深度学习入门:基于Python的理论与实现①
深度学习入门:基于Python的理论与实现①
- 机器学习的三大要素
- 第一章python入门
-
- 1.Numpy
-
- 1.1.numpy的N维数组
- 1.2.numpy广播
- 1.3访问元素
- 2.Matplotlib
- 第二章感知机
-
- 1.感知机是什么
- 2.感知机的实现
-
- 2.1简单的实现
- 2.2导入权重和偏置
- 3.多层感知机
- 第三章神经网络
-
- 1.从感知机到神经网络
-
- 1.1激活函数来源
- 2.激活函数
-
- 2.1sigmoid函数
- 2.2阶跃函数的实现
- 2.3阶跃函数的图形
- 2.4sigmoid函数的实现
- 2.5sigmoid函数和阶跃函数的比较
- 2.6非线性函数
- 2.7ReLU函数
- 3.多维数组的运算
-
- 3.1矩阵乘法
- 3.2神经网络的内积
- 4.三层神经网络的实现
- 5.输出层的设计
-
- 5.1恒等函数和softmax函数
机器学习的三大要素
(1)输入数据点。可以是记录人们说话声音的文件,也可以是图像。
(2)预期输出的示例。对于语音识别来说,可以是根据人们声音文件整理生成的文本;对于图像标记来说,可以是猫狗之类的标签。
(3)衡量算法好坏效果的方法。衡量结果是一种反馈信号,用于调节算法的工作方式。这个调节步骤就是我们所说的学习。
机器学习的技术定义:在预先定义好的可能性空间中,利用反馈信号的指引来寻找输入数据的有用表示。
神经网络中每层对输入数据所做的具体操作保存在该层的权重。
想要控制神经网络的输出,就需要能够衡量该 输出与预期值之间的距离。这是神经网络损失函数(loss function)的任务,该函数也叫目标函数(objective function)。
第一章python入门
1.Numpy
1.1.numpy的N维数组
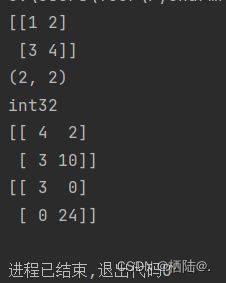
生成二维数组(矩阵):
import numpy as np
x = np.array([1.0, 2.0, 3.0])
print(x)
print(type(x))
A = np.array([[1,2], [3,4]])
print(A)
print(A.shape)
print(A.dtype)
运行结果:

Python 中使用 import语句来导入库。这里的 import numpy as np,直译的话就是“将numpy作为np导入”的意思。通过写成这样的形式,之后 NumPy相关的方法均可通过np来调用。
这里生成的A为一个2×2矩阵,矩阵A的形状可以通过shape查看, 矩阵元素的数据类型可以通过dtype查看。
矩阵的算术运算
import numpy as np
A = np.array([[1,2], [3,4]])
print(A)
print(A.shape)
print(A.dtype)
B = np.array([[3,0], [0,6]])
print(A+B)
print(A * B)
【注】数学上将一维数组称为向量, 将二维数组称为矩阵。本书将三维数组及三维以上数组称为“张量”或”多维数组“。
1.2.numpy广播
广播(Broadcast)是 numpy 对不同形状(shape)的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行。
如果两个数组 a 和 b 形状相同,即满足 a.shape == b.shape,那么 a*b 的结果就是 a 与 b 数组对应位相乘。这要求维数相同,且各维度的长度相同。
当运算中的 2 个数组的形状不同时,numpy 将自动触发广播机制。
import numpy as np
A = np.array([[1,2], [3,4]])
B = np.array([10,20])
print(A * B)
运行结果:
[[10 40]
[30 80]]
1.3访问元素
①X[i][j]直接访问第i行第j列的元素
②for row in X , 遍历所有元素
③X = X.flatten(),将X转换为一维数组再输出
2.Matplotlib
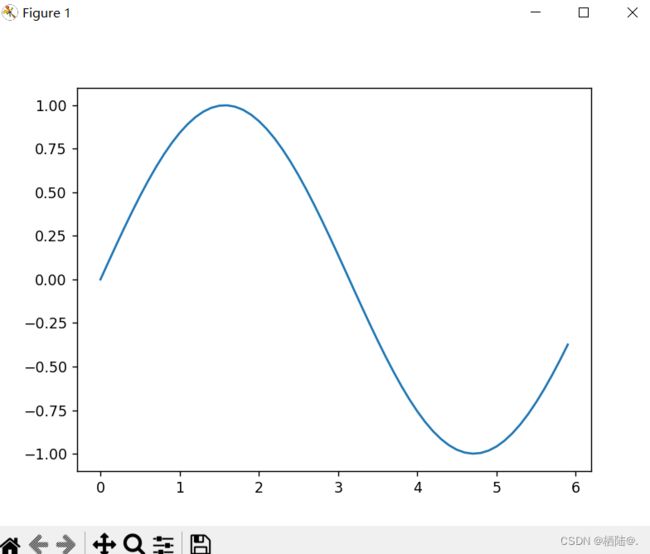
Matplotlib 是用于绘制图形的库,使用Matplotlib可以轻松地绘制图形和实现数据的可视化。
import numpy as np
import matplotlib.pyplot as plt
#生成数据
x = np.arange(0, 6, 0.1) #以0.1为单位,生成0-6的数据
y = np.sin(x)
#绘制图形
plt.plot(x,y)
plt.show()
这里使用NumPy的arange方法生成了[0, 0.1, 0.2 … 5.8, 5.9]的 数据,将其设为x。对x的各个元素,应用NumPy的sin函数np.sin(),将x、 y的数据传给plt.plot方法,然后绘制图形。最后,通过plt.show()显示图形。
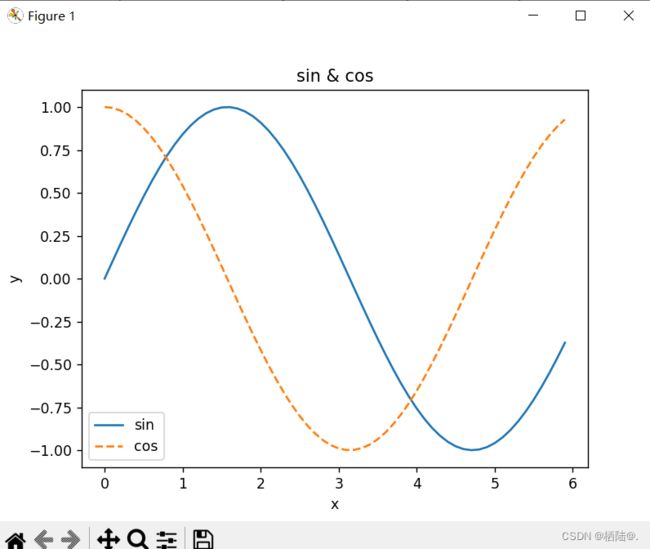
再完善一下
import numpy as np
import matplotlib.pyplot as plt
#生成数据
x = np.arange(0, 6, 0.1) #以0.1为单位,生成0-6的数据
y1 = np.sin(x)
y2 = np.cos(x)
#绘制图形
plt.plot(x, y1, label = "sin")
plt.plot(x, y2, linestyle = "--", label="cos")#用虚线绘制
plt.xlabel("x")
plt.ylabel("y") #x,y的标签
plt.title('sin & cos') #标题
plt.legend()
plt.show()
第二章感知机
1.感知机是什么
感知机接收多个输入信号,输出一个信号。感知机的信号只有“流/不流”(1/0)两种取值,0 对应“不传递信号”,1对应“传递信号”。
如图,x1、x2是输入信号, y是输出信号,w1、w2是权重(w是weight的首字母)。图中的○称为“神经元”或者“节点”。输入信号被送往神经元时,会被分别乘以固定的权重(w1x1、w2x2。神经元会计算传送过来的信号的总和,只有当这个总和超过了某个界限值时,才会输出1。这也称为“神经元被激活”。这里将这个界 限值称为阈值,用符号θ表示。

数学公式表达:
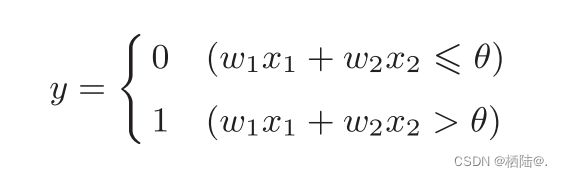
感知机的多个输入信号都有各自固有的权重,这些权重发挥着控制各个信号的重要性的作用。也就是说,权重越大,对应该权重的信号的重要性就越高。
2.感知机的实现
2.1简单的实现
def AND(x1, x2):
w1, w2, theta = 0.5, 0.5, 0.7
tmp = x1*w1 + x2*w2
if tmp <= theta:
return 0
elif tmp > theta:
return 1
输出结果:
AND(0, 0) # 输出0
AND(1, 0) # 输出0
AND(0, 1) # 输出0
AND(1, 1) # 输出1
即实现与门。
2.2导入权重和偏置
将前文数学公式中的θ换成−b,公式可改写为:

b称为偏置,w1和w2称为权重。
import numpy as np
def AND(x1, x2):
x = np.array([x1,x2]) #输入
w = np.array([0.5, 0.5]) #权重
b = -0.7 #偏置
tmp = np.sum(w*x) + b
if tmp <= 0:
return 0
else:
return 1
print(AND(1,1)) #与门
def NAND(x1, x2):
x = np.array([x1, x2])
w = np.array([-0.5, -0.5]) # 仅权重和偏置与AND不同!
b = 0.7
tmp = np.sum(w*x) + b
if tmp <= 0:
return 0
else:
return 1 #非门
def OR(x1, x2):
x = np.array([x1, x2])
w = np.array([0.5, 0.5]) # 仅权重和偏置与AND不同!
b = -0.2
tmp = np.sum(w*x) + b
if tmp <= 0:
return 0
else:
return 1 #或门
感知机的局限性:感知机无法实现异或门。
3.多层感知机
感知机的绝妙之处在于它可以“叠加层”,通过组合感知机(叠加层)就可以实现异或门。(通过组合与门、与非门、或门实现异或门)

下为真值表

def XOR(x1, x2):
s1 = NAND(x1, x2)
s2 = OR(x1, x2)
y = AND(s1, s2)
return y
#使用之前定义的AND函数、NAND函数、OR函数来实现
在这里的异或门是一种多层结构的神经网络。将最左边的 一列称为第0层,中间的一列称为第1层,最右边的一列称为第2层。
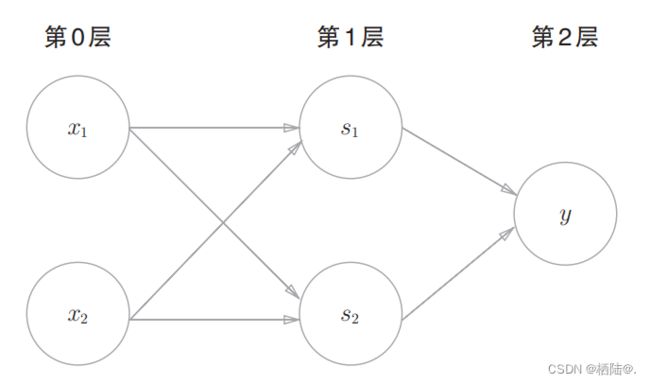
与门、或门是单层感知机,而异或门是2层感知机。叠加了多 层的感知机也称为多层感知机(multi-layered perceptron)。
第三章神经网络
1.从感知机到神经网络
用图来表示神经网络的话,如图所示。我们把最左边的一列称为输入层,最右边的一列称为输出层,中间的一列称为中间层。中间层有时也称为隐藏层。“隐藏”一词的意思是,隐藏层的神经元(和输入层、输出 层不同)肉眼看不见。第0层对应输入层,第1层对应中间层,第2层对应输出层。

1.1激活函数来源

改写为下式
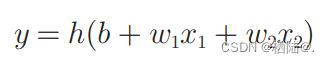
最后改写为

h(x)函数会将输入信号的总和转换为输出信号,这种函数 一般称为激活函数(activation function)。如“激活”一词所示,激活函数的 作用在于决定如何来激活输入信号的总和。
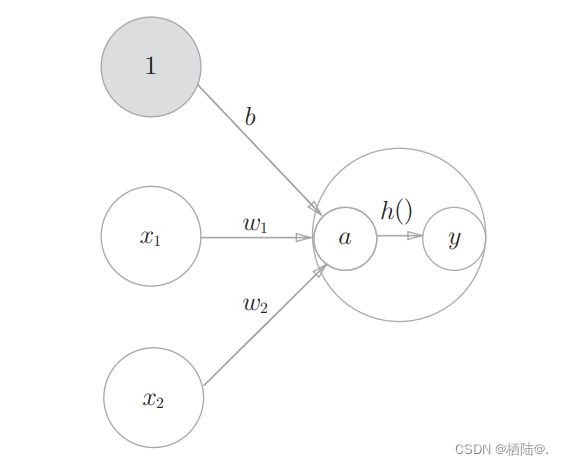
如图所示,表示神经元的○中明确显示了激活函数的计算过程,即信号的加权总和为节点a,然后节点a被激活函数h()转换成节点y。【注】此处的节点和前文神经元含义相同。
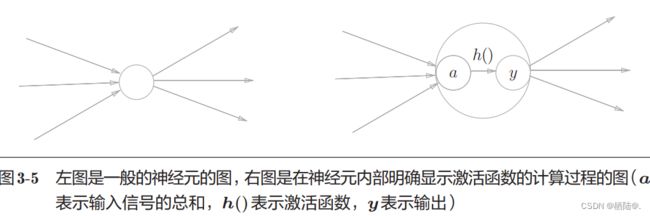
一 般而言,“朴素感知机”是指单层网络,指的是激活函数使用了阶跃函数(指一旦输入超过阈值,就切换输出的函数)的模型。“多层感知机”是指神经网络,即使用 sigmoid 函数(后述)等平滑的激活函数的多层网络。
2.激活函数
说感知机中使用了阶跃函数作为激活函数。如果将激活函数从阶跃函数换成其他函数,就可以进入神经网络的世界了。实际上,感知机和神经网络主要区别就在于激活函数的不同。
2.1sigmoid函数
神经网络中经常使用的一个激活函数就是式表示的sigmoid函数 (sigmoid function)

2.2阶跃函数的实现
def step_function(x):
y = x > 0
return y.astype(np.int)
对NumPy数组进行不等号运算后,数组的各个元素都会进行不等号运算, 生成一个布尔型数组。这里,数组x中大于0的元素被转换为True,小于等于0的元素被转换为False,从而生成一个新的数组y。 数组y是一个布尔型数组,但是我们想要的阶跃函数是会输出int型的0或1的函数。因此,需要把数组y的元素类型从布尔型转换为int型。
import numpy as np
x = np.array([-1.0,1.0,2.0])
print(x)
y = x > 0
print(y)
y = y.astype(np.int)
print(y)
输出:
[-1. 1. 2.]
[False True True]
[0 1 1]
如上所示,可以用astype()方法转换NumPy数组的类型。astype()方 法通过参数指定期望的类型,这个例子中是np.int型。Python中将布尔型 转换为int型后,True会转换为1,False会转换为0。
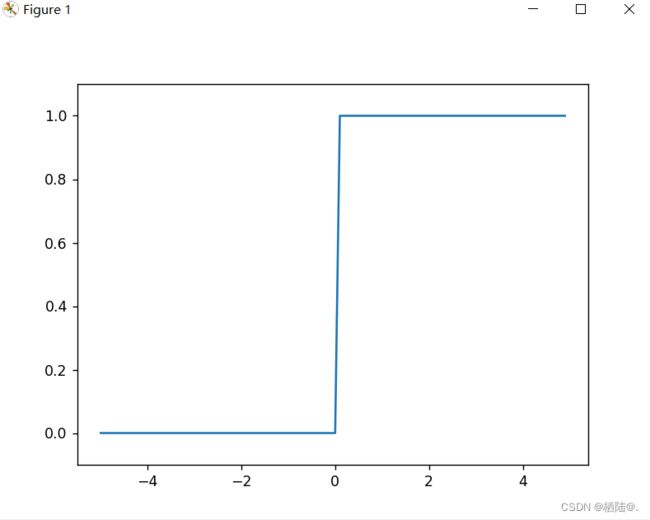
2.3阶跃函数的图形
用图表示上述定义的阶跃函数,需要使用matplotlib库。
import numpy as np
import matplotlib.pylab as plt
def step_function(x):
return np.array(x > 0, dtype=np.int)
x = np.arange(-5.0, 5.0, 0.1) #在−5.0到5.0的范围内,以0.1为单位,生成Numpy数组
y = step_function(x)
plt.plot(x,y)
plt.ylim(-0.1, 1.1) #指定y轴范围
plt.show()
2.4sigmoid函数的实现

sigmoid函数的实现能支持NumPy数组,根据NumPy 的广播功能,如果在标量和NumPy数组之间进行运算,则标量会和NumPy数组的各个元素进行运算。
画图:
import numpy as np
import matplotlib.pylab as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x)) #此处即为sigmoid函数
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x,y)
plt.ylim(-0.1, 1.1) #指定y轴范围
plt.show()
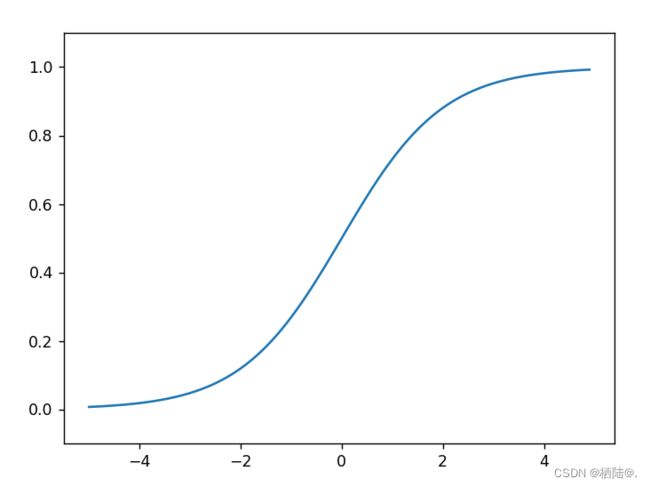
画图的代码和刚才的阶跃函数的代 码几乎是一样的,唯一不同的地方是把输出y的函数换成了sigmoid函数。
2.5sigmoid函数和阶跃函数的比较
首先注意到的是“平滑性”的不同。sigmoid函数是一条平滑的曲线,输出随着输入发生连续性的变化。而阶跃函数以0为界,输出发生急剧性的变化。sigmoid函数的平滑性对神经网络的学习具有重要意义。
另一个不同点是,相对于阶跃函数只能返回0或1,sigmoid函数可以返 回0.731 …、0.880 …等实数(这一点和刚才的平滑性有关)。也就是说,感知机中神经元之间流动的是0或1的二元信号,而神经网络中流动的是连续的实数值信号。
共同性质:它们具有相似的形状,两者的结构均是“输入小时,输出接近0(为0); 随着输入增大,输出向1靠近(变成1)”。还有一个共同点是,不管输入信号有多小,或者有多 大,输出信号的值都在0到1之间。
2.6非线性函数
阶跃函数和sigmoid函数还有其他共同点,就是两者均为非线性函数。 sigmoid函数是一条曲线,阶跃函数是一条像阶梯一样的折线,两者都属于非线性的函数。
为了发挥叠加层所 带来的优势,激活函数必须使用非线性函数。
2.7ReLU函数
ReLU函数在输入大于0时,直接输出该值;在输入小于等于0时,输出0。
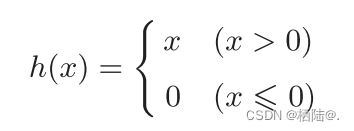
def relu(x):
return np.maximum(0, x)
3.多维数组的运算
3.1矩阵乘法
import numpy as np
A = np.array([[1,2], [3,4]])
B = np.array([[5,6], [7,8]])
print(np.dot(A, B))
输出结果:
[[19 22]
[43 50]]
它 们 的 乘 积 可 以 通 过 NumPy 的 np.dot()函数计算(乘积也称为点积)。np.dot()接收两个NumPy数组作为参 数,并返回数组的乘积。
【注】A×B中A的列数要等于B的行数。
3.2神经网络的内积
下面我们使用NumPy矩阵来实现神经网络。这个神经网络省略了偏置和激活函数,只有权重。

import numpy as np
X = np.array([1,2]) #x1,x2的值
W = np.array([[1,3,5],[2,4,6]]) #权重构成的矩阵
Y = np.dot(X, W)
print(Y)
4.三层神经网络的实现
import numpy as np
def sigmoid(x): #sigmoid为激活函数
return 1 / (1 + np.exp(-x))
def identity_function(x):
return x
def init_network(): #用于进行权重和偏置的初始化,并将它们保存在字典变量network中
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
def forward(network, x): #用于封装将输入信号转换为输出信号的处理过程
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y)
5.输出层的设计
机器学习的问题大致可以分为分类问题和回归问题。需要根据情况改变输出 层的激活函数。一般而言,回归问题用恒等函数,分类问题用softmax函数。
5.1恒等函数和softmax函数
恒等函数会将输入按原样输出,对于输入的信息,不加以任何改动地直接输出。和前面的隐藏层的激活函数一样,恒等函数进行的转换处理可以 用一根箭头来表示。
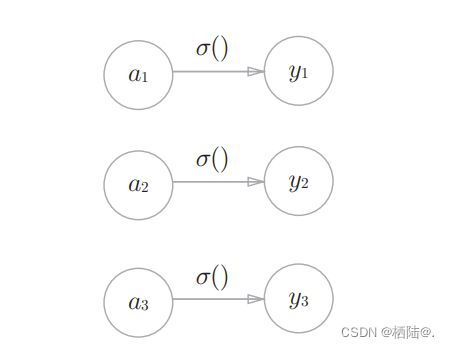
分类问题中使用的softmax函数可以用下面的式表示:

softmax函数 的输出通过箭头与所有的输入信号相连。输出层的各个神经元都受到所有输入信号的影响。
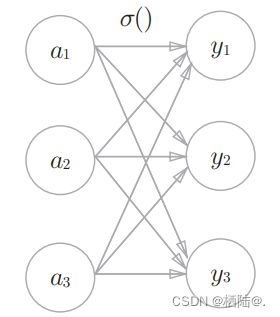
import numpy as np
def softmax(a):
exp_a = np.exp(a) #指数函数
sum_exp_a = np.sum(exp_a) #指数函数的和
y = exp_a / sum_exp_a
return y
softmax函数的输出是0.0到1.0之间的实数。并且,softmax 函数的输出值的总和是1。输出总和为1是softmax函数的一个重要性质。正因为有了这个性质,我们才可以把softmax函数的输出解释为“概率”。
前三张内容先到这啦_