【人脸识别】使用OpenCV来检测人脸做人脸识别项目
【人脸识别】使用OpenCV来检测人脸
文章目录
- 【人脸识别】使用OpenCV来检测人脸
- 前言
- 一、什么是OpenCv?
- 二、环境搭建
-
- 1.安装OpenCv
- 二、导入数据集
- 三、OpenCv的基础使用
-
- 1.读取图片
- 2.图片灰度转换
- 3.修改图片尺寸
- 4.绘制形状
- 四、静态人脸检测
-
- 1.单个人脸检测
- 2.多个人脸检测
- 五、视频中的人脸检测/摄像头人脸检测
-
- 1.用摄像头检测人脸
- 2.检测视频人脸
- 六、训练数据
-
- 1.训练数据
- 七、什么是LBPH?
-
- 1.用模型做人脸识别
- 2.基于LBPH人脸识别
- 总结
前言
今天自己尝试着做了一下人脸识别项目,感觉最后能成功运行,觉得很不错,不知道有没有小伙伴和我一样也想做这个人脸识别项目,有没有成功呢,今天我就来分享一下我的一点积累,哈哈~
提示:以下是本篇文章正文内容,下面案例可供参考
一、什么是OpenCv?
OpenCv 的全称是Open Source Computer Vision Library,是一个跨平台的计算机视觉库。OpenCv 可用于开发实时的图像处理、计算机视觉以及模式识别程序。该库有大量的Python、Java and MATLAB/OCTAVE(版本2.5)等的接口。
二、环境搭建
1.安装OpenCv
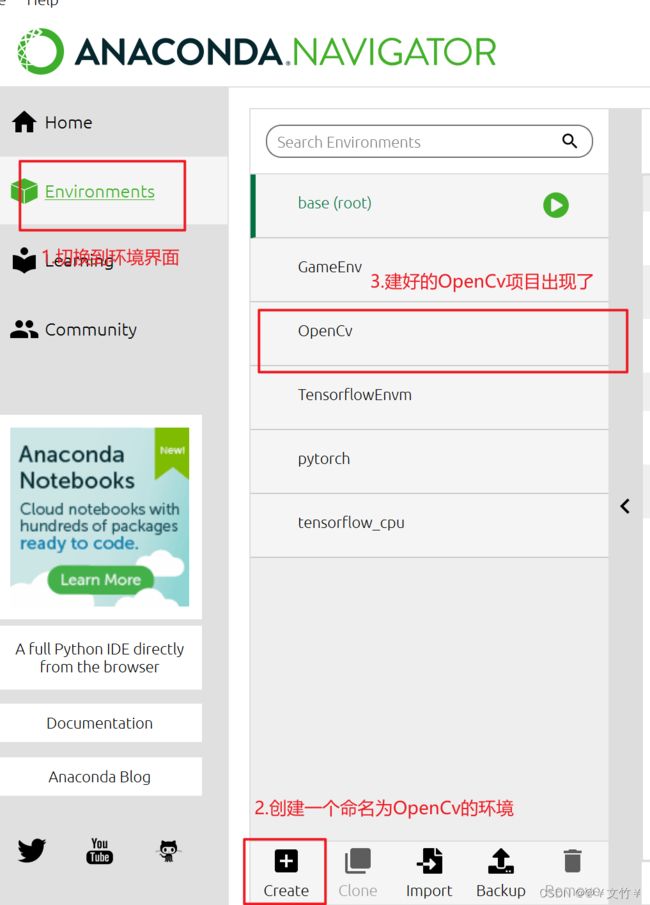
之前分享过了一篇如何搭建新环境的文章了,不会创建的小伙伴可以点击链接看一下,这里就不多做赘述了哈
·如何搭建环境链接:
https://editor.csdn.net/md/?articleId=127831950
或者在Anaconda终端直接用命令装:
pip install opencv-python
注意一下下面安装要在新建OpenCv环境下安装,不是base环境
安装Contrib:
Contrib是OpenCV的增强模块,其中包含了人脸识别的算法
命令:pip install contrib

安装PIL:
PIL(Python Imaging Library)是Python中一个强大的图像处理库
命令:pip install pillow
其他安装:python;numpy
二、导入数据集
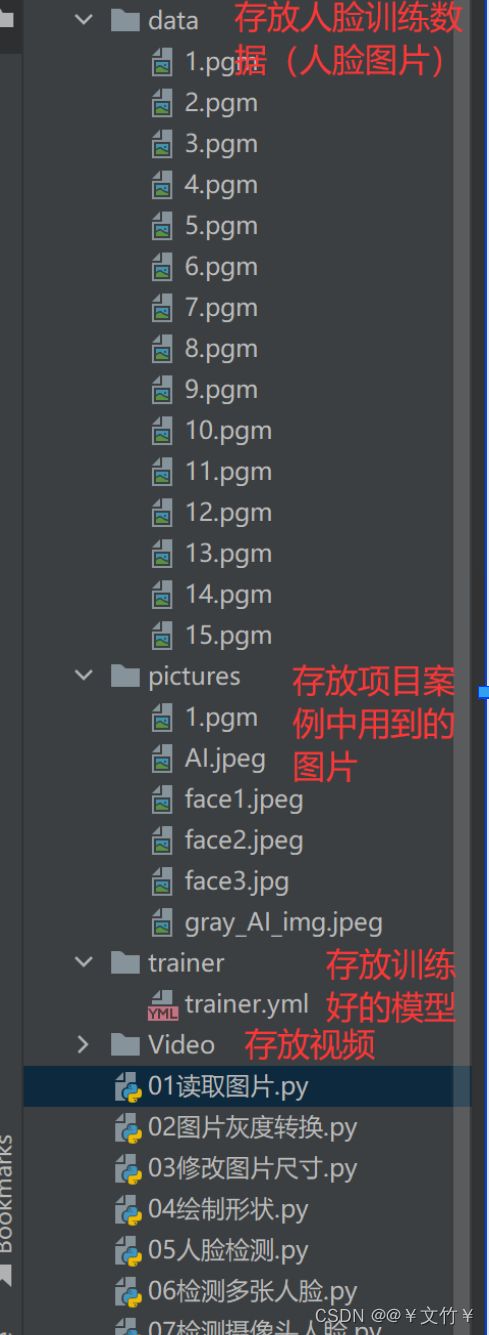
数据可以自己用自己想要的就行,想要我的数据集可以私信或者留言
注意以下代码我用的是PyCharm运行的
·详细的安装PyCharm教程:https://blog.csdn.net/weixin_46211269/article/details/119934323?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166834084016782425631348%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=166834084016782425631348&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-119934323-null-null.142v63pc_rank_34_queryrelevant25,201v3control,213v2t3_esquery_v1&utm_term=pycharm%E5%AE%89%E8%A3%85%E6%95%99%E7%A8%8B&spm=1018.2226.3001.4187
注意环境的切换:
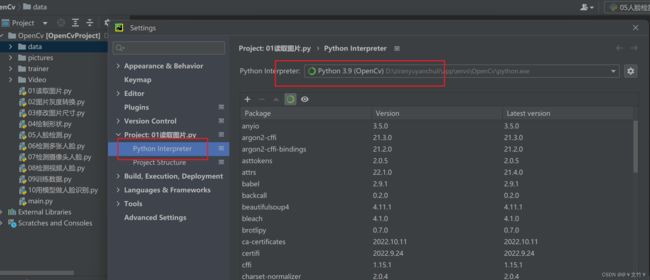
三、OpenCv的基础使用
1.读取图片
#导入OpenCv模块
import cv2 as cv
#读取图片,参数:图片路径(注意:路径中不能有中文,否则加载图片失败)
img=cv.imread('pictures/AI.jpeg')
#显示图片,参数:窗口的名称,所要显示的图片
cv.imshow('AI_img',img)
#等待键盘输入 单位毫秒 传入0则就是无限等待
cv.waitKey(0)
#销毁窗体,释放内存
cv.destroyAllWindows()
2.图片灰度转换
#导入OpenCV模块
import cv2 as cv
#读取图片
img = cv.imread('pictures/AI.jpeg')
#显示图片
cv.imshow('AI_img', img)
#将图片灰度转换,参数:所要转换的图片,指定转换为灰度图
gray_img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
#显示图片
cv.imshow('gray_AI_img', gray_img)
#保存图片
cv.imwrite('pictures/gray_AI_img.jpeg', gray_img)
#等待键盘输入
cv.waitKey(0)
#销毁窗体,释放内存
cv.destroyAllWindows()
3.修改图片尺寸
#导入0penCv模块
import cv2 as cv
#读取图片
img = cv.imread('pictures/AI.jpeg')
#显示图片
cv.imshow('AI_img', img)
print('原来图片的形状', img.shape)
#修改图片尺寸,参数:所要修改的图片,新尺寸
resize_img = cv.resize(img, dsize=(500, 500))
print('修改后图片的形状:', resize_img.shape)
#显示修改好尺寸的图片
cv.imshow('resize_AI_img', resize_img)
#等待键盘输入
cv.waitKey(0)
#销毁窗体,释放内存
cv.destroyallwindows()
4.绘制形状
#导入0penCV模块
import cv2 as cv
img = cv.imread('pictures/AI.jpeg')
#左上角的坐标是(x,y) 矩形的宽度和高度(w h)
x, y, w, h = 150, 150, 150, 150
#绘制矩形,参数:所要绘制的图片,坐标与尺寸,颜色的RGB值,线的粗度
cv.rectangle(img, (x, y, x+w, y+h), color=(0, 255, 255), thickness=6)
#圆中心点的坐标(x,y)与半径(r)
x, y, r = 300, 300, 150
#绘制圆形,参数:所要绘制的图片,圆中心点左边,半径,颜色的RGB值,线的粗度
cv.circle(img, center=(x, y), radius=r, color=(0, 0, 255), thickness=2)
#显示绘制后的图片
cv.imshow('new_img', img)
#等待键盘输入
cv.waitKey(0)
cv.destroyallwindows
四、静态人脸检测
1.单个人脸检测
# 导入0penCV模块
import cv2 as cv
# 人脸识别的函数
def face_detect_demo():
# 将图片转换为灰度图片
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# 创建级联分类器,通过该分类器检测人脸,参数:特征数据
face_detector = cv.CascadeClassifier(r'D:\ziranyuyanchuli\app\envs\OpenCv\Lib\site-packages\cv2\data\haarcascade_frontalface_default.xml')
# 检测人脸并返回人脸信息
faces = face_detector.detectMultiScale(gray)
# 遍历人脸信息获取 xX轴坐标 yY轴坐标 w宽度 h高度
for x, y, w, h in faces:
# 通过矩形框出图片人脸部分
cv.rectangle(img, (x, y), (x + w, y + h), color=(0, 255, 0), thickness=2)
cv.imshow('result_img', img)
# 加载图片
img = cv.imread('pictures/face1.jpeg')
# 调用人脸识别的函数
face_detect_demo()
# 等待键盘输入
cv.waitKey(0)
# 销毁窗体,释放内存
cv.destroyAllWindows()
2.多个人脸检测
# 导入0penCV模块
import cv2 as cv
# 人脸识别的函数
def face_detect_demo():
# 将图片转换为灰度图片
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
# 创建级联分类器,通过该分类器检测人脸,参数:特征数据
face_detector = cv.CascadeClassifier(r'D:\ziranyuyanchuli\app\envs\OpenCv\Lib\site-packages\cv2\data\haarcascade_frontalface_default.xml')
# 检测人脸并返回人脸信息
faces = face_detector.detectMultiScale(gray)
# 遍历人脸信息获取 xX轴坐标 yY轴坐标 w宽度 h高度
for x, y, w, h in faces:
print(x, y, w, h)
cv.rectangle(img, (x, y), (x + w, y + h), color=(0, 0, 255), thickness=2)
# "/" 表示浮点数除法,返回浮点结果;6/4=1.5
# "//"表示整数除法,返回不大于结果的一个最大的整数6 /4 =1.5
cv.circle(img, center=(x + w // 2, y + h // 2), radius=w // 2, color=(0, 255, 0), thickness=2)
# 显示图片
cv.imshow('result', img)
# 加载图片
img = cv.imread('pictures/face3.jpg')
# 调用人脸检测方法
face_detect_demo()
cv.waitKey(0)
cv.destroyAllWindows()
五、视频中的人脸检测/摄像头人脸检测
视频是一张一张图片组成的,在视频的帧上重复这个过程就能完成视频中的人脸检测。(两个摄像头的话,videoCapture那一行,0代表后摄像头,1代表前摄像头;如果是一个摄像头0代表的是去前面的摄像头,不行的话换成1试试)
1.用摄像头检测人脸
import cv2 as cv
def face_detect_demo(img):
gary= cv.cvtColor(img, cv.COLOR_BGR2GRAY)
#地址记得写清楚,是你那个Anacondoa文件夹里面的envs,再找到Oencv路径,直到找到cv2
face_detect= cv.CascadeClassifier(r'D:\ziranyuyanchuli\app\envs\OpenCv\Lib\site-packages\cv2\data\haarcascade_frontalface_default.xml')
face=face_detect.detectMultiScale(gary)
for x,y, w,h in face:
cv.rectangle(img,(x, y), (x+w,y+h),color=(0,0,255),thickness=2)
cv.imshow('result', img)
#打开摄像头,参数:对应优先级的摄像头,指定为打开
#单个摄像头是0,双个摄像头是1,可以自己试着切换一下,也可能因为电脑版本而不一样,也可以反过来试试
cap= cv.VideoCapture(0,cv.CAP_DSHOW)
while True:
# 获取检测到的数据(flag是否为人脸特征数据,frame人脸特征数据)
flag,frame= cap.read()
if not flag:
break
face_detect_demo(frame)
#按键盘Q键退出,前面是设置的是0,这边也要写0,要一致
if ord('q')== cv.waitKey(0):
break
cv.destroyAllWindows()
cap.release()
2.检测视频人脸
import cv2 as cv
def face_detect_demo(img):
gary= cv.cvtColor(img, cv.COLOR_BGR2GRAY)
face_detect= cv.CascadeClassifier(r'D:\ziranyuyanchuli\app\envs\OpenCv\Lib\site-packages\cv2\data\haarcascade_frontalface_default.xml')
face=face_detect.detectMultiScale(gary)
for x, y, w, h in face:
cv.rectangle(img, (x, y), (x+w, y+h), color=(0, 0, 255), thickness=2)
cv.imshow('result', img)
cap=cv.VideoCapture('Video/video.mp4')
while True:
flag,frame = cap.read()
if not flag:
break
face_detect_demo(frame)
# 按键盘Q键退出
if ord('q')== cv.waitKey(1):
break
cap.release()
cv.destroyallwindows()
六、训练数据
先要有人脸数据,需要将这些样本图像加载到人脸识别算法中。所有的人脸识别算法在它们的train()函数中都有两个参数:图像数组和标签数组。这些标签表示进行识别时候某人人脸的ID,因此根据 ID 可以知道被识别的人是谁。要做到这一点,将在「trainer/」目录中保存为.yml文件。
1.训练数据
import os
import cv2
import sys
from PIL import Image
import numpy as np
#获取训练图片数据
#参数 path 存放录入图片的文件夹的路径
def getImageAndLabels(path):
# 存放训练图片数据的列表
facesSamples=[]
# 存放训练图片数据对应id的列表(以图片名作为id)
ids=[]
# 存放所有图片的路径+名称列表
imagePaths=[]
#遍历trainIamgePath文件夹路径下的所有图片名称
for f in os.listdir(path):
#将文件夹路径和图片名称进行连接
result = os.path.join(path, f)
#将连接好的图片路径+名称存入到列表imgesPath中
imagePaths.append(result)
# imagePaths=[os.path.join(path,f) for f in os.listdir(path)]#和上面的结果一样 相当于简写
#创建级联分类器对象
face_detector =cv2.CascadeClassifier(r'D:\ziranyuyanchuli\app\envs\OpenCv\Lib\site-packages\cv2\data\haarcascade_frontalface_default.xml')
# 遍历列表中的图片
for imagePath in imagePaths:
# 读取列表imgesPath的每一张图片
img = cv2.imread(imagePath)
#将读取的图片灰度化处理
PIL_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# PIL_img=Image.open(imagePath).convert('L')#打开路径下的图像并将其转换为灰度图和上面的结果一样相当于简写
# 将图像转换为数组
img_numpy = np.array(PIL_img)
# 检测人脸并返回人脸信息
faces = face_detector.detectMultiScale(img_numpy)
# 获取每张图片的id os.path.split方法将路径和名称切割开
id=int(os.path.split(imagePath)[1].split('.')[0])
# 遍历人脸信息获取 xX轴坐标 yY轴坐标 w宽度 h高度
for x, y, w, h in faces:
# 获取人脸部分数据在转换后数组内的值,将其存放到图片数据列表facesSamples中
facesSamples.append(img_numpy[y:y+h,x:x+w])
# 再将id加到对应图片数据的列表ids中
ids.append(id)
#print(ids)
# 返回图片数据列表以及对应id列表
return facesSamples, ids
if __name__ =='__main__':
#图片路径
path='./data/'
#获取图像数组和id标签数组
faces,ids=getImageAndLabels(path)
#创建模型对象
recognizer=cv2.face.LBPHFaceRecognizer_create()
# 传入训练数据
recognizer.train(faces,np.array(ids))
#保存模型文件
recognizer.write('trainer/trainer.yml')
七、什么是LBPH?
LBPH(Local Binary Pattern Histogram)将检测到的人脸分为小单元,并将其与模型中的对应单元进行比较,对每个区域的匹配值产生一个直方图。由于这种方法的灵活性,LBPH是唯一允许模型样本人脸和检测到的人脸在形状、大小上可以不同的人脸识别算法。
1.用模型做人脸识别
import cv2 as cv
import numpy as np
import os
#创建LBPH识别方法对象
recogizer=cv.face.LBPHFaceRecognizer_create()
#加载训练好的模型
recogizer.read('trainer/trainer.yml')
#准备识别的图片
img=cv.imread('pictures/face3.jpg')
#img=cv.imread('pictures/1.pgm')
# #测试,置信分0,代表完全吻合
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
face_detector = cv.CascadeClassifier(r'D:\ziranyuyanchuli\app\envs\OpenCv\Lib\site-packages\cv2\data\haarcascade_frontalface_default.xml')
faces = face_detector.detectMultiScale(gray)
for x, y, w, h in faces:
cv.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
#人脸识别
id, confidence = recogizer.predict(gray[y:y+h, x:x+w])
print('标签id:', id, '置信评分:', confidence)
cv.imshow('result', img)
cv.waitKey(0)
cv.destroyAllWindows
运行结果:

2.基于LBPH人脸识别
调整后的区域中调用 predict()函数,该函数返回两个元素的数组:第一个元素是所识别个体的标签,第二个是置信度评分。所有的算法都有一个置信度评分阈值,置信度评分用来衡量所识别人脸与原模型的差距,0 表示完全匹配。可能有时不想保留所有的识别结果,则需要进一步处理,因此可用自己的算法来估算识别的置信度评分。LBPH 一个好的识别参考值要低于 50 ,任何高于 80 的参考值都会被认为是低的置信度评分。
总结
以上就是我个人所整理的一个利用OpenCv来进行人脸的识别,有静态的,也有动态的,希望每天的学习,都能够让自己更加充实
想要数据集或者有不明白的小伙伴可以留言或者私信哦~