扩散模型(Diffusion Model)最新综述!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本综述来自西湖大学李子青实验室、香港中文大学Pheng-Ann Heng和浙江大学陈广勇团队,对现有的扩散生成模型进行了全面的回顾。
本文首先提出了diffusion model改进算法的细化分类与深度解析,同时对diffusion model的应用进行了系统的回顾,最后率先汇总领域内benchmarks。这也促进了后续工作《Diffusion Models: A Comprehensive Survey Of Methods and Applications》在9.7之后的改进。

文章链接:https://arxiv.org/abs/2209.02646
https://github.com/chq1155/A-Survey-on-Generative-Diffusion-Model
0. Abstract
深度学习在生成任务中显示出巨大的潜力。生成模型是类可以根据某些隐含的参数随机生成观察结果的模型。最近,扩散模型凭借其强大的生成能力,成为生成模型的一大热门。已经取得了巨大的成就。除了计算机视觉、语音生成、生物信息学和自然语言处理之外,更多的应用将在这一领域得到探索。然而,扩散模型有其天然的缺点,即生成过程缓慢,据此,有许多强化的工作近些年被陆续提出。本调查对扩散模型领域进行了总结。作者首先阐述了两个标志性工作的主要问题--DDPM(Denoising Diffusion Probabilistic Model) 和DSM(Denoising Score Match)。然后,我们介绍了一系列加快扩散模型的先进技术--训练方式、免训练采样、混合模型和分数与扩散统一。关于现有的模型,作者还提供了一个FID评分的基准。我们还根据具体的NFE提供了FID得分、IS和NLL的基准。此外,作者还介绍了扩散模型的应用,包括计算机视觉、序列建模、音频、人工智能等。序列建模、音频、科学的AI。最后,作者也对这一领域进行了总结,并提出了局限性和进一步的方向。
1. Introduction
深度生成模型例如,VAE、EBM、GAN、归一化流和扩散模型 已经创造人类无法正确区分的新模式方面显示出巨大潜力。我们专注于基于扩散的生成模型。它不需要像VAE那样对准后验分布。VAE,像EBM那样处理难以解决的分区函数。训练额外的判别器(如GAN),或施加网络约束(如归一化流)。由于上述优点,基于扩散的方法已经引起了计算机视觉、自然语言处理和图分析的广泛关注。然而,目前仍然缺乏扩散模型的研究进展的系统分类和分析。扩散模型的进展提供了可操作的描述模型的概率参数化,有足够理论支持的稳定训练程序。统一的损失函数设计,具有高度的简单性。扩散模型旨在将先验数据分布转化为随机噪声,然后再一步一步地修正转换,从而重建一个全新的扩散模型的目的是将先验数据分布转化为随机噪声,然后再一步步修正转化,从而重建一个以相同分布为先验的全新样本。近几年来,扩散模型在计算机视觉(CV)领域显示了其巨大的潜力。计算机视觉(CV), 生物信息学,和语音处理。例如,去噪扩散GANs产生了高分辨率的假图像,只用了只需四个采样步骤就能击败GAN。Luo等人首先使用原子分辨率生成了抗体CDR序列和结构通过使用蛋白质特征的DDPMs,在原子分辨率上生成了抗体CDR序列和结构。Wavegrad以恒定的代数步骤生成了高保真的音频样本。辈分不变的情况下生成高保真的音频样本,其性能超过了现有的基于GAN的音频生成模型。受迄今为止扩散模型在CV、生物信息学和语音处理领域所取得的成功启发,将扩散模型应用于语音处理领域。扩散模型在CV、生物信息学和语音处理领域的成功,将扩散模型应用于将扩散模型应用于其他领域的生成相关任务,将是一条利用强大的生成模型的有利途径。将扩散模型应用于其他领域的生成相关任务,将是利用强大生成能力的有利途径。另一方面,扩散模型具有固有的与生成对抗模型相比,扩散模型有一个固有的缺点,即大量的采样步骤和较长的采样。与生成对抗网络(GANs)相比,扩散模型有一个固有的缺点,即采样步骤多,采样时间长;和变异自动编码器(VAEs)相比,扩散模型有一个固有的缺点,即大量的采样步骤和较长的采样时间。这是因为使用马尔科夫核的扩散步骤只需要微小的扰动,这导致了大量的扩散。同时,可操作的模型在推理过程中需要相同数量的步骤推理过程中。因此,它需要成千上万的步骤来对随机噪声进行采样噪声,直到它最终改变为高质量的数据与先验数据相似。因此,很多工作都希望加快扩散过程,同时提高采样质量 。例如,DPM-solver就利用了ODE的稳定性来生成样本在10个步骤内生成最先进的样本 。ES-DDPM成功地将轨迹学习与变异自动编码器,实现了对扩散模型的高速采样。扩散模型的高速采样。部分地受到Bao等人的启发,我们我们将有关扩散模型的改进工作总结为四类。(1) 训练方式;(2) 免训练采样,(3)混合生成模型,(4)分数和扩散统一。详细内容见第3节。

图1. 在这个图中,我们为每一类生成模型提供了一个直观的机制产生式模型的直观机制。(a) 生成式对抗网络(GAN); (b) 基于能量的模型(EBM); (c) 变量自动编码器(VAE); (d) 归一化流(NF); (e)扩散模型(diffusion model)
因此,基于广泛的应用以及对算法改进的多角度思考 x0 分类,本评论的核心贡献如下:
总结了本质上的数学表述和扩散模型领域的基本算法的推导,包括方法的制定、训练策略和采样算法。
提出最新的扩散算法改进工作的分类,并将其划分为分为四类:训练方式、无训练采样、混合模型、扩散模型和分数模型的统一。
提供广泛的扩散模型在计算机视觉、自然语言处理、生物信息学和语音处理上的应用,包括领域专业问题的提出、相关数据集、评估指标、下游任务,以及一系列的基准。
阐明当前模型的局限性和可能的关于扩散模型领域的进一步证明方向。
2. Problem Statement
2.1 概念和定义
定义1(前向过程)给定数据,一列潜在的的尺寸与相同,并且有一个序列的方差表由
,组成。我们定义前向过程是一个马尔可夫核的序列,名为扩散/前向步骤。
通过一连串从到的扩散步骤,我们有前向/扩散过程。
定义2(逆向过程)鉴于上述的正向过程的正向过程,我们将逆向步骤定义为与学习到的高斯转换的逆向步骤。
通过从到的一系列反向步骤,有:
其中的分布可以表示为
定义3(正向SDE过程)扩散过程可以被看作是一个由随机微分方程描述的连续情况,它等于 Itoˆ SDE的解:
其中,是标准的Wiener过程/布朗运动,是的漂移系数,是简化版的的扩散系数,假定其不依赖于。此外, , 表示数据分布和的概率密度表示原始先验分布,它没有从中获得任何信息。当系数为连续时, 前向SDE方程有唯一解。与离散情况类似,SDE框架中的前向转换被推导为:
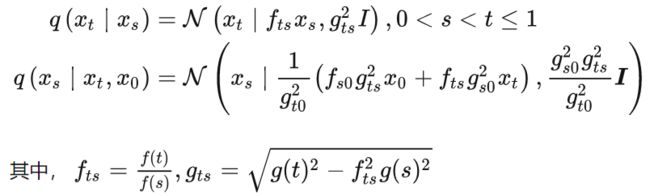
定义4(逆向SDE过程)与正向SDE过程相反,逆向SDE过程被定义为:
其中被称为标准Wiener过程,从时间到,而被定义为无限小的负时间步长。此外,是需要匹配的分数。
定义5(信噪比)信噪比的定义是平均系数和方差,在时间t的被定义为:
Kingma等人提出的信噪比是一个递减函数,在重新表达训练目标时被用作一个变量,以简化和统一不同类型模型的训练目标。

2.2 问题表述
扩散模型的目的是分解特定的数据分布 p(x) ,并从随机噪声中一步步重建数据。由于中间过程是随机不稳定的,整个过程是生成的。此外,可逆的随机步骤确保了模型的广泛保真和样本质量。所以,利用扩散模型就是重建先验数据分布。可以分为两大类任务:分别是Diffusion和Score Matching。
2.2.1 Denoised Diffusion

2.2.2 Denoised Score Matching

3. Improved Algorithms
当今diffusion model面临的主要问题是采样缓慢以及计算消耗过大。对于现有的Improved algorithms,本文根据改进方式将现有方法分为四类:分别是训练方式的改进、无训练采样、混合模型改进、以及score与diffusion的统一。对于每个大类,文章细化分类,在描述改进思想的介绍之外,并且对类别内每篇文章进行详细的分析与宏观的分类。
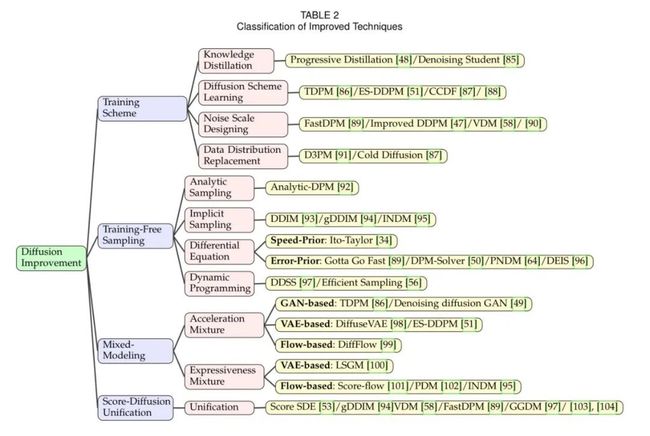
3.1 训练方式改进
改变传统的训练方式例如扩散过程、噪声规模和数据分布,这些方案与采样无关。最近的相关研究表明,训练方案是影响学习模式和模型性能的关键因素。因此,在这一小节中,我们将训练的提升分为四类:知识蒸馏、扩散过程改进、噪声规模学习和数据分布替换。
3.1.1 知识蒸馏
知识提炼是一种新兴的方法,通过将 "知识 "从具有高学习能力的复杂教师模型转移到简单的学生模型中,从而获得高效的小规模网络。因此,学生模型具备了模型压缩和模型加速方面的优势。
Salimans等人首先将核心思想运用到扩散模型的改进中,将知识从一个采样模型逐步提炼到另一个。在每一个提炼步骤中,学生模型在被训练成与教师模型一样接近地产生单步样本之前,从教师模型中重新加权。因此,在每个蒸馏过程中,学生模型可以将其采样步骤减半。遵循与DDPM相同的训练目标,采用替代的参数化方法,渐进式蒸馏模型仅用4步就达到了2.57的FID。这一核心思想被应用于文本到语音生成领域的ProDiff。ProDiff的采样质量在SOTA左右,只有2个采样步骤,而以前的SOTA DiffSpeech需要128个步骤进行采样。沿着蒸馏路径的进一步改进包括去噪学生,其中教师模型通过最小化两个模型的样本的L2损失直接指导学生模型的采样模式。去噪学生得到的单步采样的FID分数为9.36,而渐进蒸馏法单步生成的FID分数为9.12。
3.1.2 扩散过程改进
扩散方案学习旨在探究不同的扩散模式对模型速度的影响。最近的研究集中在扩散步骤上。TDPM首先提出,截断扩散过程和采样过程,导致更少的采样时间,有利于减少采样时间,同时提高生成质量。截断模式的关键思想是在GAN和VAE等其他生成模型的帮助下生成更少的扩散数据。TDPM使用GAN以及条件传输,从随机噪声中学习隐性生成分布。与TDPM不同,Early Stop (ES) DDPM通过使用VAE生成先验数据来生成隐性分布,VAE从x_0中学习潜在空间。更为普遍的是,CCDF表明,存在一个小于T的最佳步骤,通过收缩理论使估计误差最小。除了减少步骤的捷径思想,Franzese等人将训练步骤的数量定义为一个变量,以便在探测最佳步骤的同时更灵活地训练模型。
3.1.3 噪声规模学习
与DDPM将噪声尺度定义为常数不同,有关噪声尺度学习效果的探索工作也引起了人们的关注,因为在扩散和抽样过程中,噪声表的学习也会被计算在内。每个采样步骤可以被看作是指向先验分布的直线上的随机行走,这表明噪声调整可能有利于采样程序。Improved DDPM首先考虑了噪声尺度的调整,其方式是在 L_{simple} 上定义增加一个\lambda尺度的项 L_{vlb} 。与改进的DDPM不同,San Roman等人提出了一种包含另一个噪声预测网络 P_{\theta} 的噪声估计方法,在进行祖先采样前的每一步中更新噪声尺度。因此,优化损失 L_{hybrid} 会导致学习噪声时间表。值得庆幸的是,改进的DDPM超过了DDIM的50步。此外,FastDPM和VDM对噪声标度 \alpha_t 和 \beta_t 进行了重新参数化,以直接表达与噪声标度有关的损失项,从而优化了与噪声计划有关的程序。总而言之,噪声学习引导了扩散和采样过程中的随机噪声的随机行走,导致了更有效的重建。
3.1.4 数据分布替换
数据分布替换主要集中于处理不同类型的数据分布。从先验分布的角度来看,D3PM将扩散算法推广到离散空间,通过定义句子和图像等离散数据来处理。

此外,Cold Diffusion表明,噪声的数据分布可以通过冷扩散改进的采样设置为任何分布,以消除重建器 R (所有类型采样器的总称)的错误设计所带来的预测误差。Cold Diffusion改进型抽样是:

3.2 无训练采样改进
许多方法专注于改变训练和噪声安排的模式,以提高采样速度,但重新训练模型需要花费更多的计算,并导致不稳定的训练风险。值得庆幸的是,存在着一类直接用预训练的模型增强采样算法的方法,这就是所谓的免训练采样。高级免训练抽样的目标是提出一种高效的抽样算法,以更少的步骤和更高的精度从预训练的模型中获取知识。它包含四类:分析方法、隐式采样器、微分方程求解器采样器和动态规划调整。
3.2.1 分析方法
Bao等人首先提出了名为分析性DPM的分析方法。它通过KL-Divergence分析优化反向方差来改进DDIM。
3.2.2 隐式采样
如上所述,在DDPM中,生成过程和扩散过程重建原始数据分布,通常需要相同的步骤数。然而,扩散模型具有所谓的解耦特性,不需要扩散和采样的等量步骤。受生成性隐式模型的启发,Song等人提出了配备确定性扩散和跳步采样的隐式采样方法DDIM。令人惊讶的是,由于前向扩散概率密度在 [0,T] 内的任何时间 t 都保持不变,所以隐式模型没有重新训练模型的要求。DDIM使用连续过程公式解决了跳步加速问题,其形式为:

在DDIM的基础上,gDDIM将SDE框架中具有不同类型内核的隐性扩散,包括DDPM、DDIM和critically-damped Langevin diffusion(CLD)概括为DDIM家族,通过相应的ODE和SDE求解器实现了隐性扩散模型的加速。与上述不同的是,INDM 通过将非线性扩散过程归一化为线性隐空间扩散,实现了隐性机制。
3.2.3 微分方程求解器采样器
与传统的离散步骤的扩散方法相比,微分方程的数值公式通过高级求解器实现了更有效的采样。受Score SDE和Probability Flow (Diffusion) ODE的启发,有几项工作的核心是用先进的微分方程求解器进行高效采样,用较少的采样步骤使近似误差最小。现有的方法可以分为基于ODE和基于SDE。基于SDE的方法利用得分SDE中的公式和求解器,如Euler-Maruyama(EM)、改进的Euler和随机Runge-Kutta(RK)方法。基于ODE的方法有更广泛的选择,如Runge-Kutta、Forward Euler和线性多步法。一般来说,在采样速度和采样质量之间存在一个权衡。虽然高阶微分方程求解器具有较小的近似误差和较高的收敛阶数,但线性求解器需要较少的评估。此外,与SDEs相比,ODEs的求解更容易、更简单。因此,微分方程的选择与相关求解器的数量导致了另一种分类方式--在ODE、SDE和半线性DE领域的准确度优先和速度优先。
对于首选精度利用高阶求解器的方法,已经提出了使用高阶SDE求解器的Itô-Taylor采样方案。不同的是,该采样器应用理想导数替代,以一种巧妙的方式将分数函数参数化,避免了高阶导数计算。
还有一些方法,通过应用线性求解器和高阶求解器,如Gotta Go Fast和PNDM,来改善整个过程。它推导出一种基于的算法来实现对步长调整的方向性引导。在采样过程中,该方法将线性求解器(Euler-Maruyama方法)与高阶求解器(改进的Euler方法)相结合,采用外推技术,以较少的额外计算来加速。它可以在CIFAR-10上以150步达到小于3.00的FID分数。PNDM已经探索了不同的数值求解器可以共享相同的梯度。因此,它探索了在扩散ODE中使用3步高阶求解器(Runge-Kutta方法)后的线性多步法。此外,DPM-solver还利用了不同阶的求解器。根据经验,在所有的选择中,DPM-Solver-Fast(不同阶数求解器的混合进展)表现最好。因此,经过精心设计,一个联合的求解器交叉替代顺序可能有更好的性能。
此外,从微分方程选择的角度来看,DPM-solver和DEIS创造了一个新的观点,除了SDE和扩散ODE。他们声称,扩散ODE可以被看作是一种半线性形式,通过这种形式可以减少离散化误差。DPM-solver在CIFAR-10的50步内完成了SOTA,它可以在10步内生成高质量的图像(< 7 FID score),这是一个广泛的升级。另一方面,DEIS通过使用指数积分器,用多步PC取样法改进了数值DDIM。此外,DEIS-tAB3在5、10、15和20步内达到了CIFAR10的SOTA,相应的FID得分为15.37、4.17、3.37和2.86。因此,通过将其视为半线性结构来解决数值扩散模型,可获得最有效的采样质量。
3.2.4 动态规划调整
动态编程实现了对所有选择的遍历,通过记忆技巧在非常短的时间内找到优化的解决方案。与其他高效采样相比,采用动态编程的方法定位优化的采样路线,而不是设计强大的步骤,使误差最小化的速度更快。假设从一个状态到另一个状态的每条路径与其他路径有相同的KL-Divergence,Watson等人提出了一种高效采样方法,直接搜索具有最小ELBO的优化采样路线。这种方法只需要 O(T^2) 进行计算和恢复,它探索了一种优化轨迹的新方法。然而,ELBO上的最小化有时与FID分数不匹配。受Kumar等人的启发,可微分的扩散采样器搜索(DDSS)利用重物化技巧来交换内存成本和计算时间。
3.3 混合模型改进
混合模型是指在扩散模型的管道中加入另一种生成模型,以利用其他模型的高采样速度,如对抗性训练网络和自动回归编码器,以及像归一化流那样的高表达能力。因此,通过将两个或更多的模型与特定的模式联合起来,提取所有的优势,进行有前途的增强,这被称为混合模型。混合建模从混合目的的角度可以分为两类:加速混合和表现力混合。
3.3.1 加速混合


3.3.2 表现力混合
另一类混合建模称为表达性混合,支持扩散模型对表达数据或噪声的不同模式。至于噪声调制,DiffFlow在每个基于SDE的扩散步骤中采用流函数向前和向后,通过最小化前向过程和后向过程之间的KL-Divergence,自适应地、有效地添加噪声。与DDPM相比,DiffFlow导致了20*的速度提升,尽管由于流函数的反向传播,每一步需要更长的时间。另外一组模型利用NFs进行数据转换。基于其潜在空间(非连续数据)的训练数据使我们能够在更小的空间内学习更平滑的模型,引发更少的网络评估和更快的采样。因此,LSGM和PDM都分别使用VAE和流函数获得潜变量。此外,基于最大似然估计(MLE)的目标,LSGM与VAE共同训练了扩散过程,而PDM与可逆归一化流共同训练了分数匹配的SDE。此外,Score-Flow采用归一化流将数据分布转化为非量化场,并进行扩散过程以生成非量化样本。通过变分去量化将数据投射到去量化场,解决了连续密度和离散数据之间的不匹配问题,消除了去量化空间和离散空间之间的差距,从而提高了样本质量。

3.4 分数与扩散统一
有许多关于用广义的扩散模型来统一扩散模型的工作。关于广义扩散的加速方法对解决广泛的模型有很大的帮助,同时对有效的采样机制有深入的了解。另外,其他相关工作确定了扩散模型和去噪分数匹配之间的联系,这可以看作是统一的一种类型。

从统一的角度来看,得分SDE是将两类问题合二为一并提出统一框架的标志性工作。Gong等人,揭示了分数匹配与归一化流之间的隐藏联系,并提供了一种用流式ODEs表达分数匹配的新方法。Bortoli等人提供了一种使用Doob-h变换模拟扩散桥的变分匹配方法。
4. Application
得益于生成真实样本的强大能力,扩散模型已被广泛应用于各种领域,如计算机视觉、自然语言处理和生物信息学。
4.1 计算机视觉
4.1.1 低水平视觉
CMDE根据经验比较了基于分数的扩散的扩散方法进行了比较图像数据,并引入了一个多速扩散框架。通过利用可控制的扩散速度的条件的可控扩散速度,CMDE的表现优于普通的条件性去噪估计器[59]在绘画和超分辨率任务中的FID得分。DDRM提出了一种高效、无监督的后验估计器。高效、无监督的后验采样方法,用于图像修复。在变异推理的激励下,DDRM证明了其在超分辨率、去模糊、绘画和扩散模型着色方面的成功应用。Palett进一步开发了基于扩散的统一框架,用于低级别的视觉任务,例如着色、画中画、去粗取精和修复。这项工作以其简单而普遍的想法证明了扩散模型的性能优于GAN模型。DiffC提出了一种无条件生成的方法,用一个扩散模型对损坏的像素进行编码和去噪,这显示了扩散模型在有损图像压缩中的潜力。SRDiff利用了基于扩散的单图像超级分辨率模型,并显示了有竞争力的结果。RePaint是一种自由形式的涂抹方法,它直接采用了一个预训练的扩散模型作为生成性先验,并且只用取代了反向扩散,使用给定的图像信息对未被掩盖的区域进行采样。扩散模型作为生成先验,仅通过使用给定的图像信息对未遮盖的区域进行采样来取代反向扩散。虽然没有对香草预训练的扩散模型进行修改,但该方法在极端任务下的表现超过了自回归和GAN方法在极端任务下的表现。
4.1.2 高层视觉
FSDM是一个基于条件扩散模型的几率生成框架。利用视觉变换器和扩散模型的进步,FSDM可以在测试时快速适应各种生成过程,并在几率生成下表现良好,具有强大的转移能力。CARD提出了分类和回归扩散模型,结合了基于去噪扩散的条件生成模型和预训练的条件平均估计器,以预测给定条件下的数据分布。虽然从条件生成的角度接近监督学习,并以与评价指标间接相关的目标进行训练,但CARD在扩散模型的帮助下,在不确定性估计方面呈现出强大的能力。在CLIP的激励下,GLIDE探索了以文本为条件的现实图像合成,并发现具有无分类器指导的扩散模型产生了包含广泛的学习知识的高质量图像。为了在一个平滑而有限的空间内获得富有表现力的生成模型,LSGM在变异自动编码器框架的帮助下建立了一个在潜伏空间内训练的扩散模型。SegDiff扩展了扩散模型,通过对基于扩散的概率编码器和图像特征编码器的特征图进行汇总,进行图像级别的分割。另一方面,视频扩散在时间轴上扩展了扩散模型,并通过利用典型设计的重建指导条件采样方法进行视频级生成。VQ-Diffusion通过探索离散扩散模型的无分类器指导采样和提出高质量的推理策略,改进了香草矢量化的扩散。该方法在ImageNet和MSCOCO等大型数据集上表现出卓越的性能。
4.1.3 3D 视觉
《Diffusion probabilistic models for 3d point cloud generation》是一项关于基于扩散的三维视觉任务的早期工作。在非平衡热力学的激励下,这项工作将点云中的点类比为热力学系统中的粒子,并在点云生成中采用了扩散过程,从而获得了具有竞争力的性能。
PVD是一项同时进行的基于扩散的点云生成工作,但在没有附加形状编码器的情况下进行了无条件生成,同时采用了混合和点-体素表示法来处理形状。PDR提出了一种基于扩散的点云完成范式,应用扩散模型来生成基于部分观察的粗略完成,并通过另一个网络来完善生成的输出。为了处理点云去噪问题,《Score-based point cloud denoising》引入了一个神经网络来估计分布的分数,并通过梯度上升对点云进行去噪。
4.1.4 视频建模
Video diffusion将基于扩散的生成模型的进展引入视频领域。RVD采用了扩散模型来生成以上下文向量为条件的下一帧确定性预测的残差。FDM应用扩散模型来帮助长视频预测,并进行照片式的现实视频。MCVD提出了一个有条件的视频扩散框架,用于视频预测和基于遮挡帧的顺时针插值。RaMViD用三维卷积神经网络将图像扩散模型扩展到视频,并设计了一种用于视频预测、填充和上采样的调节技术。
4.1.5 医学应用
将扩散模型应用于医学图像是一个自然的选择。Score-MRI提出了一个基于扩散的框架来解决磁共振成像(MRI)重建。《Solving inverse problems in medical imaging with score-based generative models》是一个同期进行的工作,但提供了一个更灵活的框架,不需要配对的数据集进行训练。通过在医学图像上训练的扩散模型,这项工作利用了物理测量过程,并专注于采样算法,以创建与观察到的测量和估计的数据先验一致的图像样本。R2D2+将基于扩散的MRI重建和超分辨率结合到同一个网络中,以实现端到端的高质量医学图像生成。
4.2 顺序建模
4.2.1 自然语言处理
受益于扩散模型的非自回归机制,Diffusion-LM利用连续扩散的优势将噪声向量迭代去噪为词向量,并执行可控的文本生成任务。Bit Diffusion提出了一个用于生成离散数据的扩散模型,并被应用于图像标题任务。
4.2.2 时序
为了处理时间序列的估算,CSDI利用基于分数的扩散模型,以观测数据为条件。受掩蔽语言建模的启发,开发了一个自我监督的训练程序,将观察到的数值分离成条件信息和归因目标。SSSD进一步引入了结构化的状态空间模型来捕捉时间序列数据的长期依赖性。CSDE提出了一个概率框架来模拟随机动态,并引入了马尔科夫动态编程和多条件前向-后向损失来生成复杂的时间序列。
4.3 音频处理
WaveGrad和DiffWave是将扩散模型应用于原始波形生成并获得卓越性能的开创性工作。GradTTS和Diff-TTS也实现了扩散模型,但生成的是融化特征而不是原始波形。DiffVC进一步挑战了一次性多对多的语音转换问题,并开发了一个随机微分方程解算器。DiffSinger在浅层扩散机制的基础上,将普通声音的生成扩展到歌唱声音的合成。Diffsound提出了一个以文本为条件的声音生成框架,采用离散扩散模型来代替自回归解码器,以克服单向偏差和累积误差。EdiTTS也是一个基于扩散的音频模型,用于文本到语音的任务。通过对先验空间的粗略扰动,在去噪反转过程中诱发了所需的编辑。Guided-TTS和Guided-TTS2也是早期的一系列文本到语音模型,在声音生成中成功应用了扩散模型。《Zero-shot voice conditioning for denoising diffusion tts models》将语音扩散模型与频谱域调节方法相结合,并在训练期间用未见过的声音进行文本到语音。InferGrad考虑了训练中的推理过程,并在推理步骤较少时改进了基于扩散的文本到语音模型,实现了快速和高质量的采样。SpecGrad带来了信号处理的思路,并根据调节对数梅尔谱图调整了扩散噪声的时变谱包络。Ito-TTS将文本到语音和声码器统一到一个基于线性SDE的框架中。ProDiff提出了一个用于高质量文本到语音的渐进式快速扩散模型。ProDiff没有进行数百次迭代,而是通过预测干净的数据对模型进行参数化,并采用了教师合成的Mel-spectrogram作为目标,以减少数据差异并进行清晰的预测。BinauralGrad是一个基于扩散的两阶段框架,探索了扩散模型在单声道音频合成中的应用。
4.4 AI For Science
4.4.1 分子构象生成
ConfGF是基于扩散的分子构象生成模型的早期工作。在保留旋转和平移等效性的同时,ConfGF通过Langevin动力学与物理学上的梯度场生成样本。然而,ConfGF只模拟了一阶、二阶和三阶邻域之间的局部距离,因此未能捕捉到非边界原子之间的长程相互作用。为了应对这一挑战,DGSM提出根据原子的空间接近度动态构建原子间的分子图结构。GeoDiff发现,在扩散学习过程中,模型被输入了扰动的距离矩阵,这可能违反了数学约束。因此,GeoDiff引入了一个漫游不变的马尔科夫过程,对密度进行约束。EDM进一步扩展了上述方法,纳入了离散原子特征并推导出对数可能性计算所需的方程。扭转扩散对扭转角空间进行操作,根据仅限于最灵活自由度的扩散过程产生分子构象。
4.4.2 材料设计
CDVAE探索了稳定材料生成的周期结构。为了解决稳定材料只存在于具有所有可能的原子周期性排列的低维子空间的挑战,CDVAE设计了一个基于扩散的网络作为解码器,其输出梯度导致能量的局部最小值和更新的原子类型,以捕捉取决于邻居的特定局部结合的偏好。受最近抗体建模成功的启发《Iterative refinement graph neural network for antibody sequence-structure co-design》《Antibody complementarity determining regions (cdrs) design using constrained energy model》《Antibody-antigen docking and design via hierarchical structure refinement》,最近的工作《Antigen-specific antibody design and optimization with diffusion-based generative models》开发了一个基于扩散的生成模型,明确针对特定抗原结构并生成抗体。所提出的方法对抗体序列和结构进行联合采样,并在序列-结构空间中迭代生成候选抗体。
《Protein structure and sequence generation with equivariant denoising diffusion probabilistic models》为蛋白质结构和序列引入了一个基于扩散的生成模型,并学习了对旋转和平移具有等价性的结构信息。ProteinSGM将蛋白质设计表述为一个图像绘画问题,并应用基于条件扩散的生成方法对蛋白质结构进行精确建模。

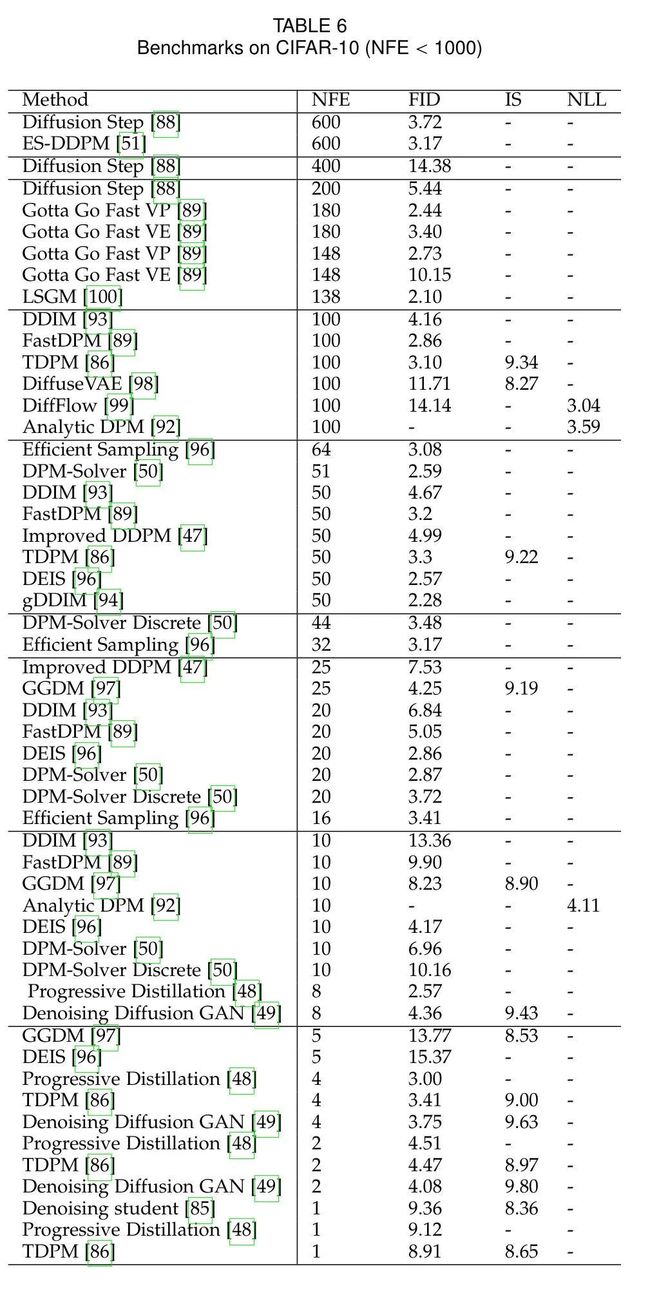
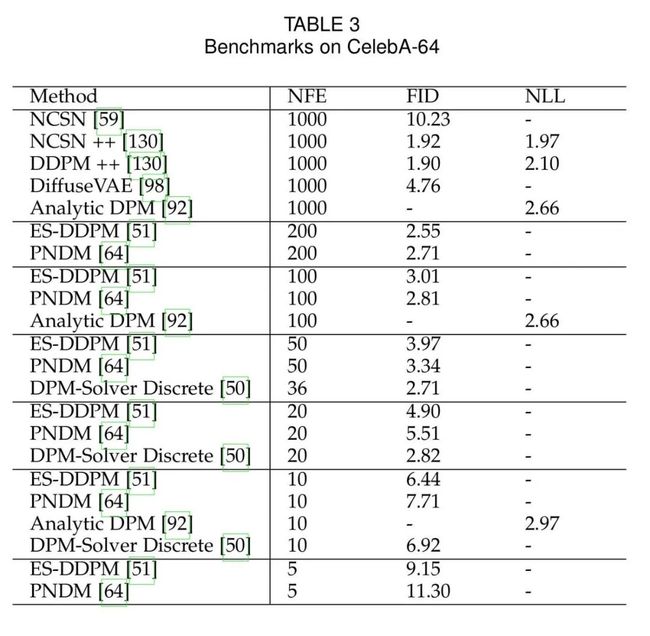
5. Benchmarks
根据各个数据集,本文率先按照NFE降序汇总了每个方法的NLL,IS与FID Score,并且定期更新。
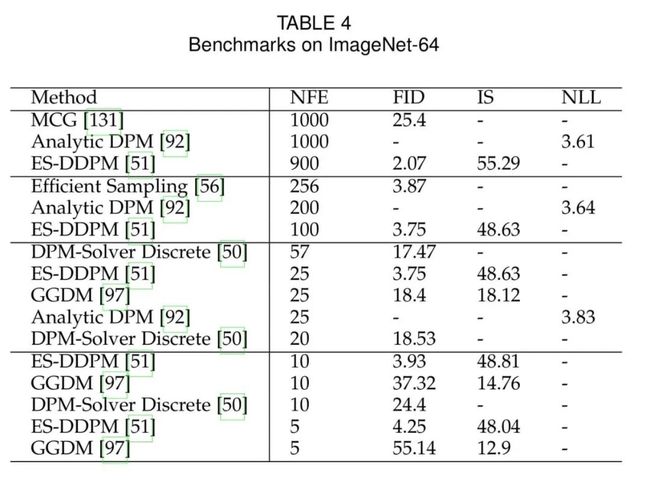
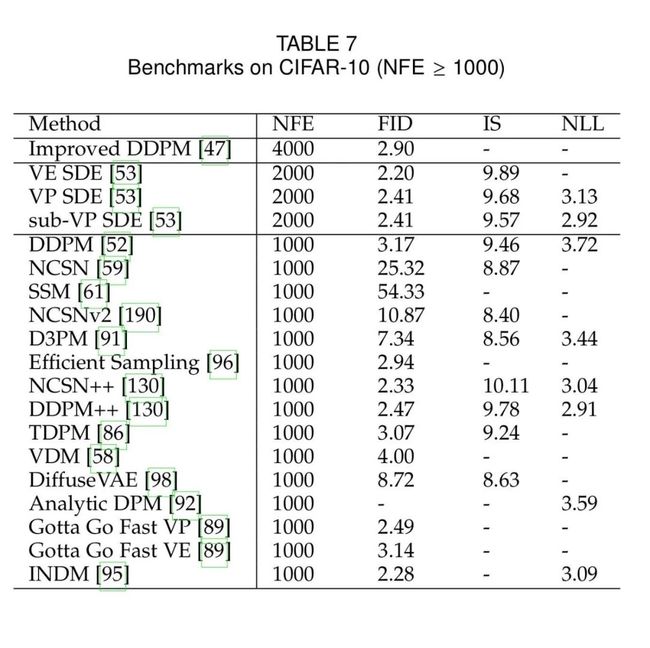
6. 结论与讨论
扩散模型正在成为一个广泛的应用领域中的热门话题。为了利用扩散模型的力量,本文利用对理论、改进算法和应用等各种态度的详细见解,对扩散模型的几个方面进行了全面和最新的回顾。我们希望这个调查能成为读者在扩散模型改进和模型提升方面的指南。
6.1 局限性
目前已经有大量的基于扩散模型的改进技术和应用领域。然而,对快速采样的更多关注导致了训练方案和原始设置的有效性降低。首先,有一个由负对数似然和证据下限之间的差异定义的变异差距。目前大多数工作都集中在优化ELBO,但忽略了对变异缺口的最小化任务,而仍有一个相对巨大的空间需要优化。其次,训练目标和评价指标性能之间不匹配。有时,较低的损失并不能带来较高的质量。因此,要探索统一这两个术语的机制,包括连接指示和度量改进。第三,现有的工作没有过多关注噪声类型和扰动核的类型。相反,高斯扰动以及作为高斯噪声的最终状态是最有可能被使用的,我们不知道高斯噪声在某些特定任务中是否合理。应该引起更多的注意。最后,模型速度和采样质量之间的权衡还不清楚,没有量化。关于定量权衡的优化任务可能为调整模型的效率提供启示。
6.2 未来发展方向
从算法和应用的角度,我们在本小节中提出了一些预期的方向。一方面,应该对不同的数据类型进行更多的尝试,包括离散空间、去量化空间和潜伏空间。同时,需要进行探索不同的最终状态噪声类型和扰动核的实验,如正态分布、伯努利分布、二项分布和泊松分布,以扩大扩散模型的多样性。此外,一个明确的损失优化机制与加速/质量权衡将导致对可控调节和更令人满意的性能产生有希望的影响。另一方面,为了获得更好的发电性能,有很多领域都采用了扩散模型。然而,目前的大多数应用仍然是肤浅的。人们期待更多针对具体问题的扩散模型,特别是针对科学问题。
特别鸣谢:十分感谢王晋东老师 的迁移学习综述为我们的分类图绘制提供的灵感
声明:如有内容引用,烦请引用原文:《A Survey on Generative Diffusion Model》
@article{cao2022survey,
title={A Survey on Generative Diffusion Model},
author={Cao, Hanqun and Tan, Cheng and Gao, Zhangyang and Chen, Guangyong and Heng, Pheng-Ann and Li, Stan Z},
journal={arXiv preprint arXiv:2209.02646},
year={2022}
}点击进入—> CV 微信技术交流群
CVPR 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看