统计学习方法笔记(一):感知机
统计学习方法笔记(一):感知机
前言:本文是基于李航老师《统计学习方法》的笔记 ~
感知机学习的目的:求出将训练数据进行线性划分的分离超平面。
1. 感知机模型:
1.1 数学形式:
f ( x ) = s i g n ( w ⋅ x + b ) f(x)=sign(w\cdot x + b) f(x)=sign(w⋅x+b)
其中输入空间为 X ϵ R n X\epsilon R^{n} XϵRn,输出空间为 Y = { + 1 , − 1 } Y = \begin{Bmatrix}+1, -1\end{Bmatrix} Y={+1,−1}。w和b为感知机模型参数, w ϵ R n w\epsilon R^{n} wϵRn叫做权值或权值向量, b ϵ R b\epsilon R bϵR叫做偏置, w ⋅ x w\cdot x w⋅x表示w和x的内积。sign是符号函数,即
s i g n ( x ) = { + 1 , x > = 0 − 1 , x < 0 } sign(x)=\begin{Bmatrix} &+1,\quad x>=0\quad \\ &-1,\quad x<0\quad \end{Bmatrix} sign(x)={+1,x>=0−1,x<0}
1.2 几何解释:
分离超平面:线性方程
w ⋅ x + b = 0 w\cdot x+b=0 w⋅x+b=0
对应于特征空间 R n R^{n} Rn中的一个超平面S(分离超平面),其中w是超平面的法向量,b是超平面的截距。这个超平面将特征空间划分为两部分,且这两部分的点分别被分为正、负两类。如下图所示: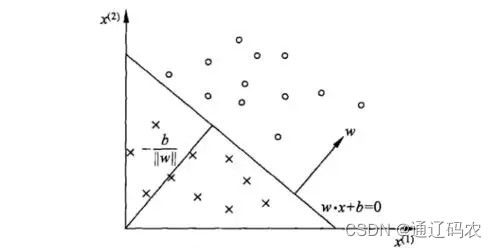
2. 学习策略
2.1 数据集——线性可分性
数据集是否线性可分,即为是否存在某个超平面S可以将该数据集中所有的实例点完全正确地划分到超平面两侧。可以完全正确的划分,则该数据集为线性可分数据集;否则,则为线性不可分。
即给定数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } T=\begin{Bmatrix}(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\end{Bmatrix} T={(x1,y1),(x2,y2),...,(xn,yn)},其中 x i ϵ X = R n x_i\epsilon X=R^n xiϵX=Rn, y i ϵ Y = { + 1 , − 1 } y_i\epsilon Y=\begin{Bmatrix}+1, -1\end{Bmatrix} yiϵY={+1,−1}, i = 1 , 2 , . . . , N i=1, 2,...,N i=1,2,...,N。若为线性可分数据集,则对于所有 y i = + 1 y_i=+1 yi=+1的实例 i i i,有 w ⋅ x i + b > 0 w\cdot x_i+b>0 w⋅xi+b>0;对所有 y i = − 1 y_i=-1 yi=−1的实例 i i i,有 w ⋅ x i + b < 0 w\cdot x_i+b<0 w⋅xi+b<0。
2.2 学习策略
-
学习策略:这里为定义(经验)损失函数并将损失函数极小化。
-
损失函数: L ( w , b ) = − ∑ x i ϵ M y i ( w ⋅ x i + b ) L(w,b) = - \sum_{x_i\epsilon M}^{} y_i(w\cdot x_i + b) L(w,b)=−∑xiϵMyi(w⋅xi+b)
其中, M M M为误分类点的集合。
损失函数推导过程:
-
首先,写出输入空间 R n R^n Rn中任意一点 x 0 x_0 x0到超平面 S S S的距离:
1 ∥ w ∥ ∣ w ⋅ x 0 + b ∣ \frac {1} {\left \| w \right \|} |w\cdot x_0 + b| ∥w∥1∣w⋅x0+b∣
这里 ∥ w ∥ \left \|w \right \| ∥w∥是 w w w的 L 2 L_2 L2范数。 -
对于误分类的数据 ( x i , y i ) (x_i, y_i) (xi,yi)来说,
− y i ( w ⋅ x i + b ) > 0 -y_i(w\cdot x_i + b) > 0 −yi(w⋅xi+b)>0
成立。因为当 ( w ⋅ x + b ) > 0 (w\cdot x + b) > 0 (w⋅x+b)>0时, y i = − 1 y_i= -1 yi=−1;而当 ( w ⋅ x + b ) < 0 (w\cdot x + b) < 0 (w⋅x+b)<0时, y i = + 1 y_i = +1 yi=+1。因此,误分类点 x i x_i xi到超平面 S S S的距离是:
− 1 ∥ w ∥ y i ( w ⋅ x i + b ) -\frac {1} {\left\|w\right\|} y_i (w\cdot x_i + b) −∥w∥1yi(w⋅xi+b)
(因为 ∣ y i ∣ = + 1 |y_i| = +1 ∣yi∣=+1,所以 − y i ( w ⋅ x i + b ) = ∣ w ⋅ x i + b ∣ -y_i(w\cdot x_i + b) = |w\cdot x_i + b| −yi(w⋅xi+b)=∣w⋅xi+b∣) -
那么假设超平面 S S S的误分类点集合为 M M M,那么所有误分类点到超平面 S S S的总距离为:
− 1 ∥ w ∥ ∑ x i ϵ M y i ( w ⋅ x i + b ) -\frac {1} {\left\|w\right\|} \sum_{x_i\epsilon M}^{} y_i (w\cdot x_i + b) −∥w∥1xiϵM∑yi(w⋅xi+b)
不考虑 1 ∥ w ∥ \frac{1} {\left\|w\right\|} ∥w∥1,就得到感知机学习的损失函数。
-
3. 感知机学习算法:
3.1 原始形式
-
基本想法:求感知机模型的参数 w , b w,b w,b,使其为如下损失函数极小化问题的解
m i n w , b L ( w , b ) = − ∑ x i ϵ M y i ( w ⋅ x i + b ) min_{w,b}^{} L(w, b) = -\sum_{x_i \epsilon M} y_i (w\cdot x_i + b) minw,bL(w,b)=−xiϵM∑yi(w⋅xi+b) -
具体方法:随机梯度下降法。
即用梯度下降法不断地极小化目标函数(损失函数 L ( w , b ) L(w, b) L(w,b)),但这个极小化过程我们不是一次使 M M M中所有误分类点的梯度下降,而是一次随机选取一个误分类点使其梯度下降。
-
损失函数 L ( w , b ) L(w, b) L(w,b)的梯度:由 ▽ w L ( w , b ) = − ∑ x i ϵ M y i x i \bigtriangledown_w L(w, b) = -\sum_{x_i\epsilon M} y_i x_i ▽wL(w,b)=−∑xiϵMyixi 和 ▽ b L ( w , b ) = − ∑ x i ϵ M y i \bigtriangledown_b L(w, b) = -\sum_{x_i\epsilon M} y_i ▽bL(w,b)=−∑xiϵMyi 给出(分别对 L ( w , b ) L(w, b) L(w,b)的 w w w和 b b b参数求偏导获得)。
-
极小化过程具体为:每次随机选取一个误分类点 ( x i , y i ) (x_i, y_i) (xi,yi),对 w , b w, b w,b进行更新:
w ← w + η y i x i b ← b + η y i w \leftarrow w + \eta y_i x_i\\ b \leftarrow b + \eta y_i w←w+ηyixib←b+ηyi
上式中 η ( 0 < η ≤ 0 ) \eta (0 < \eta \leq 0) η(0<η≤0)是步长,又称为学习率。这样,通过迭代可以使得损失函数 L ( w , b ) L(w, b) L(w,b)不断减小,直到为0。此时,我们就获得了感知机的分离超平面,此时的参数 w , b w,b w,b也即感知机模型的参数。
-
-
输入:训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T = \begin{Bmatrix}(x_1, y_1), (x_2, y_2), ..., (x_N, y_N)\end{Bmatrix} T={(x1,y1),(x2,y2),...,(xN,yN)},其中 x i ϵ X = R n x_i \epsilon X = R^n xiϵX=Rn, y i ϵ Y = { − 1 , + 1 } y_i\epsilon Y = \begin{Bmatrix}-1, +1\end{Bmatrix} yiϵY={−1,+1}, i = 1 , 2 , . . . , N i = 1, 2, ..., N i=1,2,...,N;学习率 η ( 0 < η ⩽ 1 ) \eta(0 < \eta \leqslant 1) η(0<η⩽1)。
-
输出: w , b w, b w,b,感知机模型 f ( x ) = s i g n ( w ⋅ x + b ) f(x) = sign(w\cdot x + b) f(x)=sign(w⋅x+b)
-
算法流程:
-
选取初值 w 0 , b 0 w_0,b_0 w0,b0(即任意选取一个超平面 w 0 , b 0 w_0, b_0 w0,b0)
-
在训练集中随意选取一个误分类点 ( x i , y i ) (x_i, y_i) (xi,yi);
-
如果 y i ( w ⋅ x i + b ) ⩽ 0 y_i (w\cdot x_i + b) \leqslant 0 yi(w⋅xi+b)⩽0,对 w w w和 b b b进行更新:
w ← w + η y i x i b ← b + η y i w \leftarrow w + \eta y_i x_i\\ b \leftarrow b + \eta y_i w←w+ηyixib←b+ηyi -
重复第二、三步算法,直至训练集中没有误分类点(即对于所有的点 ( x i , y i ) (x_i, y_i) (xi,yi),都有 y i ( w ⋅ x i + b ) > 0 y_i (w\cdot x_i + b) > 0 yi(w⋅xi+b)>0)
-
-
代码实现(基于
typeScript)// 导入所需常用函数 import { Get_Matrix_shape, Get_Zero_Matrix, Matrix_Item_Sum, Matrix_Dot_Multiplication, Matrix_Add_Each, Matrix_Multiplication_Number } from "./universal-func" // 代码正文 let x = [[3, 3], [4, 3], [1, 1]] let y = [1, 1, -1] let x_shape = Get_Matrix_shape(x) let y_shape = Get_Matrix_shape(y) // 初始化 w, b (初始化为0),学习率n初始化为 1 let w = Get_Zero_Matrix(x_shape.slice(1)) let b = 0 let n = 1 // 其它数据 let index = 0 // 当前的x的子矩阵序号 let sum = 0 // 当前符合 y(w·x + b) > 0 的x子矩阵的个数 while(sum < x_shape[0]){ // 求解 y(w·x + b) if(y[index] * (Matrix_Item_Sum(Matrix_Dot_Multiplication(w, x[index])) + b) <= 0){ w = Matrix_Add_Each(w, Matrix_Multiplication_Number(n * y[index], x[index])) b += n * y[index] sum = -1 } index = ((index + 1) % x_shape[0]) sum += 1 } console.log("w: ", w) console.log("b: ", b)其中引用的相关函数:
/** * @Get_Matrix_shape 获取矩阵的行列数,也即矩阵的 shape(形状) * @matrix 矩阵 */ export function Get_Matrix_shape(matrix: any){ let shape_list = [matrix.length] if(matrix[0] && Array.isArray(matrix[0])){ shape_list.push(...Get_Matrix_shape(matrix[0])) } return shape_list } /** * @Get_Zero_Matrix 按指定形状创建一个 零矩阵 * @shape 矩阵shape形状数组 */ export function Get_Zero_Matrix(shape: number[]){ let matrix: any = [] if(shape.length === 1){ for(let i = 0; i < shape[0]; i++){ matrix.push(0) } } else { for(let i = 0; i < shape[0]; i++){ matrix.push(Get_Zero_Matrix(shape.slice(1))) } } return matrix } /** * @Matrix_Dot_Multiplication 求两矩阵点乘 (二阶矩阵点乘) * @param x1、x2: 要点乘的两个矩阵 */ export function Matrix_Dot_Multiplication(x1: any, x2: any){ let x1_shape = Get_Matrix_shape(x1) let x2_shape = Get_Matrix_shape(x2) let matrix: any = [] // 一维矩阵 if(x1_shape.length === 1){ if(x1_shape[0] === x2_shape[0]){ for(let i = 0; i < x1_shape[0]; i++){ matrix.push(x1[i] * x2[i]) } } return matrix } // 二维矩阵 // 相关变量 let similar_num = 0 // 行列相同的总数 let index = -1 // 相似的行列的序号 for(let i = 0; i < 2; i++){ if(x1_shape[i] === x2_shape[i]){ similar_num += 1 index = i } } let x_l = [], x_r = [] if(similar_num === 1){ if(x1_shape[1 - index] === 1){ x_l = [...x1] x_r = [...x2] } else if(x2_shape[1 - index] === 1){ x_l = [...x2] x_r = [...x1] } else { return matrix } if(index === 0){ for(let i = 0; i < x_r.length; i++){ let mid_matrix = [] for(let j = 0; j < x_r[0].length; j++){ mid_matrix.push(x_l[i][0] * x_r[i][j]) } matrix.push(mid_matrix) } }else{ for(let i = 0; i < x_r.length; i++){ let mid_matrix = [] for(let j = 0; j < x_r[0].length; j++){ mid_matrix.push(x_l[0][j] * x_r[i][j]) } matrix.push(mid_matrix) } } } else if(similar_num === 2){ for(let i = 0; i < x1_shape[0]; i++){ let mid_matrix = [] for(let j = 0; j < x1_shape[1]; j++){ mid_matrix.push(x1[i][j] * x2[i][j]) } matrix.push(mid_matrix) } } return matrix } /** * @Matrix_Item_Sum 求矩阵各元素之和 * @param matrix 要被求和的矩阵 */ export function Matrix_Item_Sum(matrix: any){ let shape = Get_Matrix_shape(matrix) let sum = 0 if(shape.length === 1){ for(let i = 0; i < shape[0]; i++){ sum += matrix[i] } } else { for(let i = 0; i < shape[0]; i++){ sum += Matrix_Item_Sum(matrix[i]) } } return sum } /** * @Matrix_Multiplication_Number 常数点乘矩阵 * @param number_ 常数 * @param matrix 矩阵 */ export function Matrix_Multiplication_Number(number_: number, matrix: any){ let shape = Get_Matrix_shape(matrix) let m: any = [] if(shape.length === 1){ for(let i = 0; i < shape[0]; i++){ m.push(matrix[i] * number_) } } else { for(let i = 0; i < shape[0]; i++){ m.push(Matrix_Multiplication_Number(number_, matrix[i])) } } return m } /** * @Matrix_Add_Each 两矩阵相加函数 * @param x1 矩阵1 * @param x2 矩阵2 */ export function Matrix_Add_Each(x1: any, x2: any){ let x1_shape = Get_Matrix_shape(x1) let matrix: any = [] if(x1_shape.length === 1){ for(let i = 0; i < x1_shape[0]; i++){ matrix.push(x1[i] + x2[i]) } } else { for(let i = 0; i < x1_shape[0]; i++){ matrix.push(Matrix_Add_Each(x1[i], x2[i])) } } return matrix }
3.2 对偶形式
-
基本想法:将 w w w和 b b b表示为实例 x i x_i xi和标记 y i y_i yi的线性组合的形式,通过求解其系数而求得 w w w和 b b b。
-
为不失一般性,假设初始值 w 0 w_0 w0, b 0 b_0 b0均为0。对误分类点通过
w ← w + η y i x i b ← b + η y i w\leftarrow w + \eta y_i x_i \\ b\leftarrow b + \eta y_i w←w+ηyixib←b+ηyi
逐步修改 w w w, b b b。 -
设修改 n n n次,则 w w w, b b b关于 ( x i , y i ) (x_i, y_i) (xi,yi)的增量分别是 a i y i x i a_i y_i x_i aiyixi和 a i y i a_i y_i aiyi,这里 a i = n i η a_i = n_i \eta ai=niη, n i n_i ni是点 ( x i , y i ) (x_i, y_i) (xi,yi)被误分类的次数。这里最后学习到的 w w w, b b b可以表示为
w = ∑ i = 1 N a i y i x i b = ∑ i = 1 N a i y i w = \sum_{i = 1}^{N} a_i y_i x_i \\ b = \sum_{i = 1}^{N} a_i y_i w=i=1∑Naiyixib=i=1∑Naiyi
这里 a i ≥ 0 a_i \geq 0 ai≥0, i = 1 , 2 , . . . , N i = 1, 2, ..., N i=1,2,...,N,当 η = 1 \eta = 1 η=1时,表示第 i i i个实例点由于误分而进行更新的次数。实例点更新次数越多,意味着它距离分离超平面越近,也就越难分类(也就是说,这样的实例对学习结果影响最大)
-
-
输入:线性可分的数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T = \begin{Bmatrix} (x_1, y_1), (x_2, y_2), ..., (x_N, y_N) \end{Bmatrix} T={(x1,y1),(x2,y2),...,(xN,yN)},其中 x i ∈ R n x_i \in R^n xi∈Rn, y i ∈ { − 1 , + 1 } y_i \in \begin{Bmatrix} -1, +1 \end{Bmatrix} yi∈{−1,+1}, i = 1 , 2 , . . . , N i = 1, 2, ..., N i=1,2,...,N;学习率 η ( 0 < η ≤ 1 ) \eta \;(0 < \eta \leq 1) η(0<η≤1)。
-
输出: a a a, b b b;感知机模型 f ( x ) = s i g n ( ∑ j = 1 N a j y j x j ⋅ x + b ) f(x) = sign(\sum_{j = 1}^{N} a_j y_j x_j \cdot x + b) f(x)=sign(∑j=1Najyjxj⋅x+b),其中 a = ( a 1 , a 2 , . . . , a N ) T a = (a_1, a_2, ..., a_N)^T a=(a1,a2,...,aN)T。
-
算法流程:
-
初始化 a ← 0 a \leftarrow 0 a←0, b ← 0 b \leftarrow 0 b←0。
-
在训练集中选取数据 ( x i , y i ) (x_i, y_i) (xi,yi)。
-
如果 y i ( ∑ j = 1 N a j y j x j ⋅ x i + b ) ≤ 0 y_i(\sum_{j = 1}^{N} a_j y_j x_j \cdot x_i + b) \leq 0 yi(∑j=1Najyjxj⋅xi+b)≤0,
a i ← a i + η b ← b + η y i a_i \leftarrow a_i + \eta \\ b \leftarrow b + \eta y_i ai←ai+ηb←b+ηyi -
转至第二步,直到没有误分类数据。
-
由于对偶形式中训练实例仅以内积( x j ⋅ x i x_j \cdot x_i xj⋅xi)的形式出现。为便于求解,我们可以先将训练集实例间的内积计算出来并以矩阵的形式存储,这个矩阵就是所谓的Gram矩阵
G = [ x i ⋅ x j ] N × N G = [x_i \cdot x_j]_{N \times N} G=[xi⋅xj]N×N
-
代码实现:
let x = [[3, 3], [4, 3], [1, 1]] let y = [1, 1, -1] let x_shape = Get_Matrix_shape(x) // 获取Gram矩阵 let G = Get_Gram_Matrix(x) // 相关参数n let n = 1 // 初始化a和b let a = Get_Zero_Matrix([x_shape[0]]) let b = 0 // 相关参数 let index = 0 let sum = 0 while(sum < x_shape[0]){ let mid_num = 0 for(let i = 0; i < x_shape[0]; i++){ mid_num += (a[i] * y[i] * G[i][index]) } if(y[index] * (mid_num + b) <= 0){ a[index] += n b += (n * y[index]) sum = -1 } index = (index + 1) % x_shape[0] sum += 1 } // 求w let w = Get_Zero_Matrix([x_shape[1]]) for(let i = 0; i < x_shape[0]; i++){ w = Matrix_Add_Each(w, Matrix_Multiplication_Number(a[i] * y[i], x[i])) } console.log(w) console.log(b)其中的相关函数
/** * @Get_Matrix_shape 获取矩阵的行列数,也即矩阵的 shape(形状) * @matrix 矩阵 */ export function Get_Matrix_shape(matrix: any){ let shape_list = [matrix.length] if(matrix[0] && Array.isArray(matrix[0])){ shape_list.push(...Get_Matrix_shape(matrix[0])) } return shape_list } /** * @Get_Gram_Matrix 获取矩阵的Gram矩阵 * @param matrix */ export function Get_Gram_Matrix(matrix: any){ let Gram_matrix: any = [] let shape = Get_Matrix_shape(matrix) for(let i = 0; i < shape[0]; i++){ Gram_matrix.push([]) for(let j = 0; j < shape[0]; j++){ Gram_matrix[i].push(Get_Matrix_Transvection(matrix[i], matrix[j])) } } return Gram_matrix } /** * @Get_Matrix_Transvection 求两矩阵的内积(x1与x2的内积) * @param x1 * @param x2 */ export function Get_Matrix_Transvection(x1: any, x2: any){ // 两number变量,直接返回其乘法值 if(!Array.isArray(x1)){ return x1 * x2 } let x1_shape = Get_Matrix_shape(x1) let x2_shape = Get_Matrix_shape(x2) // 内积值 let sum_num = 0 let matrix: any = [] // 一维矩阵 if(x1_shape.length === 1){ if(x1_shape[0] === x2_shape[0]){ for(let i = 0; i < x1_shape[0]; i++){ sum_num += (x1[i] * x2[i]) } } return sum_num } // 二维矩阵 // 相关变量 let similar_num = 0 // 行列相同的总数 let index = -1 // 相似的行列的序号 for(let i = 0; i < 2; i++){ if(x1_shape[i] === x2_shape[i]){ similar_num += 1 index = i } } let x_l = [], x_r = [] if(similar_num === 1){ if(x1_shape[1 - index] === 1){ x_l = [...x1] x_r = [...x2] } else if(x2_shape[1 - index] === 1){ x_l = [...x2] x_r = [...x1] } else { return sum_num } if(index === 0){ for(let i = 0; i < x_r.length; i++){ for(let j = 0; j < x_r[0].length; j++){ sum_num += (x_l[i][0] * x_r[i][j]) } } }else{ for(let i = 0; i < x_r.length; i++){ for(let j = 0; j < x_r[0].length; j++){ sum_num += (x_l[0][j] * x_r[i][j]) } } } } else if(similar_num === 2){ for(let i = 0; i < x1_shape[0]; i++){ for(let j = 0; j < x1_shape[1]; j++){ sum_num += (x1[i][j] * x2[i][j]) } } } return sum_num } /** * @Get_Zero_Matrix 按指定形状创建一个 零矩阵 * @shape 矩阵shape形状数组 */ export function Get_Zero_Matrix(shape: number[]){ let matrix: any = [] if(shape.length === 1){ for(let i = 0; i < shape[0]; i++){ matrix.push(0) } } else { for(let i = 0; i < shape[0]; i++){ matrix.push(Get_Zero_Matrix(shape.slice(1))) } } return matrix } /** * @Matrix_Add_Each 两矩阵相加函数 * @param x1 矩阵1 * @param x2 矩阵2 */ export function Matrix_Add_Each(x1: any, x2: any){ let x1_shape = Get_Matrix_shape(x1) let matrix: any = [] if(x1_shape.length === 1){ for(let i = 0; i < x1_shape[0]; i++){ matrix.push(x1[i] + x2[i]) } } else { for(let i = 0; i < x1_shape[0]; i++){ matrix.push(Matrix_Add_Each(x1[i], x2[i])) } } return matrix } /** * @Matrix_Multiplication_Number 常数点乘矩阵 * @param number_ 常数 * @param matrix 矩阵 */ export function Matrix_Multiplication_Number(number_: number, matrix: any){ let shape = Get_Matrix_shape(matrix) let m: any = [] if(shape.length === 1){ for(let i = 0; i < shape[0]; i++){ m.push(matrix[i] * number_) } } else { for(let i = 0; i < shape[0]; i++){ m.push(Matrix_Multiplication_Number(number_, matrix[i])) } } return m }
4. 补充:
4.1 L 2 L_2 L2范数
向量所有元素的平方和的开平方。
即对于 n n n维特征 X = ( x 1 , x 2 , . . . , x n ) X=(x_1,x_2, ..., x_n) X=(x1,x2,...,xn),其 L 2 L_2 L2范数为:
∥ X ∥ 2 = ∑ i = 1 n x i 2 \left\|X\right\|_2 = \sqrt{\sum_{i=1}^{n} x_{i}^{2}} ∥X∥2=i=1∑nxi2