基于Pytorch的MNIST手写数字识别实现(含代码+讲解)
说明:本人也是一个萌新,也在学习中,有代码里也有不完善的地方。如果有错误/讲解不清的地方请多多指出
本文代码链接:
GitHub - Michael-OvO/mnist: mnist_trained_model with torch
明确任务目标:
使用pytorch作为框架使用mnist数据集训练一个手写数字的识别
换句话说:输入为

输出: 0
比较简单直观
1. 环境搭建
需要安装Pytorch, 具体过程因系统而异,这里也就不多赘述了
具体教程可以参考这个视频 (这个系列的P1是环境配置)
PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】_哔哩哔哩_bilibili【已完结!!!已完结!!!2021年5月31日已完结】本系列教程,将带你用全新的思路,快速入门PyTorch。独创的学习思路,仅此一家。个人公众号:我是土堆各种资料,请自取。代码:https://github.com/xiaotudui/PyTorch-Tutorial蚂蚁蜜蜂/练手数据集:链接: https://pan.baidu.com/s/1jZoTmoFzaTLWh4lKBHVbEA 密码 https://www.bilibili.com/video/BV1hE411t7RN?share_source=copy_web
https://www.bilibili.com/video/BV1hE411t7RN?share_source=copy_web
2. 基本导入
import torch
import torchvision
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
import time
import matplotlib.pyplot as plt
import random
from numpy import argmax
不多解释,导入各种需要的包
3. 基本参数定义
#Basic Params-----------------------------
epoch = 1
learning_rate = 0.01
batch_size_train = 64
batch_size_test = 1000
gpu = torch.cuda.is_available()
momentum = 0.5epoch是整体进行几批训练
learning rate 为学习率
随后是每批训练数据大小和测试数据大小
gpu是一个布尔值,方便没有显卡的同学可以不用cuda加速,但是有显卡的同学可以优先使用cuda
momentum 是动量,避免找不到局部最优解的尴尬情况
这些都是比较基本的网络参数
4. 数据加载
使用Dataloader加载数据,如果是第一次运行将会从网上下载数据
如果下载一直不行的话也可以从官方直接下载并放入./data目录即可
MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
(有4个包都需要下载)
#Load Data-------------------------------
train_loader = DataLoader(torchvision.datasets.MNIST('./data/', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_train, shuffle=True)
test_loader = DataLoader(torchvision.datasets.MNIST('./data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_test, shuffle=True)
train_data_size = len(train_loader)
test_data_size = len(test_loader)
5. 网络定义
接下来是重中之重
网络的定义
这边的网络结构参考了这张图:

有了结构图,代码就很好写了, 直接对着图敲出来就好了
非常建议使用sequential直接写网络结构,会方便很多
#Define Model----------------------------
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(in_features=3136, out_features=128),
nn.Linear(in_features=128, out_features=10),
)
def forward(self, x):
return self.model(x)
if gpu:
net = Net().cuda()
else:
net = Net()6.损失函数和优化器
交叉熵和SGD(随机梯度下降)
另外为了方便记录训练情况可以使用TensorBoard的Summary Writer
#Define Loss and Optimizer----------------
if gpu:
loss_fn = nn.CrossEntropyLoss().cuda()
else:
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9)
#Define Tensorboard-------------------
writer = SummaryWriter(log_dir='logs/{}'.format(time.strftime('%Y%m%d-%H%M%S')))7. 开始训练
#Train---------------------------------
total_train_step = 0
def train(epoch):
global total_train_step
total_train_step = 0
for data in train_loader:
imgs,targets = data
if gpu:
imgs,targets = imgs.cuda(),targets.cuda()
optimizer.zero_grad()
outputs = net(imgs)
loss = loss_fn(outputs,targets)
loss.backward()
optimizer.step()
if total_train_step % 200 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, total_train_step, train_data_size,
100. * total_train_step / train_data_size, loss.item()))
writer.add_scalar('loss', loss.item(), total_train_step)
total_train_step += 1
#Test---------------------------------
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
imgs,targets = data
if gpu:
imgs,targets = imgs.cuda(),targets.cuda()
outputs = net(imgs)
_,predicted = torch.max(outputs.data,1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
print('Test Accuracy: {}/{} ({:.0f}%)'.format(correct, total, 100.*correct/total))
return correct/total
#Run----------------------------------
for i in range(1,epoch+1):
print("-----------------Epoch: {}-----------------".format(i))
train(i)
test()
writer.add_scalar('test_accuracy', test(), total_train_step)
#save model
torch.save(net,'model/mnist_model.pth')
print('Saved model')
writer.close()注意这里必须要先在同一文件夹下创建一个叫做model的文件夹!!!不然模型目录将找不到地方保存!!!会报错!!!
Train函数作为训练,Test函数作为测试
注意每次训练需要梯度清零
模型测试时要写with torch.no_grad()
运行的过程如果有GPU加速会很快,运行结果应该如下
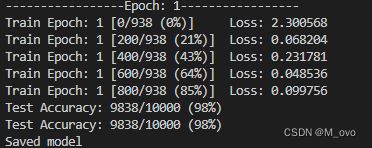
正确率也还算是可以,一个epoch就能跑到98,如果不满意或者想调epoch次数可以在basic params区域直接进行修改
8. 模型验证和结果展示
小细节很多
首先是抽取样本的时候需要考虑转cuda的问题
其次如果直接将样本扔到网络里dimension不对,需要reshape
需要对结果进行argmax处理,因为结果是一个向量(有10个features,分别代表每个数字的概率),argmax会找到最大概率并输出模型的预测结果
使用matplotlib画图
#Evaluate---------------------------------
model = torch.load("./model/mnist_model.pth")
model.eval()
print(model)
fig = plt.figure(figsize=(20,20))
for i in range(20):
#随机抽取20个样本
index = random.randint(0,test_data_size)
data = test_loader.dataset[index]
#注意Cuda问题
if gpu:
img = data[0].cuda()
else:
img = data[0]
#维度不对必须要reshape
img = torch.reshape(img,(1,1,28,28))
with torch.no_grad():
output = model(img)
#plot the image and the predicted number
fig.add_subplot(4,5,i+1)
#一定要取Argmax!!!
plt.title(argmax(output.data.cpu().numpy()))
plt.imshow(data[0].numpy().squeeze(),cmap='gray')
plt.show()运行结果如下:
效果还是很不错的
至此我们就完成了一整个模型训练,保存,导入,验证的基本流程。
完整代码
import torch
import torchvision
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
import time
import matplotlib.pyplot as plt
import random
from numpy import argmax
#Basic Params-----------------------------
epoch = 1
learning_rate = 0.01
batch_size_train = 64
batch_size_test = 1000
gpu = torch.cuda.is_available()
momentum = 0.5
#Load Data-------------------------------
train_loader = DataLoader(torchvision.datasets.MNIST('./data/', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_train, shuffle=True)
test_loader = DataLoader(torchvision.datasets.MNIST('./data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_test, shuffle=True)
train_data_size = len(train_loader)
test_data_size = len(test_loader)
#Define Model----------------------------
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(in_features=3136, out_features=128),
nn.Linear(in_features=128, out_features=10),
)
def forward(self, x):
return self.model(x)
if gpu:
net = Net().cuda()
else:
net = Net()
#Define Loss and Optimizer----------------
if gpu:
loss_fn = nn.CrossEntropyLoss().cuda()
else:
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9)
#Define Tensorboard-------------------
writer = SummaryWriter(log_dir='logs/{}'.format(time.strftime('%Y%m%d-%H%M%S')))
#Train---------------------------------
total_train_step = 0
def train(epoch):
global total_train_step
total_train_step = 0
for data in train_loader:
imgs,targets = data
if gpu:
imgs,targets = imgs.cuda(),targets.cuda()
optimizer.zero_grad()
outputs = net(imgs)
loss = loss_fn(outputs,targets)
loss.backward()
optimizer.step()
if total_train_step % 200 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, total_train_step, train_data_size,
100. * total_train_step / train_data_size, loss.item()))
writer.add_scalar('loss', loss.item(), total_train_step)
total_train_step += 1
#Test---------------------------------
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
imgs,targets = data
if gpu:
imgs,targets = imgs.cuda(),targets.cuda()
outputs = net(imgs)
_,predicted = torch.max(outputs.data,1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
print('Test Accuracy: {}/{} ({:.0f}%)'.format(correct, total, 100.*correct/total))
return correct/total
#Run----------------------------------
for i in range(1,epoch+1):
print("-----------------Epoch: {}-----------------".format(i))
train(i)
test()
writer.add_scalar('test_accuracy', test(), total_train_step)
#save model
torch.save(net,'model/mnist_model.pth')
print('Saved model')
writer.close()
#Evaluate---------------------------------
model = torch.load("./model/mnist_model.pth")
model.eval()
print(model)
fig = plt.figure(figsize=(20,20))
for i in range(20):
#random number
index = random.randint(0,test_data_size)
data = test_loader.dataset[index]
if gpu:
img = data[0].cuda()
else:
img = data[0]
img = torch.reshape(img,(1,1,28,28))
with torch.no_grad():
output = model(img)
#plot the image and the predicted number
fig.add_subplot(4,5,i+1)
plt.title(argmax(output.data.cpu().numpy()))
plt.imshow(data[0].numpy().squeeze(),cmap='gray')
plt.show()