nlp 中文文本纠错_最全NLP中文文本分类实践(中)——SVM和基于keras的TextCNN实现...
在上一篇文章中,我们获取了分词的向量表达,接下来要考虑怎么样构建模型。在这一部分,我将分别按普通的机器学习分类器和稍复杂的神经网络TextCNN模型两个部分来进行功能的实现。关于上一篇文章的详细内容请查看下面的链接。
不忘初心:最全NLP中文文本分类实践(上)——中文分词获取和Word2Vec模型构建zhuanlan.zhihu.com
1 SVM实现
我们确实拥有了词的向量表达,可是,每个文章都包含不同数量的单词,我们怎么样用训练出来的词向量表示不同的文章呢?在这里,我用的是计算平均词向量来表示文档的方法。这其实挺好理解的,就是文章内包含的所有词的向量相加再取平均,这样,我们就可以得到一个和词向量维度相同的指示文章信息的向量。
import numpy as np
#num_features表示的文本单词大小
def average_word_vectors(words,model,vocabulary,num_features):
feature_vector=np.zeros((num_features,),dtype='float64')
nwords=0
for word in words:
if word in vocabulary:
nwords=nwords+1
feature_vector=np.add(feature_vector,model[word])
if nwords:
feature_vector=np.divide(feature_vector,nwords)
return feature_vector
def averaged_word_vectorizer(corpus,model,num_features):
#get the all vocabulary
vocabulary=set(model.wv.index2word)
features=[average_word_vectors(tokenized_sentence,model,vocabulary,num_features) for tokenized_sentence in corpus]
return np.array(features)
def get_word_vectors(data):
words_art=[]
for i in range(len(data)):
words_art.append(eval(data.loc[i]))
return averaged_word_vectorizer(words_art,model=w2vmodel,num_features=300)计算平均向量的函数已经写好了,下面我们就把他应用到我们预先保存好以文章形式保存的分词列表上。
w2v_model = gensim.models.KeyedVectors.load_word2vec_format('word2vec_ensemble.txt',binary=False)
train = pd.read_csv('article_features_train.csv')
test = pd.read_csv('article_features_test.csv')
X_train = get_word_vectors(train.Words)
y_train = train.label
X_test = get_word_vectors(test.Words)
y_test = test.label接下来,利用GridSearchCV来找到设置条件下f1_macro最高的模型。
from sklearn import svm
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import f1_score
clf = svm.SVC()
grid_values = {'gamma': [0.001, 0.01, 0.05, 0.1, 1, 10],
'C':[0.01, 0.1, 1, 10, 100]}
grid_clf = GridSearchCV(clf, param_grid = grid_values,scoring = 'f1_macro')
grid_clf.fit(X_train, y_train)
y_grid_pred = grid_clf.predict(X_test)
print('Test set F1: ', f1_score(y_test,y_grid_pred,average='macro'))
print('Grid best parameter (max. f1): ', grid_clf.best_params_)
print('Grid best score (accuracy): ', grid_clf.best_score_)在我的测试中,我得到的模型效果最好的参数是{'C': 10, 'gamma': 1}。将这些参数重新设置训练并保存模型。
from sklearn.externals import joblib
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
clf = svm.SVC(C=10, gamma= 1,probability=True).fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
joblib.dump(clf, "download_w2v_svm.m")最终,这个SVM模型我得到了89.48%的accuracy和87.42%的macro f1。我们把confusion matrix绘制一下。
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib
cm = confusion_matrix(y_test,y_pred)
#绘制confusion matrix
print("Confusion Matrix")
category_labels = ['Space ','Computer ','Art ', 'Environment ', 'Agriculture ', 'Economy ','Politics ','Sports ','History ']
cm_normalised = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
sns.set(font_scale=1.5)
fig, ax = plt.subplots(figsize=(10,10))
ax = sns.heatmap(cm_normalised, annot=True, linewidths=1, square=False,
cmap="Greens", yticklabels=category_labels, xticklabels=category_labels, vmin=0, vmax=np.max(cm_normalised),
fmt=".2f", annot_kws={"size": 20})
ax.set(xlabel='Predicted label', ylabel='True label')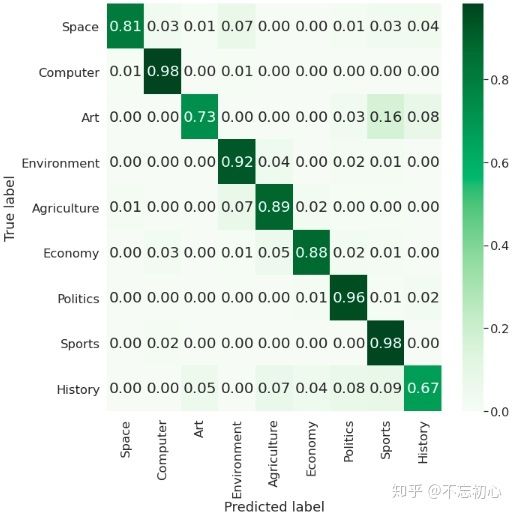
2 TextCNN实现
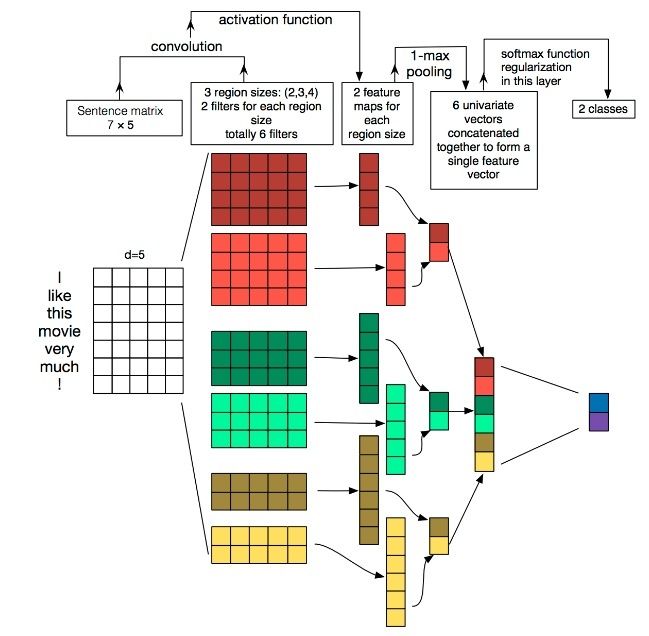
除了简单的SVM等机器学习分类器,我们当然要尝试构建一下神经网络。虽然CNN被广泛应用于图像处理之中,但是在文本处理里也有其用武之地。下面我们将构建TextCNN模型实现分类任务。 首先,我们先要对word2vec模型进行预处理。TextCNN中的Embedding层需要我们把分词转化成index,因此我们把模型中的词转化成一个字典以[word : index]保存起来,方便日后的处理。
#导入word2vec模型并进行预处理
def w2v_model_preprocessing():
#导入模型
w2v_model = gensim.models.KeyedVectors.load_word2vec_format('word2vec_ensemble.txt',binary=False)
word2idx = {"_PAD": 0} # 初始化 `[word : index]` 字典
vocab_list = [(k, w2v_model.wv[k]) for k, v in w2v_model.wv.vocab.items()]
# 存储所有 word2vec 中所有向量的数组,其中多一位,词向量全为 0, 用于 padding
embeddings_matrix = np.zeros((len(w2v_model.wv.vocab.items()) + 1, w2v_model.vector_size))
#填充字典和矩阵
for i in range(len(vocab_list)):
word = vocab_list[i][0]
word2idx[word] = i + 1
embeddings_matrix[i + 1] = vocab_list[i][1]
return w2v_model,word2idx,embeddings_matrix
w2v_model,word2idx,embeddings_matrix = w2v_model_preprocessing()同样地,我们依然面临着与构建SVM时相同的问题:怎么处理文章长度的不同。在此,我们考虑截断的解决方法,即预先规定一个长度,不足则在后面补零,超出则舍去后面全部内容,以此来达到长度一致的目的。
from tensorflow.keras.preprocessing.sequence import pad_sequences
def get_words(data):
words_art=[]
for i in range(len(data)):
words_art.append(eval(data.loc[i]))
return words_art
#将获取的中文分词用生成的字典进行转化。获取长度同为maxlen的分词index数组,若超过则截断,不足则在后面补零
#text为文本,word_index为字典,maxlen为要保存数组的长度
def get_words_index(text, word_index,maxlen):
texts = get_words(text)
data = []
for sentence in texts:
new_txt = []
for word in sentence:
try:
new_txt.append(word_index[word]) # 把句子中的分词转化为index
except:
new_txt.append(0)
data.append(new_txt)
texts = pad_sequences(data, maxlen = maxlen,padding = 'post') # 使用kears的内置函数padding对齐句子
return texts接下来,我们读取文件,将文章的分词转化成index的形式。训练集每个文章长度,即所包含单词的数量分布如下图所示。
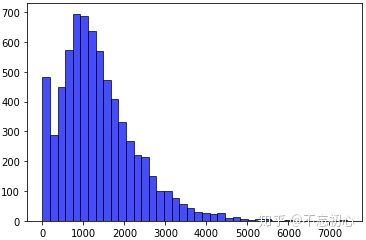
在本次实践过程中,我们将截断长度设置为1000。
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
MAX_LENGTH = 1000
#载入训练集和测试集数据
train = pd.read_csv('article_features_train.csv')
test = pd.read_csv('article_features_test.csv')
#训练集数据预处理
X_train = get_words_index(train.Words,word2idx,MAX_LENGTH) # 获取分词index
y_train = train.label #获取label
y_train = to_categorical(y_train, num_classes=9) # 将标签转化为one-hot形式保存
#划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train)
#测试集数据预处理
X_test = get_words_index(test.Words,word2idx,MAX_LENGTH) # 获取分词index
y_test = test.label
y_test = to_categorical(y_test, num_classes=9) # 将标签转化为one-hot形式保存
print("Dataset load finished.")数据已经加载并处理完毕,下面我们可以开始构建TextCNN模型了。
from tensorflow.keras.models import Sequential,Model
from tensorflow.keras.models import load_model
from tensorflow.keras.layers import Dense,Dropout,Activation,Input, Lambda, Reshape,concatenate
from tensorflow.keras.layers import Embedding,Conv1D,MaxPooling1D,GlobalMaxPooling1D,Flatten,BatchNormalization
from tensorflow.keras.losses import categorical_crossentropy
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.regularizers import l2
def build_textcnn():
#构建textCNN模型
# word2vec预处理
w2v_model_preprocessing()
main_input = Input(shape=(MAX_LENGTH,), dtype='float64')
# 词嵌入(使用预训练的词向量)
embedder = Embedding(
len(embeddings_matrix), #表示文本数据中词汇的取值可能数,从语料库之中保留多少个单词
300, # 嵌入单词的向量空间的大小
input_length=MAX_LENGTH, #规定长度
weights=[embeddings_matrix],# 输入序列的长度,也就是一次输入带有的词汇个数
trainable=False # 设置词向量不作为参数进行更新
)
embed = embedder(main_input)
# 词窗大小分别为3,4,5
cnn1 = Conv1D(256, 3, padding='same', strides=1, activation='relu',kernel_regularizer=l2(0.05))(embed)
cnn1 = MaxPooling1D(pool_size=4)(cnn1)
cnn2 = Conv1D(256, 4, padding='same', strides=1, activation='relu',kernel_regularizer=l2(0.05))(embed)
cnn2 = MaxPooling1D(pool_size=4)(cnn2)
cnn3 = Conv1D(256, 5, padding='same', strides=1, activation='relu',kernel_regularizer=l2(0.005))(embed)
cnn3 = MaxPooling1D(pool_size=4)(cnn3)
# 合并三个模型的输出向量
cnn = concatenate([cnn1, cnn2, cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.5)(flat)
main_output = Dense(9, activation='softmax')(drop)
model = Model(inputs=main_input, outputs=main_output)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
return model模型构建完毕,下面继续运行该模型进行训练
def run_textcnn(model):
# 运行textCNN模型
# 声明回调函数
lr_reducer = ReduceLROnPlateau(monitor='val_loss', factor=0.9, patience=3, verbose=1) # 学习率降低
tensorboard = TensorBoard(log_dir='./logs_textcnn') #保存日志
early_stopper = EarlyStopping(monitor='val_loss', min_delta=0, patience=8, verbose=1, mode='auto')
checkpointer = ModelCheckpoint("weights_textcnn.best.hdf5", monitor='val_loss', verbose=1, save_best_only=True) #增加checkpoint
# 模型训练
history = model.fit(X_train, y_train,
batch_size=64,
epochs=10,
verbose=1,
validation_data=(X_val,y_val),
shuffle=True,
callbacks=[lr_reducer, checkpointer, tensorboard, early_stopper])
# 模型保存
model.save('textcnn.h5')
print('Model Saved!')
#保存训练集和验证集的accuracy和loss
acc=history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
np_acc = np.array(acc).reshape((1,len(acc))) #reshape是为了能够跟别的信息组成矩阵一起存储
np_valacc = np.array(val_acc).reshape((1,len(val_acc)))
np_loss =np.array(loss).reshape((1,len(loss)))
np_valloss = np.array(val_loss).reshape((1,len(val_loss)))
np_out = np.concatenate([np_acc,np_valacc,np_loss,np_valloss],axis=0)
np.savetxt('textcnn_history.txt',np_out)
print("File Saved!")
return history
model = build_textcnn()
history = run_textcnn(model)此时模型也已经训练完了,我们用它来验证测试集,看看其表现如何。
import h5py
import seaborn as sns
from tensorflow.keras.models import load_model
def evaluate_textcnn(modelpath):
#查看textCNN表现
# 加载模型并获取预测label
model = load_model(modelpath)
y_pred = model.predict(X_test, batch_size=64, verbose=0, steps=None, callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False)
y_pred = np.rint(y_pred)
cm = confusion_matrix(y_test.argmax(axis=1), y_pred.argmax(axis=1))
#绘制confusion matrix
category_labels = ['Space','Computer','Art', 'Environment', 'Agriculture', 'Economy','Politics','Sports','History']
cm_normalised = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
sns.set(font_scale=1.5)
fig, ax = plt.subplots(figsize=(10,10))
ax = sns.heatmap(cm_normalised, annot=True, linewidths=0, square=False,
cmap="Greens", yticklabels=category_labels, xticklabels=category_labels, vmin=0, vmax=np.max(cm_normalised),
fmt=".2f", annot_kws={"size": 20})
ax.set(xlabel='Predicted label', ylabel='True label')
#打印classification report
print("Classification Report")
print(classification_report(y_test, y_pred, digits=4))
evaluate_textcnn('textcnn.h5')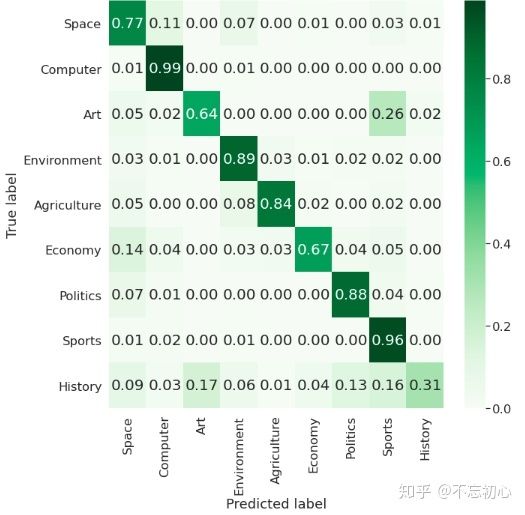
最终,我们的TextCNN只达到了80%左右的macro f1。这相比SVM可以说差的很多。
3 小结
本文利用SVM和TextCNN模型对中文文本分类任务进行实践。通过比较,我们发现相较于结构更加复杂训练更“深”的TextCNN,SVM分类器的表现反而更好。在TextCNN上,模型呈现出过拟合的趋势,即使经过多次调参,验证集在最多在达到百分之九十左右时就基本上没有提升了,但是训练集甚至可以达到99%之多。此外,History类别在两个分类器下的表现都是较差,这在TextCNN上尤为明显。
针对于这样的现象,我认为其中一个原因可能是数据的规模还没有这么大,利用SVM已经可以呈现出不错的效果,并不需要对它来说过于复杂的神经网络进行训练。还有一个原因,恐怕是特征工程做的不够,即词向量的模型还不够完善。之前看到一个分析说,特征工程决定了之后模型表现的上限,而模型的选择调参等决定了你能多大程度逼近这个上限。因此,特征工程不足也是模型表现如此的一个合理推测。
下一节,我将利用模型融合,尝试去提升模型的表现和各项指标。感谢支持,希望多多关注!