卷积神经网络模型的搭建与应用(手写数字集)
本文是基于Tensorflow库搭建的卷积神经网络模型,训练数据集为MNIST,话不多说,直接上代码,如下:
一、数据读取及预处理
# 加载库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
#读取数据
mnist = np.load('mnist.npz',allow_pickle=True)
mnist.files # 查看数据文件
# 数据归一化
# 将数据的取值范围限制在0-1之间
X_train = mnist['x_train']/255 # 原取值范围0-255,故除以255,则取值范围0-1
X_test = mnist['x_test']/255
y_train = mnist['y_train'] # 标签
y_test = mnist['y_test']
# 转换数据维度
# 模型只能接收四维的数据
X_train = X_train.reshape([-1,28,28,1]) # -1表示自适应计算该处的值
X_test = X_test.reshape([-1,28,28,1]) 二、搭建卷积神经网络模型
# 搭建卷积神经网络模型
model = tf.keras.models.Sequential() # 定义序列化模型
# 6个5*5的卷积核(滤波器),输入形状为28*28*1个输入通道,激活函数为relu
model.add(tf.keras.layers.Conv2D(6,5,input_shape=(28,28,1),activation='relu')
# 最大池化层
model.add(tf.keras.layers.MaxPool2D(2,2))
# 第二层卷积
model.add(tf.keras.layers.Conv2D(16,5,activation='relu'))
# 最大池化层
model.add(tf.keras.layers.MaxPool2D(2,2))
# 展平层
model.add(tf.keras.Flatten()) # 将数据铺平成一维数组
# 全连接层
model.add(tf.keras.layers.Dense(120,activation='relu'))
model.add(tf.keras.layers.Dense(84,activation='relu'))
model.add(tf.keras.layers.Dense(10,activation='softmax'))本文模型的构建依照传统的CNN卷积神经网络层数及参数搭建,如下:
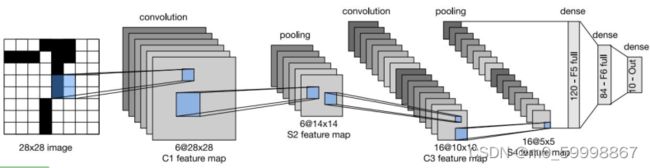
查看模型结构:
model.summary()
搭建的模型结果如下:

三、训练模型及评估
# 模型编译
model.compile(loss='sparse_categorical_crossentropy', # 损失函数
optimizer = 'adam', # 优化器
metrics = ['accuracy'] # 模型评估指标
)
# 训练模型
model.fit(X_train,y_train,epochs=10,verbse=1)
# 模型评估
score = model.evaluate(X_test,y_test,batch_size=32) # 评估模型得分
# 模型保存
model.save('let_net.h5')四、模型的应用
(1)单个手写数字图像预测
# 加载模型
model = tf.keras.models.load_model('let_net.h5')# 读取图像
img = plt.imread('./data/test/2_4.jpg)
plt.imshow(img,cmap='gray')
plt.show()# 修改维度,并进行归一化
img.shape
img = img.reshape([-1,28,28,1])/255# 预测数据的标签
predicted = model.predict(img,verbose=1)# 输出预测的标签数值
predicted.argmax(axis=1)[0]
(2)批量图像预测标签
# 读取数据
import glob
image_names = glob.glob('./data/test/*.jpg') #读取文件中的所有图像名
# 批量读取预测图像标签
# 用已训练好的模型model直接预测
for name in image_names:
image = plt.imread(name)
image = image.reshape([-1,28,28,1])/255
predicted = model.predict(image)
result = predicted.argmax(axis=1)[0]
print('照片{}中的数字是:{}'.format(name,result))部分预测结果如下:

其中文件名的最后一个数字为样本的真实标签,若预测的数字与其对应,则说明预测结果正确。从结果可以看出,预测效果不错,准确率基本达到了百分之九十多。