文本分类(朴素贝叶斯算法)
一、贝叶斯定理引入
1、朴素贝叶斯:
朴素贝叶斯中的朴素一词的来源就是假设各特征之间相互独立。这一假设使得朴素贝叶斯算法变得简单,但有时会牺牲一定的分类准确率。
2、贝叶斯公式:

3、换成分类任务的表达式
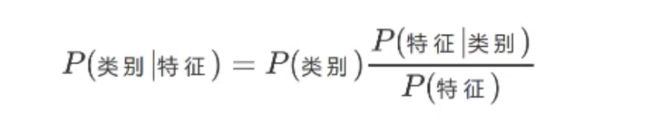
那么我们最终求的p(类别|特征)即可!就相当于完成了我们的任务。
分母的计算用到全概率公式(其实就是分子之和):
二、数据集介绍
1、原始数据集

2、测试数据集
为了减少任务量,测试数据集为自己在原始数据集上打乱后所得。

三、文本分类步骤

四、TF-IDF逆文本频率指数
概念
TF-IDF(term frequency–inverse document frequency)是信息处理和数据挖掘的重要算法,它属于统计类方法。最常见的用法是寻找一篇文章的关键词。
是一种统计方法,用以评估一个词对于一个语料库中一份文件的重要程度。词的重要性随着在文件中出现 的次数正比增加,同时随着它在语料库其他文件中出现的频率反比下降。就是说一个词在某一文档中出现次数比较多,其他文档没有出现,说明该词对该文档分类很重要。然而如果其他文档也出现比较多,说明该词区分性不大,就用IDF来降低该词的权重。
公式如下:

TF(词频)是某个词在这篇文章中出现的频率,频率越高越可能是关键字。它具体的计算方法如上面公式所示:某关键在文章中出现的次数除以该文章中所有词的个数,其中的i是词索引号,j是文章的索引号,k是文件中出现的所有词。
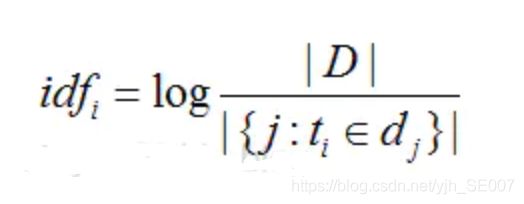
IDF(逆向文档频率)是这个词出现在其它文章的频率,它具体的计算方法如上式所示:其中分子是文章总数,分母是包含该关键字的文章数目,如果包含该关键字的文件数为0,则分子为0,为解决此问题,分母计算时常常加1。当关键字,如“的”,在大多数文章中都出现,计算出的idf值算小。

把TF和IDF相乘,就是这个词在该文章中的重要程度。
数学思想:
TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比.
TF-IDF = TF (词频) * IDF(逆文档频率)
词频:TF = 词在文档中出现的次数 / 文档中总词数
逆文档频率:IDF = log(语料库中文档总数 / 包含该词的文档数 +1 )
五、代码实现
# -*- coding: utf-8 -*-
# @File : TextClassification.py
# @Author: Junhui Yu
# @Date : 2020/8/28
import jieba
from numpy import *
import pickle # 持久化
import os
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.datasets.base import Bunch
from sklearn.naive_bayes import MultinomialNB
def readFile(path):
with open(path, 'r', errors='ignore') as file:
content = file.read()
file.close()
return content
def saveFile(path, result):
with open(path, 'w', errors='ignore') as file:
file.write(result)
file.close()
def segText(inputPath, resultPath):
fatherLists = os.listdir(inputPath) # 主目录
for eachDir in fatherLists: # 遍历主目录中各个文件夹
eachPath = inputPath + eachDir + "/" # 保存主目录中每个文件夹目录,便于遍历二级文件
each_resultPath = resultPath + eachDir + "/" # 分词结果文件存入的目录
if not os.path.exists(each_resultPath):
os.makedirs(each_resultPath)
childLists = os.listdir(eachPath) # 获取每个文件夹中的各个文件
for eachFile in childLists: # 遍历每个文件夹中的子文件
eachPathFile = eachPath + eachFile # 获得每个文件路径
# print(eachFile)
content = readFile(eachPathFile) # 调用上面函数读取内容
# content = str(content)
result = (str(content)).replace("\r\n", "").strip() # 删除多余空行与空格
# result = content.replace("\r\n","").strip()
cutResult = jieba.cut(result) # 默认方式分词,分词结果用空格隔开
saveFile(each_resultPath + eachFile, " ".join(cutResult)) # 调用上面函数保存文件
def bunchSave(inputFile, outputFile):
catelist = os.listdir(inputFile)
bunch = Bunch(target_name=[], label=[], filenames=[], contents=[])
bunch.target_name.extend(catelist)
for eachDir in catelist:
eachPath = inputFile + eachDir + "/"
fileList = os.listdir(eachPath)
for eachFile in fileList: # 二级目录中的每个子文件
fullName = eachPath + eachFile # 二级目录子文件全路径
bunch.label.append(eachDir) # 当前分类标签
bunch.filenames.append(fullName) # 保存当前文件的路径
bunch.contents.append(readFile(fullName).strip()) # 保存文件词向量
with open(outputFile, 'wb') as file_obj: # 持久化必须用二进制访问模式打开
pickle.dump(bunch, file_obj)
def readBunch(path):
with open(path, 'rb') as file:
bunch = pickle.load(file)
# pickle.load(file)
# 函数的功能:将file中的对象序列化读出。
return bunch
def writeBunch(path, bunchFile):
with open(path, 'wb') as file:
pickle.dump(bunchFile, file)
def getStopWord(inputFile):
stopWordList = readFile(inputFile).splitlines()
return stopWordList
def getTFIDFMat(inputPath, stopWordList, outputPath,
tftfidfspace_path,tfidfspace_arr_path,tfidfspace_vocabulary_path): # 求得TF-IDF向量
bunch = readBunch(inputPath)
tfidfspace = Bunch(target_name=bunch.target_name, label=bunch.label, filenames=bunch.filenames, tdm=[],
vocabulary={})
'''读取tfidfspace'''
tfidfspace_out = str(tfidfspace)
saveFile(tftfidfspace_path, tfidfspace_out)
# 初始化向量空间
vectorizer = TfidfVectorizer(stop_words=stopWordList, sublinear_tf=True, max_df=0.5)
transformer = TfidfTransformer()
# 文本转化为词频矩阵,单独保存字典文件
tfidfspace.tdm = vectorizer.fit_transform(bunch.contents)
tfidfspace_arr = str(vectorizer.fit_transform(bunch.contents))
saveFile(tfidfspace_arr_path, tfidfspace_arr)
tfidfspace.vocabulary = vectorizer.vocabulary_ # 获取词汇
tfidfspace_vocabulary = str(vectorizer.vocabulary_)
saveFile(tfidfspace_vocabulary_path, tfidfspace_vocabulary)
'''over'''
writeBunch(outputPath, tfidfspace)
def getTestSpace(testSetPath, trainSpacePath, stopWordList, testSpacePath,
testSpace_path,testSpace_arr_path,trainbunch_vocabulary_path):
bunch = readBunch(testSetPath)
# 构建测试集TF-IDF向量空间
testSpace = Bunch(target_name=bunch.target_name, label=bunch.label, filenames=bunch.filenames, tdm=[],
vocabulary={})
'''
读取testSpace
'''
testSpace_out = str(testSpace)
saveFile(testSpace_path, testSpace_out)
# 导入训练集的词袋
trainbunch = readBunch(trainSpacePath)
# 使用TfidfVectorizer初始化向量空间模型 使用训练集词袋向量
vectorizer = TfidfVectorizer(stop_words=stopWordList, sublinear_tf=True, max_df=0.5,
vocabulary=trainbunch.vocabulary)
transformer = TfidfTransformer()
testSpace.tdm = vectorizer.fit_transform(bunch.contents)
testSpace.vocabulary = trainbunch.vocabulary
testSpace_arr = str(testSpace.tdm)
trainbunch_vocabulary = str(trainbunch.vocabulary)
saveFile(testSpace_arr_path, testSpace_arr)
saveFile(trainbunch_vocabulary_path, trainbunch_vocabulary)
# 持久化
writeBunch(testSpacePath, testSpace)
def bayesAlgorithm(trainPath, testPath,tfidfspace_out_arr_path,
tfidfspace_out_word_path,testspace_out_arr_path,
testspace_out_word_apth):
trainSet = readBunch(trainPath)
testSet = readBunch(testPath)
clf = MultinomialNB(alpha=0.001).fit(trainSet.tdm, trainSet.label)
'''处理bat文件'''
tfidfspace_out_arr = str(trainSet.tdm)
tfidfspace_out_word = str(trainSet)
saveFile(tfidfspace_out_arr_path, tfidfspace_out_arr)
saveFile(tfidfspace_out_word_path, tfidfspace_out_word)
testspace_out_arr = str(testSet)
testspace_out_word = str(testSet.label)
saveFile(testspace_out_arr_path, testspace_out_arr)
saveFile(testspace_out_word_apth, testspace_out_word)
'''处理结束'''
predicted = clf.predict(testSet.tdm)
total = len(predicted)
rate = 0
for flabel, fileName, expct_cate in zip(testSet.label, testSet.filenames, predicted):
if flabel != expct_cate:
rate += 1
print(fileName, ":实际所属类别:", flabel, "-->预测所属类别:", expct_cate)
print("整个测试数据集错误率:", float(rate) * 100 / float(total), "%")
#
if __name__ == '__main__':
#原始集路径
datapath = "./data/" #原始数据路径
stopWord_path = "./stop/stopword.txt"#停用词路径
test_path = "./test/" #测试集路径
test_split_dat_path = "./test_set.dat" #测试集分词bat文件路径
testspace_dat_path ="./testspace.dat" #测试集输出空间矩阵dat文件
train_dat_path = "./train_set.dat" # 读取分词数据之后的词向量并保存为二进制文件
tfidfspace_dat_path = "./tfidfspace.dat" #tf-idf词频空间向量的dat文件
'''
以上四个为dat文件路径,是为了存储信息做的
'''
test_split_path = './split/test_split/'
split_datapath = "./split/split_data/"
tfidfspace_path = "./tfidfspace.txt"
tfidfspace_arr_path = "./tfidfspace_arr.txt"
tfidfspace_vocabulary_path = "./tfidfspace_vocabulary.txt"
testSpace_path = "./testSpace.txt"
testSpace_arr_path = "./testSpace_arr.txt"
trainbunch_vocabulary_path = "./trainbunch_vocabulary.txt"
tfidfspace_out_arr_path = "./tfidfspace_out_arr.txt"
tfidfspace_out_word_path = "./tfidfspace_out_word.txt"
testspace_out_arr_path = "./testspace_out_arr.txt"
testspace_out_word_apth ="./testspace_out_word.txt"
#输入训练集
segText(datapath,
split_datapath)
bunchSave(split_datapath,
train_dat_path)
stopWordList = getStopWord(stopWord_path)
getTFIDFMat(train_dat_path,
stopWordList,
tfidfspace_dat_path,
tfidfspace_path,
tfidfspace_arr_path,
tfidfspace_vocabulary_path)
#输入测试集
segText(test_path,
test_split_path)
bunchSave(test_split_path,
test_split_dat_path)
getTestSpace(test_split_dat_path,
tfidfspace_dat_path,
stopWordList,
testspace_dat_path,
testSpace_path,
testSpace_arr_path,
trainbunch_vocabulary_path)
bayesAlgorithm(tfidfspace_dat_path,
testspace_dat_path,
tfidfspace_out_arr_path,
tfidfspace_out_word_path,
testspace_out_arr_path,
testspace_out_word_apth)
六、预测结果
