R-CNN系列详解
1、从传统方法到R-CNN
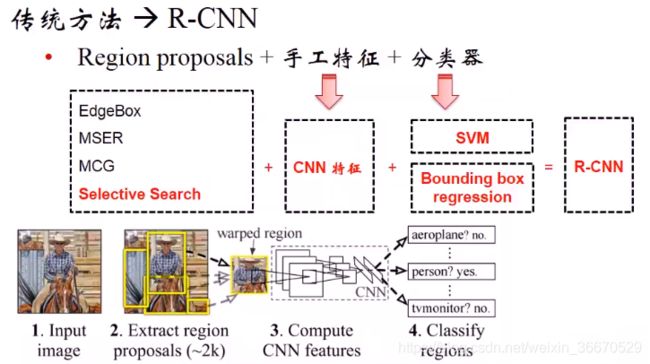
基于传统的方法,先要进行区域建议的生成,然后对每个区域进行手工特征的设计和提取,然后送入分类器。在Alexnet出现后,CNN的性能比较好,不但可以学习手工特征还有分类器和回归器。CNN主要用来提取特征,SS提取出的最小外接矩形可能不精准,这样的话就需要Bounding Box回归对区域的位置进行校正。输入图片SS算法算法生成区域,然后到原图里面截取相应的区域,截出的区域做了稍微的膨胀,把框稍微放松一点,以保证所有物体的信息都能进来,然后做一下尺寸的归一化,把尺寸变成CNN网络可接受的尺寸,这样的话送到所有的CNN网络,这个CNN是Alexnet,然后对每个区域分别做识别得到了人的标签,和传统方法相比这里是用CNN提取特征。
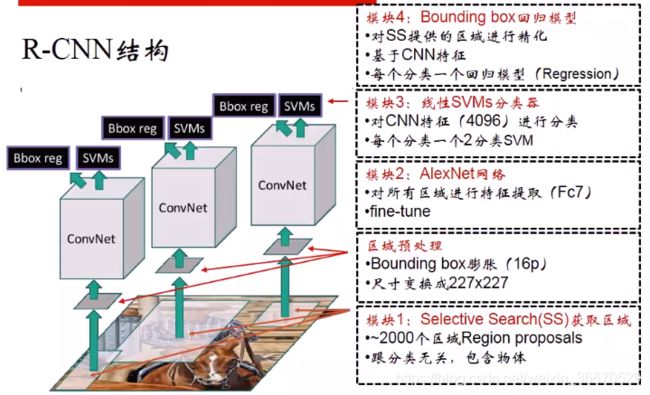
模块1用SS算法获取区域建议,大约有2000多个,SS算法不负责分类,只是判断有没有包含物体。接下来做区域预处理,每个区域先做16个像素的膨胀。接下来送到Alexnet网络,对所有区域进行特征提取,从第7层,也就是第二个全连接层的输出作为特征,Alexnet网络需要fine-tune,得到特征以后送到SVM里面进行分类。fc7输出的特征是4096维的1x4096,分类的时候是二分类问题,比如PASCAL VOC有20个类,最后就会有20个SVM,每个SVM负责一个分类,判断这个类有无用0或者1表示,而且是线性的分类器。Bounding Box回归模型是额外加的,要精化SS算法生成的区域位置,输入需要CNN特征,使用的是第5卷积层的特征,和SVM分类器类似,一个分类对应一个模型,如果有20个分类就有20个分类模型。
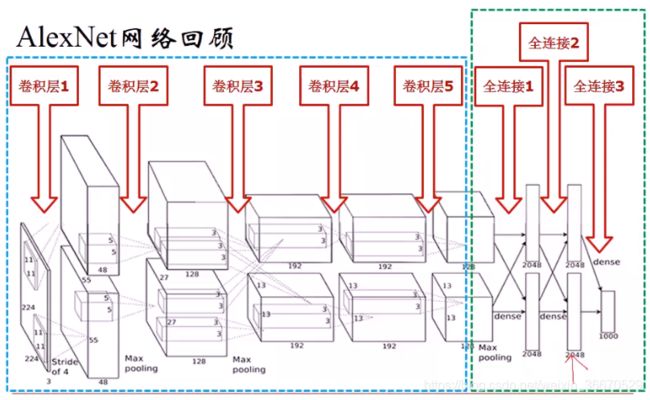
上图给出了Alexnet的结构,红色箭头给出了fc7的位置,这个位置输出的特征用来进行分类。

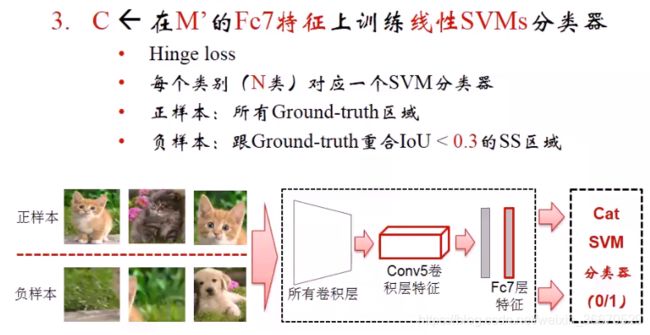
(在M'的conv5特征)
- 第一步、获取预训练的模型,R-CNN使用的是在Imagenet上预训练好的Alexnet。
- 第二步、做fine-tune,在fine-tune之前先对Alexnet进行稍微的修改,原始Alexnet最后一个全连接层的输出由1000维改为201维或21维,因为原始的Alexnet是在Imagenet上训练的,需要根据不同的数据集把全连接成改成相应的维度。样本的组织方式为:有N类,比如PASCAL VOC有20类,每个minibatch提供23个正样本,负样本也就是背景类一共96个。正负样本的判断根据和groundtruth的重合度来判断。所有层都要fine-tune包括卷积层。
- 第三步、fine-tune后这个网络就适应了检测数据集,fine-tune结束后就不使用softmax层了,而使用fc7输出的特征,4096维作为区域图片的特征,然后使用这个特征训练线性分类器。
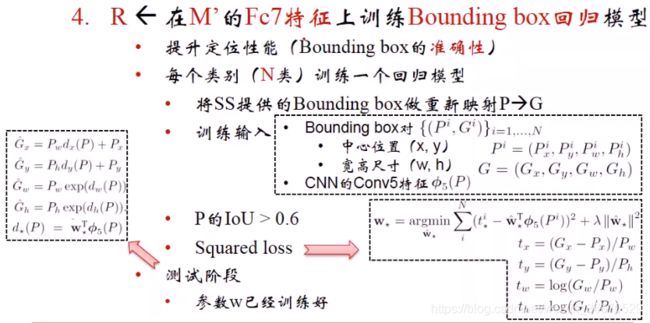
- 第四步、输入卷积层的conv5特征,是个tensor三维矩阵,特征回归模型将旧的x、y、h、w映射成更精确的x、y、h、w。P是SS算法提出的旧的Bounding box位置信息,G是ground truth输出的精确的位置选取。P的选取有新的方式,设置IOU的阈值为0.6,回归模型的优化时差平方和loss。在loss中w是需要学习的,w乘在Conv5的特征上进行特征的组织和变维,*的含义是x,y,w,h个需要学习一个参数w,x和y是直角坐标系下的比例关系,w和h是极坐标下的比例关系,最终计算出的是变化,或者说是校准量而不是原本的输出结果。最终回归模型学习到4个w。

测试和训练有一点差异,但是基本一致。首先用SS算法提取出2000个区域,然后对区域进行膨胀+缩放达到227x227,使用fine-tune过的Alexnet算出两套特征,分别是Fc7和Conv5。Fc7直接送到SVM里面进行分类,分类之后产生20个分支(假设使用的是PASCAL VOC数据集),哪个类别的分值最高,就认为这个区域属于哪个类别。比如对猫来讲,提取了2000个区域,里面有100个是猫属性输出的概率最大,对100个猫区域的候选区域进行筛选和过滤,通过非极大值抑制,把多于的重合的区域全部剔除掉,最终只剩下10个,10个就是重合度不高的区域,有可能就是多个猫,分散在不同位置上,缩小范围后进行Bounding box回归。

2、从R-CNN到SPP-Net

R-CNN计算量很大导致网络的速度很慢。主要是卷积特征的重复计算量太大,很多区域可能会重复计算好多次,每个区域要计算一个卷积特征然后进行计算,换算成原图的话,相当于这个图片已经计算过好几十遍了,本质上送一遍就可以了,这就是R-CNN比较慢的原因,尤其是在测试阶段。
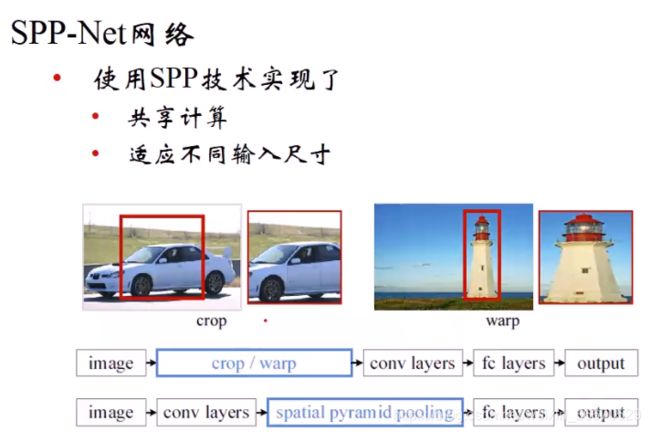
SPP-Net要解决这个问题,不给网络送子图片直接送整幅图片,送完后第五个卷积层的输出是整个图片的特征,直接在第五卷积层上截取特征而不是在原始图片上,卷积层上有长和宽维度上的降维,区域要做分辨率的变换。因为区域大小不固定,映射到卷积层上的时候,覆盖特征的像素量不同。但是CNN最后一个卷积层到第一个全连接层之间,经过全尺寸卷积核,全尺寸卷积核的尺寸和最后一个卷积层的输出尺寸一样。假如区域大小不定,第五个卷积层上的特征大小不定,但是全尺寸卷积的尺寸必须固定。因此引进了空间金字塔池化(SPP),这里不对图片做尺度变换,对区域的大小做变换。这样映射到第一个全连接层的时候就没有问题了。
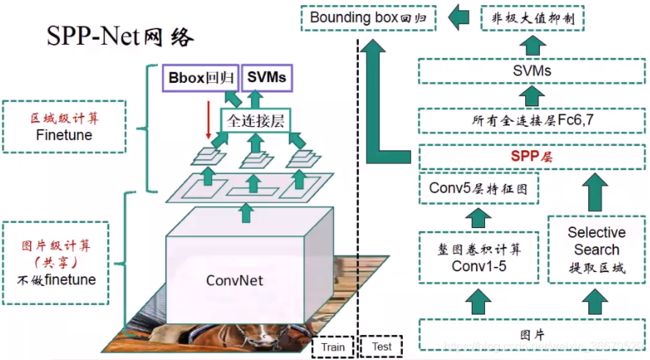
左边为训练图的演示,右边为测试图的演示。图片输入进来经过5个卷积层输出特征,在第五个特征层上进行区域的提取,这里使用的就是SPP,SPP输出定长的一维特征后送到全连接层Fc6、Fc7、Fc8,接下来进行SVM分类。右边是一个测试的流程,做只进行卷积拿到第五层特征,右边通过SS算法得到区域,在SSP层进行特征提取,所有区域都进行特征提取,所有特征层都送到全连接层SVM进行预测。Bounding box Regression回归时,和R-CNN使用第五个卷积层的特征不同,SPP-Net使用SPP层的特征,也就是定长化的特征送到Bounding box回归。SVM分类后得到了class,需要做极大值抑制,和R-CNN类似。
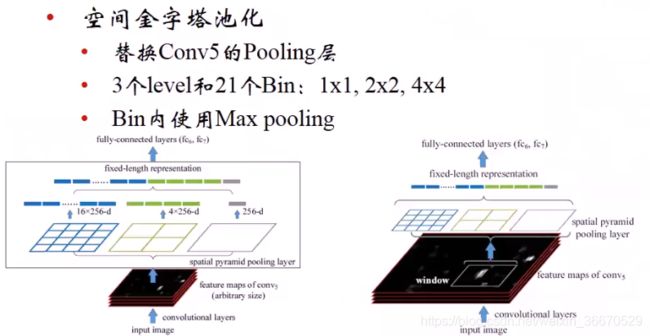
黑色图为整图进行卷积之后第五个卷积层的输出 ,白色框为一个SS算法提出的建议,对应之后进行映射,扣到特征层上,扣上之后做两个事情,先做网格的划分,共有三个1x1(全尺寸)、2x2、4x4,加起来共有21个方格。每一个方格覆盖一定量不同数量的像素点,但是每个方格要做max pooling,最终输出是一个像素的值,最终输出有21段定长的特征。

训练和R-CNN类似,但是稍有差异。

3、从SPP-Net到Fast R-CNN

多任务损失函数的意思是将分类和回归的损失函数合并成一个损失函数,统一进行训练。
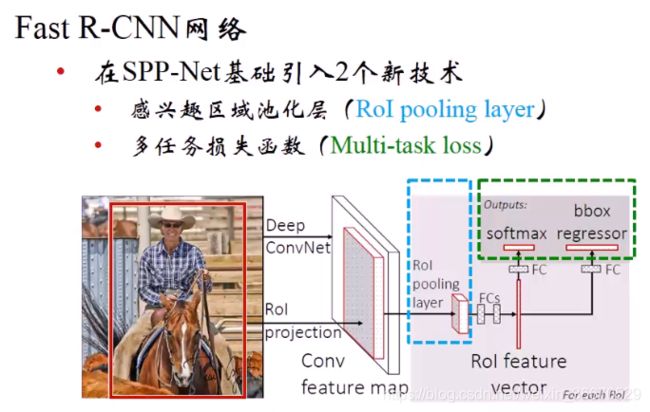
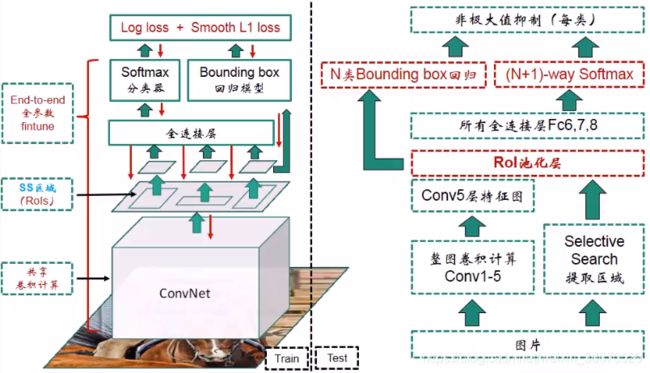
图片进来进行五个卷积层的共享计算,然后然后通过RoI池化层,池化后经过全连接层,一支给Softmax分类,另一支直接送到Bounding box回归模型,最终形成Bounding box的损失函数,两个损失统一相加,梯度回传两支,在全连接层进行汇总。测试的过程和R-CNN类似。
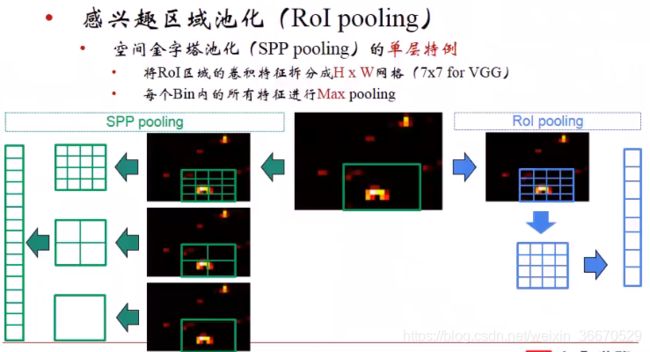
和SPP相比,假设conv5的输出是单通道,RoI只用最上面的4x4最大池化,生成一个16格的特征,RoI pooling的输出是16x512,一方面特征长度变短了,另一方面可以用梯度回传使计算变得简单,可以使用端对端的训练。
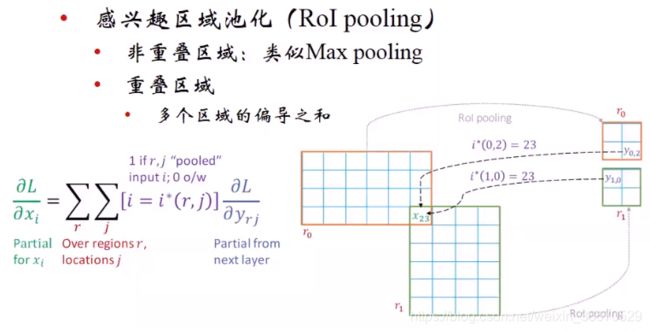
RoI池化的梯度回传:非重叠的区域和max pooling的梯度回传一样,对于重叠区域x23,重叠了一个像素,对r0来说是贡献到右下角的像素,对r1来说是贡献到左上角的像素。回传的时候用r0右下角和r1左上角的梯度相加。求偏导的时候有两个维度,一个是对xi求偏导就是对重叠的区域求偏导,多个区域偏导求和,一个和的维度是位置,一个和的维度是区域。0区域,2指的是位置,1区域,0指的是位置。

多任务损失函数一个负责分类,一个负责回归,cls代表分类,loc代表回归。分类用的是负的概率对数值,每个分类对应一个值,u是groundtruth的概率。例如,有21个分类softmax层输出了21个概率值,这个区域的真正groundtruth是猫,可能排第一个那u就等于0。每个区域都有这样一个操作,所有区域加起来,一个batch里面的分类loss。Bounding box回归的损失函数.

训练时需要注意技巧,batch的划分,128个batch是由两个图片产生的,每张图片分别输出64个ROI,这么做的目的是为了充分利用卷积层计算,设置的原因就是工程性的实验。
4、FPN和fast R-CNN的连接
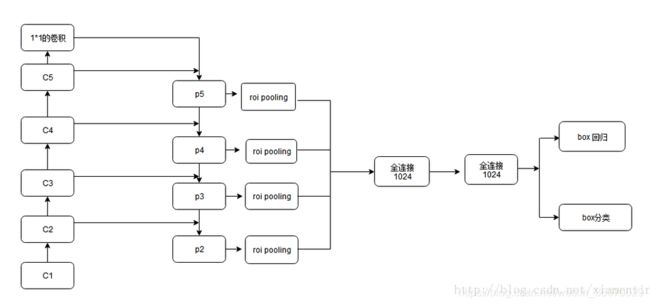
Fast R-CNN 中很重要的是ROI Pooling层,需要对不同层级的金字塔制定不同尺度的ROI。 ROI Pooling层使用region proposal的结果和中间的某一特征图作为输入,得到的结果经过分解后分别用于分类结果和边框回归。 不同尺度的ROI使用不同特征层作为ROI pooling层的输入,大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P4。那怎么判断ROI改用那个层的输出呢?这里定义了一个系数Pk,其定义为:
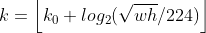
224是ImageNet的标准输入,k0是基准值,设置为5,代表P5层的输出(原图大小就用P5层),w和h是ROI区域的长和宽,假设ROI是112 * 112的大小,那么k = k0-1 = 5-1 = 4,意味着该ROI应该使用P4的特征层。k值应该会做取整处理,防止结果不是整数,把conv5也作为了金字塔结构的一部分。那么从前全连接层的那个作用怎么办呢?这里采取的方法是增加两个1024维的轻量级全连接层,然后再跟上分类器和边框回归,这样能使速度更快一些。 网络结构如下,
5、从Fast R-CNN到Faster R-CNN

Fast R-CNN解决了端对端问题,卷积层的共享计算在SPP-Net就已经解决,Fast R-CNN使用区域建议生成算法Selective Search还是一个独立的东西,Faster R-CNN中区域建议也用第五个卷积层的特征来决定,相当于把区域建议生成算法直接集成到网络里,这个网络称为RPN(Region Proposal Network),简单理解就是Fast R-CNN加上RPN网络,用RPN取代了离线的SS算法。
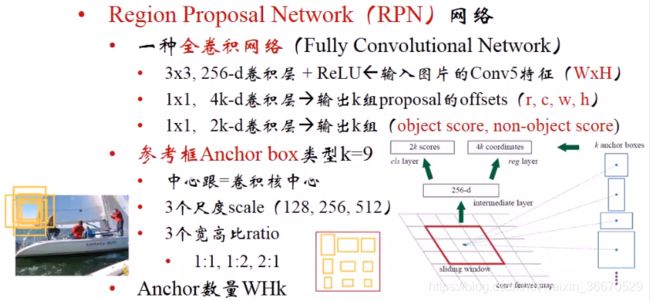
RPN本质上是一个全卷积网络,这个网络有两层,第一层是一个3x3的卷积256个输出通道,第二层是两个1x1的卷积,两个分支,一个分支的输出通道是4k,矩形框的偏差,另一个分支的输出通道是4k,判断是否为物体。给出了9种参考框,每个像素位置上书9个参考框。图中的红色框代表卷积到某个像素会输出9个框。256个3x3的卷积和,输出256个特征,特征送到是否是物体的分类器上,然后送到4k坐标偏差的分支,这两个输出就是RPN网络的最终输出。

RPN的损失有两项,各自带来两种损失,第一项代表分类,有没有物体,第二项代表bounding box的偏差。RPN网络需要单独训练。
