电商用户价值分析——基于RFM模型、KMeans聚类
电商用户价值分析——基于RFM模型、KMeans聚类
- 一、背景
- 二、RFM模型、KMeans聚类
- 三、分析框架
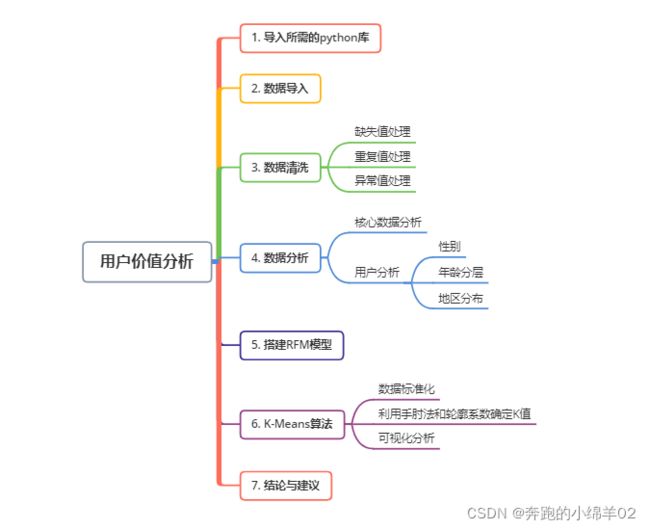
- 四、具体分析
-
- 1. 导入所需的库
- 2. 导入数据
- 3. 数据清洗
- 4. 数据分析
-
- 4.1 核心数据分析
- 4.2 用户分析
- 5. 搭建RFM模型
-
- 分别构建R、F、M
- 6. K-Means人群分类
-
- 6.1 数据标准化
- 6.2 手肘法和轮廓系数得出K值
- 6.3 可视化分析
- 五、分析结论与建议
一、背景
通过对用户价值进行分层,并针对不同用户制定不同运营策略以达到用户精准营销的策略。
二、RFM模型、KMeans聚类
美国数据库营销研究所Arthur Hughes的研究发现,在客户数据分析中发现了三个重要的指标,即:最近一次消费(Recency近度)、消费频率(Frequency频度)、消费金额(Monetary额度),它们是衡量客户价值的重要标准。RFM分析是一种探索性分析方法。
k-means简介
1.聚类算法(clustering Algorithms)介绍
聚类是一种无监督学习—对大量未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小。
2.k-means原理详解
k-means是一种常见的聚类算法,也叫k均值或k平均。通过迭代的方式,每次迭代都将数据集中的各个点划分到距离它最近的簇内,这里的距离即数据点到簇中心的距离。
三、分析框架
四、具体分析
1. 导入所需的库
import pandas as pd
import numpy as np
import datetime
import matplotlib.pyplot as plt
import cufflinks as cf
cf.set_config_file(offline=True) # 离线模式绘图
2. 导入数据
data = pd.read_csv(r"D:\Desktop\python code\python数据分析\用户分群KMeans+RFM\产品销售分析.csv")
data.head()
3. 数据清洗
缺失值处理
# 查看数据缺失
data.isnull().sum()
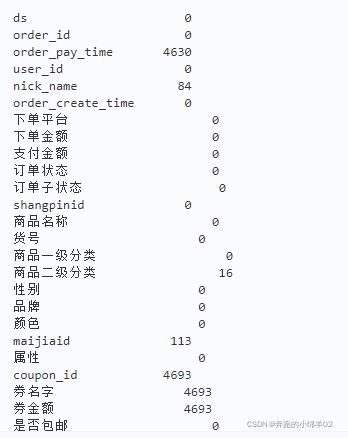
缺失值字段均为非核心字段,后续分析可直接提取有效字段。
重复值处理
#查看重复值
data.duplicated().sum()
0
异常值处理
#查找付款金额小于0的数据
abnormal=data[np.where(data['支付金额'] < 0,True,False)]
abnormal

4. 数据分析
4.1 核心数据分析
- 总GMV
#总GMV
GMV=round(data['支付金额'].sum(),ndigits=2)
4154205.04
- 每月GMV
#每月GMV
GMV_M=data.groupby(by='event_month',as_index=True).agg({'支付金额':sum}).iplot(kind='line')
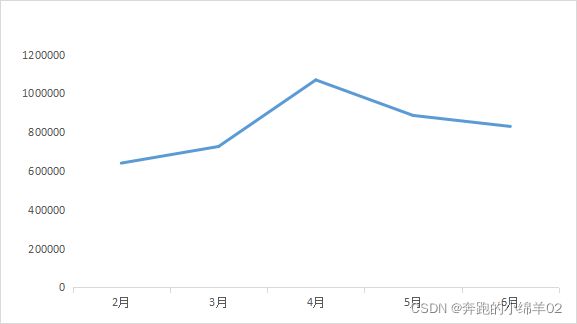
4月销售数据较大提升,可能是促销活动导致;
整体上销售数据趋势有所上升,但持续性无法得到保证
- 客单价
#客单价
price_uv=round(data['支付金额'].sum() / data['user_id'].nunique(),0)
88.59
- 笔单价
#笔单价
price_pv=round(data['支付金额'].sum() / data['order_id'].nunique(),0)
45.56
4.2 用户分析
年龄
# 先划分一下年龄
data['age_cut'] = pd.cut(data['age'],bins=[data.age.min(),20,30,40,data.age.max()],labels=['16-20','20-30','30-40','40-50'])
data.groupby(by=data['age_cut']).agg(age非重复计数=('user_id','nunique')).reset_index().iplot(kind='pie',labels='age_cut',values='age非重复计数')
各年龄阶段消费水平对比
import plotly.offline as py
import plotly.graph_objs as go
pyplt=py.offline.plot
py.init_notebook_mode(connected=True)
fig={
"data":[
{
"values":a['order_id'],
"labels":a['age_cut'],
'domain':{'x':[0,0.8],'y':[0,0.6]},
'name':"不同年龄段的订单占比",
'hoverinfo':"label+percent+name",
'hole':.3,
'type':"pie"
},
{
'values':a['amount'],
'labels':a['age_cut'],
'domain':{'x':[.6,1],'y':[0,.6]},
'name':"不同年龄段的销售额占比",
'hoverinfo':'label+percent+name',
'hole':.3,
'type':'pie'
}
],
'layout':{
'title':'不同年龄段订单/销售额占比分布图',
'annotations':[
{
'font':{'size':18},
'showarrow':False,
'text':'订单占比',
'x':0.4,
'y':0.255
},
{
'font':{'size':18},
'showarrow':False,
'text':'销售额占比',
'x':0.86,
'y':0.255
}
]
}
}
py.iplot(fig)
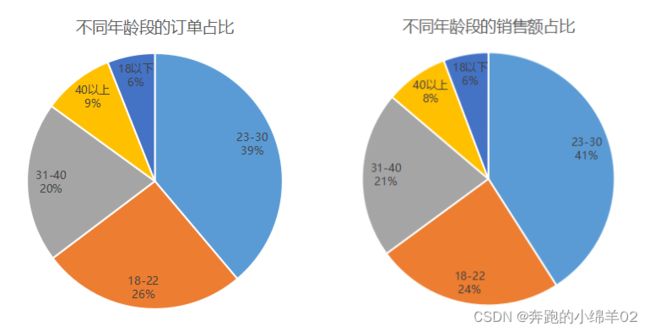
由图可得出:
- 不同年龄段订单及销售额 占比前三年龄段分别为【23-30】、【18-22】、【31-40】
- 消费用户主要集中在18-30岁年龄段,占比达65%
各性别消费情况
fig={
"data":[
{
"values":b['order_id'],
"labels":b['sex'],
'domain':{'x':[0,0.8],'y':[0,0.6]},
'hoverinfo':"label+percent+name",
'hole':.3,
'type':"pie"
},
{
'values':b['amount'],
'labels':b['sex'],
'domain':{'x':[.6,1],'y':[0,.6]},
'hoverinfo':'label+percent+name',
'hole':.3,
'type':'pie'
}
],
'layout':{
'title':'不同性别订单/销售额占比分布图',
'annotations':[
{
'font':{'size':18},
'showarrow':False,
'text':'性别-付费人数占比',
'x':0.4,
'y':0.255
},
{
'font':{'size':18},
'showarrow':False,
'text':'性别-消费金额占比',
'x':0.86,
'y':0.255
}
]
}
}
py.iplot(fig)
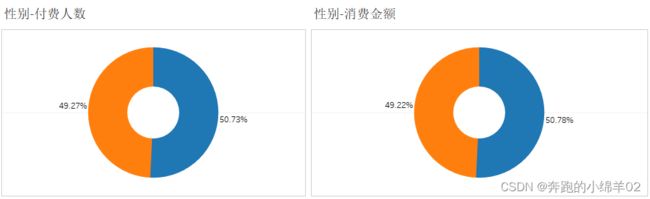
图中可以得出:
- 用户分析-性别维度,订单量与销售额占比男性用户占比均比女性用户多出1.5个百分比;
- 男女比例基于付费人数与消费金额占比几乎相同。
用户地区分布
data.groupby(by='local',as_index=True).agg({'age':len}).sort_values(by='age',ascending=True).iplot(kind='bar',orientation='h') # 这里要排下序
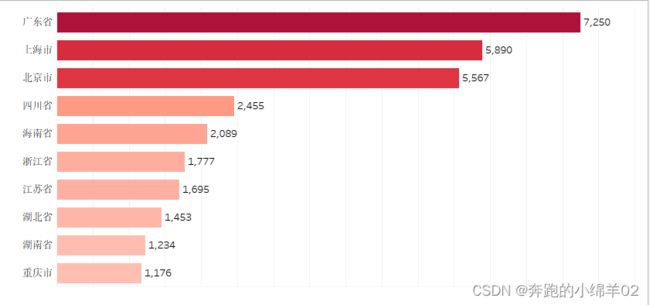
由图可得出:
消费用户所在地区前三的分别是广东、上海、北京。
5. 搭建RFM模型
分别构建R、F、M
# 上面透视表中的event_dates是每个客户的最近购买日期,我们还需要用一个固定的日期减去这一列的日期值,从而求出R
RFM_df['event_dates'] = RFM_df['event_dates'].max()-RFM_df['event_dates']
# 去除event_dates列中的“days”字段,以30天为周期
RFM_df['event_dates'] = RFM_df['event_dates'].map(lambda x:x/np.timedelta64(30,'D'))
# 将列(column)排序
RFM_df = RFM_df[['event_dates', 'order_id', 'amount']]
# 重命名列
RFM_df.rename(columns={'event_dates':'R', 'order_id':'F', 'amount':'M',},inplace=True)
RFM_df.head()

6. K-Means人群分类
6.1 数据标准化
#由于RFM量纲不同,可能导致聚类结果不好,所以我们先进行数据标准化
from sklearn.preprocessing import StandardScaler
#采用StandardScaler方法对数据规范化:均值为0,方差为1的正态分布
g = StandardScaler()
std_data= g.fit_transform(RFM_df)
std_data= pd.DataFrame(stand_data,columns=RFM_df.columns,index=RFM_df.index)
std_data.head()
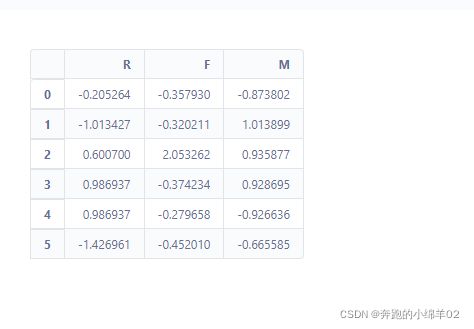
# 这里划分类别用的是归一化后的数据,因为质心就是从归一化数据里建模得出的
stand_data= pd.DataFrame(std_data)
stand_data.rename(columns={0:'R',1:'F',2:'M'},inplace = True)
stand_data.iplot('box',mean=True)
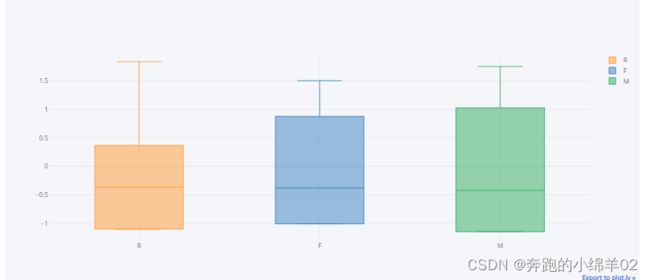
R、F、M的中位值都偏下,我们这里选用均值来判断每个质心分别时属于什么类型的客户。
R_label = np.where(stand_data['R']>stand_data['R'].mean(),1,0)
F_label = np.where(stand_data['F']>stand_data['F'].mean(),1,0)
M_label = np.where(stand_data['M']>stand_data['M'].mean(),1,0)
stand_data= pd.DataFrame([R_label,F_label,M_label]).T
stand_data.rename(columns={0:'R',1:'F',2:'M'},inplace = True)
stand_data
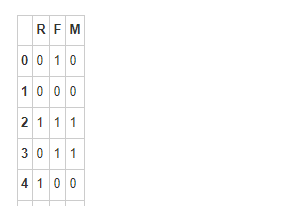
6.2 手肘法和轮廓系数得出K值
手肘法
#根据最小的SSE原则确定簇数量,选择最佳的K值,即客户的类别数量
from sklearn.cluster import KMeans
#定义SSE列表,用来存放不同K值下的SSE
SSE = []
#定义候选K值
for i in range(1,10):
kmeans = KMeans(n_clusters = i,random_state = 12)
kmeans.fit(stand_data)
SSE.append(kmeans.inertia_)
#使用手肘法看K值
plt.plot(range(1,10),SSE,marker = 'o')
plt.show()
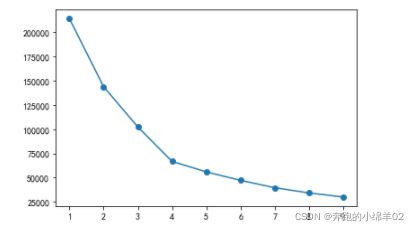
根据上图显示,当k为4或5时,效果较好
轮廓系数
#使用轮廓系数看K值:轮廓系数是描述簇内外差异的关键指标,越接近1,聚类效果越好
from sklearn.metrics import silhouette_score
kc = KMeans(n_clusters=4,random_state=12)
kc.fit(stand_data)
silhouette_score(stand_data,kc.labels_)
0.4791
kc = KMeans(n_clusters=5,random_state=12)
kc.fit(stand_data)
silhouette_score(stand_data,kc.labels_)
0.4949
由手肘法和轮廓系数得出K值分成5类,聚类效果最好
6.3 可视化分析
增加客户级别标签
RFM_labels = pd.read_excel(r"D:\Desktop\python code\python数据分析\用户分群KMeans+RFM\RFM_labels.xlsx")
RFM_labels = RFM_labels.iloc[:,:-1]
cc = pd.merge(rfm_data_centers_label, RFM_labels,on=['R','F','M'] ,how='left')
cc['labels'] = cc.index
# 在RFM_df后面添加客户类别列
RFM_df = pd.merge(RFM_df,cc[['labels','客户级别']],on='labels',how='left')
RFM_df.head()
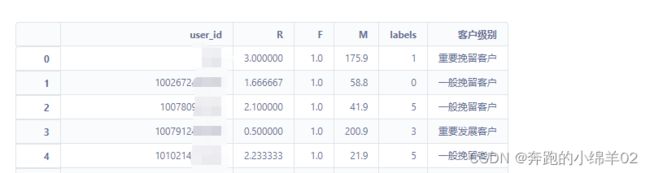
可视化
#可视化
RFM_df.groupby('客户级别')['user_id'].count().iplot(kind='bar')
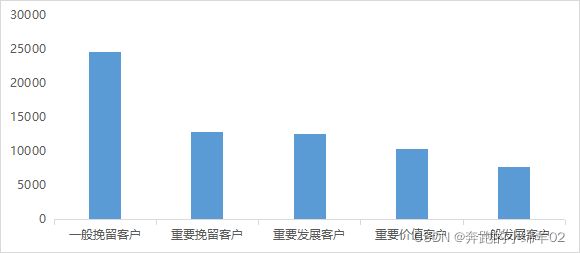
由图可得:
各分群用户呈现三个梯度,
第一梯度:一般挽留客户
第二梯度:重要客户(挽留、发展、价值)
第三梯度:一般发展客户
三梯度人数比约 3:5:2
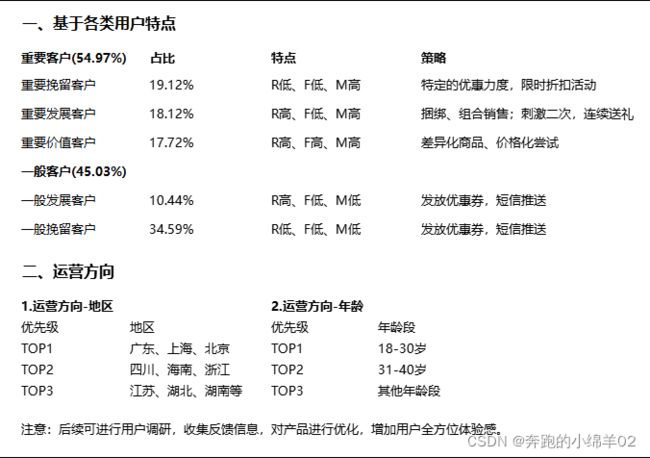
五、分析结论与建议
分析结论:
- 整理销售状况:2月-6月GMV整体呈上升趋势,但后续该趋势很难维持,需进一步分析数据,并制定相应的可落地策略;
- 用户年龄分布:男女比例接近1:1 ,可不分性别进行运营;
- 用户年龄分布:占比前三年龄段分别为【23-30】、【18-22】、【31-40】消费用户主要集中在18-30岁年龄段,占比达65%,运营策略可以基于用户年龄出发,且制定优先级。
- 用户地区分布:消费用户所在地区前三的分别是广东、上海、北京。即一线城市用户占比较大,可优先对此类用户进行运营策略。
- 分群用户:一般客户与重要客户占比约1:1,其中一般挽留客户(R低\F低\M低)占比最高,约占:30%。
分析建议