CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
[Paper] CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
目录
- Motivation
- 扩展:多尺度特征
- 扩展:受到多分支CNN架构的启发:OctConv-篇幅较长另起
- 方法
- 2.1.Vision Transformer的概述
- 2.2.多尺度Vision Transformer
- 2.3.多尺度特征融合
- All-Attention Fusion
- Class Token Fusion
- Pairwise Fusion
- Cross-Attention Fusion
- 实验
- 数据集:
- 训练和评估:
- 总结
与卷积神经网络相比,最近出现的视觉Transformer(ViT)在图像分类方面取得了很好的结果。受此启发,在本文,作者研究了如何学习Transformer模型中的多尺度特征表示来进行图像分类 。为此,作者提出了一种双分支Transformer来组合不同大小的图像patch,以产生更强的图像特征。本文的方法用两个不同计算复杂度的独立分支来处理小patch的token和大patch的token,然后这些token通过attention机制进行多次的交互以更好的融合信息。
此外,为了减少计算量,作者开发了一个简单而有效的基于cross-attention的token融合模块。在每一个分支中,它使用单个token(即 [CLS] token)作为query,与其他分支交换信息。本文提出cross-attention的计算复杂度和显存消耗与输入特征大小呈线性关系 。实验结果表明,本文提出的CrossViT的性能优于其他基于Transformer和CNN的模型。例如,在ImageNet-1K数据集上,CrossViT比DeiT的准确率高了2%,但是FLOPs和模型参数增加的非常有限。
Motivation
Transformer使NLP任务中序列到序列建模的能力取得了很大的飞跃。Transformer在NLP中的巨大成功激发了其在计算机视觉领域的应用。在ViT之前的一些工作主要将Transformer中的Self-Attention和CNN进行结合。虽然这些结合CNN和Self-Attention方法达到了比较不错的性能,但与纯粹的基于Self-Attention的Transformer相比,它们在计算方面的可拓展性非常有限。
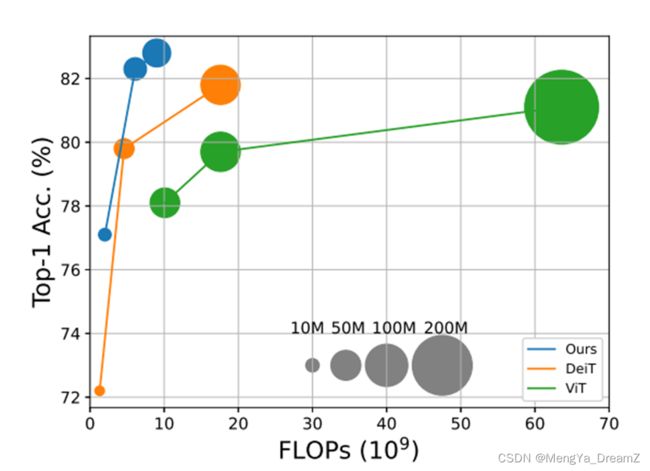 在ImageNet-1K数据集上,CrossViT比DeiT的准确率高了2%,
在ImageNet-1K数据集上,CrossViT比DeiT的准确率高了2%,
但是FLOPs和模型参数增加的非常有限。
ViT使用一系列embedding式的图像patch作为标准Transformer的输入,这是第一个与CNN模型性能相当的无卷积Transformer网络。然而,ViT需要非常大数据集,如ImageNet21K和JFT300M来进行预训练。之后的DeiT表明,数据增强和模型正则化可以在较少的数据下训练高性能的ViT模型。在此之后,ViT就逐渐成为了CV任务中的主流模型之一。
在这项工作中,作者研究了如何学习Transformer模型中的多尺度特征表示来进行图像识别 。多尺度的特征已经在很多工作中证明了对于CV任务是有效的,但多尺度特征对视觉Transformer的潜在好处仍有待验证。受到多分支CNN架构的启发,作者提出了一个双分支Transformer来组合不同大小的图像patch,以产生更强的视觉特征用于图像分类 。
本文的方法用两个具有不同计算复杂度的独立分支来分别处理大patch的token和小patch的token,这些token多次融合以相互补充信息。本文的重点是研究并设计适合视觉Transformer的多尺度特征融合方法 。在本文中,作者通过一个有效的交叉注意模块来实现这一点,其中每个Transformer分支创建一个non-patch token(即 [CLS] token)作为代理,并通过attention机制与另一个分支交换信息。(由于这里只使用[CLS] token进行信息交互,所以这一步attention的计算复杂度是线性的,而非二次的。)
扩展:多尺度特征
- 所谓多尺度,实际就是对信号的不同粒度的采样。
- 通常在不同的尺度下我们可以观察到不同的特征,从而完成不同的任务。
- 粒度更小/更密集的采样可以看到更多的细节,粒度更大/更稀疏的采样可以看到整体的趋势。
- 使用多尺度,就可以提取更全面的信息,既有全局的整体信息,又有局部的详细信息。

- 如果要完成的任务只是判断图中是否有前景,那么12×8的图像尺度就足够了。
- 如果要完成的任务是识别图中的水果种类,那么64×48的尺度也能勉强完成。
- 如果要完成的任务是后期合成该图像的景深,则需要更高分辨率的图像,比如640×480。
扩展:受到多分支CNN架构的启发:OctConv-篇幅较长另起
OctConv Drop an Octave: Reducing Spatial Redundancy inConvolutional Neural Networks with...
作者认为:不仅自然世界中的图像存在高低频,卷积层的输出特征图以及输入通道(feature maps or channels)也都存在高、低频分量。低频分量支撑的是整体,比如企鹅的白色大肚皮。显然,低频分量是存在冗余的,在编码过程中可以节省。
方法
2.1.Vision Transformer的概述
视觉Transformer(ViT)首先通过将图像按照一定的patch大小划分,然后将图像转换为一个patch的序列,并将每个patch线性投影成embedding。为了执行分类任务,还要在序列中添加了一个额外的分类token(CLS)。此外,由于Transformer编码器中的自注意是与位置无关的,而视觉应用高度需要位置信息,因此ViT向每个token添加了位置embedding,包括CLS token。
然后,将所有token输入到堆叠的Transformer编码器,最后使用CLS token进行分类。Transformer编码器由一系列块组成,其中每个块包含带有FNN和多头自注意(MSA)。FFN在隐藏层上包含具有扩展比为r的两层多层感知器,在第一个线性层后应用一个GELU非线性激活函数。在每个块之前应用Layer normalization(LN),在每个块之后应用残差连接。ViT的输入和第k个块的处理可以表示为:
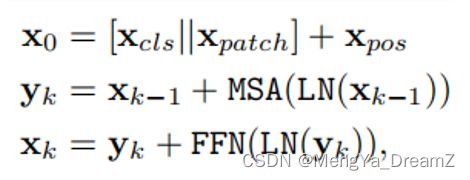
其中,和分别为CLS和patch token,为位置embedding。N和C分别是patch token的数量和embedding的维度。
值得注意的是,ViT与CNN的一个非常不同的设计是CLS token。在CNN中,最终的embedding通常是通过对所有空间位置的特征进行平均,而ViT使用与每个Transformer编码器上的patch token相互作用的CLS token作为最终的embedding。因此,我们可以认为CLS token是一个总结所有patch token的代理,因此作者提出的模块是基于CLS token设计的双路径多尺度的ViT。
2.2.多尺度Vision Transformer
patch大小会影响ViT的准确性和复杂性;具有细粒度的patch大小,ViT性能更好,但会导致更高的FLOPs和显存消耗。例如,patch大小为16的ViT比patch大小为32的ViT好6%,但前者需要更多4×的FLOPs。受此启发,作者提出的方法是利用来自更细粒度的patch大小的优点,同时平衡复杂性。更具体地说,作者首先引入了一个双分支ViT,其中每个分支处理不同patch大小的特征,然后采用一个简单而有效的模块来融合分支之间的信息。
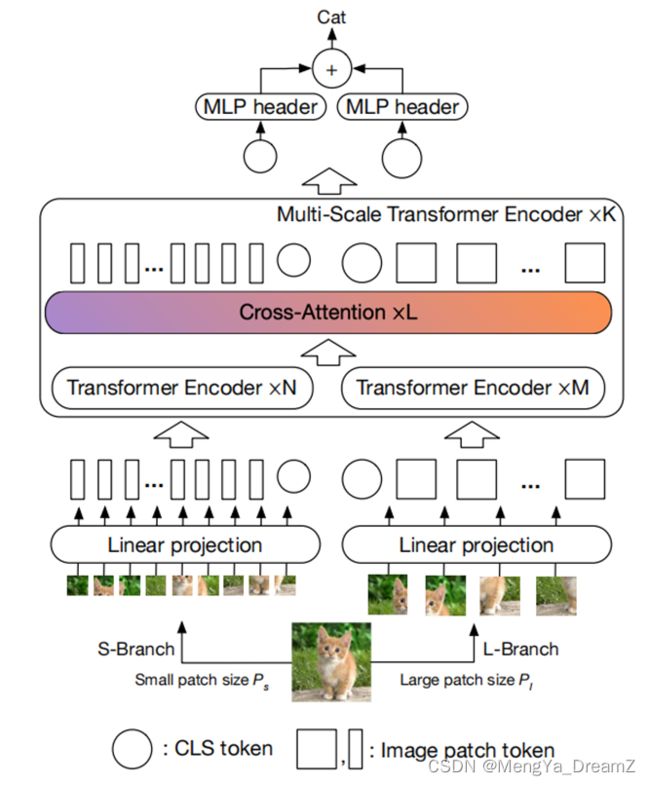
上图为交叉注意多尺度视觉Transformer( Cross-Attention Multi-Scale Vision Transformer,CrossViT)的网络结构。模型主要由K个多尺度Transformer编码器组成,其中每个编码器由两个分支组成:
- L-Branch :
- 大分支利用粗粒度的patch大小(Pl),更多的Transformer编码器和更大的embedding维度。
- S-Branch :
- 小分支对细粒度的patch大小(Ps))进行操作,具有更少的编码器和更小的embedding维度。
两个分支的输出特征在Cross-Attention中融合L次,利用末端的两个分支对CLS token进行预测。对于两个分支的每个token,作者还在多尺度Transformer编码器之前添加了一个可学习的位置embedding,以学习位置信息。
2.3.多尺度特征融合

有效的特征融合是学习多尺度特征表示的关键。在本文中,作者探索了四种策略,如上图所示。设是分支i上的token序列(包括patch和CLS token),其中i可以是l或者s,分别代表大分支和小分支。圆和矩形分别代表分支i的CLS和patch token。
All-Attention Fusion
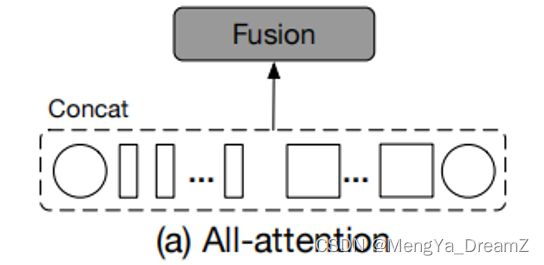
设是分支i上的token序列(包括patch和CLS token),其中i可以是l或者s,分别代表大分支和小分支。圆和矩形分别代表分支i的CLS和patch token。
All-Attention Fusion是简单地concat来自两个分支的所有token,而不考虑每个token的属性,然后通过自注意模块融合信息,如上图所示。但是这种方法的时间复杂度也是跟输入特征大小呈二次关系,因为所有的token都是通过自注意模块计算的。All-Attention Fusion方案的输出可以表示为:
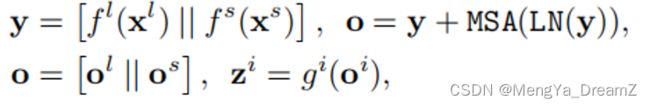
其中,f和g是用来对齐特征通道维度的投影函数。
Class Token Fusion
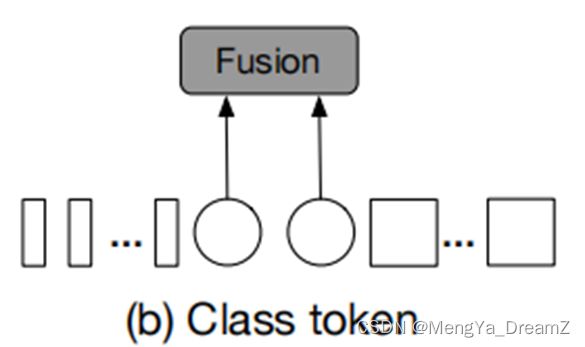
设是分支i上的token序列(包括patch和CLS token),其中i可以是l或者s,分别代表大分支和小分支。圆和矩形分别代表分支i的CLS和patch token。
CLS token可以看作是一个分支的抽象全局特征表示,因为在ViT中,它可以作为用来预测结果的最终embedding。因此,可以直接对两个分支的CLS token求和,如上图所示。这种方法计算上非常有效,因为只需要处理一个token。这个融合模块的输出可以表示为:
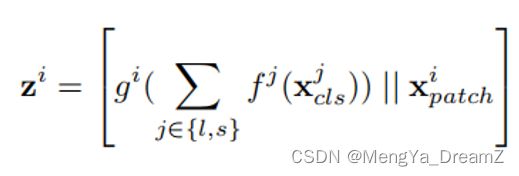
Pairwise Fusion
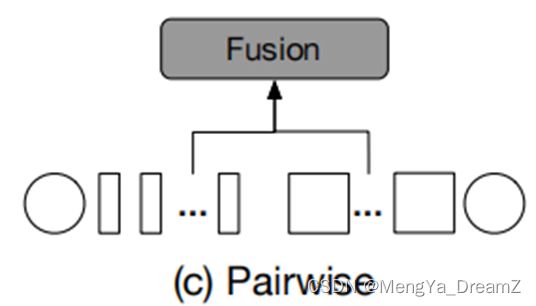
设是分支i上的token序列(包括patch和CLS token),其中i可以是l或者s,分别代表大分支和小分支。圆和矩形分别代表分支i的CLS和patch token。
上图显示了这两个分支是如何成对融合的。基于patch token位于图像的空间位置,启发式融合方法是根据它们的空间位置将它们合并。然而,这两个分支处理不同大小的patch,因此具有不同数量的patch token。因此,作者首先执行插值操作来对齐空间大小,然后以成对的方式融合两个分支的patch token。另一方面,将这两个分支的CLS token分别融合。L-Branch和S-Branch的成对融合的输出可以表示为:
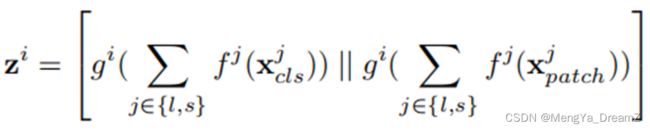
Cross-Attention Fusion
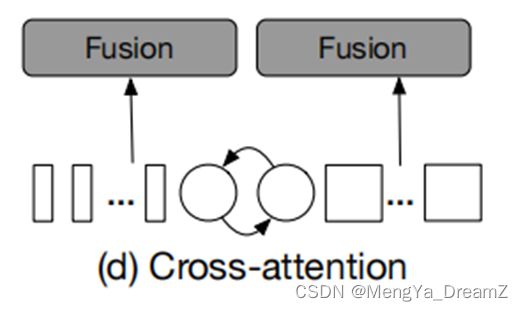
设是分支i上的token序列(包括patch和CLS token),其中i可以是l或者s,分别代表大分支和小分支。圆和矩形分别代表分支i的CLS和patch token。
上图显示了本文提出的Cross-Attention Fusion的基本思想,其中融合涉及到一个分支的CLS token和另一个分支的patch token。此外,为了更有效地融合多尺度特征,作者首先利用每个分支的CLS token作为代理,在另一个分支的patch token之间交换信息,然后将其投影到自己的分支。
由于CLS token已经学习了自己分支中所有patch token之间的抽象信息,因此与另一个分支中的patch token的交互有助于融合不同尺度的信息。与其他分支token融合后,CLS token在下一层Transformer编码器上再次与自己的patch token交互,在这一步中,它又能够将来自另一个分支的学习信息传递给自己的patch token,以丰富每个patch token的表示。
这里想直观的记录一下,直接放整理好的PPT
实验
数据集:
在ImageNet1K数据集上验证了提出的方法的有效性,并使用验证集上的top-1精度作为评估模型性能的指标。ImageNet1K包含1000个类,训练和验证图像的数量分别为128万和5万。同时,使用几个较小的数据集,如CIFAR10和CIFAR100,测试了我们方法的可移植性。
训练和评估:
原始的ViT实现了竞争的结果相比,一些最好的CNN模型,但只有在非常大规模的数据集上训练
(如ImageNet21K[9]和JFT300M)。然而,DeiT表明,在丰富的数据增强技术的帮助下,ViT可以从ImageNet单独训练,产生与CNN模型可比的结果。因此,实验中,基于DeiT建立我们的模型,并应用它们默认的超参数进行训练。这些数据增强方法包括rand增强、mixup增强、cutmix以及随机擦除。
在32个gpu上训练所有模型300个epoch(30个预热epoch),批大小为4,096。其他设置包括带有线性预热的余弦线性速率调度器,初始学习率为0.004,权重衰减为0.05。
总结
在本文中,作者提出了一种用于学习多尺度特征的双分支视觉Transformer——CrossViT,以提高图像分类的识别精度。
为了有效地结合不同尺度的图像patch token,作者进一步开发了一种基于交叉注意的融合方法,能够在线性时间复杂度下,进行两个分支的有效信息交换。通
过大量的实验,作者证明了CrossViT的性能优于目前的CNN和Transformer模型。
PS:实验结果,不过多阐述,论文图都很明了!