【论文-目标追踪】ByteTrack: Multi-Object Tracking by Associating Every Detection Box
论文信息
[CVPR-2021] ByteTrack: Multi-Object Tracking by Associating Every Detection Box
paper code(基于YOLOX)
思路概述
ByteTrack针对追踪任务中对遮挡等低分预测框直接丢弃导致的目标丢失和路径破碎,也考虑低分框,设计了两阶段的关联匹配方法,首先对高分框关联匹配,然后对未匹配的低分框进行关联匹配,两者不同的是后者考虑到低分框存在遮挡或扰动,表观特征的相似性可能不可信,只使用IOU用于关联。ByteTrack在MOT17和MOT20上取得了SOTA,并在应用到9种追踪器中产生了提升。ByteTrack可以看做是基于SORT为基线改进的追踪器,值得关注的是追踪器没用ReID,IDF1效果也稳的很。按惯例先上精度图:

1 引言
MOT中通常简单的使用得分阈值(例如0.5)丢掉低分检测框来平衡检测器的效果,避免过多的误检,但在观察中发现这些低分框很多是由于遮挡、动作扰动等产生的,如果粗鲁的删掉这些框,那么追踪器的上限能力也就受到限制。如何利用这些低分框成为提升追踪器能力的一种潜在手段。下图中红框轨迹由于遮挡产生低分而在一般追踪器中产生了轨迹中断(图中b),而有效利用低分框则可以保持轨迹(图中c)。

2 相关工作(论文中写的比较清楚,文献请查看原文)
2.1 MOT中的检测
检测是MOT的重要基础,多数的追踪方法主要是做追踪器的研究。追踪中检测的使用包括:Tracking by detection(提供检测框)和Detection by tracking(轨迹优化检测框)。
Tracking by detection中检测器和追踪器可以独立发展,RetinaNet、CenterNet和YOLO系列等单阶段检测器因为速度和精度良好的平衡性被广泛使用。追踪器大多使用单帧图像追踪。但是图像目标检测方法本身受遮挡和运动模糊等影响产生丢失检测和低分框,这也是视频目标检测方法用来诟病图像检测方法之处。因此多帧信息可用来增强视频检测效果。
Detection by tracking指的是用追踪来提升检测框的精度,一些方法利用SOT(single object tracking)或卡尔曼滤波(大概起始于SORT方法中)来预测下一帧的轨迹框,并与检测框融合来增强检测结果。一些方法利用前几帧的轨迹框来增强预测下一帧。近来,基于Transformer的检测器逐渐盛行,其能良好的传播帧间的框。作者采用了轨迹相似度来增强检测框的可信度。
2.2 数据关联
数据关联是MOT的核心,其一般分两步,首先计算轨迹和检测框之间的相似性,然后根据各种相似性利用不同策略来关联轨迹和检测框。
相似度指标。位置、运动和表观是主要的关联依据。SORT方法对于位置和运动结合采用很简单的方法,首先用卡尔曼滤波预测下一帧的轨迹框,然后计算与检测框之间的IoU。最近一些方法学习目标运动实现了对于大幅相机运动和低帧率下更加鲁棒的结果。位置和运动相似性在短期关联中是准确的。表观相似性有助于长期关联。表观相似度可以通过Re-ID特征的余弦相似性度量。DeepSORT采用了独立的Re-ID模型来提取检测框的表观特征。近来,联合检测和Re-ID模型的方法因为简单和高效逐渐流行。
关联策略。相似性计算后通过关联策略来辨识目标。常用匈牙利算法或贪心分配。SORT使用单次关联的策略。DeeoSORT提出了级联匹配策略先匹配最接近轨迹的检测框,再是丢失的轨迹。MOTDT首先利用表观相似性关联然后利用IoU相似性关联未关联的轨迹。QDTrack将表观相似性转换成概率并使用最近邻搜索来完成关联。注意力机制可以直接传播帧间框。一些方法提出了追踪查询来预测未来帧轨迹。关联在注意力交互过程中隐式执行,不使用匈牙利算法。
上述方法主要关注设计更好的关联方法。论文作者则是从如何有效运用所有框的维度来做关联的。
3 BYTE
作者提出的BYTE关联方法几乎使用所有的框。设计了两阶段的关联匹配方法,首先对高分框关联匹配,然后对未匹配的低分框进行关联匹配,两者不同的是后者考虑到低分框存在遮挡或扰动,表观特征的相似性可能不可信,只使用IOU用于关联。算法的伪代码如下图所示,其中绿色是论文的核心改进:

算法的大概流程包括:
1、将检测框分为高分框集合和低分框集合;
2、使用卡尔曼滤波预测轨迹在当前帧的位置;
3、第一次关联做高分框和所有轨迹的关联,计算IoU或Re-ID特征距离,使用匈牙利算法关联,保留未关联的检测框和未关联的轨迹;
4、第二次关联做低分框和剩余轨迹的关联,考虑到低分框存在遮挡或扰动,表观特征的相似性可能不可信,只使用IOU用于关联;
5、丢失的轨迹会保持一定的帧数,用于第一关联。
4 实验
4.1 设置
数据集。消融实验使用MOT17视频的前半段数据、CrowdHuman、Cityperson、ETHZ作为训练集,MOT17的后半段数据做验证集。这也是消融实验模型叫mix…的缘由。
指标。CLEAR metrics 包括: MOTA, FP, FN, IDs, etc., IDF1 和 HOTA。
几个实现细节。高分阈值是0.6,IoU阈值是0.2,keep frames是30,检测器是YOLOX-X。
4.2 消融实验
相似性因子分析。对于第一次关联,IoU或Re-ID都是很好的相似性因子。对于第二次关联IoU就明显优于Re-ID了。
检测阈值鲁棒性。看着比SORT稳不少。
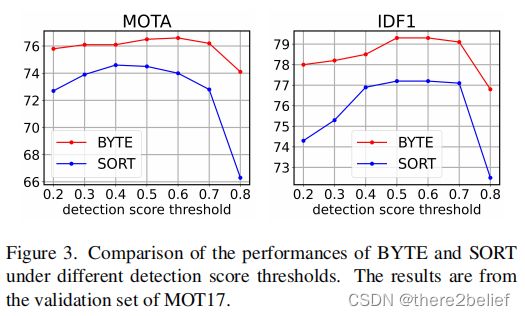
在其它追踪器上用着也大都有良好提升。

4.3 基准测试
到了刷榜环节,MOD17、MOD20等都是SOTA,例如:
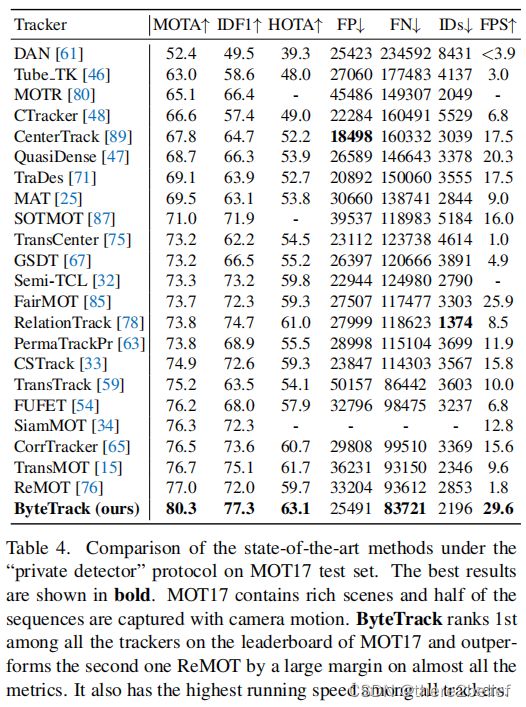
还有好多实验……实验做的确实完备,点个赞,写论文可以参考