【论文解读】持续学习三种情形
文章目录
-
- 摘要
- 1. 介绍
- 2.三种持续学习场景
-
- 2.1 单头与多头分类方案的比较
- 2.2 任务协议举例
- 2.3 任务边界
- 3. 持续学习策略
-
- 3.1 特定于任务的组件
- 3.2 正则优化
- 3.3 修正训练数据
- 3.4 使用范例
- 4. 实验细节
-
- 4.1 任务协议
- 4.2 方法
- 5. 结果
- 6. 讨论

论文标题:Three scenarios for continual learning
论文源码:https://github.com/GMvandeVen/continual-learning
【注】增量学习(Incremetal Learning)、持续学习(Continual Learning)、终身学习(Life Long Learing)基本属于一个概念。
摘要
标准人工神经网络遭受了众所周知的灾难性遗忘问题,使得持续学习或终身学习变得困难。近年来,已经提出了许多用于持续学习的方法,但是由于评估协议的差异,很难直接比较其性能。为了能够有更多结构化比较,我们根据测试时是否提供了任务身份或者是否需要推断任务身份来描述三种连续学习方案。任何定义明确的任务序列都可以根据每种情况执行。本文采用split和permuted MNIST数据集,对提出的持续学习方法进行了广泛的比较。在难度和不同方法的有效性方面,证明了这三种情况之间的实质性差异。特别是,当必须推断任务身份(即类增量学习)时,我们发现基于正则化的方法(例如,弹性权重巩固)失败,并且通过重放先前经验表示来解决这种情况。
1. 介绍
当前的最新深层神经网络可以接受各种单个任务并且拥有令人印象深刻的表现。但是,按顺序学习多个任务仍然是深度学习的重大挑战。当接受新任务训练时,标准神经网络会忘记与以前学到的任务相关的大多数信息,这种现象被称为“灾难性遗忘”。
近年来,已经提出了许多减轻灾难性遗忘的方法。由于用于评估它们的实验方案种类繁多,许多方法声称“最先进”性能。据悉在某些实验环境中表现出色的方法在其他实验环境中表现急剧下降。
为了提供减少灾难性遗忘方法更结构化的比较,本文描述了增加难度的三个不同的连续学习场景。这些方案的区别是在测试时任务身份中是否提供了任务身份,如果不是,是否必须推断任务身份。
2.三种持续学习场景

本文专注于持续学习问题,其中单个神经网络模型需要顺序学习一系列任务。在训练期间,只有来自当前任务的数据可用,并且假定任务明确分开。近些年不同的方法被提出,但评估实验协议的差异,比较性能差异显得十分困难。特别是发现不同难度级别的实验协议间一个差异是在测试时是否有可用的测试信息,并且是否还需要该模型明确识别它必须解决的任务。这意味着,即使研究使用完全相同的要学习的任务序列(即相同的任务协议),结果也不一定是可比的。为了使评估标准化并启用跨论文的更有意义的比较,我们描述了三种不同的方案。
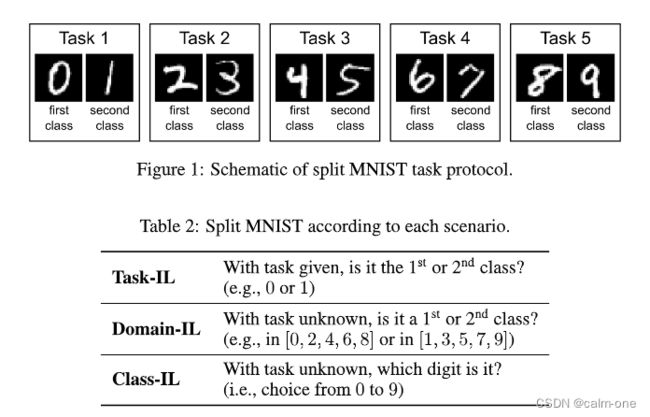
第一种情况下,模型始终知道需要执行哪些任务。这是最简单的持续学习方案,我们将其称为任务增量学习(Task-IL)。由于始终提供任务身份,因此在这种情况下,可以使用特定于任务的组件来训练模型。在这种情况下使用的典型网络体系结构具有“多头”输出层,这意味着每个任务都有其自己的输出单元,但是网络的其余部分在任务之间共享。
任务增量学习,简单说就是任务间互不干扰,每个任务知道需要目标是二分类,是分0和1,分2和3,目标是明确的
第二种情况下,我们将其称为域增量学习(Domain-IL),任务身份在测试时不可用。但是,模型只需要解决当前的任务。他们不需要推断它是哪个任务。这种情况的典型示例是协议任务的结构始终相同,但是输入分布发生改变。
域增量学习,理解上就是原先训练的是真实人物动物分类,域增量实现动画人物动物的分类,输出数据分布发生了变化。
第三种情况下,模型必须能够解决到目前为止所看到的每个任务,并推断出他们呈现的任务。我们将这种情况称为类增量学习(Class-IL),因为它包括常见的逐步学习新类的现实世界问题。
类增量学习,训练阶段只能看到当前训练数据,测试阶段是测试所有已经训练的类数据。
2.1 单头与多头分类方案的比较
持续学习文献中使用“多头”或“单头”进行区分不同任务。从某种意义上说,多头布局需要已知任务身份,而单头布局则不知道。但是,我们提出的分类在两个重要方面有所差异。
首先,多头与单头区别与网络输出层架构布局相关,而我们的场景更普遍地反映评估模型的条件。尽管在持续学习文献中,多头布局中使用任务身份信息是最常见方法,但这并不是唯一的方法。同样,单头布局本身可能不需要知道任务身份,模型仍然可以以其他方式使用任务身份。
其次,当未提供任务身份时,我们的分类方案可以扩展到多头与单头拆分,这是一个进一步的区别,具体取决于是否明确需要推断任务身份。
2.2 任务协议举例
为了说明三种连续学习间的区别,我们将对所有三种情况执行两个不同任务协议。
第一个任务协议是依次学习对MNIST数字进行分类(“split MNIST”)。该协议是在任务增量学习方案下执行的(在这种情况下,有时将其称为“多头分配MNIST”)和类增量学习场景(在这种情况下,它被转称为作为“单头拆分MNIST”),但也可以在域增量学习方案下进行。
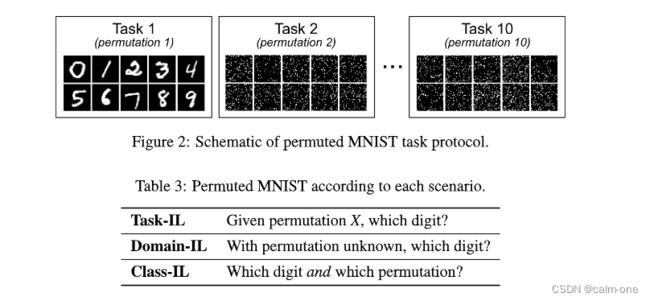
第二个任务协议是“permuted MNIST” ,其中每个任务都涉及对所有十个MNIST数字进行分类,但在每个新任务中都应用于像素置换率不同的数据。尽管根据域-IL场景最自然地执行“排列MNIST”,但也可以根据其他方案执行。
2.3 任务边界
在训练期间,学习任务间存在明确边界。如果任务之间没有这样的界限,如任务间的过渡是逐渐变化的,那当前描述的场景将不再适用,并且持续学习问题变得不那么结构化,且愈加困难。除其他外,小批量随机采样训练和多次训练将不再可能。
3. 持续学习策略
3.1 特定于任务的组件
灾难性遗忘的一个简单解释是,新任务进行训练后,其参数针对新任务进行优化,不再适用于旧任务。这表明不在每个任务上优化网络可能是减轻灾难性遗忘的一种策略。采用不同方法来为每个任务选择网络部分,一种简单的方法是随机分配节点参与每个任务的方法(如XDG),使用进化算法或梯度下降来学习每个任务使用哪些单元。这些方法仅限于任务增量学习方案,因为需要任务标识来选择正确的特定任务组件。
3.2 正则优化
当任务身份信息测试时无法获得,替代策略是仍然优先训练每个任务的网络的不同部分,但要始终使用整个网络进行执行。在每个新任务的培训过程中,将网络参数定向不同,这是弹性重量合并的方法(EWC)和突触智能(SI)。两种方法都估计网络的所有参数对它们对以前学习的任务的重要性,并对未来对他们的未来更改进行惩罚。
3.3 修正训练数据
减轻灾难性遗忘的替代策略是补充以前任务的“伪数据”来学习的每项新任务的培训数据,简称重放。
一种方式是使用先前任务训练好的模型标记当前任务的输入数据,将结果作为伪数据标签。这是Learning without Forgetting的方法(LWF)。该方法重要一点是不根据先前任务模型将重放输入标记为最可能的类别(硬标签),而是将它们对应于所有类别的预测概率(软标签)。重放数据的目的是将训练的模型与这些目标概率预测的概率相匹配。之前使用一个网络输出与另一个网络相匹配的预测概率的方法已被用来从大网络压缩信息到另一个小网络,即知识蒸馏。
另一种替代方法是生成要重放的输入数据。对所有任务进行了顺序训练单独的生成模型,从其输入数据分布中生成样本。第一个使用这样方法的是“Deep Generative Replay”(DGR),将生成的输入样品与主模型提供的“硬目标”配对。我们注意到可以通过重放来自生成模型的输入样本与软目标进行配对,实现DGR与蒸馏的结合。
最后一个选择是存储以前任务中的数据并重放该数据,该方法可以提高持续学习性能,但由于隐私问题或内存约束问题,实现应该不太实际。
3.4 使用范例
存储示例的方式可以减轻灾难性遗忘,使用该策略的方法是iCaRL 。该方法使用神经网络进行特征提取,并基于最近邻规则在特征空间中进行分类,从存储的数据中计算得到类均值。为了防止特征提取网络不适用先前学习的任务,训练特征提取器阶段,ICARL重放存储的数据以及特殊蒸馏形式的当前任务输入。
4. 实验细节
4.1 任务协议
对于 split MNIST,原始的MNIST-dataset分为5个任务,每个任务都是二分类。使用原始的未经预处理的28x28像素灰度图像。采用标准的训练/测试划分,60,000次训练图像和10,000张测试图像。
对于 permuted MNIST,采用10个任务序列。每个任务都是10分类。为了生成置换图像,首先将原始图像零填充到32x32像素。对于每个任务,然后将随机排列生成并应用于1024像素。同样不经过预处理,采用标准训练集和测试集划分。
4.2 方法
为公平对比,选择相同的神经网络体系结构,使用两个隐藏层为400( split MNIST)或1000(permuted MNIST)节点的多层感知机。所有隐藏层使用Relu激活函数。除ICARL外,最后一层是SoftMax输出层。在任务增量方案中,所有方法都使用多头输出层,这意味着每个任务都有其自己的输出单元。在域增量方案中,所有方法均使用单头输出层实现,这意味着每个任务都使用相同的输出单元。在类增量学习方案中,每个类都有自己的输出单元,并且始终是到目前为止所看到的类的所有单元。
方法:
- XdG:需要任务ID,只适用于任务增量学习。
- EWC/Online EWC/SI:基于正则的方法, L total = L current + λ L regularization \mathcal{L}_{\text {total }}=\mathcal{L}_{\text {current }}+\lambda \mathcal{L}_{\text {regularization }} Ltotal =Lcurrent +λLregularization
- LwF/DGR/DGR+distill:基于重放的方法,当前损失和重放样本损失, L total = 1 N tasks so far L current + ( 1 − 1 N tasks so far ) L replay \mathcal{L}_{\text {total }}=\frac{1}{N_{\text {tasks so far }}} \mathcal{L}_{\text {current }}+\left(1-\frac{1}{N_{\text {tasks so far }}}\right) \mathcal{L}_{\text {replay }} Ltotal =Ntasks so far 1Lcurrent +(1−Ntasks so far 1)Lreplay 。LwF:主要思想当前任务的图像和存储模型所提供的软标签被重放网络。DGR:主要思想是生成被重新放入的样本以及对应的硬标签(最大输出);DGR+distll:主要思想是生成重放样本以及蒸馏形成的软标签。
- iCaRL:存储数据,仅适用类增量学习场景。
两种Baselines:
- None:微调,即增量过程中,类别的增加直接通过微调网络解决,被视为下限。
- Offline:使用所有数据进行模型,也称为联合训练,视为上限。
除ICARL外,所有方法均使用标准的多类交叉熵损失,用于模型对当前任务数据的预测。
对于DGR和DGR+distll,所有任务进行了顺序训练单独的生成模型。对称变分自动编码器用作生成模型,具有2个完全连接的隐藏层为400( split MNIST)或1000(permuted MNIST)单元,并具有一个随机大小可变100尺寸。使用标准正态分布作为先验。生成模型的训练也是通过生成重放进行的,由其在先前任务完成训练后存储的副本提供,并且具有与主要模型相同的超参数。
5. 结果
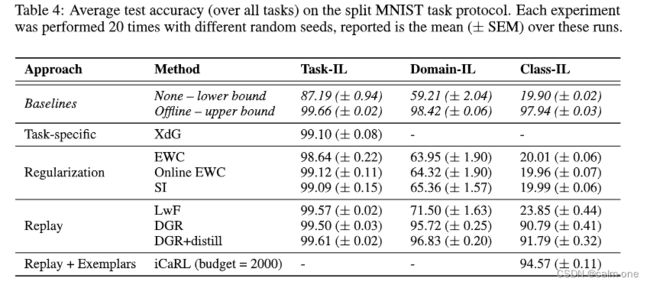
对于split MNIST,所有测试方法在任务IL方案中都表现良好,但是LWF,尤其是基于正则化的方法(EWC,Online EWC和SI)在域-IL方案中表现不佳,并且在类增量场景中完全失败。重要的是,只有使用重放(DGR,DGR+distill和ICARL)获得良好性能。有些令人惊讶的是,我们发现在所有情况下,重放当前任务图像方法优于基于正则化的方法。
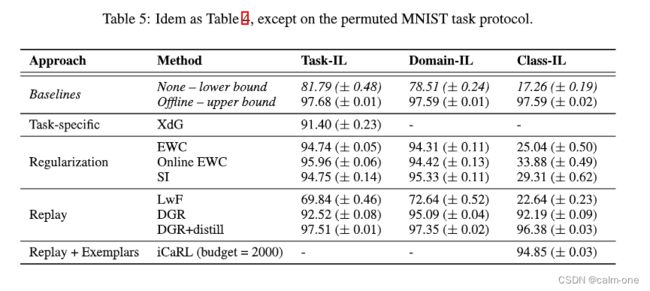
对于permuted MNIST,除LWF外,所有方法任务增量和域增量方案中均表现良好。但是,在类增量任务中,基于正则化的方法再次失败,只有基于重放的方法才能获得良好的性能。对于此任务协议,任务增量和域增量方案之间的差异很小,但这可能是因为任务身份信息仅在输出层中使用(除XDG),而有关置换信息可能是在网络的低层中更有用。确认这一假设,我们发现可以通过将其与XDG结合使用。
6. 讨论
灾难性遗忘是能够真正终身学习的人工智能应用程序发展的主要障碍,并使神经网络能够顺序学习多个任务已成为一项激烈研究的主题。然而,尽管有其范围,但该研究领域相对非结构化:即使倾向于使用相同的数据集,但很难在发布方法之间进行直接比较。我们证明,当前使用的实验协议之间的一个重要差异是是否提供了任务身份,如果不是,则必须推断出来。这两个区别使我们确定了三种情况,体现持续学习各种难度。
类增量学习方案(即,当必须推断任务身份时),目前只有基于重放的方法才能产生可接受的结果。在这种情况下,即使对于涉及MNIST数字分类的相对简单的任务,基于正则化的方法(例如EWC和SI)完全失败了。在split MNIST任务协议上,基于正则化的方法在域增量学习方案中也不好(即当不需要推断任务身份时,也没有提供任务身份时)。结果强调,重放可能是不可避免的工具。
当前研究的局限性是由MNIST研究产生。因此,对于具有更复杂的输入分布的任务协议,生成重放是否仍然如此成功,这仍然是一个悬而未决的问题。然而,生成性重放的希望生成模型的能力进一步改善。此外,LWF的良好性能(即,从当前任务中重放输入)在 split MNIST任务协议上表明,即使重放样品的质量并不完美,它们仍然非常有帮助。