[Pytorch系列-40]:卷积神经网络 - 模型的恢复/加载 - 搭建LeNet-5网络与MNIST数据集手写数字识别
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121132377
目录
第1章 模型的恢复与加载
1.1 概述
1.2 模型的恢复与加载类型
1.3 模型的保存的API函数:代码示例
1.4 模型的恢复与加载的API函数:代码示例
第2章 定义前向运算:加载CFAR10数据集
2.1 前置条件
2.2 定义数据预处理(数据强化)
2.3 下载并加载数据集
2.4 定义batch Loader
2.5 可视化部分数据集数据
第3章 定义前向运算:加载网络/模型
3.1 定义网络 (可选,仅供个人学习时的比较)
3.2 生成网络 (可选,仅供个人学习时的比较)
3.3 加载已经训练过的模型/网络
3.4 测试加载的网络的输出
3.5 选择后续进一步处理的网络
3.6 加载后网络的使用
第4章 定义反向运算:损失函数与优化器(可选)
4.1 定义损失函数
4.2 定义优化器
第5章 定义反向运算:模型训练
5.1 训练前的准备
5.2 开始训练 (可选,仅用于需要进一步训练的场合)
5.3 说明
第6章 模型评估 - 训练过程(可选,仅用于需要进一步训练的场合)
6.1 可视化loss迭代过程
6.2 可视化精度变化过程
第7章 模型评估 - 训练结果
7.1 手工验证
7.2 训练集上的验证
7.3 在测试集上的验证
第8章 模型的存储与保存 (可选,如果需要保存新参数)
第1章 模型的恢复与加载
1.1 概述
深度学习的模型训练时一个漫长的过程,保存已有的模型就显得非常重要,保存的目的是为了后续进一步的使用,包括:
(1)在已有模型的基础之上进一步的训练(fine tunning)
(2)直接利用已有的模型进行预测
1.2 模型的恢复与加载类型
(1)加载自定义的模型以及相应的训练参数:任意模型
(2)加载自定义的模型的训练参数:需要当前的网络模型与加载参数对应的网络模型一致
(3)加载Pytorch预训练模型以及相应的参数(与第一种方式本质是一致的)
1.3 模型的保存的API函数:代码示例
(1)保存模型(包括模型结构与参数)
#存储模型
torch.save(net, "models/lenet_cifar10_model.pkl")(2)保存模板参数
#存储参数
torch.save(net.state_dict() , "models/lenet_cifar10_model_params.pkl")(3)代码实例
[Pytorch系列-34]:卷积神经网络 - 搭建LeNet-5网络与MNIST数据集手写数字识别(模型保存)_文火冰糖(王文兵)的博客-CSDN博客 https://blog.csdn.net/HiWangWenBing/article/details/121050469
https://blog.csdn.net/HiWangWenBing/article/details/121050469
1.4 模型的恢复与加载的API函数:代码示例
(1)恢复模型(包括模型结构与参数)
net_a_load = torch.load("models/lenet_cifar10_model.pkl")备注:
本文关注模型的恢复/加载。
(2)恢复模型参数
# 从模型文件中加载模型参数
MODEL_PARAM_PATH = "models/lenet_cifar10_model_params.pkl"
net_params = torch.load(MODEL_PARAM_PATH)
print(net_params)# 把加载的参数应用到模型中
net_a.load_state_dict(net_params)
print(net_a)第2章 定义前向运算:加载CFAR10数据集
2.1 前置条件
#环境准备
import numpy as np # numpy数组库
import math # 数学运算库
import matplotlib.pyplot as plt # 画图库
import torch # torch基础库
import torch.nn as nn # torch神经网络库
import torch.nn.functional as F
import torchvision.datasets as dataset #公开数据集的下载和管理
import torchvision.transforms as transforms #公开数据集的预处理库,格式转换
import torchvision.utils as utils
import torch.utils.data as data_utils #对数据集进行分批加载的工具集
from PIL import Image #图片显示
from collections import OrderedDict
print("Hello World")
print(torch.__version__)
print(torch.cuda.is_available())Hello World 1.8.0 False
2.2 定义数据预处理(数据强化)
2.3 下载并加载数据集
#2-1 准备数据集
transform_train = transforms.Compose(
[transforms.ToTensor()])
transform_test = transforms.Compose(
[transforms.ToTensor()])
train_data = dataset.MNIST(root = "cifar10",
train = True,
transform = transform_train,
download = True)
test_data = dataset.MNIST(root = "cifar10",
train = False,
transform = transform_test,
download = True)
print(train_data)
print("size=", len(train_data))
print("")
print(test_data)
print("size=", len(test_data))Dataset MNIST
Number of datapoints: 60000
Root location: cifar10
Split: Train
StandardTransform
Transform: Compose(
ToTensor()
)
size= 60000
Dataset MNIST
Number of datapoints: 10000
Root location: cifar10
Split: Test
StandardTransform
Transform: Compose(
ToTensor()
)
size= 10000
2.4 定义batch Loader
# 批量数据读取
batch_size = 64
train_loader = data_utils.DataLoader(dataset = train_data, #训练数据
batch_size = batch_size, #每个批次读取的图片数量
shuffle = True) #读取到的数据,是否需要随机打乱顺序
test_loader = data_utils.DataLoader(dataset = test_data, #测试数据集
batch_size = batch_size,
shuffle = True)
print(train_loader)
print(test_loader)
print(len(train_data), len(train_data)/batch_size)
print(len(test_data), len(test_data)/batch_size)60000 937.5 10000 156.25
备注:
- 每个batch读取64个图片
- 训练数据集次数:50000/64 = 781.25
- 测试数据集次数:10000/64 = 156.25
2.5 可视化部分数据集数据
#显示一个batch图片
print("获取一个batch组图片")
imgs, labels = next(iter(train_loader))
print(imgs.shape)
print(labels.shape)
print(labels.size()[0])
print("\n合并成一张三通道灰度图片")
images = utils.make_grid(imgs)
print(images.shape)
print(labels.shape)
print("\n转换成imshow格式")
images = images.numpy().transpose(1,2,0)
print(images.shape)
print(labels.shape)
print("\n显示样本标签")
#打印图片标签
for i in range(batch_size):
print(labels[i], end=" ")
i += 1
#换行
if i%8 == 0:
print(end='\n')
print("\n显示图片")
plt.imshow(images)
plt.show()获取一个batch组图片 torch.Size([64, 1, 28, 28]) torch.Size([64]) 64 合并成一张三通道灰度图片 torch.Size([3, 242, 242]) torch.Size([64]) 转换成imshow格式 (242, 242, 3) torch.Size([64]) 显示样本标签 tensor(4) tensor(1) tensor(9) tensor(0) tensor(3) tensor(5) tensor(3) tensor(1) tensor(0) tensor(5) tensor(3) tensor(1) tensor(9) tensor(2) tensor(0) tensor(9) tensor(8) tensor(8) tensor(0) tensor(0) tensor(4) tensor(7) tensor(3) tensor(2) tensor(1) tensor(1) tensor(8) tensor(2) tensor(5) tensor(7) tensor(3) tensor(2) tensor(9) tensor(5) tensor(1) tensor(8) tensor(8) tensor(6) tensor(2) tensor(2) tensor(2) tensor(0) tensor(5) tensor(0) tensor(3) tensor(9) tensor(8) tensor(1) tensor(9) tensor(4) tensor(7) tensor(4) tensor(3) tensor(2) tensor(3) tensor(1) tensor(4) tensor(9) tensor(7) tensor(8) tensor(6) tensor(6) tensor(5) tensor(6) 显示图片

第3章 定义前向运算:加载网络/模型
3.1 定义网络 (可选,仅供个人学习时的比较)
(1)LeNet5A
# 来自官网
class LeNet5A(nn.Module):
def __init__(self):
super(LeNet5A, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution kernel
self.conv1 = nn.Conv2d(in_channels = 1, out_channels = 6, kernel_size = 5) # 6 * 24 * 24
self.conv2 = nn.Conv2d(in_channels = 6, out_channels = 16, kernel_size = 5) # 16 * 8 * 8
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(in_features = 16 * 4 * 4, out_features= 120) # 16 * 4 * 4
self.fc2 = nn.Linear(in_features = 120, out_features = 84)
self.fc3 = nn.Linear(in_features = 84, out_features = 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square, you can specify with a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = torch.flatten(x, 1) # flatten all dimensions except the batch dimension
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
#x = F.log_softmax(x,dim=1)
return x(2)LeNet5B
class LeNet5B(nn.Module):
def __init__(self):
super(LeNet5B, self).__init__()
self.feature_convnet = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d (in_channels = 1, out_channels = 6, kernel_size= (5, 5), stride = 1)), # 6 * 24 * 24
('relu1', nn.ReLU()),
('pool1', nn.MaxPool2d(kernel_size=(2, 2))), # 6 * 12 * 12
('conv2', nn.Conv2d (in_channels = 6, out_channels = 16, kernel_size=(5, 5))), # 16 * 8 * 8
('relu2', nn.ReLU()),
('pool2', nn.MaxPool2d(kernel_size=(2, 2))), # 16 * 4 * 4
]))
self.class_fc = nn.Sequential(OrderedDict([
('fc1', nn.Linear(in_features = 16 * 4 * 4, out_features = 120)), # 16 * 4 * 4
('relu3', nn.ReLU()),
('fc2', nn.Linear(in_features = 120, out_features = 84)),
('relu4', nn.ReLU()),
('fc3', nn.Linear(in_features = 84, out_features = 10)),
]))
def forward(self, img):
output = self.feature_convnet(img)
output = output.view(-1, 16 * 4 * 4) #相当于Flatten()
output = self.class_fc(output)
return output3.2 生成网络 (可选,仅供个人学习时的比较)
(1)LeNet5A
net_a = LeNet5A()
print(net_a)LeNet5A( (conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1)) (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) (fc1): Linear(in_features=256, out_features=120, bias=True) (fc2): Linear(in_features=120, out_features=84, bias=True) (fc3): Linear(in_features=84, out_features=10, bias=True) )
(2)LeNet5B
net_b = LeNet5B()
print(net_b)LeNet5B(
(feature_convnet): Sequential(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(relu1): ReLU()
(pool1): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(relu2): ReLU()
(pool2): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
(class_fc): Sequential(
(fc1): Linear(in_features=256, out_features=120, bias=True)
(relu3): ReLU()
(fc2): Linear(in_features=120, out_features=84, bias=True)
(relu4): ReLU()
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
)
3.3 加载已经训练过的模型/网络
net_a_load = torch.load("models/lenet_cifar10_model.pkl")
print(net_a_load)LeNet5A( (conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1)) (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) (fc1): Linear(in_features=256, out_features=120, bias=True) (fc2): Linear(in_features=120, out_features=84, bias=True) (fc3): Linear(in_features=84, out_features=10, bias=True) )
备注:
从打印信息,可以看出,加载后的网络与LeNet5A是一致的!!
3.4 测试加载的网络的输出
# 2-4 定义网络预测输出
# 测试网络是否能够工作
print("定义测试数据")
input = torch.randn(1, 1, 28, 28)
print("")
print("net_a_load的输出方法1:")
out = net_a_load(input)
print(out)
print("")
print("net_a_load的输出方法2:")
out = net_a_load.forward(input)
print(out)
print("")定义测试数据
net_a_load的输出方法1:
tensor([[-4.7942, 1.4898, 2.1154, 7.8800, -4.2342, 5.5373, -3.7926, -4.5306,
5.5041, -1.3831]], grad_fn=)
net_a_load的输出方法2:
tensor([[-4.7942, 1.4898, 2.1154, 7.8800, -4.2342, 5.5373, -3.7926, -4.5306,
5.5041, -1.3831]], grad_fn=)
3.5 选择后续进一步处理的网络
# 选定最终的网络
net = net_a_load3.6 加载后网络的使用
(1)可以进一步的训练(可选)
(2)直接用于预测
第4章 定义反向运算:损失函数与优化器(可选)
4.1 定义损失函数
# 3-1 定义loss函数:
loss_fn = nn.CrossEntropyLoss()
print(loss_fn)CrossEntropyLoss()
4.2 定义优化器
# 3-2 定义优化器
Learning_rate = 0.01 #学习率
# optimizer = SGD: 基本梯度下降法
# parameters:指明要优化的参数列表
# lr:指明学习率
#optimizer = torch.optim.Adam(model.parameters(), lr = Learning_rate)
optimizer = torch.optim.SGD(net.parameters(), lr = Learning_rate, momentum=0.9)
print(optimizer)SGD (
Parameter Group 0
dampening: 0
lr: 0.01
momentum: 0.9
nesterov: False
weight_decay: 0
)
第5章 定义反向运算:模型训练
5.1 训练前的准备
# 3-3 模型训练: 训练前的准备
# 动态选择GPU或CPU
# Assume that we are on a CUDA machine, then this should print a CUDA device:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
# 定义迭代次数
epochs = 1
loss_history = [] #训练过程中的loss数据
accuracy_history =[] #中间的预测结果
accuracy_batch = 0.0
#设置网络参数的运算设备
net.to(device)cpu
LeNet5A( (conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1)) (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) (fc1): Linear(in_features=256, out_features=120, bias=True) (fc2): Linear(in_features=120, out_features=84, bias=True) (fc3): Linear(in_features=84, out_features=10, bias=True) )
5.2 开始训练 (可选,仅用于需要进一步训练的场合)
# 3-3 模型训练: 开始训练
for i in range(0, epochs):
for j, (x_train, y_train) in enumerate(train_loader):
#指定数据处理的运算设备
x_train = x_train.to(device)
y_train = y_train.to(device)
#(0) 复位优化器的梯度
optimizer.zero_grad()
#(1) 前向计算
y_pred = net(x_train)
#(2) 计算loss
loss = loss_fn(y_pred, y_train)
#(3) 反向求导
loss.backward()
#(4) 反向迭代
optimizer.step()
# 记录训练过程中的损失值
loss_history.append(loss.item()) #loss for a batch
# 记录训练过程中的在训练集上该批次的准确率
number_batch = y_train.size()[0] # 训练批次中图片的个数
_, predicted = torch.max(y_pred.data, dim = 1) # 选出最大可能性的预测
correct_batch = (predicted == y_train).sum().item() # 获得预测正确的数目
accuracy_batch = 100 * correct_batch/number_batch # 计算该批次上的准确率
accuracy_history.append(accuracy_batch) # 该批次的准确率添加到log中
if(j % 100 == 0):
print('epoch {} batch {} In {} loss = {:.4f} accuracy = {:.4f}%'.format(i, j , len(train_data)/batch_size, loss.item(), accuracy_batch))
print("\n迭代完成")
print("final loss =", loss.item())
print("final accu =", accuracy_batch)epoch 0 batch 0 In 937.5 loss = 0.0570 accuracy = 96.8750%
epoch 0 batch 100 In 937.5 loss = 0.1146 accuracy = 98.4375%
epoch 0 batch 200 In 937.5 loss = 0.0325 accuracy = 98.4375%
epoch 0 batch 300 In 937.5 loss = 0.0326 accuracy = 98.4375%
epoch 0 batch 400 In 937.5 loss = 0.0779 accuracy = 96.8750%
epoch 0 batch 500 In 937.5 loss = 0.0160 accuracy = 100.0000%
epoch 0 batch 600 In 937.5 loss = 0.1101 accuracy = 98.4375%
epoch 0 batch 700 In 937.5 loss = 0.0523 accuracy = 98.4375%
epoch 0 batch 800 In 937.5 loss = 0.0252 accuracy = 98.4375%
epoch 0 batch 900 In 937.5 loss = 0.0265 accuracy = 100.0000%
迭代完成
final loss = 0.005106988362967968
final accu = 100.0
5.3 说明
从训练的结果可看出,由于是在已经训练过的模型的基础之上的进一步训练,
因此,准确率一开始就很高!
第6章 模型评估 - 训练过程(可选,仅用于需要进一步训练的场合)
6.1 可视化loss迭代过程
#显示loss的历史数据
plt.grid()
plt.xlabel("iters")
plt.ylabel("")
plt.title("loss", fontsize = 12)
plt.plot(loss_history, "r")
plt.show()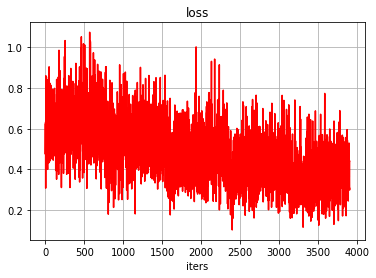
6.2 可视化精度变化过程
#显示准确率的历史数据
plt.grid()
plt.xlabel("iters")
plt.ylabel("%")
plt.title("accuracy", fontsize = 12)
plt.plot(accuracy_history, "b+")
plt.show()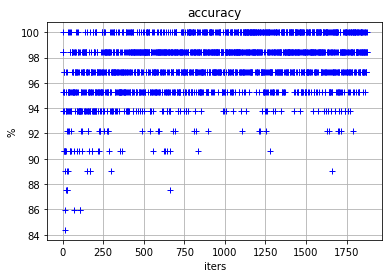
第7章 模型评估 - 训练结果
7.1 手工验证
# 手工检查
net_b.eval()
index = 0
print("获取一个batch样本")
images, labels = next(iter(test_loader))
images = images.to(device)
labels = labels.to(device)
print(images.shape)
print(labels.shape)
print(labels)
print("\n对batch中所有样本进行预测")
outputs = net(images)
print(outputs.data.shape)
print("\n对batch中每个样本的预测结果,选择最可能的分类")
_, predicted = torch.max(outputs, 1)
print(predicted.data.shape)
print(predicted)
print("\n对batch中的所有结果进行比较")
bool_results = (predicted == labels)
print(bool_results.shape)
print(bool_results)
print("\n统计预测正确样本的个数和精度")
corrects = bool_results.sum().item()
accuracy = corrects/(len(bool_results))
print("corrects=", corrects)
print("accuracy=", accuracy)
print("\n样本index =", index)
print("标签值 :", labels[index]. item())
print("分类可能性:", outputs.data[index].cpu().numpy())
print("最大可能性:",predicted.data[index].item())
print("正确性 :",bool_results.data[index].item())获取一个batch样本
torch.Size([64, 1, 28, 28])
torch.Size([64])
tensor([2, 8, 6, 4, 7, 1, 2, 7, 3, 4, 5, 2, 1, 0, 4, 2, 4, 8, 6, 2, 1, 0, 1, 0,
0, 7, 3, 7, 1, 4, 8, 0, 5, 1, 8, 0, 5, 7, 1, 9, 2, 9, 5, 9, 2, 6, 4, 7,
2, 6, 8, 9, 7, 2, 1, 2, 3, 1, 2, 2, 4, 4, 6, 3])
对batch中所有样本进行预测
torch.Size([64, 10])
对batch中每个样本的预测结果,选择最可能的分类
torch.Size([64])
tensor([2, 8, 6, 4, 7, 1, 2, 7, 3, 4, 5, 2, 1, 0, 4, 2, 4, 8, 6, 2, 1, 0, 1, 0,
0, 7, 3, 7, 1, 4, 8, 0, 5, 1, 8, 0, 5, 7, 1, 9, 2, 9, 5, 9, 2, 6, 4, 7,
2, 6, 8, 9, 7, 2, 1, 2, 3, 1, 2, 2, 4, 4, 6, 3])
对batch中的所有结果进行比较
torch.Size([64])
tensor([True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True])
统计预测正确样本的个数和精度
corrects= 64
accuracy= 1.0
样本index = 0
标签值 : 2
分类可能性: [ 1.2355812 2.7528806 17.141403 4.295339 -3.6761677 -9.359661
-8.040263 4.906373 5.9730754 -6.2058544]
最大可能性: 2
正确性 : True
7.2 训练集上的验证
# 对训练后的模型进行评估:测试其在训练集上总的准确率
correct_dataset = 0
total_dataset = 0
accuracy_dataset = 0.0
# 进行评测的时候网络不更新梯度
net_b.eval()
with torch.no_grad():
for i, data in enumerate(train_loader):
#获取一个batch样本"
images, labels = data
images = images.to(device)
labels = labels.to(device)
#对batch中所有样本进行预测
outputs = net(images)
#对batch中每个样本的预测结果,选择最可能的分类
_, predicted = torch.max(outputs.data, 1)
#对batch中的样本数进行累计
total_dataset += labels.size()[0]
#对batch中的所有结果进行比较"
bool_results = (predicted == labels)
#统计预测正确样本的个数
correct_dataset += bool_results.sum().item()
#统计预测正确样本的精度
accuracy_dataset = 100 * correct_dataset/total_dataset
if(i % 100 == 0):
print('batch {} In {} accuracy = {:.4f}'.format(i, len(train_data)/batch_size, accuracy_dataset))
print('Final result with the model on the dataset, accuracy =', accuracy_dataset)batch 0 In 937.5 accuracy = 95.3125
batch 100 In 937.5 accuracy = 97.8960
batch 200 In 937.5 accuracy = 97.9711
batch 300 In 937.5 accuracy = 97.9599
batch 400 In 937.5 accuracy = 97.9660
batch 500 In 937.5 accuracy = 98.0009
batch 600 In 937.5 accuracy = 97.9825
batch 700 In 937.5 accuracy = 98.0073
batch 800 In 937.5 accuracy = 98.0415
batch 900 In 937.5 accuracy = 98.0490
Final result with the model on the dataset, accuracy = 98.055
7.3 在测试集上的验证
# 对训练后的模型进行评估:测试其在训练集上总的准确率
correct_dataset = 0
total_dataset = 0
accuracy_dataset = 0.0
# 进行评测的时候网络不更新梯度
net_b.eval()
with torch.no_grad():
for i, data in enumerate(test_loader):
#获取一个batch样本"
images, labels = data
images = images.to(device)
labels = labels.to(device)
#对batch中所有样本进行预测
outputs = net(images)
#对batch中每个样本的预测结果,选择最可能的分类
_, predicted = torch.max(outputs.data, 1)
#对batch中的样本数进行累计
total_dataset += labels.size()[0]
#对batch中的所有结果进行比较"
bool_results = (predicted == labels)
#统计预测正确样本的个数
correct_dataset += bool_results.sum().item()
#统计预测正确样本的精度
accuracy_dataset = 100 * correct_dataset/total_dataset
if(i % 100 == 0):
print('batch {} In {} accuracy = {:.4f}'.format(i, len(test_data)/batch_size, accuracy_dataset))
print('Final result with the model on the dataset, accuracy =', accuracy_dataset)batch 0 In 156.25 accuracy = 100.0000
batch 100 In 156.25 accuracy = 97.9889
Final result with the model on the dataset, accuracy = 97.98
第8章 模型的存储与保存 (可选,如果需要保存新参数)
辛辛苦苦顺利模型不容易,需要把训练的模型保存下来。
#存储模型
# torch.save(model, "models/alexnet_model.pkl")
#存储参数
# torch.save(model.state_dict() , "models/alexnet_params.pkl")作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121132377