联邦学习概述
联邦学习
一、联邦学习诞生的背景
机器学习已经逐步改变人们的生产生活方式,在语音、图像和文本识别、语言翻译等方面都取得了巨大的进步。
传统大规模的机器学习是将所有待处理、待训练的数据收集到本地进行,然而现实情况却是,行业内由于竞争关系,行业间由于审批手续等问题,将各方的数据整合起来非常困难;甚至在同一个企业不同部门之间的数据共享也不容易.因此数据往往以孤岛的形式存在,不能发挥其应有的价值。
同时,随着人工智能技术的飞速发展,重视数据隐私和安全已经成为世界范围的大事件。面对制约人工智能发展的数据孤岛以及数据隐私和安全问题,联邦学习作为一种新型的分布式机器学习技术应运而生,新型在于无需大规模数据转移,各数据持有者在本地实现协同建模,提升人工智能模型的效果。
二、联邦学习的定义
联邦学习实际上是一种加密的分布式机器学习技术,各个参与方可在不披露底层数据和其加密形态的前提下共建模型。
假设N个数据持有者 ( U 1 , U 2 , . . . , U 3 ) (U_1,U_2,...,U_3) (U1,U2,...,U3),持有的数据为 ( D 1 , D 2 , . . . , D 3 ) (D_1,D_2,...,D_3) (D1,D2,...,D3),传统的机器学习是将所有的数据进行整合,得到数据集 D = ( D 1 , D 2 , . . . , D 3 ) D=(D_1,D_2,...,D_3) D=(D1,D2,...,D3)。建模得到模型M;而联邦学习则是在所有的参与方不可见且不进行数据交换的前提下,协同建模得到模型 M ′ M' M′。假设M的Loss为L, M ′ M' M′的Loss为 L ′ L' L′,若 ∣ L − L ′ ∣ < δ |L-L'|<\delta ∣L−L′∣<δ,那么则称联邦学习算法的损失精度为 δ \delta δ。
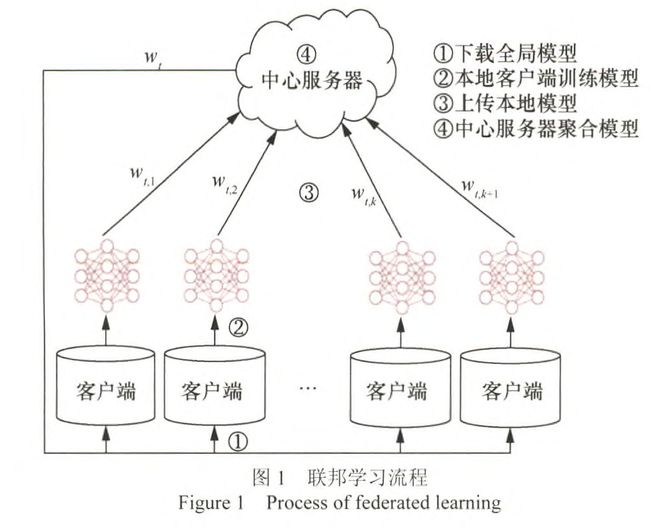
客户端(如平板电脑、手机、物联网设备)在中心服务器(如服务提供商)的协调下共同训练模型。
其中客户端负责训练本地数据得到本地模型(local model);中心服务器负责加权聚合本地模型,得到全局模型(global model)。
经过多轮迭代后最终得到一个趋近于集中式机器学习结果的模型W,有效地降低了传统机器学习源数据聚合带来的许多隐私风险。
三、联邦学习的分类
作为联邦学习中的一个参与方,假设本地数据可以用一个矩阵来表示,矩阵的每一行代表一个用户,列表示用户的一种特征。同时,每个用户都有一个标签。对于任何一方来说都希望既不暴露自己的数据又能通过建立一个更准确的模型预测自己的标签。
联邦学习被提出的原因就是为了在保障各参与方数据隐私和安全的前提下,多个参与方在本地开展自行学习,最终建立一个更强大的模型。
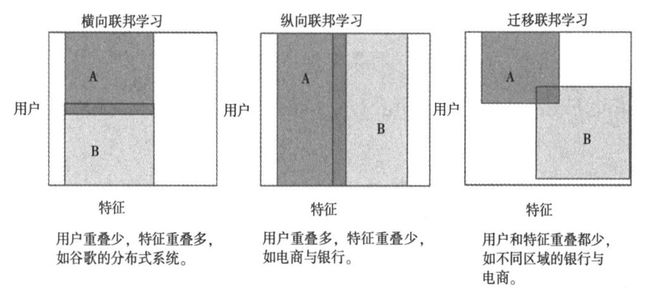
3.1 横向联邦学习
在横向联邦学习中,数据及用户呈现以下特点:参与方用户重叠部分很少,数据特征重叠部分较多。
银行系统最能说明此种情况,例如,某银行在北京和上海设有分行,两地业务类似,即数据特征相似,用户差异较大,那么两个分行通过联邦学习进行建模时,就属于横向联邦学习。
3.2 纵向联邦学学习
在纵向联邦学习中,数据及用户呈现以下特点:参与方用户重叠部分很多,数据特征重叠部分较少。
例如,同一高校的教务处和财务处,教务处有学生的课程信息,财务处有学生的缴费信息,即用户重叠多,数据特征重叠少。当两个部门不想暴露自己的数据却又想联合训练一个更强大的联邦学习模型,就属于纵向联邦学习。
3.3 迁移联邦学习
在迁移联邦学习中,数据及用户呈现以下特点:参与方用户重叠部分很少,数据特征重叠部分也很少。
例如,分别位于北京和上海的两家公司A和 B,公司A拥有北京地区的消费记录,公司B拥有上海地区的信用记录,公司A和B的用户不同,数据特征也不同,这种联合机器学习,就属于迁移联邦学习。
四、联邦学习的优势
-
高隐私性
参与联邦学习的任何一方数据不会泄露给其他参与者,满足用户隐私保护和数据安全的需求。 -
高质量
虽然不能保证比将所有数据收集到一起训练出来的模型质量好,但至少保证联邦模型比各自独立训练的模型效果好。 -
地位平等
参与联邦学习的各方地位平等。 -
高独立性
各参与方在保持独立性的情况下,与中央服务器进行模型参数的加密交换。并同时获得成长。
五、联邦学习中的数据安全
联邦学习中用户的隐私与数据安全是重中之重。根据数据安全隐患的来源分为以下几类。
5.1 中央服务器
中央服务器的存在是一个重要隐患之一。联邦学习中每轮训练的梯度都被发给中央服务器,并且所有的参与者从中央服务器下载新一轮次的模型,那么如果中央服务器遭到攻击,有可能通过对每一轮的梯度和模型信息综合分析推出某一参与方或者全部参与方的部分或全部数据信息。
5.2 单方数据污染
联邦学习中大多数情况下参与者众多,参与方虽然不直接进行数据交换,但都通过中央服务器进行梯度上传和模型下载,当某一方数据被污染时,有可能扩散到整个联邦学习集群中去。
5.3 传输问题
联邦学习中参与方和中央服务器交互的虽然是梯度信息和模型信息,但是不排除攻击者利用交互信息中的敏感数据进行逆向推理,反推出参与方原始数据信息的可能性。
5.4 数据泄露
联邦学习中原始数据不出本地的机制虽然在一定程度上保证了各参与方的数据隐私和安全,但是依然存在本地原始数据泄露的可能性。例如,联邦学习中并没有判断各参与方的行为是否合规的机制,如果存在恶意参与方,那么从与中央服务器交互的信息中推理其他参与方的关键数据,进而推理出整个原始数据,从而实现窃取数据的目的。
六、邦学习面临的困难与挑战
6.1 高昂的通信代价
联邦学习中各参与方与中央服务器并不一定在一起,原始数据保存在各参与方设备上,各参与方向中央服务器上传梯度信息,并从其下载新的模型,整个过程需要迭代很多次才能完成最终模型的构建。通常整个联邦学习网络可能包含大量的设备,网络通信速度可能比本地计算慢许多个数量级,这就造成高昂的通信代价成为联邦学习的关键瓶颈。
6.2 系统异质性
由于各参与方设备硬件条件(CPU、内存)、网络连接(3G、4G、5G、WiFi)和电源(电池电量)的差异化,联邦学习网络中每个设备的存储、计算和通信能力等都有可能不同。此外,网络和设备本身的限制可能导致某一时间仅有一部分设备处于活动状态。此外,设备还会出现没电、网络无法接入等突发情况,导致瞬间无法联通。这种异质性的系统架构影响了联邦学习整体效率和成果。
6.3 数据异质性
各参与方的用户特征和数据数量格式等可能有很大差异,因此联邦学习网络中的数据为非独立同分布的。目前,主流机器学习算法主要是基于IID(独立同分布)数据的假设立的。因此,异质性的 Non-IID(非独立同分布)数据特征给建模、分析和评估都带来了很大的挑战。
6.4 隐私问题
联邦学习共享模型参数更新(例如梯度信息),并不是每个参与者的原始数据,因此在数据隐私保护方面优于其他的机器学习方式。然而,在训练过程中传递模型的更新信息仍然存在向第三方或者中央服务器暴露敏感信息的风险。隐私保护成为联邦学习需要重点考虑的问题。