BERT模型—4.BERT模型在关系分类任务上的微调
文章目录
-
-
- 引言
- 一、项目环境配置
- 二、数据集介绍
- 三、代码介绍
-
- 1.Focal loss损失函数
- 四、测试结果
-
- 1.代码运行程序
- 2.代码预测程序
-
数据代码见:https://gitee.com/lj857335332/bert_finetune_re
引言
关系分类任务在信息抽取中处于核心地位。关系分类任务就是从非结构化文本中抽取出结构化知识;具体为:区分出头实体与尾实体之间的语义关系,比如:

通过模型将头实体与尾实体的语义关系分类分出来。那么BERT模型如何应用在关系分类任务当中呢?关系分类模型的架构有多种选择:
- 第一种实现方式:将BERT模型应用于句子的向量表征,不管实体位于句子当中的哪个位置,仍然将句子分词,首尾加上[CLS]与[SEP],将[CLS]的向量表征拿出来,输入到分类器中,这个分类器输出关系预测类型上的打分。
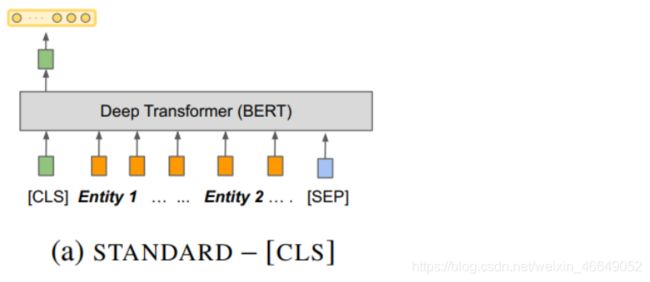
- 第二种实现方式:不是直接拿到句子的向量表征,而是将句子中的向量表征拿出来,这两个向量表征进行拼接后输入到分类器中,这里就要涉及到MENTION POOLING操作。因为实体可能是单个token,也可能是多个token。如果是多个token的话,多个token的向量表征要转化成整个实体的固定大小的向量表征。
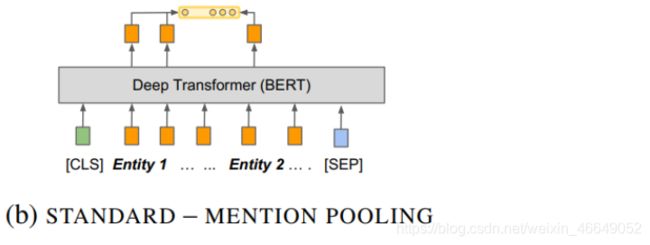
- 第三种方式:通过外部的信息告诉模型头实体与尾实体的位置,这就是所谓的POSITIONAL EMBEDDING。这种信息在传统的关系分类任务当中被验证是非常有帮助的,模型更容易表征两个实体的语义关系
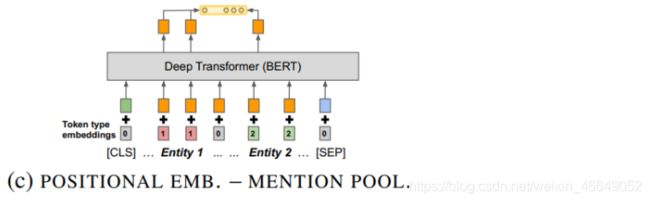
- 第四种方式:通过在句子中添加特殊符号来标识两个实体的位置,这种实现方法对句子有一定的改变
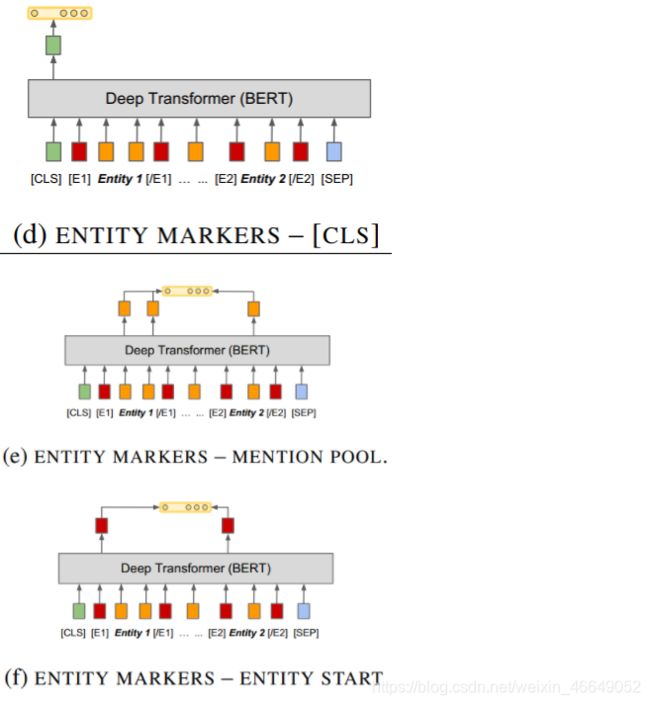
研究者们已经将这7种架构在基准数据集上进行了对比,
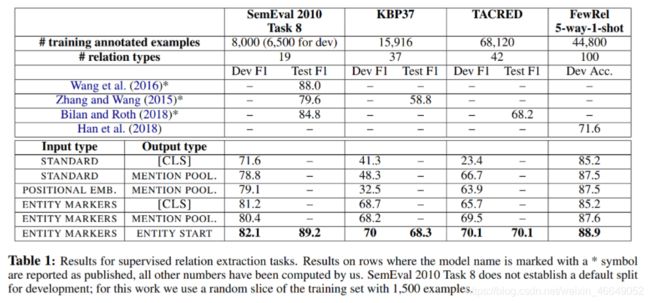
下面就ENTITY MARKERS与CLS相结合予以实现。
一、项目环境配置
- torch==1.6.0
- transformers==3.0.2
- seqeval==0.0.12
- pytorch-crf==0.7.2
二、数据集介绍
| Train | Dev | Test | Slot Labels | |
|---|---|---|---|---|
| SemEval10 | 6507 | 1493 | 2717 | 19 |
- 关系分类标签的数量由数据集决定
我们这一节使用semeval10数据,数据集由训练集、验证集、测试集组成
semeval.txt文件是semeval10数据,是一个在学术论文中广泛使用的数据集。这个数据集每一行是一个JSON文件,形式如下:
{"token": ["the", "original", "play", "was", "filled", "with", "very", "topical", "humor", ",", "so", "the", "director",
"felt", "free", "to", "add", "current", "topical", "humor", "to", "the", "script", "."], "h": {"name": "play",
"pos": [2, 3]}, "t": {"name": "humor", "pos": [8, 9]}, "relation": "Component-Whole(e2,e1)"}
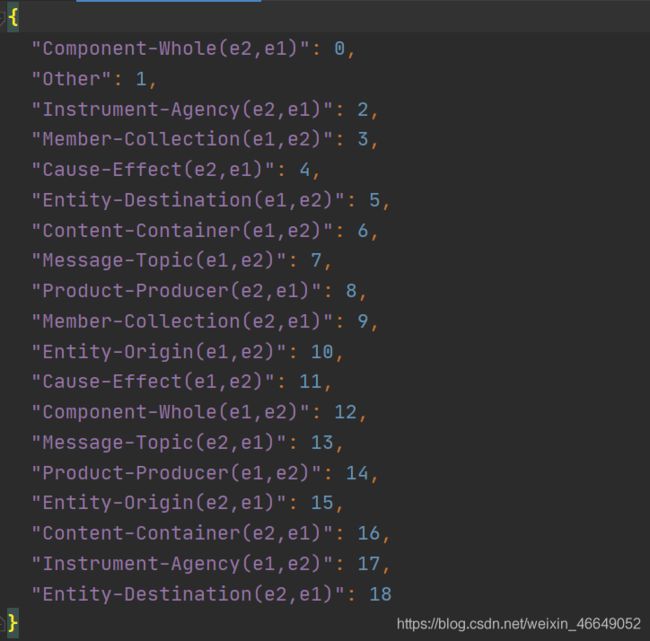
semeval_rel2id.json文件是给定的关系分类标签映射,一共19个关系分类标签
三、代码介绍
data_loader.py文件:这个文件的功能是将文本文件转化成InputExample类数据,并将输入样本转化为bert能够读取的InputFeatures类数据,最后保存至cache文件中,方便下次快速加载。utils.py文件:封装了很多实用程序,方便统一调用trainer.py文件:定义了任务的训练与评估以及保存模型与加载模型main.py文件:用于模型的训练与评估predict.py文件:用于模型的预测modeling_bert.py文件:自定义关系分类BERT模型
1.Focal loss损失函数
F L ( p t ) = − α t ( 1 − p t ) γ l o g ( p t ) FL(p_t)=-\alpha_t(1-p_t)^{\gamma}log(p_t) FL(pt)=−αt(1−pt)γlog(pt)
-
α t \alpha_t αt: 针对类别数量不均衡;
-
( 1 − p t ) γ (1 - p_t)^{\gamma} (1−pt)γ: 样本的正确标签为 t t t,原本的CE损失为 − l o g ( p t ) -log(p_t) −log(pt)
-
如果 p t p_t pt很大,说明模型对这个预测结果很自信, ( 1 − p t ) γ (1 - p_t)^{\gamma} (1−pt)γ很小,也就是说这种自信的样本对总体损失的贡献比较小;
-
如果 p t p_t pt很小,说明模型对这个预测结果置信度比较差, ( 1 − p t ) γ (1 - p_t)^{\gamma} (1−pt)γ接近于一,对总体损失的贡献比重升高;
-
自定义Focal loss损失函数代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class FocalLoss(nn.Module):
r"""
This criterion is a implemenation of Focal Loss, which is proposed in
Focal Loss for Dense Object Detection.
Loss(x, class) = - \alpha (1-softmax(x)[class])^gamma \log(softmax(x)[class])
The losses are averaged across observations for each minibatch.
Args:
alpha(1D Tensor, Variable) : the scalar factor for this criterion
gamma(float, double) : gamma > 0; reduces the relative loss for well-classified examples (p > .5),
putting more focus on hard, misclassified examples
size_average(bool): By default, the losses are averaged over observations for each minibatch.
However, if the field size_average is set to False, the losses are
instead summed for each minibatch.
"""
def __init__(self, class_num, alpha=None, gamma=2, size_average=True):
super(FocalLoss, self).__init__()
# 如果alpha为空,则每个类的权重是相同的
if alpha is None:
self.alpha = torch.ones(class_num, 1)
# 如果alpha不为空,torch.FloatTensor初始化alpha
else:
self.alpha = torch.FloatTensor(alpha)
# gamma默认为2,gamma越大表示自信样本对总体损失的贡献越低
self.gamma = gamma
# 类别总数
self.class_num = class_num
# 区分计算的是batch的总损失还是batch的平均损失
self.size_average = size_average
def forward(self, inputs, targets):
"""
定义前向传播
:param inputs: 分类层给出的logits[B,class_num]
:param targets:正确标签
:return:
"""
# batch size
N = inputs.size(0)
# class_num
C = inputs.size(1)
# 将logits进行softmax归一化
P = F.softmax(inputs)
# 正确标签及其对应的预测概率才会对loss产生影啊, class_mask在这个点上为1
class_mask = torch.zeros_like(inputs).to(inputs.device)
# 正确标签
ids = targets.view(-1, 1)
# 在class_mask的对应位置填充1
class_mask.scatter_(1, ids.data, 1.)
# print("class_mask: ", class_mask)
# 如果inputs是gpu上的数据,而alpha是cpu上的数据,那么需要进行转换
if inputs.is_cuda and not self.alpha.is_cuda:
self.alpha = self.alpha.cuda()
# 获取对应类别的类别权重,即每个样本的权重
alpha = self.alpha[ids.data.view(-1)]
# print("alpha: ", alpha)
# 获取每个样本在正确分类上的概率值
probs = (P * class_mask).sum(1).view(-1, 1)
# print("probs: ", probs)
# 将概率值进行log处理
log_p = probs.log()
# print('log_p size= {}'.format(log_p.size()))
# print(log_p)
# 计算batch loss
batch_loss = -alpha * (torch.pow((1 - probs), self.gamma)) * log_p
# print('-----bacth_loss------')
# print(batch_loss)
# 计算平均损失
if self.size_average:
loss = batch_loss.mean()
# 计算总损失
else:
loss = batch_loss.sum()
return loss
四、测试结果
1.代码运行程序
如果不使用cls_vector,仅适用use entity_vector,
python bert_finetune_re/main.py --data_dir ./bert_finetune_re/data/ --task semeval10 --model_type bert --model_dir bert_finetune_re/experiments/outputs/rebert_0 --do_train --do_eval --train_batch_size 8 --num_train_epochs 8 --learning_rate 5e-5 --linear_learning_rate 5e-4 --warmup_steps 600 --ignore_index -100 --max_seq_len 64 --use_entity_vector
测试结果为:
re_acc = 0.7425414364640884
如果仅使用cls_vector,不使用entity_vector,
python bert_finetune_re/main.py --data_dir ./bert_finetune_re/data/ --task semeval10 --model_type bert --model_dir bert_finetune_re/experiments/outputs/rebert_2 --do_train --do_eval --train_batch_size 8 --num_train_epochs 8 --use_cls_vector --learning_rate 5e-5 --linear_learning_rate 5e-4 --warmup_steps 600 --ignore_index -100 --max_seq_len 64
测试结果为:
re_acc = 0.5915285451197053
如果使用cls_vector与entity_vector,
python bert_finetune_re/main.py --data_dir ./bert_finetune_re/data/ --task semeval10 --model_type bert --model_dir bert_finetune_re/experiments/outputs/rebert_2 --do_train --do_eval --train_batch_size 8 --num_train_epochs 8 --use_cls_vector --use_entity_vector --learning_rate 5e-5 --linear_learning_rate 5e-4 --warmup_steps 600 --ignore_index -100 --max_seq_len 64
测试结果为:
re_acc = 0.7325966850828729
如果使用mention_pooling = avg
python bert_finetune_re/main.py --data_dir ./bert_finetune_re/data/ --task semeval10 --model_type bert --model_dir bert_finetune_re/experiments/outputs/rebert_0 --do_train --do_eval --train_batch_size 8 --num_train_epochs 8 --learning_rate 5e-5 --linear_learning_rate 5e-4 --warmup_steps 600 --ignore_index -100 --max_seq_len 64 --use_entity_vector --mention_pooling avg
测试结果为:
re_acc = 0.7421731123388582
如果使用mention_pooling = max,
python bert_finetune_re/main.py --data_dir ./bert_finetune_re/data/ --task semeval10 --model_type bert --model_dir bert_finetune_re/experiments/outputs/rebert_0 --do_train --do_eval --train_batch_size 8 --num_train_epochs 8 --learning_rate 5e-5 --linear_learning_rate 5e-4 --warmup_steps 600 --ignore_index -100 --max_seq_len 64 --use_entity_vector --mention_pooling max
测试结果为:
re_acc = 0.7403314917127072
如果使用focal_loss,
python bert_finetune_re/main.py --data_dir ./bert_finetune_re/data/ --task semeval10 --model_type bert --model_dir bert_finetune_re/experiments/outputs/rebert_0 --do_train --do_eval --train_batch_size 8 --num_train_epochs 8 --learning_rate 5e-5 --linear_learning_rate 5e-4 --warmup_steps 600 --ignore_index -100 --max_seq_len 64 --use_entity_vector --mention_pooling start --use_focal_loss --focal_loss_gamma 2.5
测试结果为:
re_acc = 0.7384898710865562
因为这个数据集均衡性非常好,所以focal_loss没有好的效果
2.代码预测程序
python bert_finetune_ner/predict.py --input_file bert_finetune_ner/data/atis/test/seq.in --output_file bert_finetune_ner/experiments/outputs/nerbert_0/atis_test_predicted.txt --model_dir bert_finetune_ner/experiments/outputs/nerbert_0
如果对您有帮助,麻烦点赞关注,这真的对我很重要!!!如果需要互关,请评论或者私信!
