Spatial Image Quality Metrics Authors Edward W. S. Fry, Sophie Triantaphillidou, Robin B. Jenkin, Ralph E. Jacobson, John R. Jarvis 为相机系统设计的空间图像质量度量通常采用调制传递函数MTF,噪声功率谱NPS和视觉对比度检测模型。现有技术表明,使用传统方法测量的MTF和NPS没有计算非线性,内容感知图像处理的场景相关特性。我们提出了两个新的度量标准日志噪声等效量子日志NEQ和视觉日志NEQ。它们都采用场景和过程相关的MTF SPD MTF和NPS SPD NPS测量,分别考虑信号传输和噪声场景依赖性。我们还研究了实现对比度检测和辨别模型,这些模型考虑了场景相关的视觉掩蔽。此外,修改了三个主要的摄像机指标,使用上述场景相关措施。通过检查与模拟摄像机管道产生的图像的感知质量的相关性来验证所有度量。在实施SPD MTF和SPD NPS时,度量精度始终如一地提高。新颖的指标优于同一类型的现有指标。 |
| Validation of Modulation Transfer Functions and Noise Power Spectra from Natural Scenes Authors Edward W. S. Fry, Sophie Triantaphillidou, Robin B. Jenkin, John R. Jarvis, Ralph E. Jacobson 调制传递函数MTF和噪声功率谱NPS分别表征成像系统的锐度分辨率和噪声。这两种测量均基于线性系统理论,但常规应用于采用非线性,内容感知图像处理的系统。对于这样的系统,MTF的NPS不准确地从包含边缘,正弦曲线,噪声或均匀音调信号的传统测试图中导出,这些信号不能代表自然场景信号。死叶测试图提供了改进的测量,但在描述场景相关系统的性能时仍然存在局限性。在本文中,我们验证了几种新的场景和过程相关的MTF SPD MTF和NPS SPD NPS度量,这些度量表征了一个场景的系统性能,或者涉及许多场景的平均真实世界性能,或者系统场景依赖性的水平。我们还使用死叶图获得了新的SPD NPS和SPD MTF测量。我们证明了所有提出的措施都是稳健的,并且对于场景相关系统而言比当前的措 |
| ++推理出被遮挡的物体提升抓取Inferring Occluded Geometry Improves Performance when Retrieving an Object from Dense Clutter Authors Andrew Price, Linyi Jin, Dmitry Berenson 对象搜索在杂乱的场景中找到目标对象的问题对于解决仓库和家庭环境中的许多机器人应用是必不可少的。然而,杂乱的环境需要物体经常相互遮挡,使得难以分割物体并推断它们的形状和性质。我们不再依赖于CAD或其他显式场景对象模型的可用性,而是通过最先进的深度神经网络来完成形状完成以及体积记忆系统,为杂乱的环境增加了一个操纵规划器,允许机器人推理封闭区域可能包含的内容。我们在由家居用品组成的各种桌面操作场景中测试系统,突出其对现实领域的适用性。我们的结果表明,将两个组件合并到一个操作规划框架中可以显着减少在密集的杂乱中找到隐藏对象所需的操作数量。 |
| ++基于视网膜的采样方法A Retina-inspired Sampling Method for Visual Texture Reconstruction Authors Lin Zhu, Siwei Dong, Tiejun Huang, Yonghong Tian 传统的基于帧的相机不能满足实时应用的快速反应需求,而新兴的动态视觉传感器DVS可以实现对移动物体的高速捕获。然而,为了实现视觉纹理重建,DVS除了输出尖峰之外还需要额外的信息。本文介绍了一种受视网膜神经元信号处理启发的中心凹样本,其目的在于仅利用尖峰的特性进行视觉纹理重建。在所提出的方法中,像素独立地响应具有时间异步尖峰的亮度变化。通过分析尖峰的到达,可以恢复亮度信息,从而可以重建自然场景以进行可视化。针对高速运动和静止场景,提出了三种用于纹理重建的尖峰流解码方法。与传统的基于帧的相机和DVS相比,我们的模型可以实现更好的图像质量和更高的灵活性,这可以改变苛刻的机器视觉应用的构建方式。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pexels.com