目标检测->YOLO V1
YOLO v1是One-stage工作的开山之作。YOLO: You Only Look Once. 发表于CVPR2016
1、主要思想:
1)将一副图像分成S*S的网格(grid cell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object。

2)每个网格要预测B个bounding box,每个bbox除了要预测位置之外,还要附带预测一个confidence值,且每个网格还要预测C个类别的分数。
所以输出特征图的通道数为:5B+C
其中,5是指边界框的置信度和位置参数;B是每个位置预测的bbox数量,C是类别的数量。网络的输出就是S*S*(5B+C)维的向量,与输入存在一个数学上的映射关系,而中间的yolo网络只是求这个映射关系的一种工具。
如果S=7,B=2,C=20,则每个grid cell预测向量如下图:
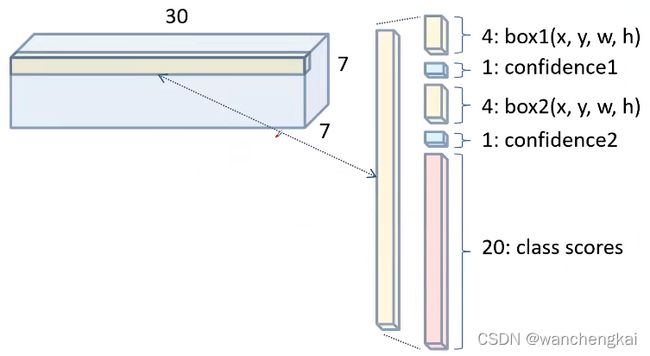
每个bbox的位置(x,y,w,h),x,y是预测物体的中心坐标。由于物体的中心落在这个网格中,则这个网格才负责预测这个物体,所以物体的中心不会超出这个网格,它们都是相对于当前网格左上角坐标的相对位移值,在0~1之间的数。
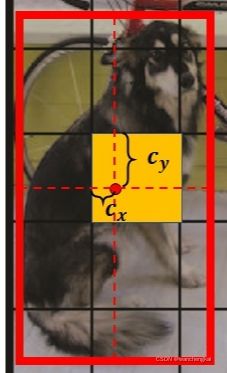
而w,h是物体的宽高,它有可能比网格大,所以它们是相对整个图像宽高的相对值。(YOLOV1中没有anchor的概念。在SSD和fast RCNN中的bbox都是相对anchor的位置)
因此,YOLOv1就是在每个网格上去做预测,理想情况下,包含了物体中心点的网格会有很高的置信度输出,而不包含中心点的网格的置信度输出应该十分接近0。
总的来说,YOLOv1一共有三部分输出,分别是confidence、class和bbox:
confidence就是框的置信度,用于回归该网格是否有物体,及物体和真实位置的IOU;
class就是类别预测;
bbox就是边界框(bounding box)。
置信度的计算方法:
![]()
如果物体不在当前grid cell中,置信度为0,否则置信度为物体和真实位置的IOU。
最终预测的目标概率为:

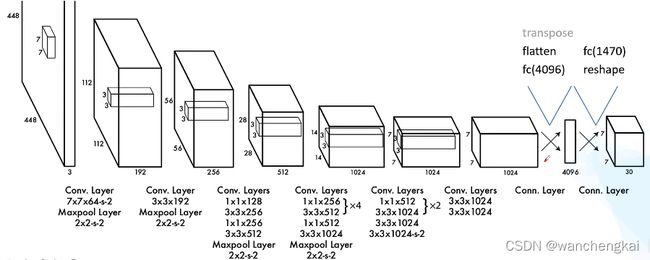
2、网络结构:
3、YOLOv1损失函数
损失函数大致分为3个部分,第一个是坐标的预测,分别是边框的x, y, w, h。第二个是物体的置信度预测,第三个是物体的类别预测,损失函数与7*7*30维的向量相对应,是求取输入与输出之间映射关系的“数学表达式”。

为了平衡大小目标的位置偏差对bbox损失,w和h用了开根号。
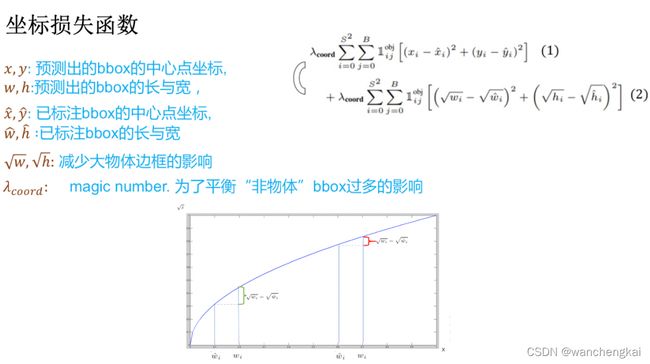
1)坐标损失函数
之所以采用根号来计算物体的长和宽,是因为根号后的大物体的长宽损失与小物体的长宽损失相近,这样整个损失函数不会被大物体所操纵。若不采用根号计算,那么大物体的损失要比小物体损失大很多,那么这个损失函数会对大物体比较准确而忽略了小物体。公式前的系数是一个超参数,因为物体检测过程中,我们所要检测的物体相对与背景来说要少的很多,所以加入这个超参数是为了平衡“非物体”对结果的影响。
2)置信度损失函数
这里为什么要加入“非物体”的置信度呢,是因为网络要想学习分类n个物体,那他实际要学n+1个类别,那多出的“1”是背景或者就是真实意义上的非物体,这一类是占有很大一部分比例的,所以必须要学习这一类,才能保证网络的准确性。那这里为什么要在“非物体”的置信度前边加上超参数呢?也是因为我们所检测的目标物体相对于“非物体”是很少的,如果不加入这个超参数,那么“非物体”的置信度损失就会很大,所占权重比较大,这样会导致网络只学习到了“非物体”特征,而忽略了目标物体特征。

3)类别损失函数
类别损失是一个很粗暴的两个类别做减法,是YOLOv1不可取的一部分,当然后续就改掉了。

4、存在的问题:
1)对拥挤目标检测不好:YOLOV1每个网格只能预测2个bbox,而且它们是同一个类别的,所以小目标聚集时效果不好。
2)直接预测bbox的位置,没有采用相对anchor的参数,和基于region proposal类的方法相比召回率更低