汉字风格迁移篇---汉字笔划提取、数据集和基准的实例分割
文章目录
- Abstract
- Introduction
- Related Work
- 建议的数据集
- 算法分析
- Conclusion
- 补充材料
-
- 笔划检测的更多分析
- 标准字体的更多可传输性结果
- 更多故障案例
- 有关先前方法的更多详细信息
- 有关下游任务的更多详细信息
- 字体生成
- 手写美学评估数据集。
- References
- References
Abstract
笔画是汉字的基本元素,笔画提取一直是一项重要而长期的工作。由于训练数据有限,现有的笔划提取方法通常是手工制作的,并且高度依赖于领域专业知识。此外,没有标准化的基准来提供不同笔画提取方法之间的公平比较,我们认为,这是发展汉字笔画理解和相关任务的主要障碍。在这项工作中,我们提出了第一个公开可用的汉字笔划提取(CCSE)基准,包括两个新的大规模数据集:Kaiti CCSE(CCSE-Kai)和手写CCSE(CC SE-HW)。利用大规模数据集,我们希望利用深度模型(如CNN)的表示能力来解决笔划提取任务,但这仍然是一个悬而未决的问题。为此,我们将笔划提取问题转化为笔划实例分割问题。使用所提出的数据集训练笔划实例分割模型,我们大大超过了以前的方法。此外,用所提出的数据集训练的模型有利于下游字体生成和手写美学评估任务。我们希望这些基准结果能够促进进一步的研究。
源代码和数据集可在以下网址公开获取:https://github.com/lizhaoliu-Lec/CCSE
Introduction
笔画是汉字的基本元素,笔画提取一直是一项重要而长期的努力(Lee和Wu 1998)。给定一个汉字图像,笔划提取旨在将其分解为单个笔划(见图1)。它是许多汉字相关应用的基础,例如手写体合成(刘和连,2021)、字体生成(姜等,2019;曾等,2021;谢等,2021)、字体转换(黄等,2020)、手写体美学评价(徐等,2007;孙等,2015)等,研究表明,明确整合笔划信息可以提高汉字相关任务的执行能力(高和吴2020;黄等人2020;曾等人2021)。虽然利用笔画信息的各种任务已经得到了社会的广泛关注,并通过应用目前最先进的深度模型取得了实质性进展,但仅对汉字笔画的理解还比较落后。
通常,有两行作品:从骨骼图像中提取笔画(Fan和Wu 2000;Liu、Kim和Kim 2001;Liu,Jia和Tan 2006;Su、Cao和Wang 2009;Zeng等人2010)和从原始图像中提取(Lee和Wu 1998;Yu、Wu和Yuan 2012)。对于基于骨架的方法,细化算法(Arcelli和Di Baja 1985)通常用作预处理步骤,这会引入笔划失真和短笔划的丢失。因此,提出了从原始图像中提取笔划来解决这些问题。这种方法通常具有丰富的信息,如笔划宽度和曲率,从而获得良好的性能。最新的研究(Xu et al.2016)提出通过在骨架上找到交叉点并结合原始图像上的笔划片段来结合两个世界的优点。然而,由于缺乏大规模数据集来开发基于学习的方法,大多数以前的方法都是基于规则的,在算法设计过程中需要深入的专业知识。因此,它们固有地受到以下限制:首先,要将字符分解为笔划段,需要手工规则来找到分区arXiv:2210.13826v1[cs.CV]2022年10月25日的点,由于复杂的字符结构,这些点不可避免地包含分叉点。其次,这些方法通常是针对规则和高度结构化的标准字体而定制的,并且由于不同的手写习惯导致的笔划的类内差异较大,因此可能无法很好地处理手写字符。最后,他们的目标是仅优化笔划提取任务,而可能不会产生可转移的特征以利于下游任务。

【图1:(a)本文所考虑的25种汉字笔画的插图,它们是汉字的基石。(b) 汉字笔画提取任务的图示。给定一个汉字,笔画提取任务要求模型将汉字分解为单个笔画。】
此外,没有标准化的基准来提供不同笔画提取方法之间的公平比较,这对于指导和促进进一步研究非常重要。缺乏公开可用的数据集导致评估协议不一致。具体而言,(Cao and Tan 2000;Qiguang 2004;Xu et al.2016)将准确度视为笔划提取任务的主要评估指标,其未考虑提取笔划的空间位置,因此无法全面衡量笔划提取算法的性能。(Chen等人,20162017)分别利用汉明距离和切割差异来测量笔划内部的一致性和笔划边界的相似性。它们要求提取的笔划和地面真实笔划严格按照空间位置和类别对齐,这很难评估遗漏和错误提取。因此,如何有效地评估具有合理协议的笔画提取算法仍然是一个未解决的问题。
为了促进笔划提取研究,我们提出了一个汉字笔划提取(CCSE)基准,包括两个新的大规模数据集和评估方法。作为CCSE基准的基础,数据集有两个要求:即字符级多样性和笔划级多样性。具体而言,数据集应包含尽可能多的汉字,以表示笔画之间的结构,笔画之间关系可能非常复杂(见图2的左侧)。此外,由于具有不同书写习惯的人即使对于同一笔划也会产生非常不同的外观(见图2的右侧),因此数据集应涵盖模型的这种多样性,以实现有效提取。为此,我们收集了大量的楷体(一种中文字体)汉字图像和手写汉字图像,以分别实现字符级多样性和笔划级多样性。
利用大规模数据集,我们希望利用深度模型(如CNN)的表示能力来解决笔划提取任务,但这仍然是一个悬而未决的问题。为此,我们将笔划提取问题转化为笔划实例分割问题。这种观点的改变不仅允许我们利用最先进的实例分割模型,而且还允许我们利用定义良好的评估度量(即,框AP和掩码AP)。我们使用最先进的实例分割模型进行实验,以产生便于进一步研究的基准结果。与以前的笔画提取方法相比,我们的方法不需要参考图像和深入的领域专业知识。此外,在我们的数据集上训练的深度模型能够产生可转移的特征,这些特征始终有利于下游任务。
我们将我们的贡献总结如下:
1、我们提出了包含两个高质量大规模数据集的第一个基准,这些数据集满足字符级和笔划级多样性的要求,用于构建有前景的笔划提取模型。
2、我们将笔划提取问题转化为笔划实例分割问题。通过这种方式,我们构建了深度笔画提取模型,该模型可扩展到具有高度多样性的字符和笔画差异的场景,同时产生可转移特征,以利于下游任务。
3、通过利用最先进的实例分割模型和定义良好的评估指标,我们建立了标准化的基准,以促进进一步的研究。
Related Work
Stroke Extraction
笔划提取旨在从手写图像中提取笔划(Lee和Wu 1998),由于复杂的字符结构(Cao和Tan 2000)和较大的类内方差(Xu等人,2016),这很难解决。现有的方法主要遵循从骨架化字符或原始字符范例中提取笔划。对于第一种方法,通过解决分叉点问题(Fan和Wu 2000)、将仿射变换应用于笔划(Liu、Jia和Tan 2006)、检测模糊区域(Su、Cao和Wang 2009)和使用附加参考图像(Zeng等人,2010),努力探索笔划之间的关系。然而,这些方法受到细化步骤的限制,细化步骤会导致笔划失真和短笔划的丢失。因此,提出了从原始图像中提取笔划来克服这一限制。这些方法侧重于通过组合笔划中的多个轮廓信息(Lee和Wu 1998)、探索像素笔划关系(Cao和Tan 2000)、检测多个方向的笔划(Su和Wang 2004)和使用角点(Yu、Wu和Yuan 2012)来利用字符中的丰富信息,如笔划宽度和曲率。最新的方法(Xu等人,2016)考虑了两个方面的优势,以进一步提高性能。尽管如此,这些方法通常仅在算法设计期间使用手工规则来改进笔划提取任务。因此,它们固有地遭受从复杂字符和高度不规则形状中提取笔画的痛苦。此外,它们不能被琐碎地用于诸如字体生成之类的下游任务,从而限制了它们的进一步应用。
Instance Segmentation
实例分割的目标是通过为图像中的每个实例(可计数对象)分配像素级标签来分割。现有方法大致可分为两类:两阶段(He等人,2017;Hsieh等人,2021)和一阶段(Bolya等人,2019)。两种方法包括实例检测和分割步骤。在计算机视觉中最重要的里程碑之一Mask R-CNN(He et al.2017)中,分割头应用于Faster R-CNN检测器(Ren et al.2015)检测到的实例,以获取实例分割掩码。基于掩码RCNN的方法通常需要密集的事先提案或锚来获得良好的结果,从而导致复杂的标签分配和后处理步骤。为了解决这个问题,YOLACT(Bolya等人2019)等单阶段方法通过将原型与掩模系数线性组合来产生实例掩模,而不依赖于预检测步骤。在本文中,我们受益于实例分割算法的快速发展,并专注于应用实例分割模型来处理笔划提取任务,因此我们主要考虑研究良好的两阶段方法,如Mask R-CNN作为我们的基线。

图2:CCSE-Kai数据集和CCSE-HW数据集中带注释的汉字样本,从左至右。
建议的数据集
图像采集和注释
为了实现有希望的笔画提取性能,我们收集了大量样本,这些样本涵盖了汉字的复杂结构和笔画的不同风格,分别是字符级别和笔画级别的多样性。由于频繁使用的汉字限制在很小的范围内,因此可能没有足够的笔画结构复杂的手写字符。因此,我们收集了常用的标准字体(例如Kai-Ti),以满足字符级别的多样性要求。然后,为了满足笔画水平的多样性,我们收集来自不同作家的手写汉字图像。我们将在下面详细介绍收集和注释的过程。
楷体图像采集与注释
为图像中的每个笔划添加标签既耗时又费力。由于Kai-Ti是日常生活中常用的标准中文字体,我们首先想到的是通过从字体设计数据库中检索空间信息来收集无注释的Kai-Ti数据集。但是,在字体设计过程中不会保留每个笔划的坐标。因此,我们广泛浏览了网络资源,发现了一个开源项目Make Me A Hanzi1,该项目为Kai Ti构建了一个笔画数据库。然后,这个项目通过cnchar2进一步发展,提供了更友好的界面,可以逐笔访问Kai Ti的图像。如图3所示,cnchar的结果具有清晰的笔划方向标记,浅棕色表示当前笔划的空间掩码和类别。关于笔划类别,cnchar的数据库包含最常用的25个类别(详见图1(a))。
https://github.com/theajack/cnchar
https://github.com/skishore/makemeahanzi

图3:Kai Ti图像采集过程示意图。我们使用开源字符渲染库cnchar以笔划增量方式生成汉字图像。字符ya是一笔画一笔画地书写的,笔画在图像中以浅棕色突出显示,笔画类在下面表示。

图4:笔划可分离和笔划不可分离手写体的比较。相应的楷体字符放在左边以供参考。
在cnchar的帮助下,我们从9523个独特的楷体汉字中获取笔画图像。然后,我们使用OpenCV3从浅棕色区域生成边界框和遮罩注释,从而生成我们的Kaiti CCSE(CCSE Kai)数据集。CCSE-Kai的可视化结果如图2左侧所示。我们可以看到,CCSE-Kai提供了具有复杂笔划结构的样本。CCSEKai中有超过100万例中风病例,详细统计数据将在后面详述。我们的CCSE Kai的优点如下:1)我们发现了一种自动化方法,可以在不需要大量人力的情况下有效地生成中风实例数据集。2) CCSE Kai通过覆盖大多数汉字(尽管使用频率很高)来满足字符级别的多样性。然而,它的缺点是显而易见的:由于标准字体库中的笔划相对固定,因此缺乏笔划级别的多样性。从这个意义上讲,使用CCSE Kai训练的模型在某些应用场景中可能无法提供令人满意的结果,在这些应用场景中需要从手写汉语中提取笔画。
手写图像采集与注释
由于CCSE Kai仅满足字符级别的多样性,我们的目标是通过利用具有各种样式的手写字符来提高数据集的笔划级别的多样。为此,我们进一步收集手写汉字,并以笔划实例的方式标记它们。具体而言,我们利用CASIA离线中文手写体数据集拥有约300人反复书写的7185种汉字,产生了近300万张手写汉字图像。
然而,如图4所示,一些人类作家绘制了一个笔划不可分离的字符,这在笔划提取任务中无法轻松处理。为了解决这个问题,我们对可与CASIA分离的笔划数据进行了子采样。此外,考虑到人类注释是劳动密集型和耗时的,我们为前300个最常用的汉字选择了10个样本,为后700个汉字选择了8个样本,总共产生了约7600个图像。然后,我们应用大量的人力仔细地为每个笔划提供注释,并最终创建手写CCSE(CCSE-HW)数据集。请注意,我们在笔划注释过程中采用了CCSE Kai中使用的笔划类别。CCSE-HW的可视化结果如图2右侧所示,从中我们可以看到,同一类别的笔划在尺度、覆盖范围和曲率等方面表现得非常不同。到目前为止,我们通过补充笔划级别的多样性来克服CCSE-Kai的缺点。通过CCSEKai和CCSE-HW,我们提供了具有丰富字符和笔划水平多样性的数据集,以有效和合理地构建我们的基准。
数据集统计
在本节中,我们分析了建议的CCSE-Kai和CCSE-HW数据集的属性。我们首先在数量和注释类型方面将数据集与现有数据集进行比较。然后,我们分析了提出的数据集和数据集中出现的固有困难。
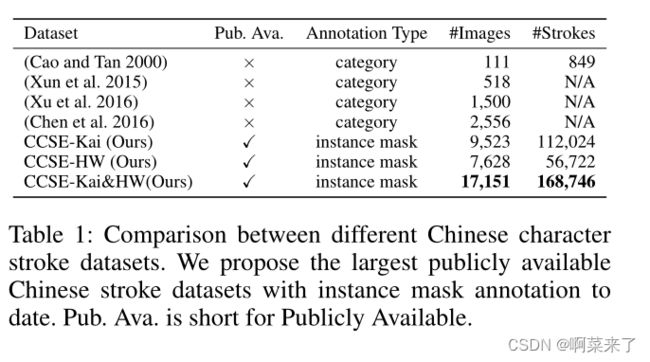
表1:不同汉字笔画数据集之间的比较。我们提出了迄今为止最大的具有实例掩码注释的公开可用中文笔划数据集。酒吧艾娃。是Publicly Available的缩写。
与现有数据集的比较
我们分析了提议的数据集的大小,并与中国笔画提取的几种常用数据集(Cao和Tan 2000;Xun等人2015;Xu等人2016;Chen等人2016)进行了比较。总结如表1所示。与之前最大的图像相比,我们有大约4倍的图像量(例如,9523对2556)。值得注意的是,与仅提供类别级标签的现有数据集不同,我们为每个笔划提供了实例级掩码,其中包含详细的空间和形状信息。最重要的是,我们是第一个为笔划提取提供公开可用数据集的公司,促进笔划提取和下游任务的公平比较。

表2:掩模R-CNN和级联掩模R-CNN的实验结果。D是Dataset的缩写。K和H分别是CCSE-Kai和CCSE-HW的缩写。

图5:CCSE-HW和CCSE-Kai数据集中中风实例的统计数据。
CCSE-Kai和CCSE-HW分析
我们主要从实例级别和类别级别对数据集进行定量分析。结果如图5所示。从图5a和图5b中,我们观察到CCSEKai在一幅图像中平均提供了更多的笔划,正如我们所预期的那样,因为复杂的笔划结构通常在一个字符中引入更多的笔画和类别。这表明CCSE Kai确实改进了我们基准数据集的字符级别多样性。此外,如图5c所示,我们发现CCSE-HW在图像中覆盖的范围更广,这表明手写字符能够通过包括不同尺度的笔划来改善笔划级别的多样性。这些结果验证了我们的数据集满足了实现有希望的笔划提取性能的多样性要求。
然后,我们通过分析每个类别的笔划数和边界框的尺度统计来揭示数据集的内在困难,结果分别如图6和图7所示。从图6中,我们观察到笔画提取任务面临严重的类别不平衡问题,这可能导致对数据点较少的笔画进行分类的性能受到阻碍。此外,我们还从图7中发现:1)笔画通常是条形的,这是与普通物体检测的主要区别。2) 笔划的形状也会出现类不平衡问题,使得很难定位具有非常条形的笔划。解决这些困难超出了本文的范围,我们将其留给未来的工作。
图6:CCSE-HW和CCSE-Kai中每个类别的注释实例数。

图7:我们提出的两个数据集中边界框比例的累积分布直方图。
算法分析
基线
为了构建笔划检测基线5,我们考虑了广泛使用的检测器Faster R-CNN(Ren等人,2015)、Cascade R-CNN和FCOS(Cai和V ascencelos 2018)。为了构建笔划实例分割基准结果,我们使用了Mask R-CNN(He等人,2017)及其级联版本(Cai和V asconcelos 2018)。笔划实例分割工作流的概述如图8所示。为了简单起见,我们使用K和H分别表示CCSE-Kai和CCSE-HW数据集。
实施细节。我们的实现基于detectron2(Wu等人,2019)框架。由于图像分辨率低,我们的数据集的训练成本很低,因此我们默认应用3×训练计划。所有实验在单个Titan XP GPU上执行。对于每个迭代,从{112120}中随机选择最小训练图像大小。对于边界框回归,我们默认使用广义IoU损失。至于其他超参数和模块选择,我们遵循detectron2中的默认设置。掩码R-CNN用作我们的默认笔划实例分割模型。对于train/val/test 分区,我们以9:1:1的比例随机划分CCSE-Kai和CCSE-HW。

图8:笔划提取任务的笔划实例分割模型概述(使用掩码R-CNN进行说明)。
Stroke Instance Segmentation笔划实例分割
主要结果在本节中,我们介绍了笔划实例分割的结果。定量结果见表2。我们还提供了图9中的定性结果。如表2所示,我们在CCSE-Kai和CCSE-HW的中风实例分割方面取得了有希望的结果。CCSE Kai的AP掩码较低。我们将其归因于CCSE Kai中笔画高度重叠的复杂字符。它可以通过裁剪具有复杂特征结构的模型来进一步改进。值得注意的是,如图9所示,我们能够产生具有高置信度的笔划实例分割结果,这表明了我们的数据集的有效性,并将实例分割应用于笔划提取。由于篇幅有限,我们将失效案例分析放在补充部分。

图9:CCSE结果在CCSE-Kai和CCSE-HW上使用了掩码R-CNN。放大的最佳视图。
标准字体的可转移性结果
一个人可能会问,所提出的数据集是否可以包含更多打印字体样式的字符图像,这些字体样式也是笔划可分离的。简单地标记更频繁使用的打印字体样式可以实现这一目标,但也会耗时费力。考虑到常用字体样式(如Kai-Ti、Song Ti、Hei Ti)的结构和外观高度相似,因此我们利用CCSE Kai数据集训练的模型来自动标记其他字体样式的字符图像。如图106所示,调整边界框和遮罩以使用由我们的CCSE-Kai训练的模型导出的标签需要很小的努力。

图10:在Kai-Ti数据集上训练模型的宋体、黑体笔划提取结果。

图11:从左到右,分别向CCSE-Kai和CCSE-HW的样本添加噪声背景。
背景的影响
由于所提出的数据集没有背景,因此在此设置下训练模型可能不适合具有噪声背景的实际应用。因此,我们进行实验来验证和纠正这个问题。如图11所示,我们将复杂背景添加到角色图像7中,并使用它们来测试用原始数据集训练的模型。如表3所示,性能显著下降。为了弥补这一点,我们建议用复杂的背景增强图像训练模型,这大大提高了性能。

表3:掩模R-CNN在具有复杂背景的图像上的实验结果。BG表示向数据集中的图像添加复杂背景。
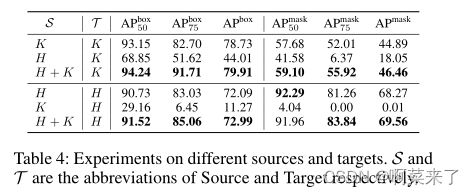
表4:不同来源和目标的实验。S和T分别是Source和Target的缩写。

表5:(Xu et al.2016)中的传统笔划提取方法与我们的笔划实例分割方法之间的比较,通过准确度、精度、召回率和F1。Ks和Hs分别是来自K和H的100个随机采样数据点的子集。K∗s表示K中笔划最多的100个数据点。
跨域评估
为了评估训练笔划提取模型的鲁棒性,我们在跨域设置下进行了实验。具体而言,我们在源(S)训练集上训练模型,并在目标(T)测试集上评估模型。因此,如表4所示,我们用(S,T)∈ {(H,K),(K,H)}。跨域评估结果表明,由于字符水平和笔划水平差异不匹配导致的域差异,该模型无法提供令人满意的性能。因此,我们提出了一种简单的补救方法,通过组合源和目标数据集来训练模型。通过这种方式,与仅使用一个数据集相比,总体性能得到了改进。我们认为有一种更有效的数据方式来解决领域差异问题,如无监督的领域适应(Ganin和Lempitsky 2015)。
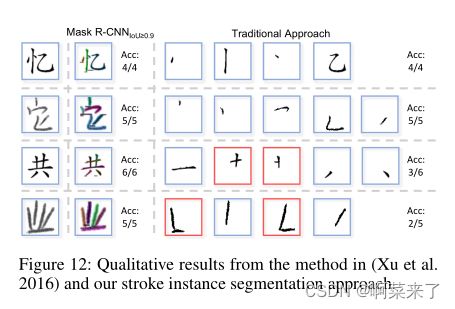
图12:(Xu et al.2016)中的方法和我们的笔划实例分割方法的定性结果。
与先前方法的比较
实验协议
以前的大多数方法(Sun、Qian和Xu,2014;Xu等人,2016)只能在提取的中风位置上提供结果,而没有相应的类别。这样,在无法访问外部数据库的情况下,他们只能用人类评估对100张图像进行结果基准测试(Sun、Qian和Xu,2014)。具体而言,给定提取的笔划图像,要求人类评估提取的结果是否包含期望的笔划。然后,准确性被用作评估标准对比。我们还提供了准确度、召回率和F1得分方面的结果,以进行更全面的评估。
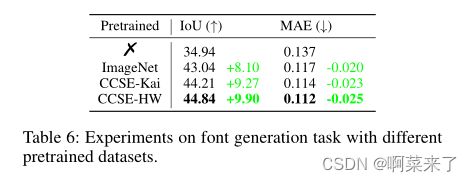
表6:使用不同预训练数据集进行字体生成任务的实验。
定量结果
我们在表5中报告了最新的传统笔划提取方法(Xu等人,2016)与我们的笔划实例分割方法之间的比较。由于传统方法在正确识别笔划时产生完美的位置匹配,因此我们设置了高IoU阈值,即。,0.9,并且具有高于0.9的IoU重叠的提取笔划被认为是正确提取的。我们有以下观察:首先,传统方法在K∗s大于Ks,这表明它们在处理具有复杂结构的字符方面的局限性。其次,传统的方法比Kai-Ti数据集Ks更难识别手写数据集Hs中的字符,这表明具有高方差的笔划对这项任务构成了一个不小的挑战。最后,在所有数据集上(即K∗s、Ks和Hs),我们的笔划实例分割方法在所有度量下都大大超过了以前的方法。请注意,0.9是标准实例分割文献中非常高的IoU阈值(He等人,2017;Wu等人,2019)。当我们降低IoU阈值时,我们观察到更显著的收益。在高IoU阈值下提高笔划实例分割性能是一项具有挑战性的任务。
定性结果
我们在传统方法(Xu et al.2016)和图12中的方法之间进行了定性比较。我们观察到:1)传统方法可以很好地提取可分离和规则笔划(图12中第1-2行)。2) 他们很难从结构复杂或形状不规则的字符中提取笔画(图12中的第3-4行)。与它们不同,我们可以很好地处理这些情况,证明了所提出的数据集和中风实例分割方法的有效性。
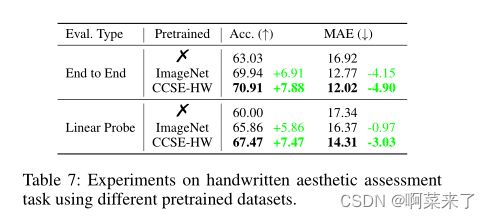
表7:使用不同预训练数据集的手写美学评估任务实验。
将功能转移到下游任务
字体生成
我们研究我们训练的特征是否可以转移到字体生成任务中(姜等人,2019;刘和连,2021)。我们使用fontRL(Liu和Lian,2021)进行实验,fontRL使用笔划边界盒网络(BBoxNet)在角色渲染之前将角色的每个笔划放置在所需位置。因此,我们使用不同的预训练模型来初始化BBoxNet,结果如表6所示。IoU和MAE分别用于评估生成的字体和GT字体之间的结构对齐和外观差异。使用在我们的数据集上预训练的模型,我们获得了比其他预训练模型更好的性能,尤其是在IoU上,这表明我们的预训练模型能够更好地理解字符结构,从而促进这项任务。
手写美学评估
我们使用不同的预训练模型研究了这项任务(Sun等人,2015)。给定手写字符图像,该任务要求模型输出分类结果(从好、中和坏)和回归结果(从0到150),以指示手写体的美学水平。我们使用不同的预训练模型初始化ResNet-50。此外,我们还使用了线性探测协议,该协议冻结了预训练模型,并训练分类和回归层,以进一步检查特征的有效性。在表7中,用我们的CCSE-HW数据集预处理的模型比用ImageNet预处理的具有超过1M张图像的模型表现得好得多,这表明具有领域特定字符结构知识的紧凑数据集比大规模通用视觉数据集更适合于手写美学评估任务。
Conclusion
在这项工作中,我们提出了第一个大规模汉字笔划提取(CCSE)基准,以改进笔划提取任务并促进进一步研究。为此,我们毫不费力地采集了大量汉字图像,并为它们提供笔划级注释,以创建CCSE-Kai和CCSE-HW数据集。所提出的数据集满足字符级和笔划级的多样性,以实现有前景的笔划提取。我们对所提出的数据集的特性进行了一系列分析,并指出了它们的内在困难。最后,我们对笔画实例分割模型进行了大量的实验,以分析产生有希望的结果的影响因素,并表明预训练模型与提出的数据集有利于下游任务。我们未来的工作将集中在提高严格IoU条件下的笔划分割性能。
补充材料
我们将补充材料整理如下。
在“笔划检测的更多分析”一节中,我们对中风检测过程进行了详细分析。
•在“标准字体的更多可转移性结果”一节中,我们提供了其他标准字体的更定性结果。
•在“更多失败案例”一节中,我们提供了关于中风实例分割的更多失败案例。
•在“先前方法的更多细节”一节中,我们提供了先前笔划提取方法的更多详情(Xu等人,2016)。
•在“下游任务的更多细节”一节中,我们提供了下游任务的实验细节,即实验设置、评估指标和更多结果。
•在“背景效应的更多结果”一节中,我们提供了背景效应的定性结果
笔划检测的更多分析
由于我们采用Mask R-CNN(He et al.2017)模型进行笔划实例分割,该模型首先执行笔划检测,然后进行分割,因此我们通过调整重要的超参数来分析Faster R-CNN的笔划检测过程(Ren et al.2015)(Mask R-CNN的检测部分):阶段数、锚框、主干和图像分辨率。
阶段数的影响
在本节中,我们将对广泛使用的一级、两级和多级检测器进行实验,以了解它们在我们提出的数据集上的性能。结果如表1所示。请注意,我们将级联R-CNN的级数设置为3,得到了4级模型(RPN贡献1级)。结果表明,随着阶段数的增加,我们获得了更好的笔划检测结果。
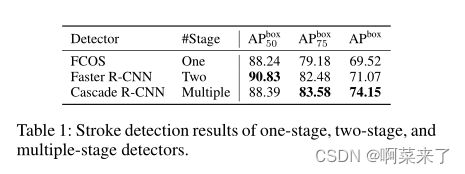
表1:单级、两级和多级探测器的中风检测结果。
锚箱的作用
如先前的研究所示(Ren等人,2015),锚箱的比率对最终结果有很大影响。由于笔划的条形特性,我们分析了锚盒的选择如何影响笔划检测性能。具体而言,我们逐渐将具有较高比率的锚定框添加到Faster RCNN中。结果如表2所示,这表明采用更高比率的锚箱确实提高了行程检测性能。
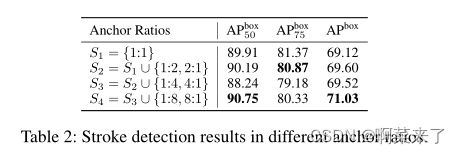
表2:不同锚定比的笔划检测结果。
图像分辨率的影响
目前,大多数探测器是在COCO(Lin等人,2014)基准上评估的,该基准具有相对较大的图像分辨率,即(800∼1000). 然而,汉字图像的分辨率通常较小,即(80∼120). 目前尚不清楚探测器是否受到图像分辨率的影响。因此,我们提供了不同分辨率的实验,以观察其效果。具体而言,我们在将短尺寸调整为{112、120}、{224、240}和{448、480}之一的同时应用相等缩放策略,以查看Faster R-CNN检测器的性能。请注意,我们还相应地缩放锚定框。在表3中,我们实现了分辨率为{448480}的最佳APbox,但也带来了更高的计算成本。
骨干的影响
我们为Faster R-CNN提供了不同主干设置的实验,以展示它们如何影响最终性能。具体而言,我们考虑两种设置,例如,不同的主干架构和在ImageNet上预训练或未预训练(Deng等人,2009)。对于主干架构,我们使用ResNet-{50101}(He等人,2016)和FPN{50101}(Lin等人,2017)。表4显示了实验结果,表明预训练和更深层次的模型提高了性能。
标准字体的更多可传输性结果
在图1中,我们展示了其他标准字体样式的更多可移植性结果。具体来说,我们利用CCSE-Kai数据集训练的模型来自动标记其他字体样式的字符图像。由于源字体样式(即Kai-Ti),大多数结果都具有竞争优势。我们将这种强大的表现归因于这些字体样式所共享的高度相似的笔划样式。我们注意到,在某些情况下,除Kai-Ti之外的笔划提取是不准确的。我们认为,这可以通过弱监督实例分割方法解决(Zhou等人,2018),因为在不同字体样式中,每个字符的笔划类别和笔划组成是相同的。我们把它留给未来的工作。

图1:使用在Kai-Ti数据集上训练的模型,Kai-Ti、Li-Ti、Hei-Ti、You Yuan、Song-Ti风格的笔划提取结果。放大的最佳视图。
更多故障案例
我们在中风实例分割模型中分析了更多的失败案例。在图2中,我们观察到以下情况可能导致笔划提取失败:
(1)两个单独的笔划连接,因此类似于另一个笔划。如图2a所示,shu和heng之间的联系恰好与heng zhe相似;
(2) 由错误的超参数选择(如高置信度分数)导致的漏检(图2b);
(3) 有些笔画非常相似,有时无法区分,如图2c中的舒婉和舒体;
(4) 一个笔划被检测为多个笔划,如图2d所示;
(5) 笔划具有细长的形状,如图2e所示;
(6) 如图2f所示,由于另一笔划的遮挡,一个笔划的一小部分被错误检测到。我们相信,通过将笔画实例分割模型与更多的字符结构信息和笔画之间的出现关系结合起来,可以解决这些问题。

表3:不同图像分辨率的实验。

表4:不同骨干的中风检测结果以及是否经过预训练。
有关先前方法的更多详细信息
我们在图3中提供了最新的传统笔画提取方法ACSE(Xu等人,2016)的工作流程,该方法包括三个步骤:字符分解、跨区域提取和基于斜率的笔画组合。在ACSE中,字符首先根据连接性分解为几个独立的组件。然后,提取骨架和轮廓以计算交叉点集和终点集。如果骨架的交叉点集为空,则相应的笔划将直接输出为简单笔划。根据交叉点集和终点集,每个组件被分成若干笔划段。最后,如果多个笔划段共享相似的坡度,则将它们组合为一个笔划。
有关下游任务的更多详细信息
在本节中,我们将详细介绍如何将在建议的CCSE-Kai和CCSE-HW数据集上预训练的模型用于下游字体生成和手写美学评估任务。
字体生成
数据集。按照之前的方法(刘和廉,2021),我们在数字手写字体FZJHSXJW上执行字体生成任务。训练集包括775个汉字和7004个笔画。测试集包含6763个汉字中,有注释的笔划骨架和相应的平均字体样式。为了评估,首先将生成的字体和GT字体转换为二进制掩码,其中1表示带有笔划的像素,0表示背景。然后将生成的字体和GT字体之间的并集交集(IoU)和平均绝对误差(MAE)用作度量
**实施细节。**我们利用(Liu和Lian,2021)中的fontRL作为基线方法,测试不同预训练数据集的字体生成性能。
字体生成过程如下:
给定平均字体样式的笔划轨迹,
1)应用修改参数网络(MPNet)将其弯曲成目标字体样式的描画轨迹;
2) 边界框预测网络(BBoxNet)用于预测画布中弯曲笔划的位置;
3) 对所有笔划重复上述过程以形成目标字体的完整骨架;
4) 最终采用图像渲染模块(IRM)以图像到图像转换方式将完整骨架转换为字形字体图像。MPNet、BBoxNet和IRM按顺序进行训练。我们通过使用从不同数据集预训练的参数初始化BBoxNet进行实验:None、ImageNet(Deng等人,2009)、我们的CCSE-Kai和CCSE-HW,同时保持其他模块相同。L1损耗用作训练BBoxNet的损耗函数。对于优化,我们使用lr=1e的Adam优化器−前100个时期为4,lr=1e−过去50个时代为5。其他实验方案严格符合(刘和廉,2021)。
结果我们在图4中提供了关于训练损失、测试IoU和测试MAE的训练过程的演变。我们有以下观察结果:首先,在没有数据集进行预训练的情况下,训练损失的收敛速度缓慢且非常不稳定。其次,具有预训练数据集的所有模型都能够提供快速但不一定稳定的(即ImageNet)收敛。第三,用我们的CCSE-Kai和CCSE-HW预训练的模型不仅提供了快速和稳定的收敛,而且大大提高了IoU度量。这表明,通过提供有效的字符结构信息而不是一般的视觉特征,我们具有10K图像的数据集可以在该任务中胜过具有1M图像的更大的ImageNet数据集。

图2:更多故障案例。第一行是笔划实例分割结果,第二行是地面实况。放大的最佳视图。
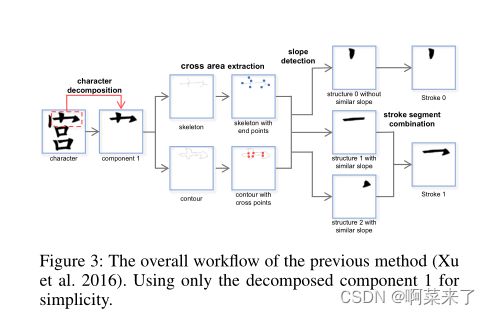
图3:先前方法的总体工作流程(Xu等人,2016)。为了简单起见,仅使用分解的组件1。
手写美学评估数据集。
数据集。我们使用来自(Sun et al.2015)的中国手写美学评估数据集(CHAED),该数据集由1000张图像组成,每100个汉字中有10张。奇数和偶数图像分别用于训练和测试。每个图像由33人标记,从3个级别中选择一个:好、中、坏。对于每个图像,用pgood、pmedium和pbad表示将其标记为好、中和坏的人数。最终分类标签由arg maxi pi,i计算∈ {好、中、坏}。此外,美感得分按100×好+50×中+0×差计算。

图4:使用不同预训练模型的字体生成任务的结果。从左到右:(a)训练损失,(b)并集上的测试交集,(c)测试平均绝对误差。

图5:使用不同预训练模型的手写美学评估任务的结果。从左到右:(a)美学分类任务的训练损失,(b)美学分类的测试准确性,(c)美学回归任务的训练损耗,(d)美学回归的测试平均绝对误差。
**实施细节。**对于模型架构,我们使用ResNet-50作为具有不同预处理数据集的特征提取器,即None、ImageNet(Deng等人,2009)和我们的CCSE-HW。我们删除了在ImageNet或None中预训练的模型的原始1000类分类层。在CCSE-HW中预训练后,我们将FCN检测器头和分割头放在Mask RCNN中。通过这种方式,ResNet50用于生成R2048中的特征向量。最后一个分类层和回归层是随机初始化的完全连接层。我们分别利用推土机距离损失(Talebi和Milanfar 2018)和平滑-1损失作为美学分类任务和回归任务的目标函数。为了优化,我们使用SGD优化器,其中(lr,权重衰减,动量)=(5e−3、1e−2、9e−1). 我们对所有模型进行120个周期的训练,学习率每40个周期衰减0.1。我们使用批量大小=64。对于图像增强,在训练和测试期间分别应用随机五次裁剪和中心裁剪到224×224的大小。
结果我们在图5中提供了关于分类训练损失、回归训练损失、测试精度和测试平均绝对误差(MAE)的端到端训练过程的演变。与在None和ImageNet上预训练的模型相比(Deng等人,2009),在我们的CCSE-HW上预训练后的模型收敛更稳定、更快,在测试精度和MAE方面取得了比它们更好的结果。这些结果验证了使用我们的数据集预训练模型能够有利于下游手写体美学评估任务,证明了我们的数据集合和所提出的笔划实例分割模型的有效性。我们相信有一种更有效的方法来改进下游任务,我们将其留给未来的工作。
关于背景效果的更多结果
为了评估加入CCSE-Kai和CCSE-HW的背景的效果,我们进行了更多的实验。我们利用利用纯数据集和复杂背景增强数据集训练的模型来评估它们在噪声图像上的性能。在图6中,当使用在纯CCSE-Kai和CCSEHW上训练的模型时,我们毫不意外地发现在复杂背景上存在大量错误检测。我们推测这是因为复杂的背景包含笔划状结构和一些颜色干扰,这在训练阶段没有考虑在内。为了弥补这一点,我们建议用复杂的背景增强图像来训练模型。如图6所示,性能得到了大幅提升。可以看出,该模型可以显著减少误检。这进一步证明了我们的数据集是适用于现实世界的,只需付出很少的努力。

图6:从左到右,“纯”:没有添加复杂背景。“+BG”:添加复杂背景。“TrainedPure”:用于推理的模型是用纯数据集训练的。“Trained+BG”:用于推理的模型使用复杂的背景增强数据集进行训练。放大的最佳视图。
References
Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; and Fei-
Fei, L. 2009. Imagenet: A large-scale hierarchical image
database. In CVPR, 248–255.
He, K.; Gkioxari, G.; Dollár, P .; and Girshick, R. 2017. Mask
r-cnn. In ICCV, 2961–2969.
He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual
learning for image recognition. In CVPR, 770–778.
Lin, T.-Y .; Dollár, P .; Girshick, R.; He, K.; Hariharan, B.;
and Belongie, S. 2017. Feature pyramid networks for object
detection. In CVPR, 2117–2125.
Lin, T.-Y .; Maire, M.; Belongie, S.; Hays, J.; Perona, P .; Ra-
manan, D.; Dollár, P .; and Zitnick, C. L. 2014. Microsoft
coco: Common objects in context. In ECCV, 740–755.
Liu, Y .; and Lian, Z. 2021. FontRL: Chinese Font Synthesis
via Deep Reinforcement Learning. In AAAI, 2198–2206.
Ren, S.; He, K.; Girshick, R. B.; and Sun, J. 2015. Faster
R-CNN: Towards Real-Time Object Detection with Region
Proposal Networks. 91–99.
Sun, R.; Lian, Z.; Tang, Y .; and Xiao, J. 2015. Aesthetic Vi-
sual Quality Evaluation of Chinese Handwritings. In IJCAI,
2510–2516.
Talebi, H.; and Milanfar, P . 2018. NIMA: Neural image as-
sessment. TIP, 27: 3998–4011.
Xu, Z.; Liang, Y .; Zhang, Q.; Dong, L.; and Izquierdo, E.
2016. Decomposition and matching: Towards efficient auto-
matic Chinese character stroke extraction. In VCIP, 1–4.
Zhou, Y .; Zhu, Y .; Y e, Q.; Qiu, Q.; and Jiao, J. 2018. Weakly
supervised instance segmentation using class peak response.
In CVPR, 3791–3800.
References
Arcelli, C.; and Di Baja, G. S. 1985. A width-independent
fast thinning algorithm. TPAMI, 7: 463–474.
Bolya, D.; Zhou, C.; Xiao, F.; and Lee, Y . J. 2019. YOLACT:
Real-Time Instance Segmentation. In ICCV, 9156–9165.
Cai, Z.; and V asconcelos, N. 2018. Cascade R-CNN: Delv-
ing Into High Quality Object Detection. In CVPR, 6154–
6162.
Cao, R.; and Tan, C. L. 2000. A model of stroke extraction
from chinese character images. In ICPR, 368–371.
Chen, X.; Lian, Z.; Tang, Y .; and Xiao, J. 2016. A bench-
mark for stroke extraction of chinese characters. Acta Sci-
entiarum Naturalium Universitatis Pekinensis, 52: 49–57.
Chen, X.; Lian, Z.; Tang, Y .; and Xiao, J. 2017. An Auto-
matic Stroke Extraction Method using Manifold Learning.
In Eurographics, 65–68.
Fan, K.-C.; and Wu, W.-H. 2000. A run-length-coding-based
approach to stroke extraction of Chinese characters. PR, 33:
1881–1895.
Ganin, Y .; and Lempitsky, V . 2015. Unsupervised domain
adaptation by backpropagation. In ICML, 1180–1189.
Gao, Y .; and Wu, J. 2020. GAN-Based Unpaired Chinese
Character Image Translation via Skeleton Transformation
and Stroke Rendering. In AAAI, 646–653.
He, K.; Gkioxari, G.; Dollár, P .; and Girshick, R. 2017. Mask
r-cnn. In ICCV, 2961–2969.
Hsieh, T.-I.; Robb, E.; Chen, H.-T.; and Huang, J.-B. 2021.
Droploss for long-tail instance segmentation. In AAAI,
1549–1557.
Huang, Y .; He, M.; Jin, L.; and Wang, Y . 2020. RD-GAN:
few/zero-shot chinese character style transfer via radical de-
composition and rendering. In ECCV, 156–172.
Jiang, Y .; Lian, Z.; Tang, Y .; and Xiao, J. 2019. Scfont:
Structure-guided chinese font generation via deep stacked
networks. In AAAI, 4015–4022.
Lee, C.; and Wu, B. 1998. A Chinese-character-stroke-
extraction algorithm based on contour information. PR, 31:
651–663.
Liu, C.-L.; Kim, I.-J.; and Kim, J. H. 2001. Model-based
stroke extraction and matching for handwritten Chinese
character recognition. PR, 34: 2339–2352.
Liu, X.; Jia, Y .; and Tan, M. 2006. Geometrical-statistical
modeling of character structures for natural stroke extraction
and matching. In IWFHR.
Liu, Y .; and Lian, Z. 2021. FontRL: Chinese Font Synthesis
via Deep Reinforcement Learning. In AAAI, 2198–2206.
Qiguang, L. Z. H. 2004. Algorithm and implementation in
chinese charac-tersorder of strokes recognition. CAS, 7: 041.
Ren, S.; He, K.; Girshick, R. B.; and Sun, J. 2015. Faster
R-CNN: Towards Real-Time Object Detection with Region
Proposal Networks. 91–99.
Su, Y .-M.; and Wang, J.-F. 2004. Decomposing Chinese
characters into stroke segments using SOGD filters and ori-
entation normalization. In ICPR, 351–354.
Su, Z.; Cao, Z.; and Wang, Y . 2009. Stroke extraction based
on ambiguous zone detection: a preprocessing step to re-
cover dynamic information from handwritten Chinese char-
acters. IJDAR, 12: 109–121.
Sun, R.; Lian, Z.; Tang, Y .; and Xiao, J. 2015. Aesthetic Vi-
sual Quality Evaluation of Chinese Handwritings. In IJCAI,
2510–2516.
Sun, Y .; Qian, H.; and Xu, Y . 2014. A geometric approach to
stroke extraction for the Chinese calligraphy robot. In ICRA,
3207–3212.
Tian, Z.; Shen, C.; Chen, H.; and He, T. 2019. Fcos: Fully
convolutional one-stage object detection. In ICCV, 9627–
9636.
Wu, Y .; Kirillov, A.; Massa, F.; Lo, W.-Y .; and Girshick,
R. 2019. Detectron2. https://github.com/facebookresearch/
detectron2.
Xie, Y .; Chen, X.; Sun, L.; and Lu, Y . 2021. DG-Font: De-
formable Generative Networks for Unsupervised Font Gen-
eration. In CVPR, 5130–5140.
Xu, S.; Jiang, H.; Lau, F. C.-M.; and Pan, Y . 2007. An intel-
ligent system for chinese calligraphy. In AAAI, 1578–1583.
Xu, Z.; Liang, Y .; Zhang, Q.; Dong, L.; and Izquierdo, E.
2016. Decomposition and matching: Towards efficient auto-
matic Chinese character stroke extraction. In VCIP, 1–4.
Xun, E.; Xiaochen, L.; Weihua, A.; Sun, Y .; and Ramp, I.
2015. Stroke retrieval of handwritten Chinese character im-
ages for handwriting teaching. Scientiarum Naturalium Uni-
versitatis Pekinensis, 51: 241–248.
Y u, K.; Wu, J.; and Y uan, Z. 2012. Stroke extraction for
chinese calligraphy characters. JCIS, 8: 2493–2500.
Zeng, J.; Chen, Q.; Liu, Y .; Wang, M.; and Y ao, Y . 2021.
Strokegan: Reducing mode collapse in Chinese font genera-
tion via stroke encoding. In AAAI, 3270–3277.
Zeng, J.; Feng, W.; Xie, L.; and Liu, Z.-Q. 2010. Cascade
Markov random fields for stroke extraction of Chinese char-
acters. IS, 180: 301–311.