标准化——python
一、标准化
(一)作用
- 解决因变量之间量纲不同,无法比较的问题。通过标准化使数据之间具有可比性。
- 同时因为是线性变换,所以不改变原有的数据分布。
(二)sklearn中的标准化方法
sklearn中有scale和standscaler两种方法,它们的区别在于计算时使用的均值和方差不一样。standscaler更符合实际应用。
1. Scale( )
将训练集和测试集统一进行标准化处理,此时均值和方差为整个数据的均值和方差
from sklearn import preprocessing
X_scaled = preprocessing.scale(X)
2. Standscaler( )
得到训练集的均值和标准差,然后利用训练集的均值和标准差去分别标准化训练集和测试集。
from sklearn import preprocessing
scaler = preprocessing.StandardScaler().fit(X)
train_scale=scaler.transform(X_train)
test_scale=scaler.transform(X_test)
(三)标准化的实际操作注意点
标准化希望消除特征之间的量纲差异,在此之前,需要先对特征做异常值和缺失值处理。
- 异常值处理
- 缺失值处理
二、标准化与归一化的区别
(一)相同点
- 目的:都是去量纲
- 变换形式:都是线性变换,因此都不改变数据的分布
- 对象:都是针对连续型变量做变换,在建模时一般会统一对连续型自变量做标准化处理
(二)不同点
1. 计算公式:
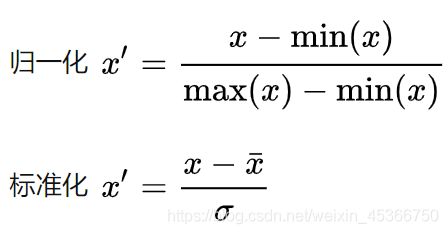
2. 应用场景
一般情况下采用标准化,因为归一化极易受到异常值的影响。
3. 转换值的区间范围
- 标准化:转换为标准正态分布
- 归一化:转换为[0,1]区间