DL--环境搭配
环境搭建
- 前言
- 一、我的平台
- 二、配置
-
- 1. wsl
- 2. GPU
- 3. Docker
- 3 Demo
前言
开启深度学习之旅,首先要确定 炼丹炉 放到什么地方,据了解,常规的平台组合有:
- win + anaconda
- win + wsl
- ubuntu + anaconda
- ubuntu + docker
上述是用的比较多的组合方式,当然,对于 GPU/CPU 以及 tensorflow/pytorch 是根据需求来的。
一、我的平台
我的电脑是 9300H+GTX1650 的组合,GPU 虽然有点 low,但聊胜于无,勉强凑合着用吧,毕竟是自己花的钱,太牛的搞不来。
经过今天一天的折腾,我决定选择:
win + wsl + docker的方式,主要考虑的因素有以下几点:
- 只有一台笔记本,无论是装双系统还是装
Linux,都会或多或少的影响后续其他工作的使用,也懒得折腾了,担心一不小心就变成砖; wsl不够稳定,会出现莫名其妙的错误,比如,pip3没反应,折腾了一周找不到原因,直接放弃anaconda创建环境和启动太慢docker的应用越来越广,尤其是到部署的时候,所以,有必要学习下使用 ,而且可以建立多个images,比wsl要实惠很多。
综上所述,决定采用win + wsl + docker的组合方式。
二、配置
1. wsl
wsl的安装与卸载网上的教程很多,在这里记录下个人常用的功能:
wsl 的操作是在 PowerShell 中进行的,打开方式就是快捷键 win + R,然后打开 cmd 即可
查看WSL
wsl --list
输出为:
PS C:\Users\ASUS> wsl --list
适用于 Linux 的 Windows 子系统分发版:
Ubuntu-20.04 (默认)
Ubuntu-18.04
注销
wsl --unregister Ubuntu-18.04
2. GPU
这是大事,你的电脑能不能用 GPU 就看这一步的,wsl 安装 cuda 主要有两个步骤:
步骤一
本机安装,从官网下载 wsl 专用的 nvidia 驱动软件
步骤二
wsl中安装 cuda-toolkit
主要过程为:
sudo apt-key adv --fetch-keys http://mirrors.aliyun.com/nvidia-cuda/ubuntu2004/x86_64/7fa2af80.pub
sudo sh -c 'echo "deb http://mirrors.aliyun.com/nvidia-cuda/ubuntu2004/x86_64 /" > /etc/apt/sources.list.d/cuda.list'
sudo apt-get update
sudo apt-get install -y cuda-toolkit-11-3
在安装过程中,如果遇到 NO_PUBKEY A4B469963BF863CC
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys A4B469963BF863CC
安装完成后,需要配置下环境变量 .bashrc,再尾部追加:
export CUDA_HOME=/usr/local/cuda
export PATH=$PATH:$CUDA_HOME/bin
export LD_LIBRARY_PATH=/usr/local/cuda-11.3/lib64
为确定是否完成安装,可通过 nvcc -V 查看,若安装正常,会有以下反馈:
z@LAPTO:~$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Mon_May__3_19:15:13_PDT_2021
Cuda compilation tools, release 11.3, V11.3.109
Build cuda_11.3.r11.3/compiler.29920130_0
或者编译一个 samples 校验:
cd /usr/local/cuda/samples/4_Finance/BlackScholes
sudo make
./BlackScholes
注:若 apt-key 操作异常,可直接将 pub 的数据 Ctrl + c 复制出来,然后保存到本地 *.pub,再通过 apt-key add 的方式添加。
3. Docker
相关资源设置:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
curl -s -L https://nvidia.github.io/libnvidia-container/experimental/$distribution/libnvidia-container-experimental.list | sudo tee /etc/apt/sources.list.d/libnvidia-container-experimental.list
nvidia-docker2安装
sudo apt-get update
sudo apt-get install -y nvidia-docker2
安装完记得重启下:
sudo service docker stop
sudo service docker start
装完后的测试:
sudo docker run --gpus all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark
若安装成功,则会出现:
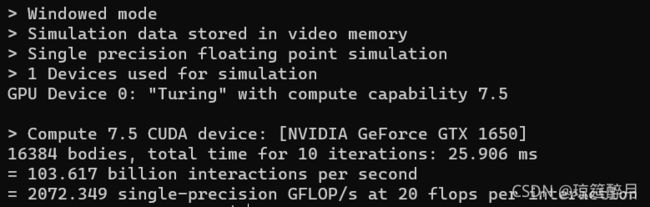
异常
关机重启后,出现 nvidia-docker 无法 run 的情况,报错提示为:
docker: Error response from daemon: Unknown runtime specified nvidia.
See 'docker run --help'.
解决方法为,修改 :/etc/docker/daemon.json 文件:
{
"registry-mirrors":[
"http://hub-mirror.c.163.com",
"https://reg-mirror.qiniu.com"],
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
3 Demo
运行 demo :
python3 demo.py --cfg_file cfgs/kitti_models/pv_rcnn.yaml --ckpt pv_rcnn_8369.pth --data_path 000001.bin
遇见的报错有:
2021-11-16 01:42:31,620 INFO -----------------Quick Demo of OpenPCDet-------------------------
2021-11-16 01:42:31,735 INFO Total number of samples: 1
/usr/local/lib/python3.6/dist-packages/torch/functional.py:445: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:2157.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
2021-11-16 01:42:41,023 INFO ==> Loading parameters from checkpoint pv_rcnn_8369.pth to CPU
2021-11-16 01:42:43,918 INFO ==> Done (loaded 367/367)
2021-11-16 01:42:44,093 INFO Visualized sample index: 1
Traceback (most recent call last):
File "demo.py", line 105, in <module>
main()
File "demo.py", line 93, in main
pred_dicts, _ = model.forward(data_dict)
File "/usr/local/lib/python3.6/dist-packages/pcdet/models/detectors/pv_rcnn.py", line 11, in forward
batch_dict = cur_module(batch_dict)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/pcdet/models/backbones_3d/spconv_backbone.py", line 147, in forward
x = self.conv_input(input_sp_tensor)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/spconv/modules.py", line 134, in forward
input = module(input)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/spconv/conv.py", line 181, in forward
use_hash=self.use_hash)
File "/usr/local/lib/python3.6/dist-packages/spconv/ops.py", line 95, in get_indice_pairs
int(use_hash))
ValueError: /root/spconv/src/spconv/spconv_ops.cc 87
unknown device type
没解决,放弃
2.
pip install pyyaml==5.4.1