基于动态时间规整算法(DTW)的语音识别技术研究-含Matlab代码
⭕⭕ 目 录 ⭕⭕
- ⏩ 一、引言
- ⏩ 二、动态时间规整算法基本原理
- ⏩ 三、语音识别实例分析
- ⏩ 四、参考文献
- ⏩ 五、Matlab代码获取
⏩ 一、引言
在语音识别技术的发展过程中,动态时间规整算法(Dynamic Time Warping,DTW)一直处于重要地位,其本质上是一种距离度量算法。在过去的几十年中研究者们提出了几十种距离度量算法,实验证明,动态时间规整算法仍然是最佳的距离度量技术。然而,目前的各种嵌入式语音识别方案中,由于动态时间规整算法本身庞大的计算量和相邻数据处理过程中的高度依赖性极大地限制了它的实际应用,同时也使得计算资源和存储空间相对有限的嵌入式设备无法更好地发挥其性能。
⏩ 二、动态时间规整算法基本原理
动态时间规整算法是一种准确性高、鲁棒性强的时间序列相似性度量方法。通过在测试语音序列和模板语音序列之间利用规整函数建立一条非线性的弯折路径,不断对比两序列之间弯折路径的距离,距离越小,相似度越高,以此找到声学相似性最大的两个序列。
设T={t1,t2,t3,t4,t5,…,tN}和H={h1,h2,h3,h4,h5,…,hM} 分别为长度为 N 和 M 的语音序列。动态时间规整算法需要不断搜索得出一个时间规整函数C=z(n),该函数将T序列的时间轴非线性的映射到H序列的时间轴上。同时,该函数z满足公式(1):
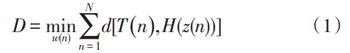
式中,d[T(n),H(z(n))] 是序列 T 中第 n 个数据 tn和序列 H 中第 C = w(n) 个数据 hm 之间的距离度量,D 为最优时间规整情况下两个序列的累积距离。为了保证两个序列之间的搜索匹配路径具有实际意义,规整函数 z(n) 必须满足以下 3个条件:
单调性:z(n)≤z(n+1),1≤n≤N-1;
边界性:z(1)=1,z(N)=M;
连续性:z(n+1)-z(n)≤1。
根据上述3个条件,由N和M两个序列中任意两点的距离构成N×M的距离矩阵 A N × M {{A}_{N\times M}} AN×M,其中任意两点A1、A2使用公式(2)计算其欧氏距离。
![]()
边界性是为了保证搜索路径的起点从矩阵 A N × M {{A}_{N\times M}} AN×M的左下角(1,1)开始到右上角(N,M)结束。单调性和连续性是为了保证搜索路径的下一个方向在当前点的上方、右上方或者右方。从而在所有有效路径中找到唯一最优路径可以使累积距离最小。
为了找到唯一最优路径,动态时间规整算法采用逆序决策过程,求其任意点处累积距离,需先找出其所有满足上述 3 个条件的前序节点 ,利用公式(3)递推求得所有节点。
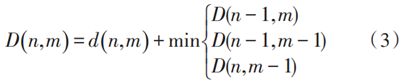
⏩ 三、语音识别实例分析
一个完整的基于统计的语音识别系统可大致有这样的步骤:
①语音信号预处理;
②语音信号特征提取;
③声学模型选择;
④模式匹配选择;
⑤语言模型选择;
⑥语言信息处理。
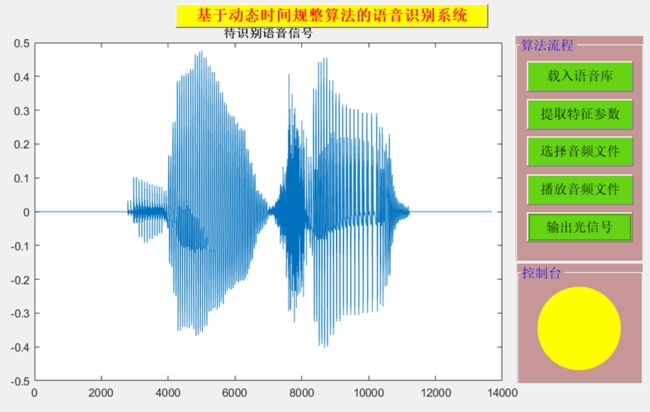
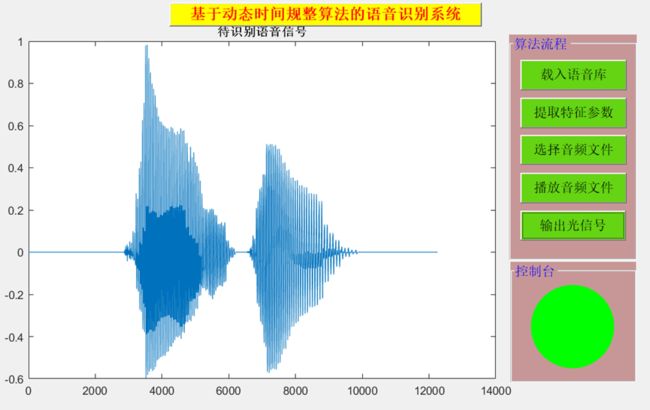
基于Matlab GUI设计的语音控制光信号等识别系统用户界面如下图所示:

语音信号“停止”,用控制台中的“黄色”来表示。
语音信号“关闭”,用控制台中的“绿色”来表示。
⏩ 四、参考文献
[1] 温玉华.基于DTW算法的英语发音错误自动校正系统设计[J].现代电子技术,2020,43(10):124-126.
[2] 钟颖.基于DSP的语音识别系统的研究与实现[J].数字技术与应用,2017(5):48-49.
[3] 杨凡,杨迎尧,邹杰,等.基于语音识别的智能家居系统的设计与开发[J].现代信息科技,2019,3(9):164-167.
[4] 贺霄琛,韩燮,李顺增.改进的LB算法在动态手势识别中的应用[J].微电子学与计算机,2016,33(4):55-59.
⏩ 五、Matlab代码获取
上述Matlab代码,可私信博主获取
博主简介:研究方向涉及智能图像处理、深度学习等领域,先后发表过多篇SCI论文,在科研方面经验丰富。任何与算法、程序、科研方面的问题,均可私信交流讨论。