【数据分析】 Titanic乘客获救预测(2)数据处理
Titanic乘客获救预测(2)数据处理
- 1 数据清洗及特征处理
-
- 1.1 缺失值处理
-
- 1.1.1 查看缺失值
- 1.1.2 缺失值处理
- 1.2 重复值处理
- 1.3 特征处理
-
- 1.3.1 连续型数值离散化处理
- 1.3.2 类别型文本特征转换
- 1.3.3 纯文本中特征提取
- 2 初步分析
-
- 2.1 数据重构
-
- 2.1.1 数据连接与合并merge()、join()、concat()
- 2.2.2 数据重排stack()
- 2.2 数据运用
- 3 数据可视化
-
- 3.1 柱状图
- 3.2 折线图
- 3.3 密度图
1 数据清洗及特征处理
数据清洗是指对拿到的原始数据中的缺失值,异常值的处理,以保证后续数据分析和建模的进行。
1.1 缺失值处理
1.1.1 查看缺失值
- 方法1:info() 查看数据基本信息
df = pd.read_csv('titanic/titanic_train.csv')
print(df.info())
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
由info()函数输出结果可知dataframe长度为891,其中Age,Cabin有较多缺失值,Embarked有少量缺失值。
- 方法2:isnull()
print(df.isnull().sum())
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
isnull()函数筛选值为空的属性,sum()对其进行求和,得到每个属性缺失值个数。
1.1.2 缺失值处理
对于缺失值处理主要包括删除以及填充两个大方向,删除一般用于缺失数据很小且对数据集无明显影响的情况下,填充方式需要结合数据集属性具体情况进行分析。
对于本次选取的数据集,三个属性存在缺失值:Age(年龄),Cabin(舱位),Embarked(港口),具体处理方式分析如下:
- Embarked登船港口
该数据仅有两个缺失值,对总体影响不大,这里我选择采用众数进行填充。
(也可以删除这两行数据)
# 找到embarked属性的众数
# 一种非常复杂的方法
Embarked_mode = df.groupby('Embarked')['Embarked'].count().sort_values(ascending=False).index[0]
# 突然发现可以直接用mode()函数
Embarked_mode = df['Embarked'].mode().iloc[0]
print(Embarked_mode) #S
# 利用求得的众数Embarked_mode进行填充
df['Embarked'].fillna(Embarked_mode, inplace=True)
print(df.info())
通过打印df.info()得到如下所示,可知此时Embarked缺失值已经填充完成。
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 891 non-null object
dtypes: float64(2), int64(5), object(5)
还可以把缺失的两行直接删除啦!
# 直接删除数据中Embarked值为0的两行
df.dropna(subset=["Embarked"],inplace=True)
dropna() & fillna() 的使用 —> 官方文档
-
dropna()DataFrame.dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False)[source]
- axis:{0 or ‘index’, 1 or ‘columns’}, default 0,决定按列/行删除缺失值
- how:{‘any’, ‘all’}, default ‘any’,any表示该行/列中包含NA即dropna,all表示当该行/列全为NA才执行
- subset:array-like, optional 标签
- inplace:bool, default False
-
fillna()
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)- value:scalar, dict, Series, or DataFrame,填充值,不能是list
- method:{‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None,
- axis:{0 or ‘index’, 1 or ‘columns’}
- inplace:bool, default False
- limit:int,default None,只填充limit个NAN
-
Cabin舱位
结合titanic实际情况,舱位号缺失可能由于数据丢失或者无舱位,模糊记得船舱底部有很多穷人聚集,可能缺失也代表着一定的特征,故对其空缺值填充为U0。
df['Cabin'].fillna('U0',inplace=True)
- Age年龄
由于age缺失值相对较对,删除以及填充为0对结果影响都比较大,应对其进行合理化填充,利用无缺失数据对缺失数据的age值进行预测。在这里选用随机森林的方式进行处理:
# 取以下几个特征对age进行预测
df_age = df[['Age', 'Survived', 'Fare', 'Parch', 'SibSp', 'Pclass']]
# 将数据集划分为age非空和age值缺失两部分
age_notnull = df_age.loc[df_age['Age'].notnull()]
age_isnull = df_age.loc[df_age['Age'].isnull()]
print(age_notnull.head())
# x为除age外其他特征,y表示age值
x = age_notnull.values[:, 1:]
y = age_notnull.values[:, 0]
-
TypeError:unhashable type:'slice
x = age_notnull[:,1:]会报上面这个错,查看资料发现
X是一个Dataframe,不能通过切片术语来访问X[:, 1],必须通过iloc或访问X.values
# 随机森林模型
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(n_estimators=100, n_jobs=-1)
rf.fit(x,y)
sklearn随机森林回归器RandomForestRegressor()
RandomForestRegressor()(n_estimators=10, criterion=‘gini’, max_depth=None,min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,max_features=‘auto’, max_leaf_nodes=None, min_impurity_split=1e-07,bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0,warm_start=False, class_weight=None)
参数非常多,只解释两个用到的参数,其余参考官方文档
- n_estimators: 就是弱学习器的最大迭代次数,或者说最大的弱学习器的个数,默认是10。
- n_jobs:表示要并行运行的作业数,-1表示使用所有处理器
# 得到Age缺失值的预测结果
agePredict = rf.predict(age_isnull.values[:,1:])
# 把预测结果作为age特征的值填充回原df中
df.loc[df['Age'].isnull(), ['Age']] = agePredict
print(df.isnull().sum())
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 0
通过如上结果可得,至此缺失值已全部填充完毕。
1.2 重复值处理
print(df[df.duplicated()])
打印结果为空可知本组数据中不含有缺失值,若存在可通过drop_duplicates()进行处理
缺失值和重复值均处理完毕后,对清洗后的数据进行保存(注意路径)
df.to_csv('titanic/train_clear.csv')
1.3 特征处理
对特征进行观察可将其大致分为两大类:
-
数值型特征:Survived ,Pclass, Age ,SibSp, Parch, Fare
- 离散型数值特征:Survived, Pclass
- 连续型数值特征:Age,SibSp, Parch, Fare
-
文本型特征:Name, Sex, Cabin,Embarked, Ticket
- 类别型文本特征:Sex, Cabin, Embarked, Ticket
- 纯文本特征:Name
数值型特征一般可以直接用于模型的训练,但有时候为了模型的稳定性及鲁棒性会对连续变量进行离散化。
文本型特征往往需要转换成数值型特征才能用于建模分析。
1.3.1 连续型数值离散化处理
将Age特征进行离散化处理,使用数据分箱的方式
数据分箱
数据分箱技术在Pandas官方给出的定义:Bin values into discrete intervals,是指将值划分到离散区间。好比不同大小的苹果归类到几个事先布置的箱子中;不同年龄的人划分到几个年龄段中。主要就是用到pd.cut()和pd.qcut()两个函数。
# 将Age平均分为5块,标签为1~5
df['Age_bin1'] = pd.cut(df['Age'], 5, labels=['1','2','3','4','5'])
# 将Age划分为[0,5) [5,15) [15,30) [30,50) [50,80)五个年龄段
df['Age_bin2'] = pd.cut(df['Age'], [0,5,15,30,50,80],labels=['1','2','3','4','5'])
# 将Age按10% 30% 50 70% 90%五个年龄段进行划分
df['Age_bin3'] = pd.qcut(df['Age'], [0,0.1,0.3,0.5,0.7,0.9], labels=['1','2','3','4','5'])
总结一下pd.cut()和pd.qcut()的使用区别:
-
pd.cut()pd.cut( x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates=‘raise’, )
- x:一维数组(在上述代码中对应df[‘Age’])
- bins:整数,标量序列或者间隔索引,是进行分组的依据
- 整数n:表示将x中的数值分成等宽的n份(Age_bin1)
- 标量序列:表示用来分档的分界值(Age_bin2)
- 间隔索引:“ bins”的间隔索引必须不重叠
- right :布尔值,默认为True表示包含最右侧的数值
- labels : 数组或布尔值,可选,指定分箱的标签
- include_lowest:布尔值,表示区间的左边是开还是闭,默认为false,也就是不包含区间左边
如果填入整数n,则表示将x中的数值分成等宽的n份(即每一组内的最大值与最小值之差约相等);
如果是标量序列,序列中的数值表示用来分档的分界值
如果是间隔索引,“ bins”的间隔索引必须不重叠
pd.qcut()
pd.qcut(x, q, labels=None, retbins=False, precision=3, duplicates=‘raise’)
pd.qcut()与pd.cut()参数大致相同,少了right和include_lowest两个参数- q:表示分位数的整数或者数组
- 如果是分位数的整数,例如10用于十分位,4用于四分位
- 如果是分位数数组,例如[0,0.25,0.5,0.75,1]用于四分位数
- q:表示分位数的整数或者数组
1.3.2 类别型文本特征转换
类别型文本特征包括Sex, Cabin, Embarked,Ticket,通过对数据观察可知:
- Sex包括female,male两类
- Cabin包含多个类别(可根据其开头字母进行分类)
- Embarked包含S,C,Q三个类别
- Ticket包含多个类别
(查看类别课用unique()方法)
具体分析如下:
- 对于Sex进行处理
两个类别male,female替换为1,2
# 方法一:replace
df['Sex_num1'] = df['Sex'].replace(['male','female'],[1,2])
# 方法二:map
df['Sex_num2'] = df['Sex'].map({'male':1,'female':2})
- 对于Embarked进行处理
三个类别SCQ也可使用上述方法一,方法二,同时还有其他解决方式
# 方法三:one-hot编码
# dummy variables(转化成 one hot encode),生成多个特征(比如此题中S C Q)
embark_dummy = pd.get_dummies(df['Embarked'])
df = df.join(embark_dummy)
df.drop(['Embarked'], axis=1, inplace=True)
print(embark_dummy.head())
打印embark_dummy.head()结果如下,实对Embarked one-hot编码后的结果,最终结果在原df中加入SCQ三列。
C Q S
0 0 0 1
1 1 0 0
2 0 0 1
3 0 0 1
4 0 0 1
- 对于Cabin进行处理
Cabin的类别非常多,但是观察发现是有一定规律的,开头字母相同的我们将其认为是同等级船舱
# 方法四:编码函数factorize()
# Factoring每个类别映射成一个ID,最终生成为一个特征
# 把Cabin中的值映射成其舱位号首字母,例如把U0映射为U,A1,A2,A15等都映射为A,B2 B4之类的映射为B…
import re
df['Cabin_set'] = df['Cabin'].map(lambda x:re.compile('([A-Za-z]+)').search(x).group())
# 对上述结果进行编码
df['Cabin_set'] = pd.factorize(df['Cabin_set'])[0]
# factorize结果包含两个array,一个为编码后的数字,一个为原来的Index,[0]取我们要的第一组~
get_dummies()与factorize()的区别- factorize() 对每一个类别映射一个ID,这种映射最后只生成一个特征
- get_dummes() 映射后生成多个特征
1.3.3 纯文本中特征提取
Name是一个纯文本型数据,一个人的性命对于我们是否存活的分析意义不大,但是姓名中含有的Title部分(如Mr.,Miss. etc)却包含着一定的特征信息。
故对于Name特征,提取其title部分进行后续分析
df['Title'] = df['Name'].str.extract('([A-Za-z]+)\.', expand=False)
str.extract():可用正则从字符数据中抽取匹配的数据,只返回第一个匹配的数据。
Series.str.extract(pat, flags=0, expand=None)
pat : 字符串或正则表达式
flags : 整型
expand : 布尔型,是否返回DataFrame
2 初步分析
对于处理好的数据进行一系列运算操作,进行初步分析。(主要是groupby()函数的使用)
2.1 数据重构
2.1.1 数据连接与合并merge()、join()、concat()
- pandas中的数据连接和合并方法
merge():merge()是对DataFrame进行行连接的,对于两个DataFrame,可以用参数on指定用来merge的共同列,也可以利用left_on和right_on分别指定用来merge的列,还可以利用how参数指定merge的方式,how可以为inner、outer、left、right,默认为inner。join(): join()方法根据索引进行合并,如果df1和df2中有重叠的列名,所以还需要分别指定lsuffix和rsuffix参数来表示合并后的列名后缀以区分合并后的列名。concat():轴向连接,就是直接将多个Series或者DataFrame按某个轴的方向进行连接,不指定某个列进行合并,而是直接将多个对象沿着指定的轴进行堆叠,无论是否有重复值。
2.2.2 数据重排stack()
将Dataframe数据变为Series类型的数据,主要用到stack()函数。
stack():stack即为堆叠,该函数即为实现输入数个数组不同方式的堆叠,返回堆叠后的1个数组。- 参数:
- arrays:用来作为堆叠的数个形状维度相等的数组
- axis:即指定依照哪个维度进行堆叠,也就是指定哪种方式进行堆叠数组,默认axis=0
- 输出:堆叠后的1个数组
(概念有些不太清晰,举个例子来看看具体应用)
# 首先构造a,b,c,d四个数组
import numpy as np
a=np.arange(1, 7).reshape((2, 3))
b=np.arange(7, 13).reshape((2, 3))
c=np.arange(13, 19).reshape((2, 3))
d=np.arange(19, 25).reshape((2, 3))
print(a, '\n', b, '\n', c, '\n', d)
[[1 2 3]
[4 5 6]]
[[ 7 8 9]
[10 11 12]]
[[13 14 15]
[16 17 18]]
[[19 20 21]
[22 23 24]]
不同维度的堆叠实验
- axis=0
stack_axis_0 = np.stack([a,b,c,d],axis=0)
print("axis=0时stack结果为:\n", stack_axis_0)
print("axis=0时shape为:\n", stack_axis_0.shape)
axis=0时stack结果为:
[[[ 1 2 3]
[ 4 5 6]]
[[ 7 8 9]
[10 11 12]]
[[13 14 15]
[16 17 18]]
[[19 20 21]
[22 23 24]]]
axis=0时shape为:
(4, 2, 3)
axis等于几就说明在哪个维度上进行堆叠。当axis=0的时候,意味着整体,也就是一个2行3列的数组。
对于0维堆叠,相当于简单的物理罗列,进行0维堆叠即把它们按顺序排放了起来,形成了一个(4,2,3)的3维数组。
- axis=1
stack_axis_1 = np.stack([a,b,c,d],axis=1)
print("axis=1时stack结果为:\n", stack_axis_1)
print("axis=1时shape为:\n", stack_axis_1.shape)
axis=1时stack结果为:
[[[ 1 2 3]
[ 7 8 9]
[13 14 15]
[19 20 21]]
[[ 4 5 6]
[10 11 12]
[16 17 18]
[22 23 24]]]
axis=1时shape为:
(2, 4, 3)
当axis=1的时候,意味在第一个维度上进行堆叠,也就是数组的每一行。
对于1维堆叠,4个2行3列的数组,各自拿出自己的第一行数据进行堆叠形成3维数组的第一“行”,各自拿出自己的第二行数据进行堆叠形成3维数组的第二“行”,从而形成了一个(2,4,3)的3维数组。
- axis=2
#axis=2
stack_axis_2 = np.stack([a,b,c,d],axis=2)
print("axis=2时stack结果为:\n", stack_axis_2)
print("axis=2时shape为:\n", stack_axis_2.shape)
[[[ 1 7 13 19]
[ 2 8 14 20]
[ 3 9 15 21]]
[[ 4 10 16 22]
[ 5 11 17 23]
[ 6 12 18 24]]]
axis=2时shape为:
(2, 3, 4)
axis=2的时候,意味着第二个维度,也就是数组的每一行中的更深一层的维度,对于本例的2维数组来说就到了单个的数据。
注意:2维堆叠不是对每一列拿出来进行堆叠若进行列堆叠,本质上就是1维堆叠的转置并无区别。(个人认为)维度的概念是逐层深入的。比如我们这里谈到的整体、行、单个数据。所以对于2维堆叠,4个2行3列的数组,各自拿出自己每个数据,在对应的位置,进行堆叠。从而形成了一个(2,3,4)的3维数组。
将Dataframe数据变为Series类型的数据
# Dataframe数据变为Series
data = pd.DataFrame(np.arange(12).reshape(3,4),index=['A','B','C'],columns=['col_1','col_2','col_3','col_4'])
print(data)
print(type(data))
(个人理解)
上面关于stack函数的讲解是对于多个数组堆叠的情况,在dataframe中不存在多个数组。可将其近似看作每个index和columns对应组成一个1x1的array,然后对其进行axis=0的堆叠,每个array按顺序排放起来。也就相当于是对于dataframe中每个值进行依次排列,做了一个dataframe到Series的解雇转换。结合以下输出结果看得更清晰。
col_1 col_2 col_3 col_4
A 0 1 2 3
B 4 5 6 7
C 8 9 10 11
A col_1 0
col_2 1
col_3 2
col_4 3
B col_1 4
col_2 5
col_3 6
col_4 7
C col_1 8
col_2 9
col_3 10
col_4 11
dtype: int32
2.2 数据运用
对于处理好的数据进行一系列运算操作,进行初步分析。(主要是groupby()函数的使用)
# 1 计算泰坦尼克号男性与女性的平均票价
fare_sex_mean = df.groupby(df['Sex'])['Fare'].mean()
Sex
female 44.479818
male 25.523893
Name: Fare, dtype: float64
注意数据结构的问题
fare_sex_mean = df.groupby(df[‘Sex’])['Fare'].mean() 得到为Series
fare_sex_mean = df.groupby(df[‘Sex’])[['Fare']].mean() 得到为DataFrame
# 2 统计泰坦尼克号中男女的存活人数
sex_survived = df.groupby(df['Sex'])['Survived'].sum()
Sex
female 233
male 109
Name: Survived, dtype: int64
pclass_survived = df.groupby(df['Pclass'])['Survived'].sum()
Pclass
1 136
2 87
3 119
Name: Survived, dtype: int64
# 4 统计在不同等级的票中的不同年龄的船票花费的平均值
fare_mean = df.groupby(['Pclass','Age'])['Fare'].mean()
print(fare_mean.head())
Pclass Age
1 0.92 151.5500
2.00 151.5500
4.00 81.8583
11.00 120.0000
14.00 120.0000
Name: Fare, dtype: float64
# 5 将任务1和任务2的数据合并,并保存到sex_fare_survived.csv
result = fare_sex_mean.join(sex_survived)
result.to_csv('titanic/sex_fare_survived.csv')
Fare
Sex
female 44.479818 任务1结果
male 25.523893
Survived
Sex
female 233 任务2结果
male 109
Fare Survived
Sex
female 44.479818 233 合并结果
male 25.523893 109
记录一下自己踩的坑:
join() 和merge()都是只用于DataFrame数据结构中的,任务一任务二得到结果均为Series,不能直接用这两个函数连接。
此外,merge为公共列行连接,join为索引连接,在这里应该用join()
# 6 得出不同年龄的总的存活人数
age_survived = df.groupby(df['Age'])['Survived'].sum()
# 然后找出存活人数最高的年龄
max_age_survived = age_survived.sort_values(ascending=False).index[0]
print('不同年龄的总的存活人数:\n',age_survived.head())
print('存活人数最高的年龄为:',max_age_survived)
不同年龄的总的存活人数:
Age
0.42 1
0.67 1
0.75 2
0.83 2
0.92 1
Name: Survived, dtype: int64
存活人数最高的年龄为: 24.0
3 数据可视化
3.1 柱状图
主要学习了一下利用groupby()函数画柱状图和折线图~
# 任务1:男女中生存人数分布情况
import matplotlib.pyplot as plt
y = df.groupby(['Sex'])['Survived'].sum()
y.plot.bar()
plt.show()

从结果可以看出,性别对于存活率的影响还是比较大的,从数据上看大概两倍多了,大概因为lady first的优良美德吧(?)
# 任务2:男女中生存人与死亡人数的比例图
y = df.groupby(['Sex','Survived'])['Survived'].count().unstack()
y.plot.bar(stacked='True') #Stacked表示把生存与死亡堆叠在一起展示
plt.show()

同样印证了上述结论,女性无论从存活人数还是存活率都高出很多,Sex在预测中会是一个很重要的特征。
3.2 折线图
# 任务3:不同票价的人生存和死亡人数分布情况
fare_survived = df.groupby(['Fare'])['Survived'].value_counts()
# value_counts查看表格某列中有多少个不同值,即不同票价中死亡与存活人数各是多少
fare_survived.plot(grid=True) #grid=True添加网格线
plt.legend() #创建图例
plt.show()

# 对其进排序
fare_survived2 = df.groupby(['Fare'])['Survived'].value_counts().sort_values(ascending=False)
fare_survived2.plot(grid=True) #grid=True添加网格线
plt.legend() #创建图例
plt.show()

3.3 密度图
# 不同仓位等级的人年龄分布情况
df.Age[df.Pclass == 1].plot(kind='kde')
df.Age[df.Pclass == 2].plot(kind='kde')
df.Age[df.Pclass == 3].plot(kind='kde')
plt.xlabel("age")
plt.legend((1,2,3),loc="best")

# 不同年龄的人生存与死亡人数分布情况
import seaborn as sns
facet = sns.FacetGrid(df, hue="Survived",aspect=3)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, df['Age'].max()))
facet.add_legend() #加注释,绘制图例
plt.show()
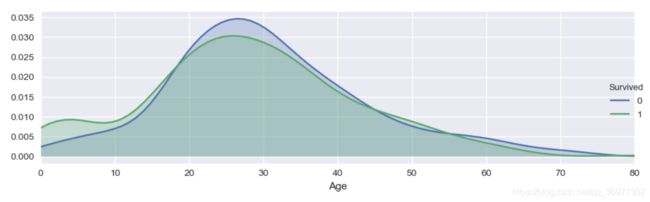
一直没找到上面这个图如何打印…尝试了一下居然可以plt.show()来打印…震惊子
查看资料得知seaborn是在matplotlib基础上进行封装得来的,大概是因为这个原因吧(?)
2020.8.21
TBC…