Python基础(适合初学-完整教程-学习时间一周左右-节约您的时间)
 Python基础——核心文章
Python基础——核心文章
前言
本系列博客所有内容都是【实际操作】为主,部分内容一定要解释说明的会伴随少量的理论说明,在【最短时间内】让大家【掌握】真正的【实操技能】才是实打实的【为您创造价值】。
学习环境
系统版本:win10、win11
开发工具:PyCharm Community社区版本(我这里只做数据,不做Web)
知识点
章节号 章节名 章节内容 第一章 Python环境与语法基础 PyCharm Community开发环境。
Python的数据类型、变量、运算符等内容。第二章 Python逻辑控制语句 if判断、while循环、for循环、break、continue 第三章 Python函数 内置函数、随机函数、数学函数、日期函数、自定义函数 第四章 Python集合列表 list(列表)、set(集合)、Dictionary(字典)、tuple(元组) 第五章 Python字符串操作 字符串编码、字符串内置函数 第六章 Python文件IO操作 异常、系统操作、File操作 第七章 Python面向对象 OOP概述、类和实例、封装、继承和多态
目录
前言
学习环境
知识点
第一章 Python环境与语法基础
知识点一、PyCharm Community开发环境
安装步骤
创建【python】项目
修改文字大小
创建【HelloWorld.py】文件
调试模式
知识点二、Python数据类型
2.x与3.x中文编码的区别
Python关键字(也叫保留字·不能用作变量名)
Python变量名
Python注释
基本数据类型
数字类型(Number)
【整数】
【浮点数】
【复数】
布尔类型
字符串类型
单行与都行字符串定义
Python字符串拼接
保留2位小数
Python数据类型匹配
转义符号
取消转义符号
字符串索引
取消print()换行
Python中分号【;】的作用
字符与整数类型数据转换
知识点三、运算符
符号备注:
四则运算
取模(取余)运算
eval函数
Python比较运算符
Python赋值运算符
Python逻辑运算符
Python位运算符
Python成员运算符
多表达式赋值
第二章 Python逻辑控制语句
if判断
if语法:
while循环
for循环
循环计算示例:
数组遍历:
循环嵌套:
break与continue
第三章 Python函数
python函数结构
知识点一、Python内置函数
sum()求和函数
pow()幂运算函数
id()查看内存地址函数
知识点二、random随机函数
模拟暴击:
知识点三、python数学函数:
知识点四、日期函数
时间戳是什么:
当前时间
基本时间格式化:asctime()函数
格式化时间:
知识点五、自定义函数
空函数
返回多个值的自定义函数(超好用,超方便,后期谁用谁知道,虽然是假的。。。)
第四章 Python集合列表
知识点一、list列表
list(列表)
list索引查找
list列表插入
list列表删除末尾
遍历list列表
列表截取
知识点二、set集合
set列表添加
set移除元素
知识点三、Dictionary(字典)
修改字典的值(相当于重写value)
删除字典中的值:
知识点四、tuple(元组)
第五章 Python字符串操作
知识点一、字符串编码
Unicode 字符串
知识点二、字符串内置函数
String.center(宽度)
String.count("查询字符串")
字符串查找String.find("")或String.index("")两种·可以用【re】正则替换,更好用
String.find("")示例:
String.index("")示例:
String.split()分割函数,核心1
String.replace()替换字符串·核心2
第六章 Python文件IO操作
知识点一、异常处理
异常处理语法:
异常解决示例:
知识点二、系统操作·OS操作
绝对路径符号:
相对路径符号:
知识点三、File操作
文件操作异常处理:
第七章 Python面向对象
知识点一、OOP概述(OOP=面向对象)
知识点二、类和实例
知识点三、封装
知识点四、继承和多态
第一章 Python环境与语法基础
知识点一、PyCharm Community开发环境
官方下载地址:【PyCharm:JetBrains为专业开发者提供的Python IDE】

点击下载后,选择【Community】社区版本
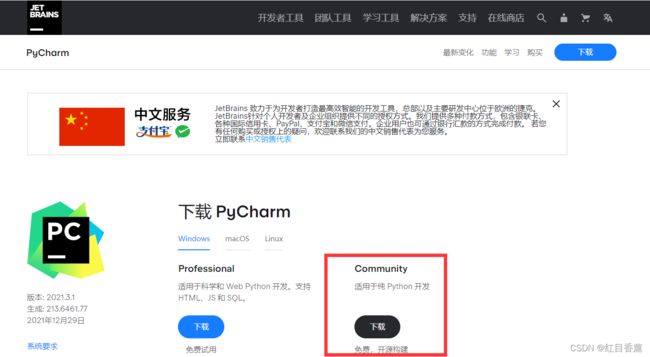
有的时候比较慢,需要等待一会会出现下载栏。
这里还有一个温馨提示,没必要。
下载成功

安装步骤
都是点击【下一步/Next】
为了后续操作方便,需要勾选几个内容

安装过程时间较长

可以稍后重启。安装完毕
创建【python】项目

修改文字大小
点击【File】->【Settings】,搜索【font】修改一下文字显示:


创建【HelloWorld.py】文件
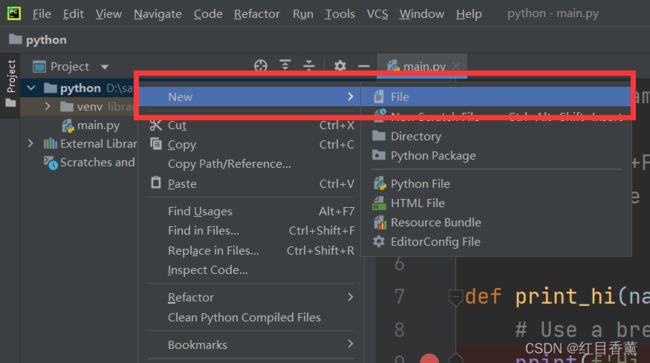

输入以下编码:
print("HelloWorld")
调试模式
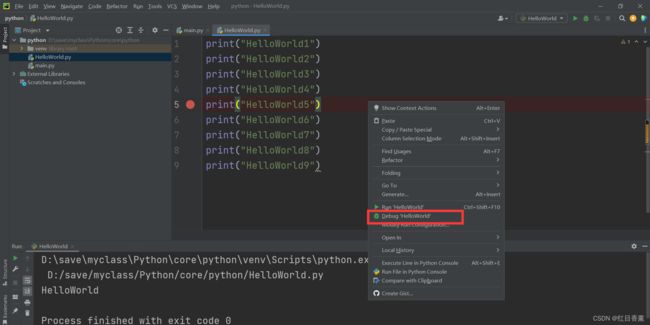
进入调试模式可以看到整个执行过程。

以上我们就拥有了【Python】开发的环境了,后面开始正式课程内容。
知识点二、Python数据类型
2.x与3.x中文编码的区别
如果是2.x的python版本在编码中有中文则需要添加以下声明:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
Python3.x源码默认使用utf-8,可以正常解析中文,无需指定 UTF-8 编码。
Python关键字(也叫保留字·不能用作变量名)
import keyword
# 遍历python关键字列表
print(keyword.kwlist)
其实python的关键字不多,以下是遍历结果:
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']

打包语法
pyinstaller -F -p D:\save\Exe\studys\Python\exe\Lib -i D:\save\myclass\Python\core\pythonProject\python.ico demo1.py –noconsolePython变量名
- 变量名可以包括字母、数字、下划线,但是【数字不能做为开头】。
- 系统关键字不能做变量名使用,我们上面有遍历关键字。
- 除了下划线【 _ 】这个,其它符号不能做为变量名使用。
- Python的变量名是区分大小写的
Python注释
Python注释有三种方法分别是三种符号:
1、# 单个
2、''' ''' 三个,两对作为声明作用域,用于做变量、函数或者类的注释说明
3、""" """三个,两对作为声明作用域,用于做变量、函数或者类的注释说明
代码示例
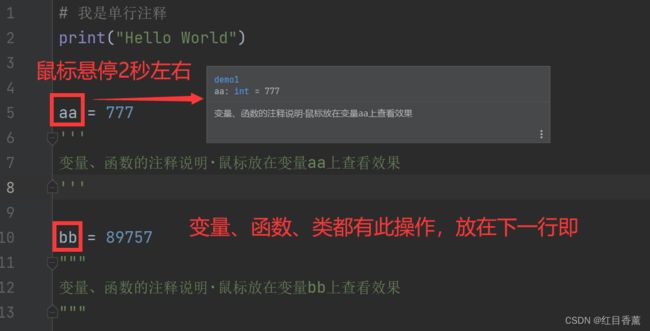
# 我是单行注释
print("Hello World")
aa = 777
'''
变量、函数或者类的注释说明·鼠标放在变量aa上查看效果
'''
bb = 89757
"""
变量、函数或者类的注释说明·鼠标放在变量aa上查看效果
"""
注释效果:
基本数据类型
在Python3中有六种基本数据类型,分别是:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
在这里我们先讲解前两种,在后面的章节中我们在对另外四种进行深入讲解。下面我们逐一去了解Number数字类型与String字符串类型。
数字类型(Number)
Python里有【整数】、【浮点数】和【复数】四种数据类型,咱们逐一说明。
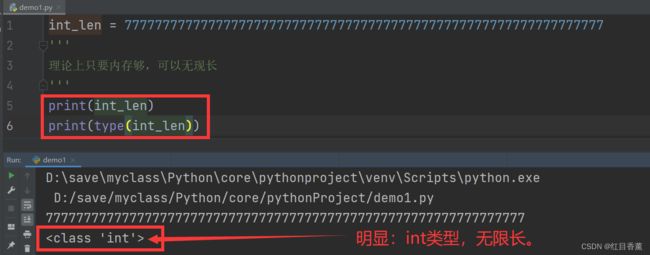
【整数】
int在Python3中是没有限制大小的,只要内存够,理论上无限大小。
int_len = 777777777777777777777777777777777777777777777777777777777777777
'''
理论上只要内存够,可以无现长
'''
print(int_len)
print(type(int_len))
【浮点数】
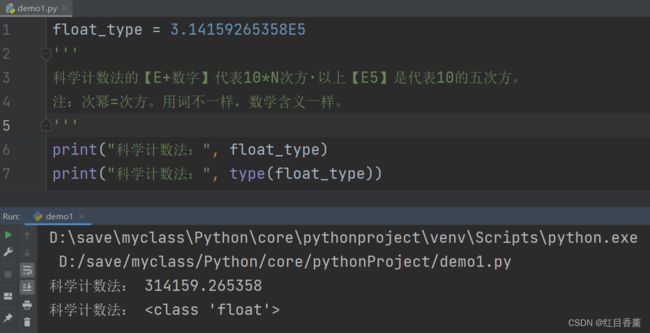
也就是小数,例如:【3.14】就是一个浮点数。也肯能是科学计数法。
浮点数基础使用:
float_type = 3.14159265358E5
'''
科学计数法的【E+数字】代表10*N次方·以上【E5】是代表10的五次方。
注:次幂=次方。用词不一样,数学含义一样。
'''
print("科学计数法:", float_type)
print("科学计数法:", type(float_type))
以下是浮点数的浮点数【15/16】尾数处理的情况1:
float_type_15 = 3.000000000000001
float_type_16 = 3.0000000000000001
'''
小数点后15位,当有16位的时候会出现自动舍去
'''
print("15位:", float_type_15)
print("15位:", type(float_type_15))
print("16位:", float_type_16)
print("16位:", type(float_type_16))

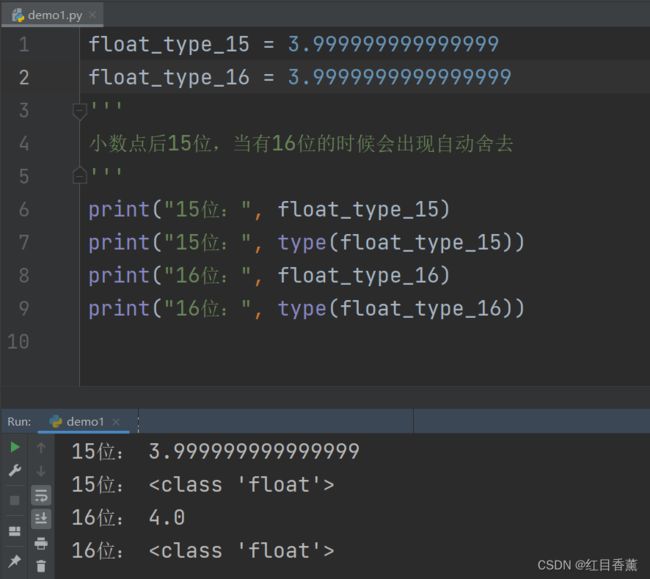
以下是浮点数的浮点数【15/16】尾数处理的情况2:
float_type_15 = 3.999999999999999
float_type_16 = 3.9999999999999999
'''
小数点后15位,当有16位的时候会出现自动舍去
'''
print("15位:", float_type_15)
print("15位:", type(float_type_15))
print("16位:", float_type_16)
print("16位:", type(float_type_16))
【复数】
复数由实部与虚部构成,Python中使用【j】/【J】作为后缀。
complex_num = 2j
'''
复数由实部与虚部构成,Python中使用【j】/【J】作为后缀
'''
print("复数:", complex_num)
print("复数:", type(complex_num))

根据i的平方等于-1,故而结果应该是-1j
i = 1j
complex_num = i ** 2
'''
根据i的平方等于-1,故而结果应该是-1j
'''
print("i²=-1:", complex_num)
print("复数:", type(complex_num))

布尔类型
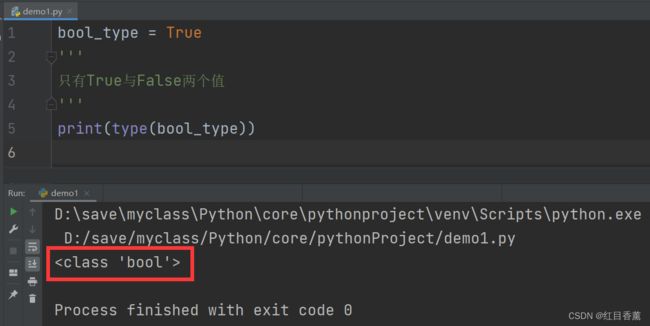
True与False,布尔类型只有对错两个值。
bool_type = True
'''
只有True与False两个值
'''
print(type(bool_type))
字符串类型
- Python 中单引号【'】和双引号【"】使用完全相同
- 使用三引号【'''】或【"""】可以指定一个多行字符串
- 转义【\】
单行与都行字符串定义
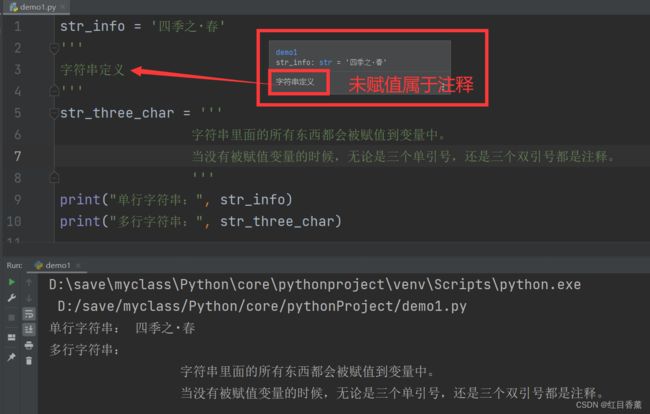
当没有被赋值变量的时候,无论是三个单引号,还是三个双引号都是注释。
str_info = '四季之·春'
'''
字符串定义
'''
str_three_char = '''
字符串里面的所有东西都会被赋值到变量中。
当没有被赋值变量的时候,无论是三个单引号,还是三个双引号都是注释。
'''
print("单行字符串:", str_info)
print("多行字符串:", str_three_char)
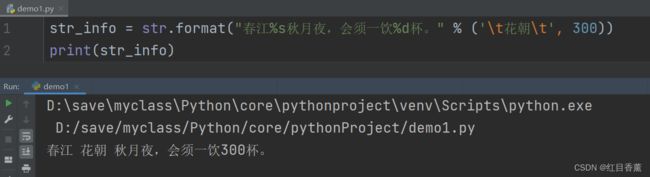
Python字符串拼接
符号 描述 %c 格式化字符及其ASCII码 %s 格式化字符串 %d 格式化整数 %f 格式化浮点数字,可指定小数点后的精度
我们主要也就使用%s、%d、%f,其实还有一些符号,但是用的非常少。接下来我们拼接一个字符串:
str_info = str.format("春江%s秋月夜,会须一饮%d杯。" % ('\t花朝\t', 300))
print(str_info)
保留2位小数
王姑娘的成绩从去年的72分提升到了今年的85分,请计算王姑娘成绩提升的百分点,并用字符串格式化显示出'xx.x%',只保留小数点后2位:
s1 = 72
s2 = 85
r = (1 - (s1 / s2))
print(f"王姑娘是成绩提升的百分比是:%.2f " % r)

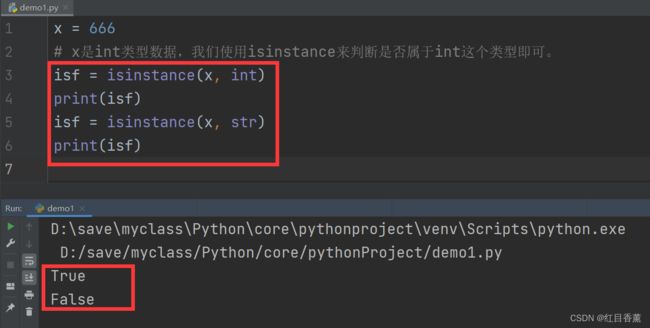
Python数据类型匹配
在后面面向对象的操作过程中有的时候需要根据传递的参数对象进行判断是否进行下一步操作,我们在这里用到了【isinstance】函数,这个函数可以判断变量是否属于某类型数据。
x = 666
# x是int类型数据,我们使用isinstance来判断是否属于int这个类型即可。
isf = isinstance(x, int)
print(isf)
isf = isinstance(x, str)
print(isf)
转义符号
str_char = '字符串\n中\r可以穿插\t转义字符,\b'
'''
转义符号是对应ascii码表的
\n 全拼newline的首字母表示换行
\t -->tab的首字母表示制表符
\r -->return的首字母表示返回
\b -->backspace的首字母表示退一个格
'字符串\n【换行】中\r【回车】可以穿插\t【制表符,大空格】转义字符,\b【退格,不显示,】'
'''
print(str_char)
可以看到实际效果:

取消转义符号
str_char = r'字符串\n中\r可以穿插\t转义字符,\b'
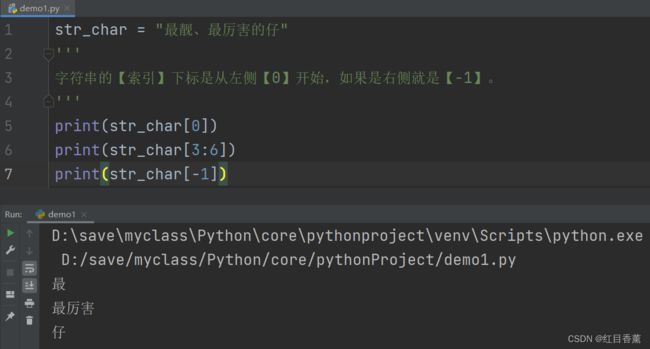
字符串索引
字符串的【索引】下标是从左侧【0】开始,如果是右侧就是【-1】。字符串的知识点很多,我们会在后面的章节详细述说。
str_char = "最靓、最厉害的仔"
'''
字符串的【索引】下标是从左侧【0】开始,如果是右侧就是【-1】。
'''
print(str_char[0])
print(str_char[3:6])
print(str_char[-1])
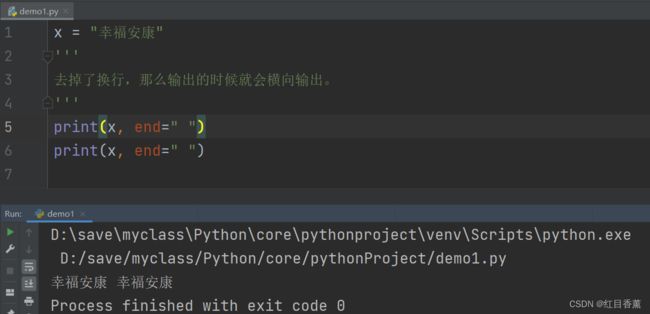
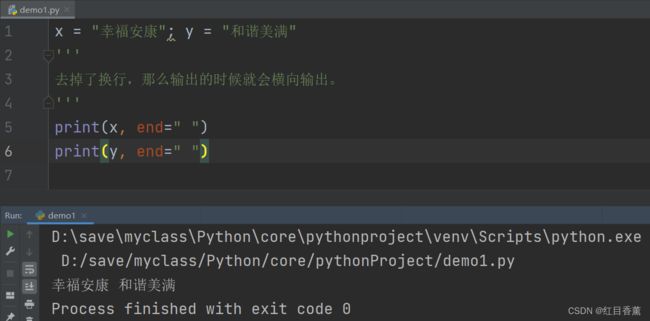
取消print()换行
x = "幸福安康"
'''
去掉了换行,那么输出的时候就会横向输出。
'''
print(x, end=" ")
print(x, end=" ")
Python中分号【;】的作用
Python中的【;】用于区分前后语句,如果每行一句则不需要,如果一行内写多条语句,那么就需要使用【;】作为分隔符来明确对应的语句含义了。但是不建议这么使用,使语句理解起来麻烦的多。
字符与整数类型数据转换
# 数字类型转换字符类型·可以理解成ascii码转字符
print(chr(22909))
# 字符转ascii码
print(ord('好'))
知识点三、运算符
这里为了让大家先入门,我就不对一些有难度的符号进行讲解了,再后面的文章有会有精讲,这里先让大家入门。
符号备注:
运算符支持的符号有:+、-、*、/、%(取模|求余)、//(整除)、**(次幂),与我们学习中常用的符号类型有点区别,我们常用的【x】乘号、【×】乘号、【÷】除号在程序运算中是无法使用的,这点我们要切忌。
四则运算
【//】相当于java中的整数除法,在明确自身是int的类型的时候不会进行浮点数处理。
x = 7
y = 5
print("加法计算:", x + y)
print("减法计算:", x - y)
print("乘法计算:", x * y)
print("除法计算:", x / y, "整数运算,无浮点数")
print("整除计算:", x // y, "会出现浮点数计算")
print("取模计算:", x % y)
print("幂运算:", x ** y, "次幂运算、x的y次幂(次方)")

取模(取余)运算
num = 12345
print("万位:", num // 10000)
print("千位:", num // 1000 % 10)
print("百位:", num // 100 % 10)
print("十位:", num // 10 % 10)
print("个位:", num % 10)
可以在结果中看到是没有浮点数运算的,说明是正确的操作,但是如果使用的是【/】就会出现浮点数的问题。

eval函数
# 计算字符串运算结果
print(eval("5+1+6*5+2+6/2+25-2"))

这种运算非常方便,我们使用这个函数就能写出一个小应用,例如输入字符串的运算直接出结果:
# 输入运算字符串
calc = str(input("请输入运算公式:"))
calc = calc.replace("×", "*").replace("÷", "/")
# (873×477-198)÷(476×874+661169)
# 需要将以上的特殊符号【×】与【÷】替换成【*】与【/】
# (873*477-198)/(476*874+661169)
# eval计算
print("eval函数计算结果:", eval(calc))
# 直接计算
print("直接计算", (873*477-198)/(476*874+661169))
我做了对照实验,说明eval函数计算的没有任何问题,所以我们接下来导出我们的程序。
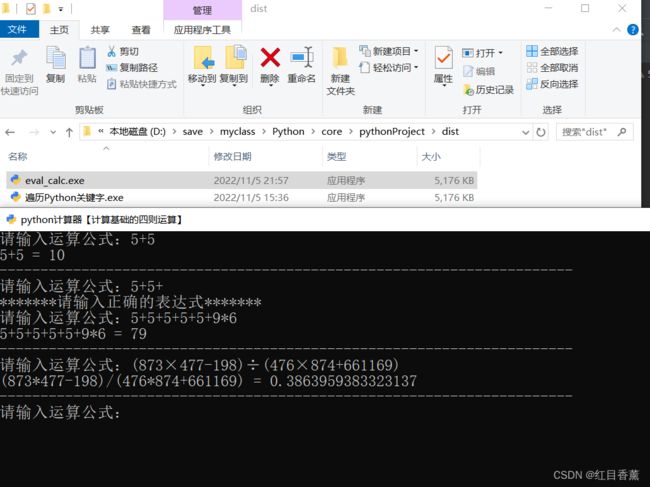
程序源码:
import re
import os
while True:
try:
os.system("title python计算器【计算基础的四则运算】")
# 输入运算字符串
calc = str(input("请输入运算公式:"))
info = r"[+]|[-]|[*]|[/]|[×]|[÷]|[x]|[X]"
te = re.search(info, calc)
if te == None:
print("请输入正确的运算公式")
os.system("cls")
calc = calc.replace("×", "*").replace("x", "*").replace("X", "*").replace("÷", "/")
# eval计算:(873×477-198)÷(476×874+661169)
print(calc, "=", eval(calc))
print("-----------------------------------" * 2)
except :
print("*******请输入正确的表达式*******")
程序已经打包好,回头我会统一发对照组应用列表。
这里正则如果自己编写可能会出现【nothing to repeat at position 0(解决方案)_红目香薰的博客-CSDN博客】这个异常,我在文章有具体的说明,可以参考并解决。
Python比较运算符
比较运算符就是我们常说的:大于号、小于号啥的,符号有:
>、>=、<、<=、==、!=六个符号。
示例:

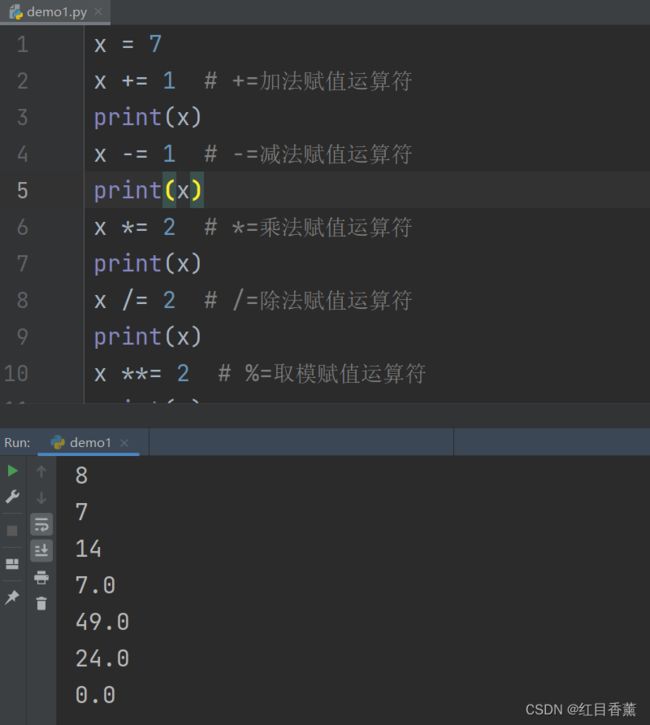
Python赋值运算符
x = 7
x += 1 # +=加法赋值运算符
print(x)
x -= 1 # -=减法赋值运算符
print(x)
x *= 2 # *=乘法赋值运算符
print(x)
x /= 2 # /=除法赋值运算符
print(x)
x **= 2 # %=取模赋值运算符
print(x)
x //= 2 # **=幂赋值运算符
print(x)
x %= 2 # //=取整除赋值运算符
print(x)
由于我用的是一个变量【x】,我们需要一层一层的分析
Python逻辑运算符
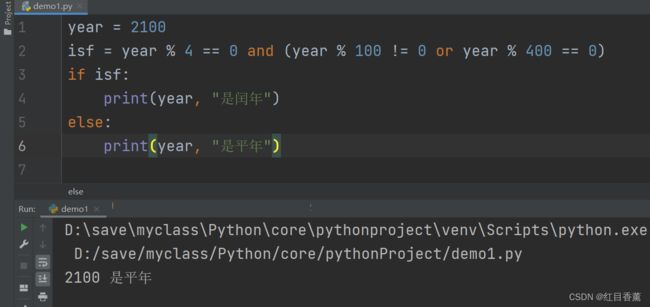
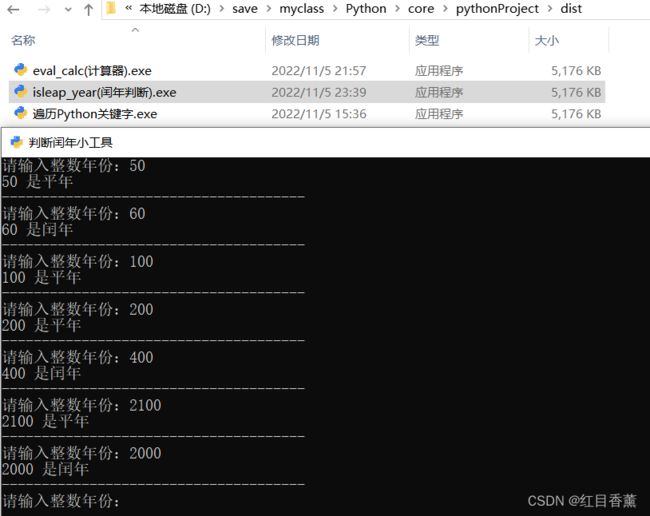
Python有三个逻辑运算符,这里用的是英文【and】与、【or】或、【not】非,优先级顺序为 NOT、AND、OR,我们用的非常多,多用用也就熟悉了。我们有一个经典练习题【判断闰年】,接下来我们看看具体的编写方法,同时我也准备了示例exe:
基础判断闰年
year = 2100
isf = year % 4 == 0 and (year % 100 != 0 or year % 400 == 0)
if isf:
print(year, "是闰年")
else:
print(year, "是平年")
我们精致化处理一下:
import os
os.system("title 判断闰年小工具")
while True:
try:
year = int(input("请输入整数年份:"))
isf = year % 4 == 0 and (year % 100 != 0 or year % 400 == 0)
if isf:
print(year, "是闰年")
else:
print(year, "是平年")
except:
print("请正确输入年份,例如:2100")
print("-------------------" * 2)
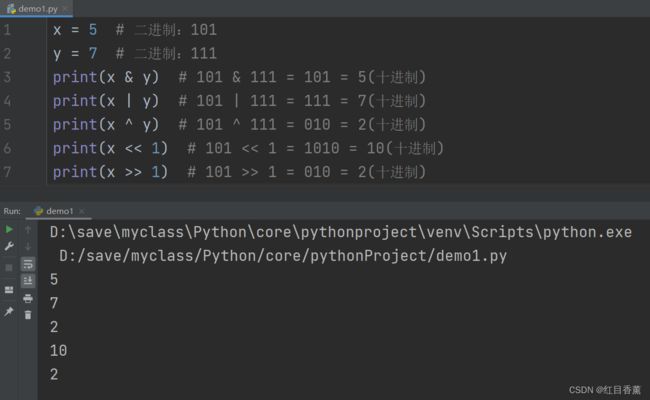
Python位运算符
这个稍微难度大一些,基础的有【&与、|或、^异或、<<左位移、>>右位移】
x = 5 # 二进制:101
y = 7 # 二进制:111
print(x & y) # 101 & 111 = 101 = 5(十进制)
print(x | y) # 101 | 111 = 111 = 7(十进制)
print(x ^ y) # 101 ^ 111 = 010 = 2(十进制)
print(x << 1) # 101 << 1 = 1010 = 10(十进制)
print(x >> 1) # 101 >> 1 = 010 = 2(十进制)下面的对应的结果,这个理解起来比较难,后面我会有对应的文章进行详细说明。
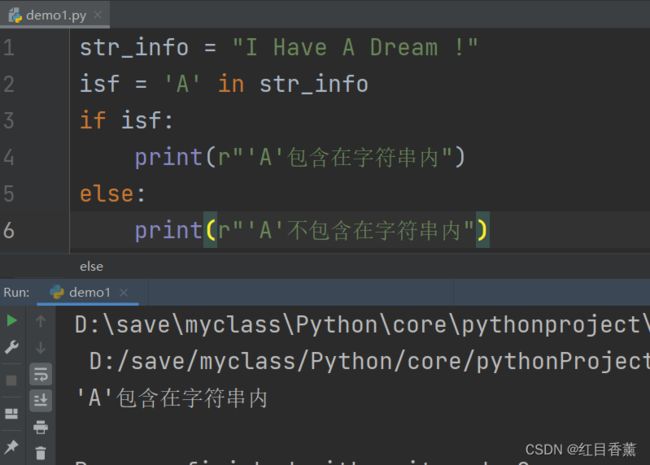
Python成员运算符
有两个【in包含】、【not in不包含】,我们通过一个字符串做一个示例:
str_info = "I Have A Dream !"
isf = 'A' in str_info
if isf:
print(r"'A'包含在字符串内")
else:
print(r"'A'不包含在字符串内")
多表达式赋值
x = 7
y = 5
x, y = 666, x + y
'''
x, y = 666, x+y 的计算方式为先计算右边表达式,然后同时赋值给左边
'''
print(x)
print(y)
在下图中可以清晰的看出等号左右的赋值内容。

第一章就到这里,在第一章您已经可以基本掌握Python的基础语法了,我会在第二章进行逻辑控制语句的讲解。
第二章 Python逻辑控制语句
if判断
其实在上面的实例中我有几次的展示了这种用法,会执行一次【True】的语句,后面的自动关闭。按照中文的翻译说法就是:
如果 对:
执行某语句后结束。
其它如果 对:
执行某语句后结束。
其它如果 对:
执行某语句后结束。
其它:
执行某语句,直接结束。
if语法:
if True:
print("正确执行后直接结束")
elif True:
print("正确执行后直接结束")
elif True:
print("正确执行后直接结束")
else :
print("直接后结束")
这就像我们在大学的数学书上列的那些图一样,其实没什么复杂度,无论是单分支,双分支,多分支,就是与平时说话自己进行大脑判断一样。反正只有一个结果,虽然中间判断表达式比较多,但是【结果是唯一】的。
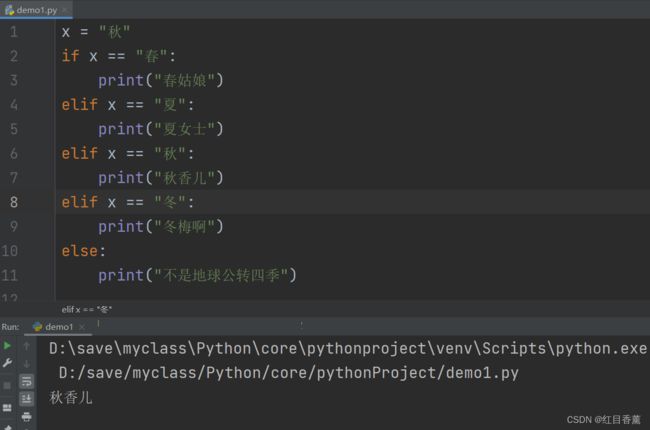
代码示例:
x = "秋"
if x == "春":
print("春姑娘")
elif x == "夏":
print("夏女士")
elif x == "秋":
print("秋香儿")
elif x == "冬":
print("冬梅啊")
else:
print("不是地球公转四季")
在Python中是没有switch语句的,如果有,那就是通过第三方的方式插入进来的,本身不属于Python自带啊,而且在Python中if判断的效率还是非常高的,没有上亿次运算if和switch没啥区别,所以不用强行的搞Python的switch,反而不美丽了。
while循环
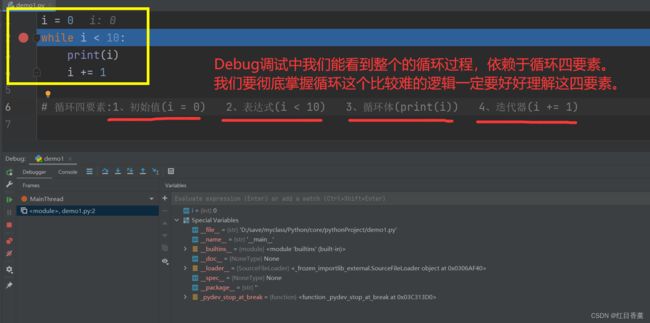
循环四要素:1、初始值(i = 0) 2、表达式(i < 10) 3、循环体(print(i)) 4、迭代器(i += 1)
循环四要素的意义很重大,后面有很多算法都是巧妙的利用循环四要素进行变化式的处理,千万别太自信自己能举一反三,没有一定量的练习,可能别人的写法根本看不懂。多练,才是王道。
i = 0
while i < 10:
print(i)
i += 1
# 循环四要素:1、初始值(i = 0) 2、表达式(i < 10) 3、循环体(print(i)) 4、迭代器(i += 1)
插入GIF太大,我们用图片和视频了解一下具体的执行步骤吧。
while循环的Debug完整过程
视频演示了动态的过程。
for循环
for循环也是依赖于循环四要素进行每一步操作。但是在Python中将这些步骤封装了一下,咱们在外部可以看到的语法中并未体现出迭代器,是通过【寻址器PC】自动查找下一个。
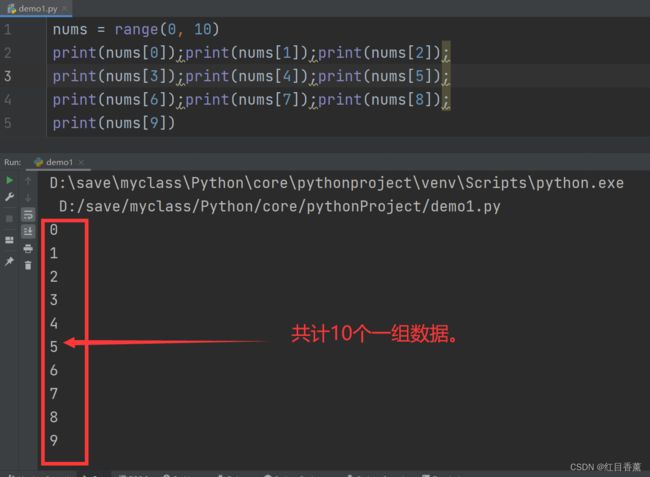
讲循环遍历前我们需要了解一个函数【range(start int,end int)】函数,我们来看看它是做什么的。
nums = range(0, 10)
print(nums[0]);print(nums[1]);print(nums[2]);
print(nums[3]);print(nums[4]);print(nums[5]);
print(nums[6]);print(nums[7]);print(nums[8]);
print(nums[9])
可以看到,我们在读取这个数据的时候好麻烦,我才写了0~10,共计10个数字。
我们通过for循环来遍历就很方便了,看看我们循环的使用方法:
for item in range(0, 10):
print(item)循环四要素:1、2:初始值与表达式range(0,10) 3、循环体(print(i)) 4、寻址器(PC)
依然依赖于循环四要素,但是有一部分不需要咱们来理解,系统会自动查找下一个,直到结束。
for循环的Debug过程:
for循环Debug全过程
循环计算示例:
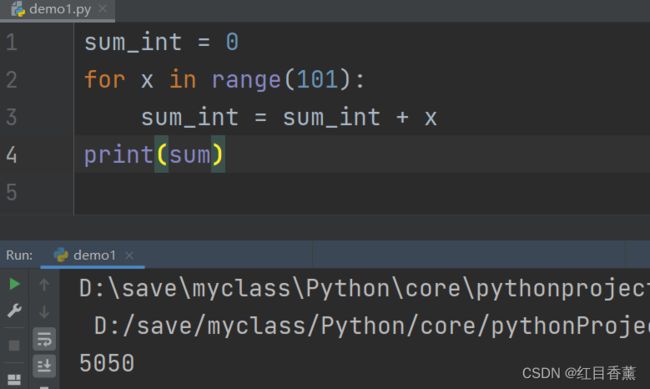
这个示例是计算从1累计到100的总值。我们在不使用公式推导的情况下就由以下的方式实现:
sum_int = 0
for x in range(101):
sum_int = sum_int + x
print(sum)
计算结果是:5050,说明计算正确。
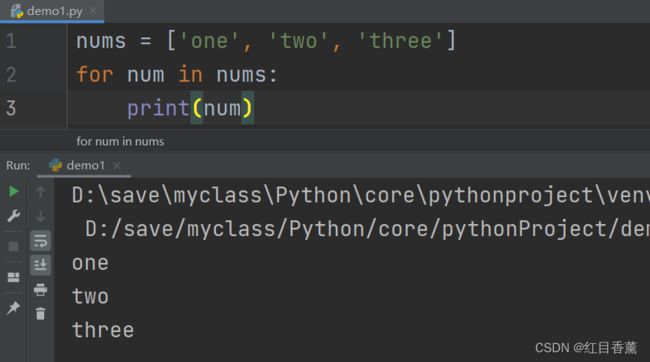
数组遍历:
nums = ['one', 'two', 'three']
for num in nums:
print(num)
循环嵌套:
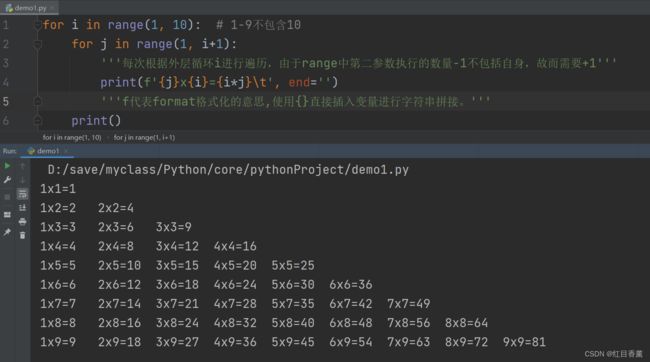
for i in range(1, 10): # 1-9不包含10
for j in range(1, i+1):
'''每次根据外层循环i进行遍历,由于range中第二参数执行的数量-1不包括自身,故而需要+1'''
print(f'{j}x{i}={i*j}\t', end='')
'''f代表format格式化的意思,使用{}直接插入变量进行字符串拼接。'''
print()
九九乘法表是一个非常经典的练习题,还有斐波那契额数列,水仙花数,我们在这里值对循环结构以及基本使用进行掌握,后面我会有算法课程,如果对算法感兴趣可以看看我2022蓝桥的专栏文章,
break与continue
break是结束循环指令,continue是跳过本次循环进入下次循环的指令。为了更加直接的展示我们的操作,我们使用while循环来测试一下:
n = 1
while n <= 100: # 理论上会循环100次
if n > 10: # 当n = 11时,条件满足,执行break语句
break # break语句会结束当前循环,输出到11的时候由于大雨10就会执行这里,关闭循环
print(n, end=",")
n = n + 1
print('结束')

同理, continue也是一样的,但是它只是跳过当前的循环,继续后面的循环,例如我们跳过1-100中的5-95的所有数字:
n = 0
while n < 100: # 理论上会循环100次
n = n + 1
if n >= 5 and n <= 95: # 满足大于等于5小于等于95的时候执行continue语句
continue
else:
print(n, end=",") # 由于仅仅有
print('结束')
执行的结果中可以看到,跳过了我们单独判断的这些的数字的范围。

逻辑语句其实不太难理解,这里相对应的理论少一些,我就直接使用了几个案例来表示,这样看着更直接。
第三章 Python函数
python函数结构
从下图可以看出来,函数声明需要使用【def】关键字,返回数据需要使用【return】,其余的都是自定义编写的函数名以及编码过程,python的函数无需单独设置返回值,会直接返回return返回的数据类型。
def 函数名(参数列表):
函数体
return 值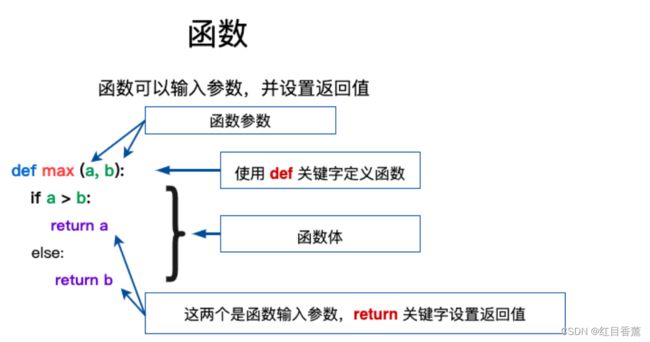
知识点一、Python内置函数
以下是python3.x的内置函数表,看着其实挺多的,不过咱们常用的也就10个左右。
| 内置函数 | ||||
|---|---|---|---|---|
| abs() | delattr() | hash() | memoryview() | set() |
| all() | dict() | help() | min() | setattr() |
| any() | dir() | hex() | next() | slicea() |
| ascii() | divmod() | id() | object() | sorted() |
| bin() | enumerate() | input() | oct() | staticmethod() |
| bool() | eval() | int() | open() | str() |
| breakpoint() | exec() | isinstance() | ord() | sum() |
| bytearray() | filter() | issubclass() | pow() | super() |
| bytes() | float() | iter() | print() | tuple() |
| callable() | format() | len() | property() | type() |
| chr() | frozenset() | list() | range() | vars() |
| classmethod() | getattr() | locals() | repr() | zip() |
| compile() | globals() | map() | reversed() | __import__() |
| complex() | hasattr() | max() | round() | |
我标记了几个比较常用的内容函数,我们拿几个来测试一下:
sum()求和函数
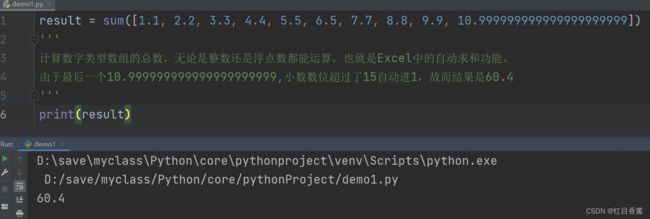
result = sum([1.1, 2.2, 3.3, 4.4, 5.5, 6.5, 7.7, 8.8, 9.9, 10.999999999999999999999])
'''
计算数字类型数组的总数,无论是整数还是浮点数都能运算,也就是Excel中的自动求和功能。
由于最后一个10.999999999999999999999,小数数位超过了15自动进1,故而结果是60.4
'''
print(result)
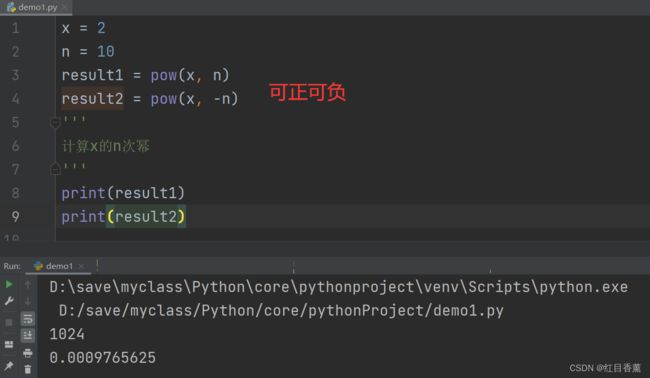
pow()幂运算函数
id()查看内存地址函数
x = 2
print(id(x))
x = 3
print(id(x))
'''由于x属于int类型,那么int类型也就是常量的地址是不变的,每个数字对应一个地址,所以值变了,内存地址就变了'''
y = [1, 2, 3, 4, 5]
print(id(y))
y[2] = 666
print(id(y))
'''数组有些不同,是开辟了一个堆空间,堆空间确立之后就不会变,除非新new出来一个地址。'''

知识点二、random随机函数
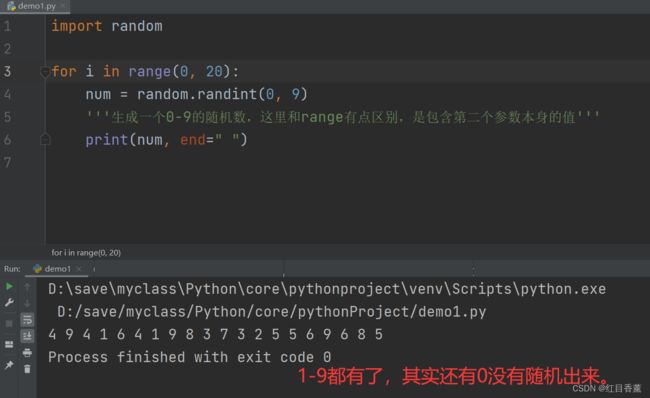
import random
for i in range(0, 20):
num = random.randint(0, 9)
'''生成一个0-9的随机数,这里和range有点区别,是包含第二个参数本身的值'''
print(num, end=" ")
多随机几次0-9就都看到了,游戏里面的概率就是利用这个随机数写的。
模拟暴击:
import random
for i in range(0, 100):
num = random.randint(0, 99)
'''生成0-99一百以内的随机数其中的1个值,我们循环100次,那么任意取1个数:也就是1/100=1%的概率'''
if num == 22 or num == 66: # 我写了2个数,那么概率就是2%,偶尔也能出现3~4次,也可能0次
print("暴击", end=" ")
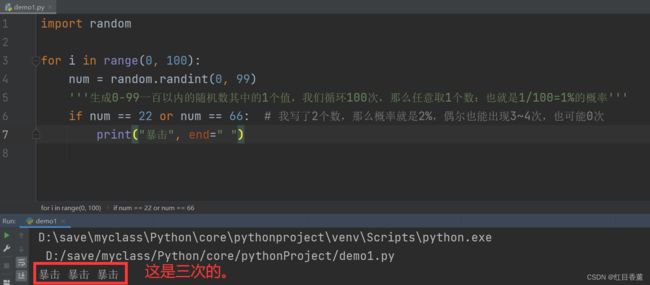
这只是随机的基础运用,后面会有更加深入的文章针对随机函数进行详细的介绍与案例实践。
知识点三、python数学函数:
数学函数在Python基础中用不到,而且使用方法也比较简单,我们会在后面有一个章节专门针对数学函数的三角函数做一篇博客,三角函数其实还是非常实用的一种计算方法。
| 函数名 | 功能 |
| abs() | 绝对值,例如:abs(-10)=10 |
| math.ceil() | 向上取整,例如:math.ceil(3.14)=4,不是四舍五入 |
| math.floor() | 向下取整,例如:math.ceil(3.14)=3,不是四舍五入 |
| cmp() | 判断函数,例如x |
| math.log10(10) | log计算函数 |
| math.e | 神一样美的数字,自然常数e |
| math.pi | 十进制永远无法计算出结果的π |
| pow() | 幂运算,例如:pow(2,10)=1024 |
| round() | 四舍五入函数 |
| math.sqrt() | 开方函数或者叫做开根号,返回浮点数 |
| cmath.sqrt() | 开方函数或者叫做开根号,返回复数 |
| math.isqrt() | 开方函数或者叫做开根号,返回整数 |
| acos(x) | 返回x的反余弦弧度值。 |
| asin(x) | 返回x的反正弦弧度值。 |
| atan(x) | 返回x的反正切弧度值。 |
| atan2(y, x) | 返回给定的 X 及 Y 坐标值的反正切值。 |
| cos(x) | 返回x的弧度的余弦值。 |
| hypot(x, y) | 返回欧几里德范数 sqrt(x*x + y*y)。 |
| sin(x) | 返回的x弧度的正弦值。 |
| tan(x) | 返回x弧度的正切值。 |
| degrees(x) | 将弧度转换为角度,如degrees(math.pi/2) , 返回90.0 |
| radians(x) | 将角度转换为弧度 |
知识点四、日期函数
日期函数我们用的还是很多的,特别是进行各种时间的记录,时间的推导,时间范围的判断等操作中我们都会使用,一般我会单独的创造一个自己习惯的时间工具类,调用自己二次编写的一些函数,更为方便,我们今天先介绍一下系统的日期函数,后面我们会根据系统的日期函数进行更多的优化与自定义函数的编写。
时间戳是什么:
一个能表示一份数据在某个特定时间之前已经存在的、完整的、可验证的数据,通常是一个字符序列,唯一地标识某一刻的时间。
时间戳获取:
import time
print("系统当前时间戳:", time.time())

当前时间
import time
print("系统当前时间戳:", time.time())
localtime = time.localtime(time.time())
print("本地时间为 :", localtime)
可以看到,输出的本地时间格式是一个【struct】结构体,我们大学都学过结构体,可以在这个时间的结构体里面获取对应的时间信息:
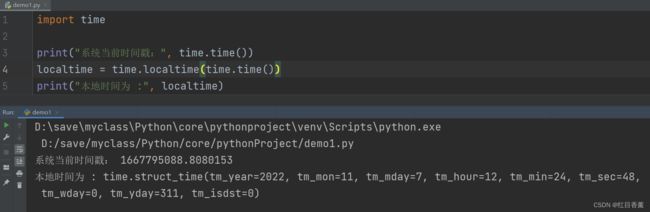
我们进行时间拼接,虽然没有这么用的,但是有的时候需要单个的时间信息,我们就可以直接获取了。
import time
print("系统当前时间戳:", time.time())
localtime = time.localtime(time.time())
print(localtime.tm_year, "年", localtime.tm_mon, "月", localtime.tm_mday, "日")
print(localtime.tm_hour, "时", localtime.tm_min, "分", localtime.tm_sec, "秒")
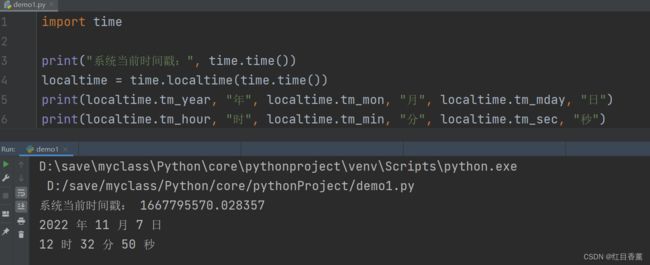
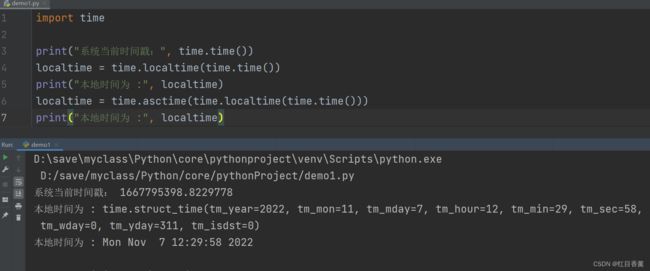
基本时间格式化:asctime()函数
import time
print("系统当前时间戳:", time.time())
localtime = time.localtime(time.time())
print("本地时间为 :", localtime)
localtime = time.asctime(time.localtime(time.time()))
print("本地时间为 :", localtime)
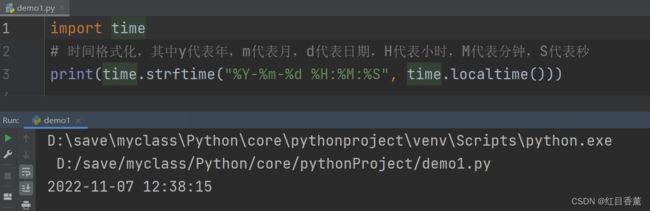
格式化时间:
import time
# 时间格式化,其中y代表年,m代表月,d代表日期,H代表小时,M代表分钟,S代表秒
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
时间的格式化内容还是很多的,但是常用的就那么几个,多用几次就背下来了,难度不大,不用特意去记忆。
知识点五、自定义函数
在Python中,定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回。
我们以自定义一个求绝对值的my_abs函数为例:
def my_abs(x):
if x >= 0:
return x
else:
return -x
print(my_abs(-666))空函数
pass语句什么都不做,那有什么用?实际上pass可以用来作为占位符,比如现在还没想好怎么写函数的代码,就可以先放一个pass,让代码能运行起来。缺少了pass代码运行就会有语法错误。
def nop():
pass返回多个值的自定义函数(超好用,超方便,后期谁用谁知道,虽然是假的。。。)
import math
def move(x, y, step, angle=0):
'''比如在游戏中经常需要从一个点移动到另一个点,给出坐标、位移和角度,就可以计算出新的坐标'''
nx = x + step * math.cos(angle)
ny = y - step * math.sin(angle)
return nx, ny
x, y = move(100, 150, 60, math.pi / 6)
print("x轴:", x)
print("y轴", y)
直接计算了两个坐标,多潇洒。。

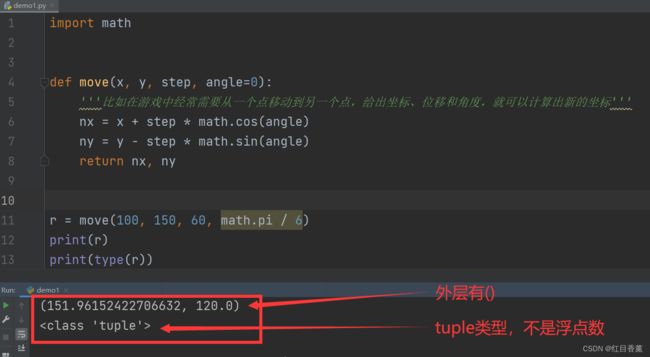
真正返回的数据格式
import math
def move(x, y, step, angle=0):
'''比如在游戏中经常需要从一个点移动到另一个点,给出坐标、位移和角度,就可以计算出新的坐标'''
nx = x + step * math.cos(angle)
ny = y - step * math.sin(angle)
return nx, ny
r = move(100, 150, 60, math.pi / 6)
print(r)
print(type(r))
第四章 Python集合列表
知识点一、list列表
list(列表)
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。 比如,列出班里所有同学的名字,就可以用一个list表示:
list = ['王语嫣', '小龙女', '赵灵儿']
print(list)变量list就是一个list。用len()函数可以获得list元素的个数,输出为3:
list = ['王语嫣', '小龙女', '赵灵儿']
print(len(list))list索引查找
用索引来访问list中每一个位置的元素,记得索引是从0开始的,超过数据会报异常:
list = ['王语嫣', '小龙女', '赵灵儿']
print(list[0])
print(list[1])
print(list[2])
print(list[3])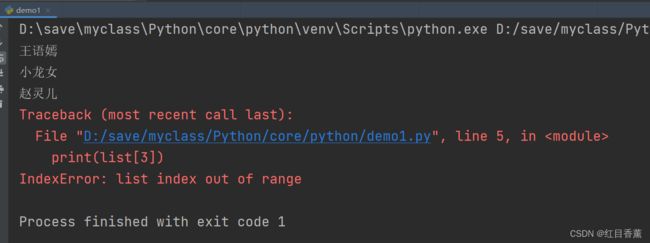
当索引超出了范围时,Python会报一个IndexError错误,所以,要确保索引不要越界,记得最后一个元素的索引是len(list) - 1。
如果要取最后一个元素,除了计算索引位置外,还可以用-1做索引,直接获取最后一个元素:
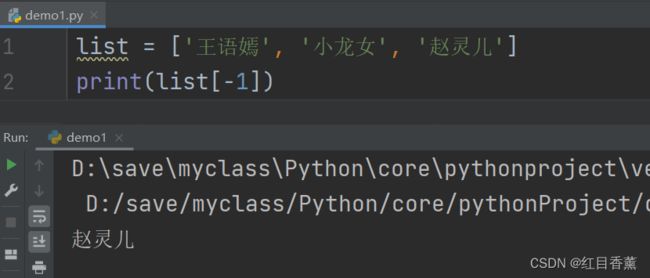
list是一个可变的有序表,所以,可以往list中追加元素到末尾:
list = ['王语嫣', '小龙女', '赵灵儿']
list.append("刘亦菲")
print(list)
print(list[-1])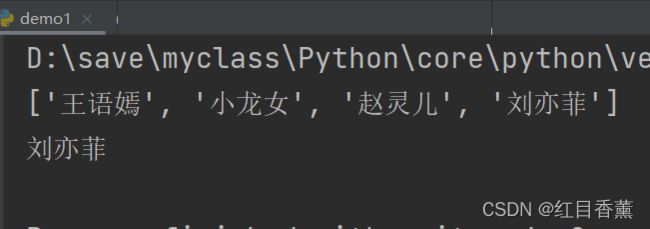
list列表插入
也可以把元素插入到指定的位置,比如索引号为1的位置:
list = ['王语嫣', '小龙女', '赵灵儿']
list.insert(1,"刘亦菲")
print(list)
print(list[-1])
list列表删除末尾
要删除list末尾的元素,用pop()方法:
list = ['王语嫣', '小龙女', '赵灵儿',"刘亦菲"]
print(list)
print(list.pop())
print(list)
要删除指定位置的元素,用pop(i)方法,其中i是索引位置:
list = ['王语嫣', '小龙女', '赵灵儿',"刘亦菲"]
print(list)
print(list.pop(1))
print(list)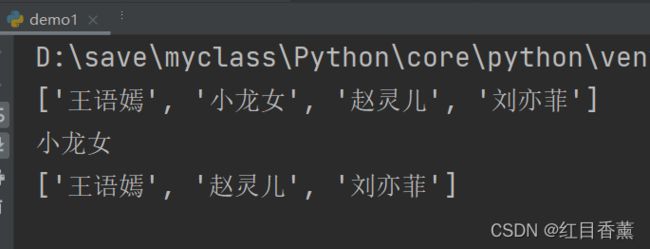
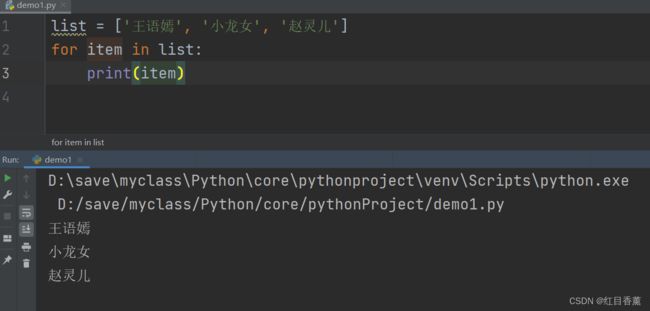
遍历list列表
list = ['王语嫣', '小龙女', '赵灵儿']
for item in list:
print(item)
列表截取
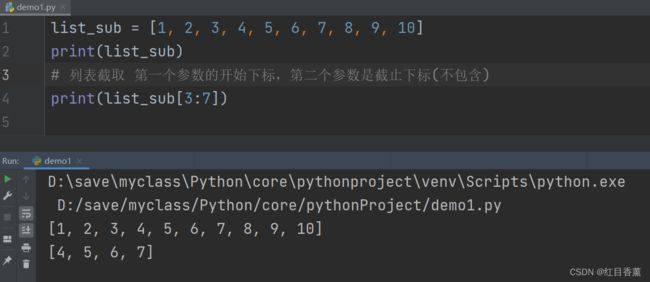
list_sub = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(list_sub)
# 列表截取 第一个参数的开始下标,第二个参数是截止下标(不包含)
print(list_sub[3:7])
可以看到截取的范围是正确的。
知识点二、set集合
其实这里应该在后面的【Pandas】与【NumPy】中详细讲解,我们在这里先让大家认识set集合的基础特性。声明的时候需要使用{}大括号。
Set集合的特性是无序的且不重复的集合。
我们依据这个特性进行一个测试:
# 定义方法1
set_info1 = {"a", "a", "b", "b", "c", "d", "c", "d", "e"}
# 定义方法2
set_info2 = set(["a", "a", "b", "b", "c", "d", "c", "d", "e"])
print(set_info1)
print(set_info2)
输入中可以看到,其特性是去重以及无序:

set列表添加
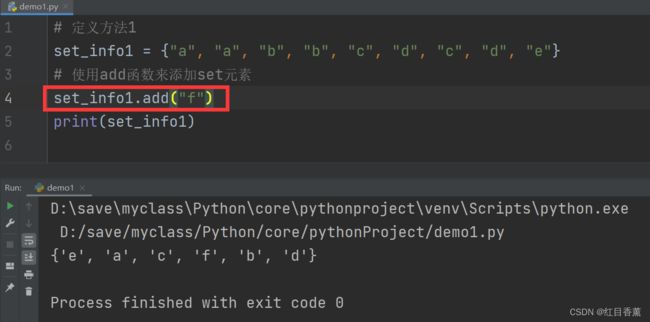
# 定义方法1
set_info1 = {"a", "a", "b", "b", "c", "d", "c", "d", "e"}
# 使用add函数来添加set元素
set_info1.add("f")
print(set_info1)
set移除元素
# 定义方法1
set_info1 = {"a", "a", "b", "b", "c", "d", "c", "d", "e"}
# 使用remove函数来移除set元素
set_info1.add("b")
print(set_info1)
可以看到,其中的"b"元素已经被移除成功。

以上的set操作已经够基础操作了,set集合很多时候会用到查交集、并集、差集的功能,现在咱们用不到,后面后详细讲解。文章链接会在更新后添加进来。
知识点三、Dictionary(字典)
字典的每个键值 key=>value 对用冒号 : 分割,每个对之间用逗号(,)分割,整个字典包括在花括号 {} 中,以下是字典的数据格式:
- 字典中使用键(key)/值(value)对的形式存储数据。
- 键可以是数字、字符串甚至是元组;值可以是任意数据类型。
- 字典使用{}组织元素。
- 字典使用”字典名[键]” 来访问对应的值。
- 字典中的键是唯一的,而值可以不唯一。
- 同列表一样,字典中的值也可以是其他子字典或是子列表。
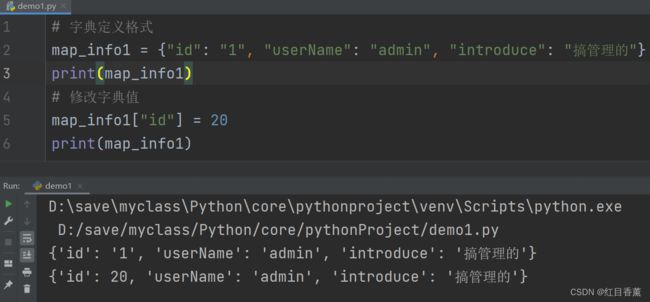
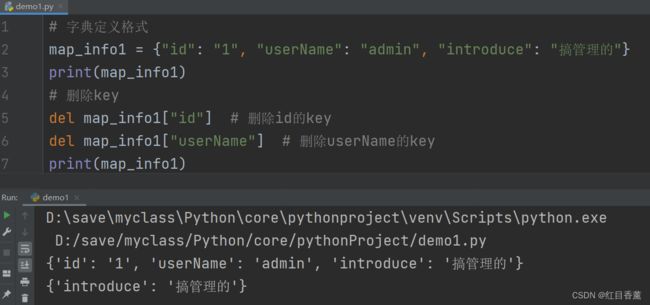
# 字典定义格式
map_info1 = {"id": "1", "userName": "admin", "introduce": "搞管理的"}
print(map_info1)
# 获取key的值
print(map_info1["userName"])
修改字典的值(相当于重写value)
map一旦定义后就没法再添加了。所以没有添加,能修改和删除。
# 字典定义格式
map_info1 = {"id": "1", "userName": "admin", "introduce": "搞管理的"}
print(map_info1)
# 修改字典值
map_info1["id"] = 20
print(map_info1)
删除字典中的值:
如果删除字典的话就直接del 字典名
# 字典定义格式
map_info1 = {"id": "1", "userName": "admin", "introduce": "搞管理的"}
print(map_info1)
# 删除key
del map_info1["id"] # 删除id的key
del map_info1["userName"] # 删除userName的key
print(map_info1)
知识点四、tuple(元组)
元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改,比如同样是列出同学的名字:
tuple = ('王语嫣', '小龙女', '赵灵儿',"刘亦菲")
print(tuple)它也没有append(),insert()这样的方法。其他获取元素的方法和list是一样的。
不可变的tuple有什么意义?因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
Python在显示只有1个元素的tuple时,也会加一个逗号,,以免你误解成数学计算意义上的括号。
很多数据操作完成后返回的数据类型也都是tuple,除了遍历之外没有什么其它有意义的操作。
第五章 Python字符串操作
知识点一、字符串编码
Unicode 字符串
引号前小写的"u"表示这里创建的是一个 Unicode 字符串。如果你想加入一个特殊字符,可以使用 Python 的 Unicode-Escape 编码。如下例所示:
utf-8格式:
str_info = 'Hello World!'
print(str_info)
# byte字符串-utf-8
str_info = str_info.encode("utf-8")
print(str_info)gbk格式:
str_info = 'Hello World!'
print(str_info)
# byte字符串-GBK
str_info = str_info.encode("gbk")
print(str_info)
两种格式都要单独处理,不能先改成utf-8,在改成gbk这样会出现异常。
知识点二、字符串内置函数
这里说实话,函数非常多,用的也多,在没有框架进行数据清洗的时候,真的是头都炸了,那时候整天各种字符串格式化的处理,这些函数也记忆个差不多,好久的事情了,后面有更好的格式化方法就忘记了一些用法了,常用的还是很熟悉。我直接用几个最常用的字符串内置函数来示例讲一下,后面我们直接用框架的字符串处理方法,就节约了大家很多的时间了。
String.center(宽度)
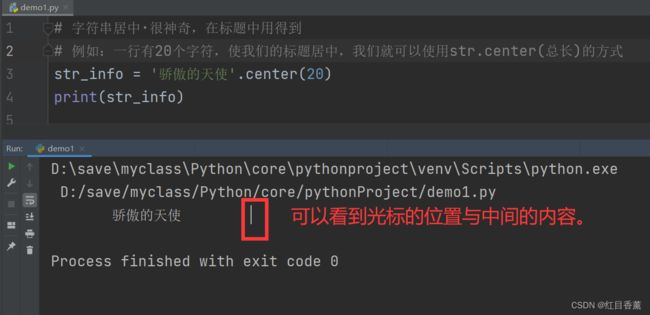
字符串居中·很神奇,在标题中用得到
# 字符串居中·很神奇,在标题中用得到
# 例如:一行有20个字符,使我们的标题居中,我们就可以使用str.center(总长)的方式
str_info = '骄傲的天使'.center(20)
print(str_info)
String.count("查询字符串")
查询字符串中
# 查询字符串中某个字符串的数量String.count("查询字符串")
str_info = """Do not go gentle into that good night
Do not go gentle into that good night,
Old age should burn and rave at close of day;
Rage, rage against the dying of the light.
Though wise men at their end know dark is right,
Because their words had forked no lightning they
Do not go gentle into that good night.
Good men, the last wave by, crying how bright
Their frail deeds might have danced in a green bay,
Rage, rage against the dying of the light.
Wild men who caught and sang the sun in flight,
And learn, too late, they grieved it on its way,
Do not go gentle into that good night.
Grave men, near death, who see with blinding sight
Blind eyes could blaze like 4)meteors and be gay,
Rage, rage against the dying of the light.
And you, my father, there on the sad height,
Curse, bless, me now with your fierce tears, I pray.
Do not go gentle into that good night.
Rage, rage against the dying of the light."""
print("字符串长度:", len(str_info))
print("字符串中包含【good】的数量:", str_info.count("good"))
字符串查找String.find("")或String.index("")两种·可以用【re】正则替换,更好用
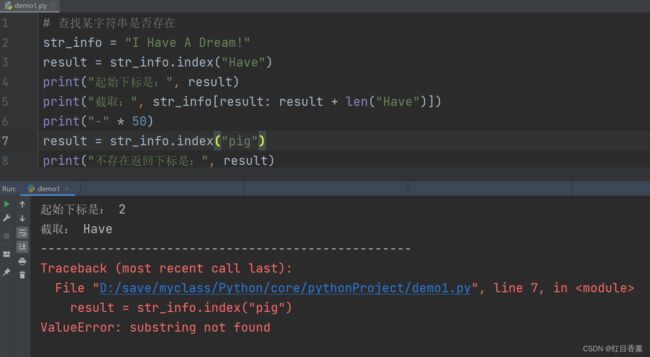
两个区别在于find没有返回-1,index没有返回异常。
String.find("")示例:
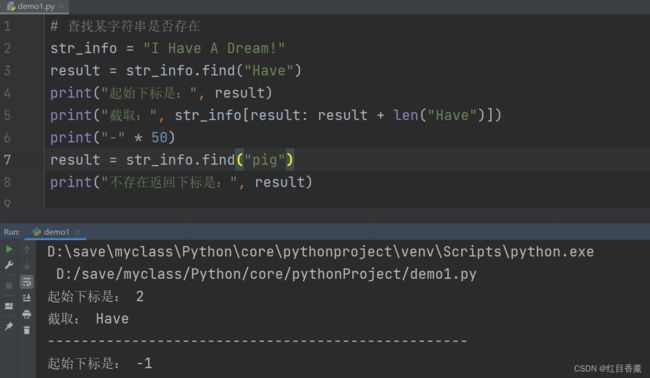
# 查找某字符串是否存在
str_info = "I Have A Dream!"
result = str_info.find("Have")
print("起始下标是:", result)
print("截取:", str_info[result: result + len("Have")])
print("-" * 50)
result = str_info.find("pig")
print("不存在返回下标是:", result)
String.index("")示例:
# 查找某字符串是否存在
str_info = "I Have A Dream!"
result = str_info.index("Have")
print("起始下标是:", result)
print("截取:", str_info[result: result + len("Have")])
print("-" * 50)
result = str_info.index("pig")
print("不存在返回下标是:", result)
其实两者区别在上面的实验中就很明显了。
String.split()分割函数,核心1
通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串。
str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
num -- 分割次数。默认为 -1, 即分隔所有。
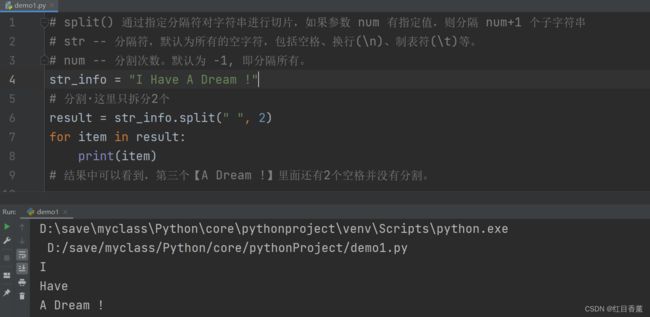
这里用的是非常多的,甚至在数据库中以及Redis中很多存储的就是某种自定义格式的字符串。
String.replace()替换字符串·核心2
replace函数有三个参数,分别是:
old:将被替换的子字符串。
new:新字符串,用于替换old子字符串。
max:可选字符串, 替换不超过 max 次。
str_info = "有三颗星星:☆☆☆"
print(str_info)
str_info = str_info.replace("颗星星", "个方块").replace("☆", "◇")
print(str_info)

以上就是常用的字符串处理的内置函数。其余的一般情况下用不到,我们会在后面框架讲解中深入的对数据清洗做讲解,有更方便的字符串处理技术,我的价值就是节约您的时间。
第六章 Python文件IO操作
知识点一、异常处理
当我们认为某些代码可能会出错时,就可以用try来运行这段代码,如果执行出错,则后续代码不会继续执行,而是直接跳转至错误处理代码,即except语句块,执行完except后,如果有finally语句块,则执行finally语句块,至此,执行完毕。
异常处理语法:
try:
执行代码
except:
发生异常后执行的代码
else:
如果没有异常执行的代码异常示例:例如,都知道除数不能为0,那么计算机中也是一样的。
print(1 / 0)

数组下标越界:
str_info = "老铁666"
print(str_info[20])

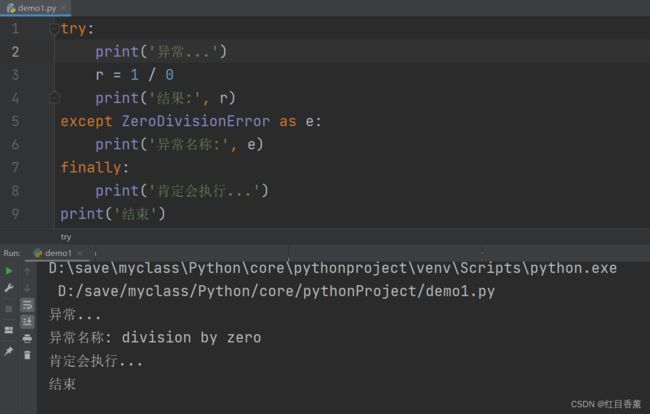
异常解决示例:
try:
print('异常...')
r = 1 / 0
print('结果:', r)
except ZeroDivisionError as e:
print('异常名称:', e)
finally:
print('肯定会执行...')
print('结束')
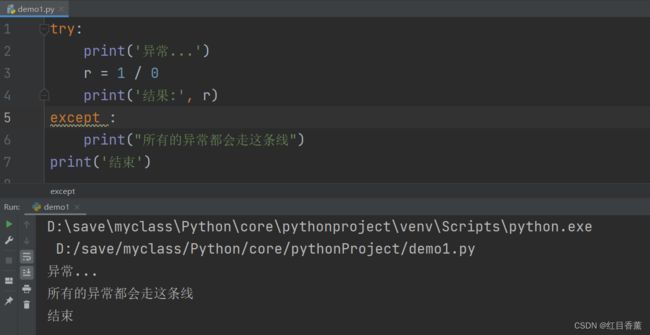
为了处理更多的异常,我们直接写成如下格式:
try:
print('异常...')
r = 1 / 0
print('结果:', r)
except :
print("所有的异常都会走这条线")
print('结束')
知识点二、系统操作·OS操作
这里我给OS操作做了一个列表,因为这个东西没有那个常用,那个不常用的说法。很多的时候都是综合着用的,写一套程序,在操作的过程中就会有如下各个操作,但是真没什么难度,就是一个查询使用字典的熟悉程度。看一下列表后我们看示例。
| 方法 |
描述 |
| os.getcwd() |
获取当前工作目录,即当前Python脚本工作的目录路径 |
| os.listdir() |
返回指定目录下的所有文件和目录名 |
| os.remove() |
用来删除一个文件 |
| os.removedirs(r"c:\python") |
删除多个目录 |
| os.path.isfile() |
判断给出的路径是否是一个文件 |
| os.path.isdir() |
检验给出的路径是否是一个目录 |
| os.path.dirname() |
获取路径名 |
| os.path.basename() |
获取文件名 |
| os.path.split() |
返回一个路径的目录名和文件名 |
| os.path.splitext() |
分离扩展名 |
| os.path.basename() |
获取文件名 |
| os.rename(oldFileName,newFileName) |
重命名 |
| os.makedirs(r"c:\python\test") |
创建多级目录 |
| os.mkdir("test") |
创建单个目录 |
| os.chmod(file) |
修改文件权限与时间戳 |
| os.exit() |
终止当前进程 |
| os.path.getsize(filename) |
获取文件大小 |
示例:
import os
print(os.getcwd())
print(os.listdir())
print(os.path.isfile(os.getcwd()))
print(os.path.isdir(os.getcwd()))
print(os.path.dirname(os.getcwd()))
print(os.path.split(os.getcwd()))
print(os.path.splitext(os.getcwd()+"\\demo1.py"))
print(os.path.basename(os.getcwd()+"\\demo1.py"))
print(os.path.getsize(os.getcwd()+"\\demo1.py"))
# 我将自己改为了demo5.py,所以会直接关闭当前对话框,在左侧的project列表里能看到demo1改为demo5了
print(os.rename("./demo1.py", "./demo5.py"))
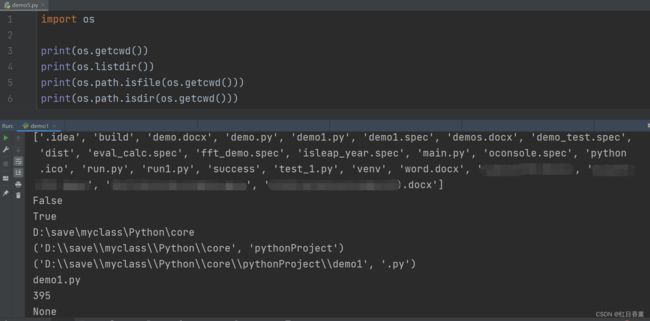
需要深入了解的主要是相对路径。
绝对路径符号:
windows系统根路径:【盘符:/】例如,【C:/】读取的时候会显示【C:\\】
linux系统根路径:【/】例如:/root
相对路径符号:
“./”:表示当前的文件所在的目录。
“../”:表示当前的文件所在的上一层的目录。
“/”:表示当前的文件所在的根目录。
遍历文件夹示例:
import os
def dfs(dir_url):
"""遍历某文件夹"""
list_url = os.listdir(dir_url)
for str_url in list_url:
path = dir + str_url
if os.path.isdir(path):
print("文件夹:", str_url)
try:
dfs(path + "/")
except:
print("非可读文件夹")
else:
print("文件:", str)
dfs("D:/")

知识点三、File操作
语法:
文件对象名 = open(file_name [, access_mode][, buffering])
参数说明:
file_name:该参数指要访问的文件名称对应的字符串
access_mode:决定了打开文件的模式,包括只读、写入和追加等
buffering:buffering的值被设为0,则不会寄存;buffering的值取1,访问文件时会寄存行。
模式列表:
| 模式 |
描述 |
| r |
以只读方式打开文件。文件的指针将会放在文件的开头,这是默认模式 |
| rb |
以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头,这是默认模式 |
| r+ |
打开一个文件用于读写。文件指针将会放在文件的开头 |
| rb+ |
以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头 |
| w |
打开一个文件只用于写入。如该文件已存在,则将其覆盖。如该文件不存在,创建新文件 |
| w+ |
打开一个文件用于读写。如该文件已存在,则将其覆盖。如该文件不存在,创建新文件 |
| wb+ | 以二进制格式打开一个文件用于读写,用于下载文件操作。 |
| a |
打开一个文件用于追加。如该文件已存在,文件指针将会放在文件的结尾,即新的内容将会被写入到 已有内容之后。如该文件不存在,创建新文件进行写入 |
| a+ |
打开一个文件用于读写。如该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。 如该文件不存在,创建新文件用于读写 |
| ab+ |
以二进制格式打开一个文件用于追加。如该文件已存在,文件指针将会放在文件的结尾。 如该文件不存在,创建新文件用于读写 |
文件对象操作列表
| file.closed |
如果文件已被关闭,返回True,否则返回False |
| file.mode |
返回被打开文件的访问模式 |
| file.name |
返回文件的名称 |
| file.softspace |
如果用print输出后,必须接一个空格符,即返回false,否则返回true |
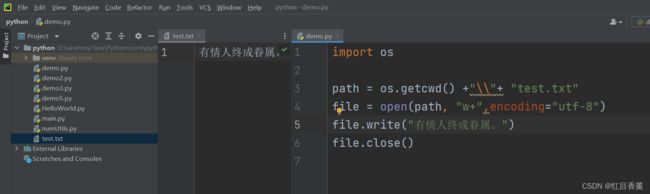
写入示例:
import os
path = os.getcwd() +"\\"+ "test.txt"
file = open(path, "w",encoding="utf-8")
file.write("有情人终成眷属。")
file.close()
读取示例:
import os
path = os.getcwd() + "\\" + "test.txt"
file = open(path, "r", encoding="utf-8")
print(file.read())
file.close()

以上是文本的操作,如果要操作【字节流】文件,需要使用【wb+】来操作。
文件操作异常处理:
try:
fh = open("test.txt", "w+", encoding="utf-8")
fh.write("我就是想向里面写,读取模式操作不了,用于测试异常!")
print("写入过")
except IOError:
print("Error: 模式不对应该是w+")
else:
print("第二种情况内容写入文件成功")
fh.close()
finally:
print("是否执行我都执行")第七章 Python面向对象
这里的理论稍微多一些,面向对象其实就是一种开发思想,我们通过面向对象的方式开发效率会搞很多。要有一些耐心,其实东西并不多,好好读几遍也就理解了,我们后面写几个项目就会更加的熟练了。
知识点一、OOP概述(OOP=面向对象)
面向对象编程——Object Oriented Programming,简称OOP,是一种程序设计思想。OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数。
面向过程的程序设计把计算机程序视为一系列的命令集合,即一组函数的顺序执行。为了简化程序设计,面向过程把函数继续切分为子函数,即把大块函数通过切割成小块函数来降低系统的复杂度。
而面向对象的程序设计把计算机程序视为一组对象的集合,而每个对象都可以接收其他对象发过来的消息,并处理这些消息,计算机程序的执行就是一系列消息在各个对象之间传递。
在Python中,所有数据类型都可以视为对象,当然也可以自定义对象。自定义的对象数据类型就是面向对象中的类(Class)的概念。
我们以一个例子来说明面向过程和面向对象在程序流程上的不同之处。
假设我们要处理学生的成绩表,为了表示一个学生的成绩,面向过程的程序可以用一个dict表示:
std1 = { 'name': 'Michael', 'score': 98 }
std2 = { 'name': 'Bob', 'score': 81 }
而处理学生成绩可以通过函数实现,比如打印学生的成绩:
def print_score(std):
print('%s: %s' % (std['name'], std['score']))
如果采用面向对象的程序设计思想,我们首选思考的不是程序的执行流程,而是Student这种数据类型应该被视为一个对象,这个对象拥有name和score这两个属性(Property)。如果要打印一个学生的成绩,首先必须创建出这个学生对应的对象,然后,给对象发一个print_score消息,让对象自己把自己的数据打印出来。
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
def print_score(self):
print('%s: %s' % (self.name, self.score))
给对象发消息实际上就是调用对象对应的关联函数,我们称之为对象的方法(Method)。面向对象的程序写出来就像这样:
bart = Student('Bart Simpson', 59)
lisa = Student('Lisa Simpson', 87)
bart.print_score()
lisa.print_score()面向对象的设计思想是从自然界中来的,因为在自然界中,类(Class)和实例(Instance)的概念是很自然的。Class是一种抽象概念,比如我们定义的Class——Student,是指学生这个概念,而实例(Instance)则是一个个具体的Student,比如,Bart Simpson和Lisa Simpson是两个具体的Student。
所以,面向对象的设计思想是抽象出Class,根据Class创建Instance。
面向对象的抽象程度又比函数要高,因为一个Class既包含数据,又包含操作数据的方法。
知识点二、类和实例
面向对象最重要的概念就是类(Class)和实例(Instance),必须牢记类是抽象的模板,比如Student类,而实例是根据类创建出来的一个个具体的“对象”,每个对象都拥有相同的方法,但各自的数据可能不同。
仍以Student类为例,在Python中,定义类是通过class关键字:
class Student(object):
pass
class后面紧接着是类名,即Student,类名通常是大写开头的单词,紧接着是(object),表示该类是从哪个类继承下来的,继承的概念我们后面再讲,通常,如果没有合适的继承类,就使用object类,这是所有类最终都会继承的类。
定义好了Student类,就可以根据Student类创建出Student的实例,创建实例是通过类名+()实现的:
class Student(object):
pass
bart = Student()
print(bart)
print(Student)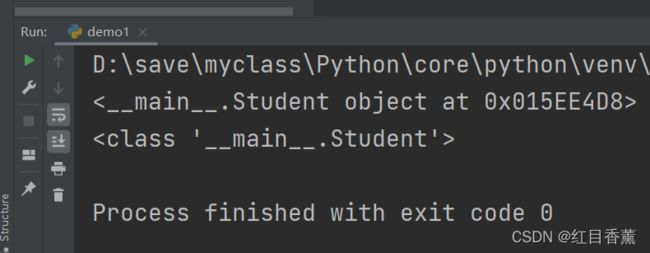
可以看到,变量bart指向的就是一个Student的实例,后面的0x10a67a590是内存地址,每个object的地址都不一样,而Student本身则是一个类。
可以自由地给一个实例变量绑定属性,比如,给实例bart绑定一个name属性:
class Student(object):
pass
bart = Student()
bart.name = 'Blus li'
print(bart.name)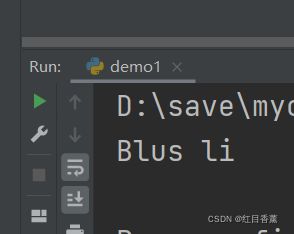
由于类可以起到模板的作用,因此,可以在创建实例的时候,把一些我们认为必须绑定的属性强制填写进去。通过定义一个特殊的__init__方法,在创建实例的时候,就把name,score等属性绑上去:
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
注意:特殊方法“__init__”前后分别有两个下划线!!!
注意到__init__方法的第一个参数永远是self,表示创建的实例本身,因此,在__init__方法内部,就可以把各种属性绑定到self,因为self就指向创建的实例本身。
有了__init__方法,在创建实例的时候,就不能传入空的参数了,必须传入与__init__方法匹配的参数,但self不需要传,Python解释器自己会把实例变量传进去:
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
bart = Student('Blus li', 97)
print(bart.name)
print(bart.score)
和普通的函数相比,在类中定义的函数只有一点不同,就是第一个参数永远是实例变量self,并且,调用时,不用传递该参数。除此之外,类的方法和普通函数没有什么区别,所以,你仍然可以用默认参数、可变参数、关键字参数和命名关键字参数。
知识点三、封装
面向对象编程的一个重要特点就是数据封装。在上面的Student类中,每个实例就拥有各自的name和score这些数据。我们可以通过函数来访问这些数据,比如打印一个学生的成绩:
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
bart = Student('Blus li', 97)
def print_score(std):
print('%s: %s' % (std.name, std.score))
print_score(bart)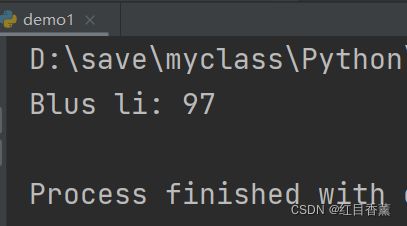
但是,既然Student实例本身就拥有这些数据,要访问这些数据,就没有必要从外面的函数去访问,可以直接在Student类的内部定义访问数据的函数,这样,就把“数据”给封装起来了。这些封装数据的函数是和Student类本身是关联起来的,我们称之为类的方法:
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
def print_score(self):
print('%s: %s' % (self.name, self.score))
要定义一个方法,除了第一个参数是self外,其他和普通函数一样。要调用一个方法,只需要在实例变量上直接调用,除了self不用传递,其他参数正常传入:
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
def print_score(self):
print('%s: %s' % (self.name, self.score))
bart=Student("Blue Li",96);
bart.print_score()
和普通的函数相比,在类中定义的函数只有一点不同,就是第一个参数永远是实例变量self,并且,调用时,不用传递该参数。除此之外,类的方法和普通函数没有什么区别,所以,你仍然可以用默认参数、可变参数、关键字参数和命名关键字参数。
知识点四、继承和多态
在OOP程序设计中,当我们定义一个class的时候,可以从某个现有的class继承,新的class称为子类(Subclass),而被继承的class称为基类、父类或超类(Base class、Super class)。
比如,我们已经编写了一个名为Animal的class,有一个run()方法可以直接打印:
class Animal(object):
def run(self):
print('Animal is running...')
当我们需要编写Dog和Cat类时,就可以直接从Animal类继承:
class Dog(Animal):
pass
class Cat(Animal):
pass对于Dog来说,Animal就是它的父类,对于Animal来说,Dog就是它的子类。Cat和Dog类似。
继承有什么好处?最大的好处是子类获得了父类的全部功能。由于Animial实现了run()方法,因此,Dog和Cat作为它的子类,什么事也没干,就自动拥有了run()方法:
dog = Dog()
dog.run()
cat = Cat()
cat.run()
运行结果如下:
Animal is running...
Animal is running...
当然,也可以对子类增加一些方法,比如Dog类:
class Dog(Animal):
def run(self):
print('Dog is running...')
def eat(self):
print('Eating meat...')
继承的第二个好处需要我们对代码做一点改进。你看到了,无论是Dog还是Cat,它们run()的时候,显示的都是Animal is running...,符合逻辑的做法是分别显示Dog is running...和Cat is running...,因此,对Dog和Cat类改进如下:
class Dog(Animal):
def run(self):
print('Dog is running...')
class Cat(Animal):
def run(self):
print('Cat is running...')
再次运行,结果如下:
Dog is running...
Cat is running...
当子类和父类都存在相同的run()方法时,我们说,子类的run()覆盖了父类的run(),在代码运行的时候,总是会调用子类的run()。这样,我们就获得了继承的另一个好处:多态。
要理解什么是多态,我们首先要对数据类型再作一点说明。当我们定义一个class的时候,我们实际上就定义了一种数据类型。我们定义的数据类型和Python自带的数据类型,比如str、list、dict没什么两样:
a = list() # a是list类型
b = Animal() # b是Animal类型
c = Dog() # c是Dog类型
判断一个变量是否是某个类型可以用isinstance()判断:
class Animal(object):
def run(self):
print('Animal is running...')
class Dog(Animal):
def run(self):
print('Dog is running...')
class Cat(Animal):
def run(self):
print('Cat is running...')
a = list() # a是list类型
b = Animal() # b是Animal类型
c = Dog() # c是Dog类型
print(isinstance(a, list))
print(isinstance(b, Animal))
print(isinstance(c, Dog))
看来a、b、c确实对应着list、Animal、Dog这3种类型。
但是等等,试试:
class Animal(object):
def run(self):
print('Animal is running...')
class Dog(Animal):
def run(self):
print('Dog is running...')
class Cat(Animal):
def run(self):
print('Cat is running...')
a = list() # a是list类型
b = Animal() # b是Animal类型
c = Dog() # c是Dog类型
print(isinstance(c, Animal))
看来c不仅仅是Dog,c还是Animal!
不过仔细想想,这是有道理的,因为Dog是从Animal继承下来的,当我们创建了一个Dog的实例c时,我们认为c的数据类型是Dog没错,但c同时也是Animal也没错,Dog本来就是Animal的一种!
所以,在继承关系中,如果一个实例的数据类型是某个子类,那它的数据类型也可以被看做是父类。但是,反过来就不行:
class Animal(object):
def run(self):
print('Animal is running...')
class Dog(Animal):
def run(self):
print('Dog is running...')
class Cat(Animal):
def run(self):
print('Cat is running...')
b = Animal()
print(isinstance(b, Dog))
Dog可以看成Animal,但Animal不可以看成Dog。
要理解多态的好处,我们还需要再编写一个函数,这个函数接受一个Animal类型的变量:
def run_twice(animal):
animal.run()
animal.run()
当我们传入Animal的实例时,run_twice()就打印出:
class Animal(object):
def run(self):
print('Animal is running...')
class Dog(Animal):
def run(self):
print('Dog is running...')
class Cat(Animal):
def run(self):
print('Cat is running...')
def run_twice(animal):
animal.run()
animal.run()
run_twice(Animal())
当我们传入Dog的实例时,run_twice()就打印出:
class Animal(object):
def run(self):
print('Animal is running...')
class Dog(Animal):
def run(self):
print('Dog is running...')
class Cat(Animal):
def run(self):
print('Cat is running...')
def run_twice(animal):
animal.run()
animal.run()
run_twice(Dog())
看上去没啥意思,但是仔细想想,现在,如果我们再定义一个Tortoise类型,也从Animal派生:
class Animal(object):
def run(self):
print('Animal is running...')
class Dog(Animal):
def run(self):
print('Dog is running...')
class Cat(Animal):
def run(self):
print('Cat is running...')
class Tortoise(Animal):
def run(self):
print('Tortoise is running slowly...')
def run_twice(animal):
animal.run()
animal.run()
run_twice(Tortoise())
你会发现,新增一个Animal的子类,不必对run_twice()做任何修改,实际上,任何依赖Animal作为参数的函数或者方法都可以不加修改地正常运行,原因就在于多态。
多态的好处就是,当我们需要传入Dog、Cat、Tortoise……时,我们只需要接收Animal类型就可以了,因为Dog、Cat、Tortoise……都是Animal类型,然后,按照Animal类型进行操作即可。由于Animal类型有run()方法,因此,传入的任意类型,只要是Animal类或者子类,就会自动调用实际类型的run()方法,这就是多态的意思:
对于一个变量,我们只需要知道它是Animal类型,无需确切地知道它的子类型,就可以放心地调用run()方法,而具体调用的run()方法是作用在Animal、Dog、Cat还是Tortoise对象上,由运行时该对象的确切类型决定,这就是多态真正的威力:调用方只管调用,不管细节,而当我们新增一种Animal的子类时,只要确保run()方法编写正确,不用管原来的代码是如何调用的。这就是著名的“开闭”原则:
对扩展开放:允许新增Animal子类;
对修改封闭:不需要修改依赖Animal类型的run_twice()等函数。
继承还可以一级一级地继承下来,就好比从爷爷到爸爸、再到儿子这样的关系。而任何类,最终都可以追溯到根类object,这些继承关系看上去就像一颗倒着的树。比如如下的继承树:
┌───────────────┐
│ object │
└───────────────┘
│
┌────────────┴────────────┐
│ │
▼ ▼
┌─────────────┐ ┌─────────────┐
│ Animal │ │ Plant │
└─────────────┘ └─────────────┘
│ │
┌─────┴──────┐ ┌─────┴──────┐
│ │ │ │
▼ ▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐
│ Dog │ │ Cat │ │ Tree │ │ Flower │