【AI】《ResNet》论文解读、代码实现与调试找错
前言
残差网络Resnet,被誉为撑起计算机视觉半边天的文章,重要性不言而喻。另外,文章作者何凯明,在2022年AI 2000人工智能最具影响力学者排行里排名第一:
为什么这篇文章影响力这么大呢?
通常来说,在同等条件下,网络越深,性能越好(暂且这样认为)。在resnet提出之前,网络无法做到“很深”,堆叠到二十多层就极容易出现梯度消失等问题,导致模型难以训练。resnet的出现,解决了这个问题,模型可以轻易堆叠到几十层上百层(一千层的都有)。那么,接下来就来看看这个网络是如何解决问题的吧。
下文主要包括:
-
论文分析
-
从头搭建resnet_50
-
Pytorch张量表示方法,搭建网络出错时该如何调试找错
正文:论文解读
论文地址:https://arxiv.org/abs/1512.03385

首先看摘要,实际上讲了一件事情:
以往的模型设计,往往通过增加网络的深度来实现更好的性能,但问题是,层数堆叠多了,一是极易造成梯度消失,二是难以训练,因此先前的模型如果能堆叠到二十多层并成功训练就已经万事大吉了。作者经过研究,发现问题主要出在信息传递这个过程中:每一次传递都没有可以“参考”的东西,只能根据上一层的信息来学习;如果在传递的过程中不断给予“指导”,就能够解决这个问题。
如何理解呢?
举个形象的例子:5个人、10个人、20个人分别进行传话,5个人的时候,传到最后可能还保留不少原始信息,10个人的时候,传到最后可能意思都变了一大半了,但还可以保留一部分有用信息,20个人的时候,传到最后可能已经大相径庭。如果第一个人能不断地提示后面的人,那么传到最后时,信息就能较为完整地保留下来。
下面给出论文中用的最多的一张图:

输入的x就是第一个传话人说的内容,中间的weight layer就是中间传话的人,右边的x(identity)就是第一个传话人提示后面某个人的真实内容;F(x)就是中间人传话的内容丢失情况,F(x)+x就是真实内容对传话内容的纠错。
例子举完了,相信大家也大致明白为什么要使用“残差”结构了。下面就从数学角度来看一下这种残差结构,分析一下为什么能够work:
一、为什么能够解决梯度消失的问题?
首先看核心公式:
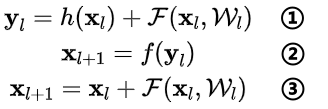
①式为恒等映射函数h(·)和残差函数F(·)之和,即:对第l层的输入x计算残差,再和x的恒等映射加起来,记作y;②式表示对y进行激活,得到第l层的输出(也就是第l+1层的输入);③式是对①和②的整理,可以用一个式子统一起来书写。
上面的公式是针对相邻两层的情况,那么对于任意深的单元L和任意浅的单元l有:

该式表示第L层的输入等于第l层的输出加上第l层到第L-1层的残差和,那么在优化的时候,只需要拟合残差项(后面的∑(·)),使之尽可能为0,就能实现第L层和第l层恒等,从而做到信息不丢失。为什么需要拟合残差呢?我个人的理解是:第L层和第l层之间的每一个部分,都会对当前造成影响,有些地方是不好的残差,那么优化方向可能会被带偏,起到反作用。
假如损失函数为ε,在反向传播时,对上面的式子求偏导,得到:
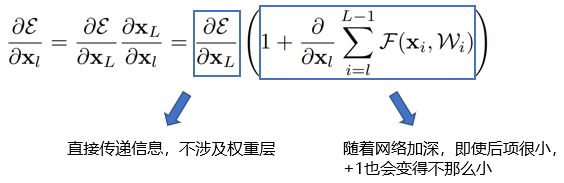
可以看到,左边蓝框框里的项没有权重信息,意味着反向传播的时候,信息能够从第L层直接传递到第l层,而无需经过权重,这就保证了信息的完整性。右边蓝框框里是1+▲是防止梯度消失的关键,因为目前大多用的是批量梯度下降算法,每次是把一个批量(batch)的样本送进去计算,那么不可能所有批量计算偏导的结果都为-1,从而1+▲在大部分情况下不会为0,因此即便某个批量计算的权重很小,都不会发生梯度消失。
二、为什么能够加快收敛速度?
实际上还是可以从上面的偏导公式来解释,在计算batch的梯度时,大多数情况可以获得一个较大的梯度值(因为有一个1在那里),从而可以大步向前走,更快地找到最优值。
另外,在整个模型中,浅层网络提取到的是低级特征,深层网络提取到的是复杂特征,如果没有恒等映射连接,那么最后是利用复杂特征进行拟合,从而比较费时,加入恒等映射,相当于保留了一部分低级特征用来判断。
理论方面讲完了,现在看看网络架构是什么样的:
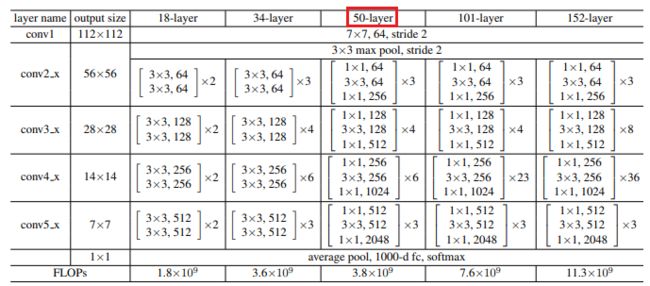
以50-layer为例,也就是后面将要实现的resnet_50,可以看到总共有6个模块,分别是:conv1、conv2_x、conv3_x、conv4_x、conv5_x、fc。
conv1主要是对原始输入图像进行第一波卷积,把输入图像从224缩小为112(这里的224和112指图像的长宽,后面同理);conv2/3/4/5_x是4个卷积模块,每个模块包含了多个由3个卷积层组成的小模块,例如,对于conv3_x这个模块来说,包含了4个小模块(右边有一个×4),每个小模块包含了3个卷积层。
fc主要是实现分类作用,这个层可以保留,也可以不要。
可视化网络架构:
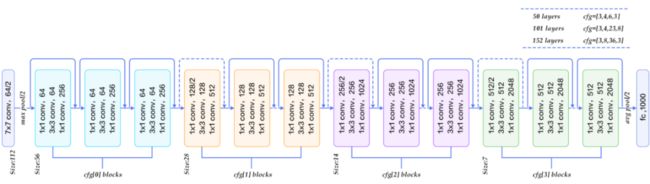
注:可以看到图中跳跃连接的地方有实线和虚线之分,区别是:实线表示不需要改变图像大小(卷积步长为1),虚线表示要把图像大小减半(卷积步长为2)
正文:代码实现——从头搭建resnet_50
一、模型搭建(很多坑)
Pytorch已经在torchvision.models里集成了resnet模型,但是官方代码较为复杂,因为resnet模型有多种结构(resnet_18/34/50/108/152),还有很多变种(不同宽度、不同组数),而官方都在一个代码文件里进行实现,因此看上去比较繁琐。因为这篇文章主要是介绍resnet_50,因此我把源码做了大量修改,以便更容易读懂。下面给出resnet_50的简洁实现方式。
考虑到用注释的方式讲解代码不太合适,编辑器里无法修改字体样式,所以需要重点讲解的地方将放在后面。
注意!!这里代码块无法显示行号,而后面的讲解是基于行号来讲的,所以推荐大家去我的微信公众号看这篇文章,公众号在文末可查看。(我也没办法)
import torch
import torch.nn as nn
class BottleNeck(nn.Module):
expension = 4 # 瓶颈层里的第三个卷积层的通道数是第二个的4倍
def __init__(self, in_channel, out_channel, stride=1, channel_match = None):
super(BottleNeck, self).__init__()
# 第一个卷积层
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=1, stride=stride, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
# 第二个卷积层
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
# 第三个卷积层
self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel*self.expension, # 这里扩充通道数
kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channel*self.expension)
self.relu = nn.ReLU(inplace=False)
self.channel_match = channel_match
def forward(self, x):
identity = x
if self.channel_match is not None: # 这个if一定要加上
identity = self.channel_match(x)
# print('x:',x.shape)
# print('identity:', identity.shape)
# 卷积层1
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
# print('x1:', out.shape) # x1: torch.Size([2, 64, 56, 56])
# 卷积层2
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
# print('x2:', out.shape)
# 卷积层3
out = self.conv3(out)
out = self.bn3(out)
# print('x3:', out.shape)
# 直连+跳跃
out += identity
out = self.relu(out)
return out
class ResNet_50(nn.Module):
def __init__(self,
block = BottleNeck,
block_nums = [3,4,6,3],
num_classes=14):
super(ResNet_50, self).__init__()
self.in_channel = 64
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=False)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self.make_layer(block, 64, block_nums[0])
self.layer2 = self.make_layer(block, 128, block_nums[1], stride=2)
self.layer3 = self.make_layer(block, 256, block_nums[2], stride=2)
self.layer4 = self.make_layer(block, 512, block_nums[3], stride=2)
self.avepool = nn.AvgPool2d(kernel_size=7, stride=1)
self.fc = nn.Linear(2048, num_classes)
def make_layer(self, block, first_channel, block_num, stride = 1):
expansion = 4
channel_match = None
layers = []
channel_match = nn.Sequential(nn.Conv2d(self.in_channel, first_channel*expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(first_channel*expansion)
)
layers.append(block(self.in_channel, first_channel,
channel_match = channel_match, stride = stride)) # 只有这里需要channel_match!
self.in_channel = first_channel*expansion
for _ in range(1, block_num): # 这里不需要channel_match!
layers.append(block(self.in_channel, first_channel))
return nn.Sequential(*layers)
def forward(self, x):
# print('输入x:',x.shape)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
# print('conv1 x:', x.shape)
x = self.maxpool(x)
# print('conv2_x_maxpool x:', x.shape)
x = self.layer1(x)
# print('conv2_x_1 x:', x.shape)
x = self.layer2(x)
# print('conv2_x_2 x:', x.shape)
x = self.layer3(x)
# print('conv2_x_3 x:', x.shape)
x = self.layer4(x)
# print('conv2_x_4 x:', x.shape)
x = self.relu(x)
x = self.avepool(x)
# print('avepool x:', x.shape)
x = torch.flatten(x,1)
# print('flatten x:', x.shape)
x = self.fc(x)
return x
代码关键地方讲解:
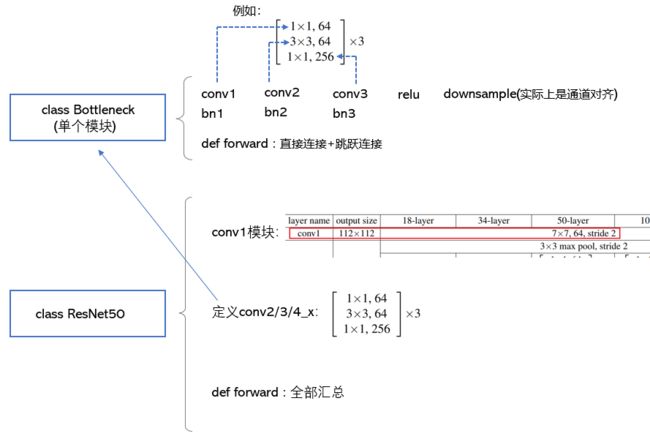
1. 第4行:定义一个BottleNeck类,也就是论文中对应的conv2/3/4/5_x,之所以要单独定义,是因为这样做可以更方便地搭建中间的小模块,因为这些小模块中,卷积核的大小都是规律的(1×1,3×3,1×1),只有通道数不同,那么只需把通道数设为一个参数,就能够用for循环快速搭建中间的那48个卷积层。
代码框架如下:
2. 第26行,self.relu = nn.ReLU(inplace=False)这里有个bug,ReLU里面的参数需要置为False,不然会报错,有的人认为是Pytorch版本的问题,但我跑AlexNet的时候,参数置为True就不会报错...看来真是bug看人品。
3. 第33-34行,if self.channel_match is not None: 这条语句不能漏!因为每一个小模块里,只有第一个卷积层(红色框)需要通道匹配(channel_match),而剩余两个是不需要匹配的,由第7行可知参数channel_match = None是默认的,第89-92行定义了channel_match(not None),第94-95行传入这个not None的channel_match给第7行,从而第33-34行的if语句就判为真,执行identity = self.channel_match(x),从而使得跳跃连接的通道数能够匹配上。
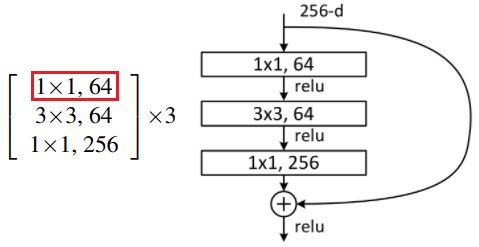
4. 第75-78行,只有self.layer1不指定步长stride的参数,从而是第7行默认参数stride=1,其余的层都需要指定参数stride=2,因为把特征图从112砍半的事情,conv1的maxpool层已经做了(第74行MaxPool2d的参数stride=2) ,而conv3/4/5_x需要自己通过卷积核的stride=2来砍半。
正文:Pytorch张量表示方法&调试方法
在这个模块中,将介绍Pytorch框架下张量的一些表示方法。这部分我觉得挺重要的,因为不论是跑别人的模型,还是自己搭模型,有一个很重要的环节就是张量的形状匹配,很多的Error都出现在这个地方。
一、张量表示方法。
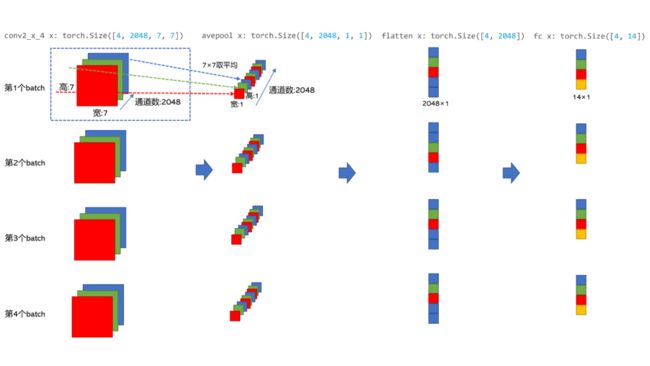
conv2_x_maxpool x: torch.Size([4, 64, 56, 56])
conv2_x_1 x: torch.Size([4, 256, 56, 56])
conv2_x_2 x: torch.Size([4, 512, 28, 28])
conv2_x_3 x: torch.Size([4, 1024, 14, 14])
conv2_x_4 x: torch.Size([4, 2048, 7, 7])
avepool x: torch.Size([4, 2048, 1, 1])
flatten x: torch.Size([4, 2048])
fc x: torch.Size([4, 14])第1行,对应下图红框处的输出,torch.Size([4, 64, 56, 56])中的数字分别表示:(batch_size,通道数,特征图宽,特征图高)

第2-5行,对应下图红框处的输出:

后面以此类推。
下面画个图来捋一捋batch、通道数等之间的关系:(这个图用PPT画了很久)
二、模型调试方法(主要针对张量大小问题)
前排tips:如果出错了,最好用print(tensor.shape)输出张量的大小来查看是哪里的问题。
当你在开始训练时,突然报错了,看Traceback可知,是特征图的大小出了问题,那么可以判断:应该是kernel_size或stride或padding出问题了:

往上找,发现在这个位置输出x1的形状,说明是conv1的参数设置错了(bn和 relu不会改变张量形状):

经过检查,发现是paddind设置错了,需要修改:

经过修改,再次运行,发现形状正确:
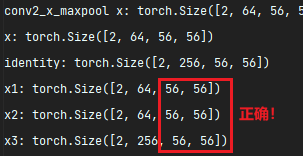
如果张量的形状全部能够匹配上,那么就成功一大半了!还有其它调试方法待我继续尝试,后面再分享吧。
后记:虽然resnet看上去挺简单的,但实现起来并不简单,看一遍源码和自己写一遍是两码事,因为很多细节只有在调试的时候才会发现。尽管写这篇文章花了很多精力,但是能把知识分享出去就挺开心的。
如有新的想法,期待交流探讨

关注我的微信公众号“风的思考笔记”,我们一起思考当下,探索未来自由之路。
