Python数据分析案例-使用RFM模型与基于RFM的K-Means聚类算法实现电商用户价值分层
前言
本文通过使用真实电商订单数据,采用RFM模型与K-means聚类算法对电商用户按照其价值进行分层。
1. 案例介绍
该数据集为英国在线零售商在2010年12月1日至2011年12月9日间发生的所有网络交易订单信息。
该公司主要销售礼品为主,并且多数客户为批发商。
数据集介绍及来源:
https://www.kaggle.com/carrie1/ecommerce-data
https://archive.ics.uci.edu/ml/datasets/online+retail#
特征说明:
- InvoiceNo:订单编号,由六位数字组成,退货订单编号开头有字幕’C’
- StockCode:产品编号,由五位数字组成
- Description:产品描述
- Quantity:产品数量,负数表示退货
- InvoiceDate:订单日期与时间
- UnitPrice :单价(英镑)
- CustomerID:客户编号,由5位数字组成
- Country:国家
2. 操作环境
语言:Python 3
主要使用的库:numpy,pandas, matplotlib,seaborn,pyecharts,sklearn,scipy 等
3. 数据清洗
3.1 数据加载及预览
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
import warnings
warnings.filterwarnings("ignore")
# 读取数据
data = pd.read_csv('data-2.csv')
data.head()

# 查看数据集基本信息
data.info()

3.2 重复值
# 删除重复值
data.drop_duplicates(inplace=True)
data.shape[0] # 536641
删除了几千条重复值
3.3 缺失值
# 查看缺失值数量与比例
(
pd.DataFrame({
"NaN_num": round(data.isnull().sum(),2),
"NaN_percent":(data.isnull().sum()/data.shape[0]).apply(lambda x:str(round(x*100,2))+'%') ,
})
.sort_values('NaN_num', ascending=False)
)

因为本文是做用户价值分析,CustomerID的缺失会对结果产生影响,所以缺失值不能填补上的话需删除。
Description的缺失则没有影响不用删除。
# 查看用户编号为缺失值的数据,找到其InvoiceNo订单编号
CustomerID_isnull_list = data.loc[data['CustomerID'].isnull()].InvoiceNo.unique().tolist()
# 查看用户编号为非缺失值的列,找到其InvoiceNo订单编号
CustomerID_notnull_list = data.loc[~data['CustomerID'].isnull()].InvoiceNo.unique().tolist()
# 查看两者交集--即缺失值中没有订单编号与未缺失的相同
[i for i in CustomerID_isnull_list if i in CustomerID_notnull_list]
订单编号相同的为同一用户,以上的结果为空列表,表示缺失值中没有订单号与未缺失的相同,即无法通过订单编号来补充用户编号的缺失值。
# 删除CustomerID缺失值
data.dropna(subset=['CustomerID'], how='any', inplace=True)
3.4 异常值
3.4.1 日期
# 将日期字符串格式转换成时间格式
data['InvoiceDate'] = pd.to_datetime(data.InvoiceDate, format='%m/%d/%Y %H:%M')
# 查看是否有日期不在选定日期范围内的数据
data.query(" InvoiceDate < '2010-12-01' | InvoiceDate > '2011-12-10'")
没有查询到结果,表示所有日期均在选定范围内
3.4.2 价格与数量
# 描述性统计
data[['Quantity', 'UnitPrice']].describe()

价格没有负值,数量存在负值。
print('单价为0的数量:', data.query("UnitPrice == 0 ").shape[0])
单价为0的数量为40, 由于单价为0订单没有产生价值,所以删除此部分数据
# 删除单价为0的数据
data.drop(data.query("UnitPrice == 0 ").index, inplace=True)
# 查看数量为负且InvoiceNo订单编号没有C的数量
print(data.query("Quantity < 0 & ~InvoiceNo.str.contains('C')", engine='python').InvoiceNo.count())
# 查看数量为不为负且且InvoiceNo订单编号含有C的数量
print(data.query("Quantity >= 0 & InvoiceNo.str.contains('C')", engine='python').InvoiceNo.count())
以上两者数量皆为0,说明数量为负的与订单编号带有C的一致为退货订单
# 查看数量为负的订单
data.query(" Quantity < 0").head(3)

查看退货的订单编号是否两条信息,即一条是下单信息,另一条是退单信息。
即:上表第一行的C536379是否还存在订单编号为536379且数量为正数、其他信息一样的订单
# 筛选并拼接数量为负的订单信息
data_return = data.query(" Quantity < 0")
data_return['return'] = data_return.InvoiceNo.str.split("C", expand=True)[1] + data_return.StockCode + \
data_return.Description + abs(data_return.Quantity).astype("str") + \
data_return.UnitPrice.astype("str") + data_return.CustomerID.astype("str")
# 筛选并拼接数量为正的订单信息
data_sale = data.query(" Quantity > 0").astype("str")
data_sale['sale'] = data_sale.InvoiceNo + data_sale.StockCode + data_sale.Description + data_sale.Quantity + \
data_sale.UnitPrice + data_sale.CustomerID
# 利用intersection方法查看是否有交集
set(data_return['return'].tolist()).intersection(set(data_sale['sale'].tolist()))
没有交集说明不存在,即退货的订单不存在下单信息。
# 删除退货订单信息
data.drop(data.query("Quantity <= 0 ").index, inplace=True)
3.5 辅助列
# 添加总价列
data['Monetary'] = data['Quantity'] * data['UnitPrice']
# 添加年、月、日 、日期列
data['Date'] = data['InvoiceDate'].dt.date
data['Year'] = data['InvoiceDate'].dt.year
data['Month'] = data['InvoiceDate'].dt.month
data['Day'] = data['InvoiceDate'].dt.day
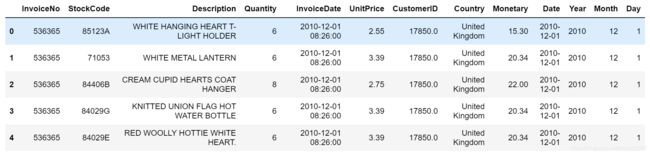
data.head()
查看提取的日期信息
4. RFM模型
# 定义一个分箱之后的统计函数
def rfm_bins_statistics(feature, scores, name,):
feature_statistic = pd.concat([feature, data.groupby('CustomerID').Monetary.sum(), scores], axis=1)
feature_statistic.columns = [name, 'Monetary', 'label']
feature_bins = feature_statistic.groupby('label')[name].max().tolist()
feature_bins_min = [-1]+ feature_bins[:-1] # 辅助列
feature_label_statistic = feature_statistic.groupby('label').agg({
'{}'.format(name):['count',('占比', lambda x: "%.1f"%((x.count() / feature_statistic[name].count()*100)) + '%')],
'Monetary':['sum',('占比', lambda x: "%.1f"%((x.sum() / feature_statistic.Monetary.sum()*100)) + '%')],
}).assign(范围 = [str(i + 1) + '-' + str(j) for i,j in zip(feature_bins_min, feature_bins )] )
return feature_statistic , feature_label_statistic, feature_bins
4.1 R
# 计算每个客户购买的最近日期
R = data.groupby('CustomerID')['Date'].max()
# 计算每位客户最近一次购买距离截止日期的天数
R_days = (data['Date'].max()-R).dt.days # .dt.days取出days
# 数据非正态分布,将客户最近一次购买天数按照中位数分5层,并依次评分
R_scores= pd.qcut(R_days, q=5, duplicates='drop',labels=[5,4,3,2,1]) # 上一次消费距离天数越近越好,所以labels为倒序
这里根据帕累托法则即20%的客户贡献了80%的财富,按照中位数分为5个层级,每层的数量接近相同。
实际可根据业务场景进行调整, 比如[0, 30, 90, 180, 360, 720]按照天数进行划分。下面的F与M同理
R_statistic, R_label_statistic, R_bins = rfm_bins_statistics(R_days, R_scores, 'Date')
R_label_statistic

from matplotlib.patches import Polygon
from matplotlib.collections import PatchCollection
fig,ax = plt.subplots(figsize=(18, 10), facecolor='#f4f4f4')
# 各天数的消费金额之和
Monetary_sum = pd.concat([R_statistic.Date.value_counts().sort_index(), R_statistic.groupby('Date').Monetary.sum()], axis=1)
# 层级消费金额按照天数范围从小到大的累计之和---sumsum不是sum
Monetary_range = R_label_statistic['Monetary', 'sum'].cumsum().tolist()
# 频数分布图
ax.hist(R_statistic.Date, bins=50, alpha=0.5)
ax1 = ax.twinx()
ax1.plot(Monetary_sum.Monetary.cumsum(), color='#cc0033')
# 文字标注
for i in range(5):
ax1.text(
R_bins[i]/2,
Monetary_range[i],
'天数范围:' + str(R_label_statistic['范围'].tolist()[i])+ '\n' + '消费金额占比:' + str(R_label_statistic['Monetary','占比'].tolist()[i]),
va='top',
ha='left',
bbox={'boxstyle': 'round',
'edgecolor':'grey',
'facecolor':'#d1e3ef',
'alpha':0.5})
# # 矩形
# polygons = [Polygon(xy=np.array([(0, 0), (R_bins[0], 0), (R_bins[0], Monetary_range[0]), (0,Monetary_range[0])])),
# Polygon(xy=np.array([(R_bins[0], Monetary_range[0]), (R_bins[1], Monetary_range[0]), (R_bins[1], Monetary_range[1]), (R_bins[0], Monetary_range[1])])),
# Polygon(xy=np.array([(R_bins[1], Monetary_range[1]), (R_bins[2], Monetary_range[1]), (R_bins[2], Monetary_range[2]), (R_bins[1], Monetary_range[2])])),
# Polygon(xy=np.array([(R_bins[2], Monetary_range[2]), (R_bins[3], Monetary_range[2]), (R_bins[3], Monetary_range[3]), (R_bins[2], Monetary_range[3])])),
# Polygon(xy=np.array([(R_bins[3], Monetary_range[3]), (R_bins[4], Monetary_range[3]), (R_bins[4], Monetary_range[4]), (R_bins[3], Monetary_range[4])]))]
# ax1.add_collection(PatchCollection(polygons, facecolor='grey', alpha=0.3));
ax.set_xlabel('距离最近一次的购买天数')
ax.set_ylabel('频数')
ax1.set_ylabel('消费累计金额')
ax.set_facecolor('#f4f4f4')
plt.show()
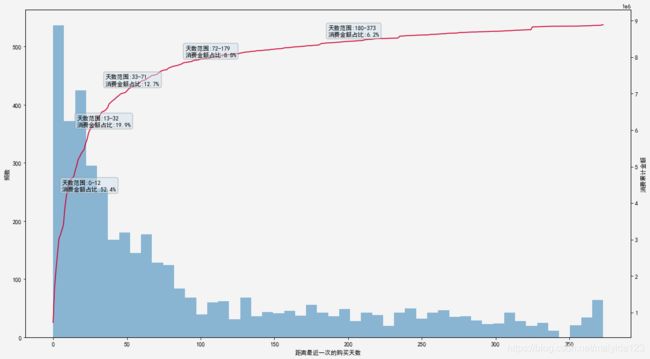
观察以上图表可得,距离最近一次购买天数在0-12天时,其数量占所有顾客的20%,贡献了52.4%的消费。
距离最近一次购买天数越大,其贡献的消费越低。
4.2 F
# 计算每个客户购买的频次---一天内多次消费算一次,按照天数计次
F = data.groupby('CustomerID')['Date'].nunique()
# 查看消费次数占比
pd.DataFrame({'count':F.value_counts(),
'percent':F.value_counts()/F.value_counts().sum()}).head(5)

可以看到消费次数为1的超过三分之一
# 自定义边界分箱
F_scores = pd.cut(F,[1, 2, 3, 5, 8, F.max()+1], labels=[1, 2, 3, 4, 5], right=False) # 消费频次越大越好,所以labels为顺序
# 查看相关统计
F_statistic, F_label_statistic, F_bins = rfm_bins_statistics(F, F_scores, 'Freq')
F_label_statistic

# 绘图
fig,ax = plt.subplots(figsize=(18, 10), facecolor='#f4f4f4')
# 各天数的消费金额之和
Monetary_sum = pd.concat([F_statistic.Freq.value_counts().sort_index(), F_statistic.groupby('Freq').Monetary.sum()], axis=1)
# 层级消费金额按照天数范围从小到大的累计之和---sumsum不是sum
Monetary_range = F_label_statistic['Monetary', 'sum'].cumsum().tolist()
# 频数分布图
ax.hist(F_statistic.Freq, bins=50, alpha=0.5)
ax1 = ax.twinx()
ax1.plot(Monetary_sum.Monetary.cumsum(), color='#cc0033')
# 文字标注
for i in range(5):
ax1.text(
F_bins[i]/2,
Monetary_range[i],
'购买次数范围:' + str(F_label_statistic['范围'].tolist()[i])+ '\n' + '消费金额占比:' + str(F_label_statistic['Monetary','占比'].tolist()[i]),
va='top',
ha='left',
bbox={'boxstyle': 'round',
'edgecolor':'grey',
'facecolor':'#d1e3ef',
'alpha':0.5})
ax.set_xlabel('购买次数')
ax.set_ylabel('频数')
ax1.set_ylabel('消费累计金额')
ax.set_facecolor('#f4f4f4')
plt.show()

观察以上图表可以看到,消费频率最高的11.1%客户贡献了53.9%的消费。
4.3 M
# 将每层按照中位数分5层,并依次评分
M = data.groupby('CustomerID')['Monetary'].sum()
M_scores = pd.qcut(M, q=5, duplicates='drop',labels=[1,2,3,4,5]) # 消费金额越大越好,所以labels为顺序
# 查看相关统计
M_statistic = pd.concat([data.groupby('CustomerID').Monetary.sum(), M_scores], axis=1)
M_statistic.columns = ['Monetary', 'label']
M_label_statistic = M_statistic.groupby('label').agg({
'label':['count',('占比', lambda x: x.count() / M_statistic.label.count())],
'Monetary':['sum',('占比', lambda x: x.sum() / M_statistic.Monetary.sum())],
}).sort_values(('Monetary','sum'),ascending = False).round(2)
M_label_statistic

# 绘图
fig,ax = plt.subplots(figsize=(18, 10), facecolor='#f4f4f4')
label_count_cumsum = M_label_statistic.cumsum()['label', 'count'].values
label_percent_cumsum = M_label_statistic.cumsum()['label', '占比'].values
Monetary_sum_cumsum = M_label_statistic.cumsum()['Monetary', 'sum'].values
Monetary_percent_cumsum = M_label_statistic.cumsum()['Monetary', '占比'].values
ax.plot(M_statistic.Monetary.sort_values(ascending=False).cumsum().values)
for i in range(5):
ax.text(label_count_cumsum[i],
Monetary_sum_cumsum[i],
'数量占比:%.0f%%'%(label_percent_cumsum[i]*100)+'\n'+'金额占比:%.0f%%'%(Monetary_percent_cumsum[i]*100),
va='center',
ha='right',
bbox={
'boxstyle': 'round',
'edgecolor':'grey',
'facecolor':'#d1e3ef',
'alpha':0.5 })
ax.set_xlabel('顾客数量')
ax.set_ylabel('消费累计金额')
ax.set_facecolor('#f4f4f4')
plt.show()
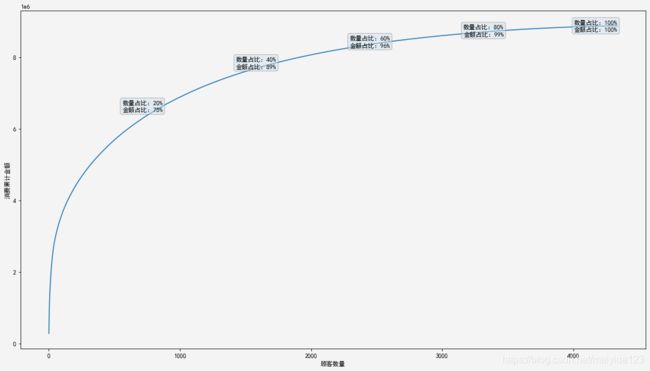
至此,R、F、M已分箱完毕,各分5层,除了个别外数量大致相近。
各特征的头部客户均贡献了超过50%的消费。
4.4 分值计算
# 合并
RFM = pd.concat([R_scores,F_scores,M_scores],axis=1)
RFM.columns = ['R_scores', 'F_scores', 'M_scores']
# 绘制R F M 得分交叉表
pd.pivot_table(RFM, index = ['R_scores','F_scores'], columns=['M_scores'], aggfunc=len)
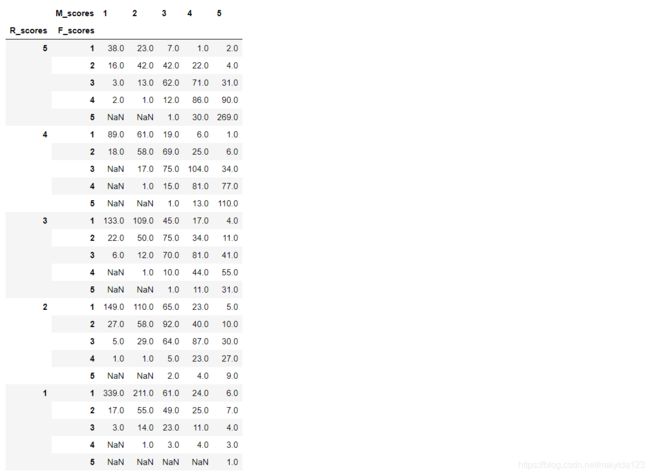
可以通过上表看到RFM分值的详细分布
# 格式转换
for i in RFM.columns:
RFM[i] = RFM[i].astype(float)
# 将每个值按照R/F/M均值大小分别定义其价值高低
for i,j in enumerate(['R', 'F', 'M']):
RFM[j] = np.where(RFM.iloc[:,i] > RFM.iloc[:,i].mean(), '高', '低')
# 创造综合价值变量
RFM['Value'] = RFM['R'] + RFM['F'] +RFM['M']
map_dict = {'高高高':'重要价值客户', '高低高':'重要发展客户', '低高高':'重要保持客户', '低低高':'重要挽留客户','高高低':'一般价值客户', '高低低':'一般发展客户', '低高低':'一般保持客户', '低低低':'流失客户'}
RFM['CustmerLevel'] = RFM['Value'].map(map_dict)
RFM.head()

4.5 分析
# 计算出每个客户的消费总金额,下单总数,下单的产品总数
data_temp = data.groupby('CustomerID').agg({'Monetary':np.sum, 'Quantity':np.sum, 'InvoiceNo':'nunique'})
RFM_data = pd.concat([RFM['CustmerLevel'], data_temp, R_days, F],axis=1)
RFM_data.columns = ['客户等级','消费金额', '购买商品总量', '订单总量', '最近消费天数', '消费次数']
RFM_data.head()

# 定义一个统计函数
def customer_level_statistic(customer_data):
customer_level = (customer_data
.groupby('客户等级')
.agg({
'消费金额':[('均值', 'mean'),
('总量', 'sum'),
('占比', lambda x: "%.1f"%((x.sum()/ customer_data['消费金额'].sum()*100))+'%')],
'购买商品总量':[('均值', 'mean'),
('总量', 'sum'),
('占比', lambda x:"%.1f"%((x.sum()/ customer_data['购买商品总量'].sum()*100))+'%')],
'订单总量':[('均值', 'mean'),
('总量', 'sum'),
('占比', lambda x:"%.1f"%((x.sum()/ customer_data['订单总量'].sum()*100))+'%')],
'客户等级':[('数量', 'count'),
('占比', lambda x:"%.1f"%((x.count()/ customer_data['客户等级'].count()*100))+'%')],
'最近消费天数':[('均值','mean')],
'消费次数':[('均值','mean')],
})
.sort_values(('消费金额','总量'),ascending=False)
.assign(客单价 = lambda x : x['消费金额','总量'] / x['订单总量','总量'])
.round(1)
)
customer_level.columns = pd.Index(customer_level.columns[:-1].tolist() + [('客单价', '均值')])
return customer_level
RFM_level = customer_level_statistic(RFM_data)
RFM_level
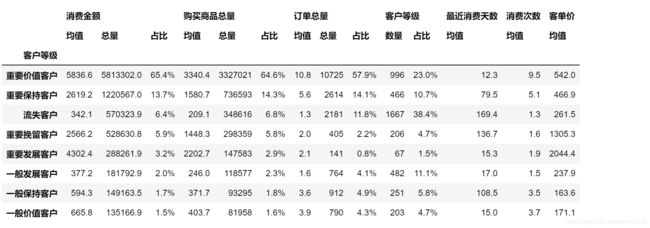
相关指标的可视化
# 饼图
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.globals import ThemeType
def customer_level_pie(value, name):
type = value.index.tolist()
Monetary = value['消费金额','总量'].astype(float).round(1).tolist()
ProductQuantity = value['购买商品总量','总量'].astype(int).tolist()
OrderNunique = value['订单总量','总量'].astype(int).tolist()
Num = value['客户等级','数量'].astype(int).tolist()
c = (
Pie(init_opts=opts.InitOpts(bg_color="#f4f4f4", width="1600px", height="900px"))
.add(
"",
[list(z) for z in zip(type, Monetary )],
center=["25%", "30%"],
radius="32%",
label_opts=opts.LabelOpts(formatter=" {b} : {d}%"),
)
.add(
"",
[list(z) for z in zip(type, ProductQuantity )],
center=["60%", "30%"],
radius="32%",
label_opts=opts.LabelOpts(formatter=" {b} : {d}%"),
).add(
"",
[list(z) for z in zip(type, OrderNunique)],
center=["25%", "76%"],
radius="32%",
label_opts=opts.LabelOpts(formatter=" {b} : {d}%"),
)
.add(
"",
[list(z) for z in zip(type, Num)],
center=["60%", "76%"],
radius="32%",
label_opts=opts.LabelOpts(formatter=" {b} : {d}%"),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="{}每层客户各项指标对比图".format(name),pos_left="30%",pos_top="2%",
title_textstyle_opts=opts.TextStyleOpts(font_size=30),),
legend_opts=opts.LegendOpts(
type_="scroll", pos_top="30%", pos_left="80%", orient="vertical"
),
graphic_opts=[
opts.GraphicGroup(
graphic_item=opts.GraphicItem(
left="21%",
top="7%",
),
children=[
# opts.GraphicText控制文字的显示
opts.GraphicText(
graphic_textstyle_opts=opts.GraphicTextStyleOpts(
text='消费金额对比' + ' '*43 + '购买商品总量对比' + '\n'*24 + ' 订单总量对比' +' '*43 + ' 客户数量对比',
font="18px Microsoft YaHei",
)
)
]
)
],
).set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{b} \n 数量: {c} \n 占比:{d}%"
),
)
.render("{}指标对比图.html".format(name))
)
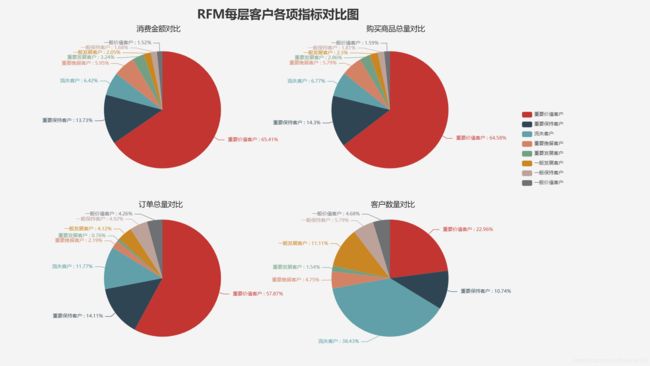
customer_level_pie(RFM_level, 'RFM')
# 均值对比
def customer_level_barh(data_level):
fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(18, 12), facecolor='#f4f4f4', dpi=300)
plt.style.use('seaborn-dark')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
columns_list = [['消费金额', '客单价'], ['最近消费天数', '消费次数']]
for i in [0,1]:
for j in [0,1]:
index = data_level[columns_list[i][j], '均值'].sort_values().index
values = data_level[columns_list[i][j], '均值'].sort_values().values
ax[i][j].barh(index, values)
for k in range(len(data_level)):
ax[i][j].text(values[k], k-0.1, values[k], size=13 )
ax[i][j].set_title(columns_list[i][j]+'均值对比')
ax[i][j].set_facecolor('#f4f4f4')
ax[i][j].set_xticks([])
for m in ['left', 'right', 'top', 'bottom']:
ax[i][j].spines[m].set_color("#f4f4f4")
ax[i][j].tick_params(axis='y', which='major',color='#f4f4f4')
customer_level_barh(RFM_level)

根据R、F、M高低区分的8类客户,可以根据其各自特点给出针对性的营销策略。
| R | F | M | 客户类型 | 行为特征 | 营销策略 |
|---|---|---|---|---|---|
| 高 | 高 | 高 | 重要价值客户 | 近期购买过,购买频率高,消费高,为主要消费客户 | 升级为VIP客户,提供个性化服务,倾斜较多的资源 |
| 高 | 低 | 高 | 重要发展客户 | 近期购买过,购买频率低,客单价高,可能是新的批发商或企业采购者 | 提供会员积分服务,给与一定程度的优惠来提高留存率 |
| 低 | 高 | 高 | 重要保持客户 | 近期没有购买,购买频率高,消费较高 | 通过短信邮件等介绍最新产品/功能,来促进消费 |
| 低 | 低 | 高 | 重要挽留客户 | 近期没有购买,购买频率低,客单价高,即将流失 | 通过短信、邮件、电话等介绍最新产品/功能/升级服务促销折扣等,避免流失 |
| 高 | 高 | 低 | 一般价值客户 | 近期购买过,购买频率高,消费较低 | 潜力股, 提供社群服务,介绍新产品/功能促进消费 |
| 高 | 低 | 低 | 一般发展客户 | 近期购买过,购买频率低,消费较低,可能是新客户 | 提供社群服务,介绍新产品/功能,提供折扣等提高留存率 |
| 低 | 高 | 低 | 一般保持客户 | 近期没有购买,购买频率高,消费低, | 介绍新产品/功能等方式唤起此部分用户 |
| 低 | 低 | 低 | 流失客户 | 近期没有购买,购买频率低,消费低,已流失 | 促销折扣等方式唤起此部分用户,当资源分配不足时可以暂时放弃此部分用户 |
4.6 加权得分
RFM模型的假设:
- R:用户最近一次购买离得越久就越有流失风险
- F:用户消费频次越高越忠诚
- M:用户消费越多越有价值
但并不是所有的场景都能够满足这三个假设。
服装等跟着季节走,礼物饰品等看节日,而手机平板等购买间隔时间参考产品更新周期。而诸如电器、家具等耐消品,分析R的意义就不大了。像母婴奶粉等产品有生命周期,当到了周期结束后,分析M已没有意义。还有其他促销活动、节假日等因素造成的分析场景受限等。
所以在R、F、M统一量纲之后,某些场景下比如需要弱化某一因素的对于分层的影响,可以需根据不同业务场景设置不同的权重。
本次分析的网站主要产品是非季节性礼物,权重3:3:4仅供参考。
权重的设置可以依据个人经验或者AHP法。
# 按照R、F、M权重3:3:4综合评分
RFM_weight = RFM[['R_scores', 'F_scores', 'M_scores']]
RFM_weight['Scores'] = 0.3 * RFM_weight['R_scores'] + 0.3 * RFM_weight['F_scores'] + 0.4 * RFM_weight['M_scores']
def score2value(x):
if x >= 4.2:
x = '高价值客户'
elif 4.2 > x >= 3.4:
x = '较高价值客户'
elif 3.4 > x >= 2.6:
x = '中等价值客户'
elif 2.6 > x >= 1.8:
x = '一般价值客户'
else:
x = '低价值客户'
return x
RFM_weight['Value'] = RFM_weight['Scores'].apply(lambda x : score2value(x))
# 选出每个客户的消费总金额,下单总数,下单的产品总数
RFM_weight = pd.concat([RFM_weight.Value, data_temp, R_days, F],axis=1)
RFM_weight.columns = ['客户等级', '消费金额', '购买商品总量', '订单总量', '最近消费天数', '消费次数']
RFM_weight_level = customer_level_statistic(RFM_weight)
RFM_weight_level

# 绘制饼图
customer_level_pie(RFM_weight_level, 'RFM加权')
# 绘制柱状图
customer_level_barh(RFM_weight_level)
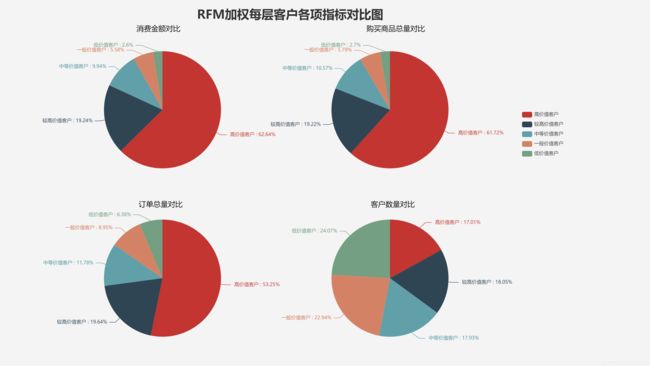

观察结果可以看到,
- 17%的高价值客户贡献了网站62.6%的消费。
- 而24.1%的低价值客户仅贡献了2.6%的消费。
分层具有一定的效果,各层客户间有明显的差别。
5.聚类
# 合并数据
k_data = pd.concat([R_days, F, M], axis=1)
k_data.columns = ['R', 'F', 'M']
5.1 特征工程
查看数据的正态性
from scipy import stats
from scipy.stats import norm, skew
plt.style.use('fivethirtyeight')
def draw_dist_prob(data):
fig, ax = plt.subplots(nrows=2, ncols=3, figsize=(24, 12), dpi=300)
for i,j in enumerate(['R', 'F', 'M']):
sns.distplot(data[j], fit=norm, ax=ax[0][i])
(mu, sigma) = norm.fit(data[j])
ax[0][i].legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],loc='best')
ax[0][i].set_ylabel('数量')
ax[0][i].set_title('{} 频数图'.format(j))
stats.probplot(data[j], plot=ax[1][i])
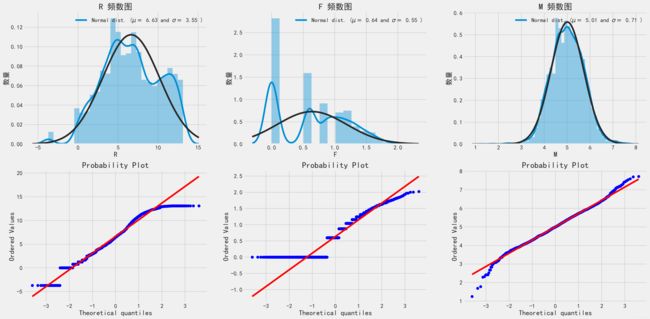
draw_dist_prob(k_data)

- 可以看到数据均呈现长尾分布,且存在一定的异常值
- 异常值的处理需要根据业务情况判断,电商数据需要慎重对待。处理方法可参考《使用K-Means聚类算法检测离群点》,本文暂不作处理。
# 查看偏度、峰度
pd.DataFrame([i for i in zip(k_data.columns, k_data.skew(), k_data.kurt())],
columns=['特征', '偏度', '峰度'])

可以看到峰度与偏度均较大。
5.1.1 box-cox转换
# R中存在0值,进行box-cox转换时存在0值会将其转变成无穷大,所以将所有的值加上一个很小的数全部变成正数
k_data.R = k_data.R + 0.0001
# boxcox转换
k_data_bc = k_data.copy()
for i in k_data_bc.columns: # 自动计算λ
k_data_bc[i], _ = stats.boxcox(k_data_bc[i])
# 查看偏度、峰度
pd.DataFrame([i for i in zip(k_data_bc.columns, k_data_bc.skew(), k_data_bc.kurt())],
columns=['特征', '偏度', '峰度'])

对于一组数据来说,如果计算出来的偏度和峰度都在0附近,那么可以初步判断其分布服从正态分布。
draw_dist_prob(k_data_bc)
数据分布相较于变换之前更符合正态分布。
5.1.2 标准化
# K-means 的本质是基于欧式距离的数据划分算法,均值和方差大的维度将对数据的聚类产生决定性影响。
# 使用标准化对数据进行预处理可以减小不同量纲的影响。
from sklearn.preprocessing import StandardScaler
standard_scaler = StandardScaler()
standard_scaler.fit(k_data_bc)
data_scaler = standard_scaler.transform(k_data_bc)
k_data_scaler = pd.DataFrame(data_scaler, columns = ['R', 'F', 'M'], index = k_data.index)
k_data_scaler.head()

5.2 K-Means建模
5.2.1 k值选取
5.2.1.1 肘部法则选取k
from sklearn.cluster import KMeans
# 选择K的范围 ,遍历每个值进行评估
inertia_list = []
for k in range(1,10):
model = KMeans(n_clusters = k, max_iter = 500, random_state = 12)
kmeans = model.fit(k_data_scaler)
inertia_list.append(kmeans.inertia_)
# 绘图
fig,ax = plt.subplots(figsize=(8,6))
ax.plot(range(1,10), inertia_list, '*-', linewidth=1)
ax.set_xlabel('k')
ax.set_ylabel("inertia_score")
ax.set_title('inertia变化图')
plt.show()

观察上图可知K=2时有明显的拐点,但实际业务中2类并不能够很好地满足需求,所以接下来使用廓系数评估。
5.2.1.2 轮廓系数
使用轮廓系数评估聚类效果—轮廓系数的区间为:[-1, 1]。
-1代表分类效果差,1代表分类效果好。0代表聚类重叠,没有很好的划分聚类。
from sklearn import metrics
label_list = []
silhouette_score_list = []
for k in range(2,10):
model = KMeans(n_clusters = k, max_iter = 500, random_state=123 )
kmeans = model.fit(k_data_scaler)
silhouette_score = metrics.silhouette_score(k_data_scaler, kmeans.labels_) # 轮廓系数
silhouette_score_list.append(silhouette_score)
label_list.append({k: kmeans.labels_})
# 绘图
fig,ax = plt.subplots(figsize=(8,6))
ax.plot(range(2,10), silhouette_score_list, '*-', linewidth=1)
ax.set_xlabel('k')
ax.set_ylabel("silhouette_score")
ax.set_title('轮廓系数变化图')
plt.show()

观察轮廓系数可得,分为2类的效果最好,3-6类的效果相近,7-9类的效果最差。
5.2.1.3 calinski-harabaz Index
calinski-harabaz Index:适用于实际类别信息未知的情况,为群内离散与簇间离散的比值,值越大聚类效果越好。
calinski_harabaz_score_list = []
for i in range(2,10):
model = KMeans(n_clusters = i, random_state=1234)
kmeans = model.fit(k_data_scaler)
calinski_harabaz_score = metrics.calinski_harabasz_score(k_data_scaler, kmeans.labels_)
calinski_harabaz_score_list.append(calinski_harabaz_score)
# 绘图
fig,ax = plt.subplots(figsize=(8,6))
ax.plot(range(2,10), calinski_harabaz_score_list, '*-', linewidth=1)
ax.set_xlabel('k')
ax.set_ylabel("calinski_harabaz_score")
ax.set_title('calinski_harabaz_score变化图')
plt.show()

分2类的效果最好,其次是3类,效果随着k增大而变差
综上,分为2类的效果最好,但是不符合业务诉求,分3类效果次之,所以退而求其次本文将其分为3类。
5.2.2 效果可视化
# 分为3类
model = KMeans(n_clusters = 3, random_state=12345)
kmeans = model.fit(k_data_scaler)
k_data['label'] = kmeans.labels_
k_data_scaler['label'] = kmeans.labels_
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(12, 8), dpi=200)
ax = Axes3D(fig, rect = [0,0,.95, 1], elev = 30, azim = -30)
ax1 = ax.scatter(k_data_scaler.query("label == 0").R, k_data_scaler.query("label == 0").F,
k_data_scaler.query("label == 0").M, edgecolor = 'k', color = 'r')
ax2 = ax.scatter(k_data_scaler.query("label == 1").R, k_data_scaler.query("label == 1").F,
k_data_scaler.query("label == 1").M, edgecolor = 'k', color = 'b')
ax3 = ax.scatter(k_data_scaler.query("label == 2").R, k_data_scaler.query("label == 2").F,
k_data_scaler.query("label == 2").M, edgecolor = 'k', color = 'c')
ax.legend([ax1, ax2, ax3], ['Cluster 1', 'Cluster 2', 'Cluster 3'])
ax.invert_xaxis()
ax.set_xlabel('R')
ax.set_ylabel('F')
ax.set_zlabel('M')
ax.set_title('K-Means Clusters')
plt.show()
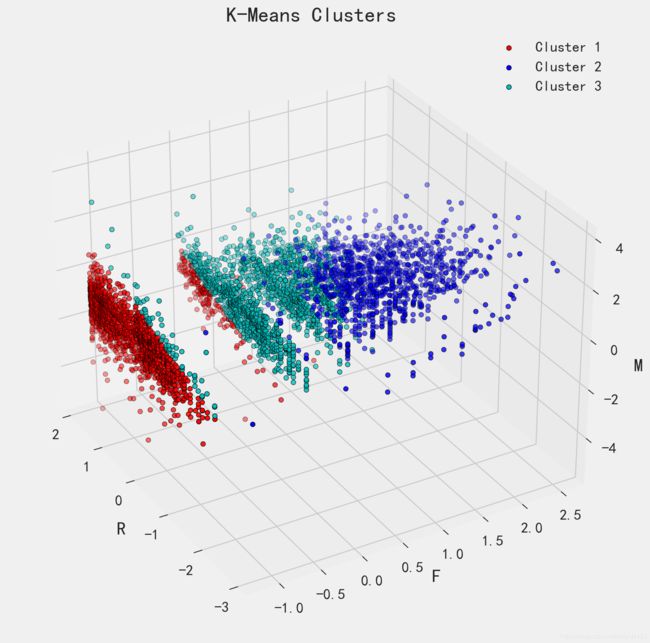
5.3 分析
# 选出每个客户的消费总金额,下单总数,下单的产品总数
data_temp = data.groupby('CustomerID').agg({'Quantity':np.sum, 'InvoiceNo':'nunique'})
kmeans_data = pd.concat([k_data, data_temp],axis=1)
kmeans_data.columns = ['最近消费天数', '消费次数', '消费金额', '客户等级', '购买商品总量','订单总量']
kmeans_level = customer_level_statistic(kmeans_data)
kmeans_level
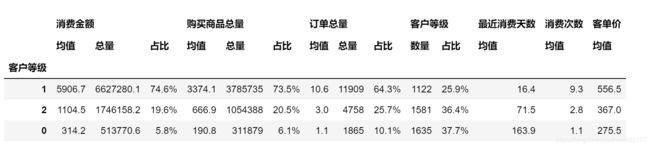
- 观察上表可以看到:
- 1类客户数量近四分之一的数量贡献了四分之三的价值,近似符合帕累托法则,为主要消费客户
- 2类客户对平台具有一定的价值,其最近消费的平均天数在三个月以内,可以采取一定措施来挽回此类客户。
- 0类客户消费人数距离最近购买的平均天数超过5个月,且其价值最低,已基本流失。
kmeans_level.index = ['重要价值客户', '中等价值客户', '低价值客户']
customer_level_pie(kmeans_level, 'K-Means')
customer_level_barh(kmeans_level)


6. 总结
无论是RFM模型还是基于RFM加权得分或者聚类算法得到的结果,都能够都可以在一定程度上较好的将客户分层。但三种方法都有使用场景,也都有局限性,
- RFM模型得到的不同层级的客户,可以采取针对性措施进行营销,但是销售场景受限。
- 加权得分可以根据不同的业务场景灵活的调整比重来划分客户层级,但权重的分配具有一定的主观性。
- 聚类则可以较好的区分出各层客户,对于业务来说解释性不够,数据更新前后的两次聚类结果,有的客户会被分为不同的层级,对于后续的操作比较麻烦。