《Communication-Efficient Learning of Deep Networks from Decentralized Data》论文阅读
4.29 天气:阴。
看论文看不懂,所以找回来这篇经典的FedAvg看看。
AISTATS 2017.
《Communication-Efficient Learning of Deep Networks from Decentralized Data》
- 一、intro
- 二、the FederatedAveraging Algorithm
- 三、实验
一、intro
数据的中心化存储不现实、不安全。所以数据需要分布式存储。
主要贡献:
1)本文定义了在去中心化的数据上进行训练是一个重要的方向。
2)提出了在1)的setting下的解决方案。
3)提出一种合适的实验测度。
联邦学习出现了!作者将这种分布式的训练方式称为Federated learning。
Federated learning出现的必要性:
1)私密的移动设备上的数据可以有效利用起来。
2)不应该把移动设备上的大量的私密数据转移到中心服务器上(仅为了优化模型)。
3)可以根据在移动设备上的用户数据轻松自然导出label数据。
Federated learning涉及到的优化问题Federated optimization:
clients传输给server的数据应该只是updata information,其他信息(即使经过匿名化处理)还是有信息泄漏的风险。
1)non-IID:每个clients上的数据的差异性是很大的,是不独立同分布的。
2)unbalanced:一些用户可能具有更多的数据
3)massively distributed:clients的数目可能比clients拥有的数据要更多。
4)limited communication:通讯expensive,甚至可能clients离线。
Federated learning的优化过程描述:
假设有固定数据的clients,以及每个clients都有固定的local datasets。在每轮循环开始的时候,都有固定数目的一部分clients被选择出来参与优化(for 效率)。每个被选择出来的clients进行在全局状态下的局部数据的局部计算,并且将updates上传到server。这些server然后将这些updates上传到global state。重复进行上面描述的步骤。
Federated learning的通讯问题:
在一般的data center optimization的计算中,通讯花费很少,计算花费较多。
但是在federated optimization中通信花费是大部分的花费,通常被带宽所限制。因此,我们的目标是能够增加额外的计算来减少通讯花费。增加计算有以下两种方法:
1)增加并行度。增加每次communication round的参加的client的数目。
2)增加每个clients上的计算量。每个clients上将承担除了梯度更新以外更加复杂的计算。
经过实验证明,speedups的增加都是由于增加clients的计算量引起的。
二、the FederatedAveraging Algorithm
算法描述如下:
In the convex setting?
在这种设置下的实验数据往往违反了联邦学习的数据设置情况,
数据是IID的,且并不是massively distributed的。
In the non-convex setting?
在参数空间中取参数的平均值可能获得很糟糕的结果。
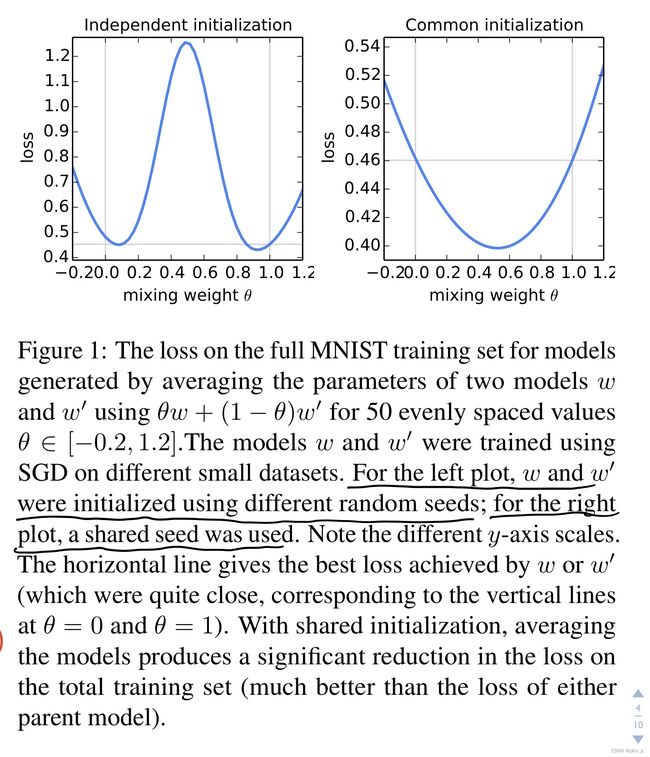
shared initialization的效果比较好。因此,在FedAvg的训练中:“a shared starting model w t w_t wt is used for each round of FedAvg”.
三、实验
实验的基础设置:
实验任务:图片分类、语言建模任务。
将首先使用代理数据集来获得FedAvg的最优超参数。
图片分类:
数据任务:MNIST digit recognition task。
测试模型:MLP、CNN。
数据划分方式:IID、Non-IID。
IID: 数据洗牌->均匀划分数据到多个clients中。
Non-IID: 通过数字标签对数据排序->划分为大小一致的多个数据块->给多个clients少量的几个数据块(如给200个clients,每个clients 2个数据块)。这是一种pathological(无道理的)non-IID划分方式。依据此划分看看对模型的性能损害有多大。
语言建模任务:
数据集:威廉莎士比亚全集。
测试模型:LSTM。
切割方式:
non-IID:每个人物说的话至少有两句。将这些每个人物说的句子划分(前80%-后20%)。
IID:洗牌均匀划分。
increasing parallelism:
改变client fraction C C C:增加了每轮参与训练的clients的数目。
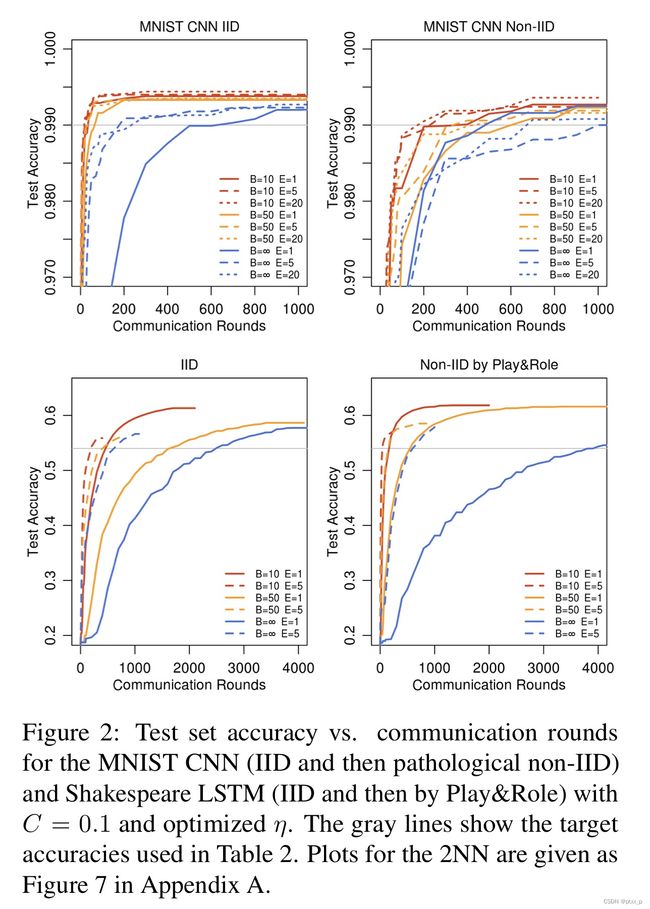
改变E、B,提高运行速度。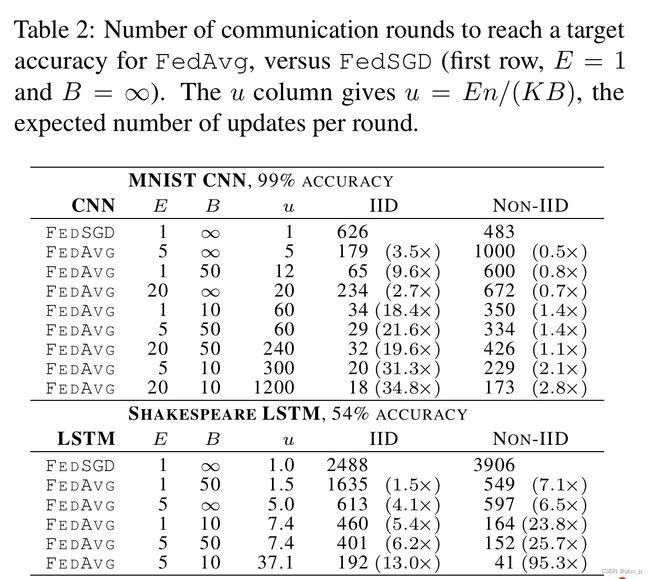 increasing computation per client:
increasing computation per client:
看图二、表二。表二中的u表示每个round里clients需要更新的次数。
提升BE不仅仅能够下降communication cost,还能产生和dropout一样的正则化效果。
can we over-optimize on the client datasets?
CIFAR experiments:
Large-scale LSTM experiments:
总结:保证了数据私有的情况下,保持了模型性能,并且大大降低了communication cost。