NNDL 实验三 线性回归
目录
2.2 线性回归
2.2.1 数据集构建
2.2.2 模型构建
2.2.3 损失函数
2.2.4 模型优化
2.2.5 模型训练
2.2.6 模型评估
2.2.7 样本数量 & 正则化系数
2.3 多项式回归
2.3.1 数据集构建
2.3.2 模型构建
2.3.3 模型训练
2.3.4 模型评估
2.4 Runner类介绍
2.5 基于线性回归的波士顿房价预测
2.5.1 数据处理
2.5.1.1 数据集介绍
2.5.1.2 数据清洗
2.5.1.3 数据集划分
2.5.1.4 特征工程
2.5.2 模型构建
2.5.3 完善Runner类
2.5.4 模型训练
2.5.5 模型测试
2.5.6 模型预测
记录一下:
2.2 线性回归
2.2.1 数据集构建
构造一个小的回归数据集:
生成 150 个带噪音的样本,其中 100 个训练样本,50 个测试样本,并打印出训练数据的可视化分布。
假设输入特征和输出标签的维度都为 1,需要被拟合的函数定义为:
# 真实函数的参数缺省值为 w=1.2,b=0.5
def linear_func(x,w=1.2,b=0.5):
y = w*x + b
return y
使用torch.rand()函数来进行随机采样输入特征xxx,并代入上面函数得到输出标签y。生成样本数据的函数create_toy_data实现如下
import torch
def create_toy_data(func, interval, sample_num, noise = 0.0, add_outlier = False, outlier_ratio = 0.001):
'''
根据给定的函数,生成样本
输入:
- func:函数
- interval: x的取值范围
- sample_num: 样本数目
- noise: 噪声均方差
- add_outlier:是否生成异常值
- outlier_ratio:异常值占比
输出:
- X: 特征数据,shape=[n_samples,1]
- y: 标签数据,shape=[n_samples,1]
'''
# 均匀采样
# 使用torch.rand在生成sample_num个随机数
X = torch.rand(size = [sample_num]) * (interval[1]-interval[0]) + interval[0]
y = func(X)
# 生成高斯分布的标签噪声
# 使用torch.normal生成0均值,noise标准差的数据
epsilon = torch.normal(0,noise,y.shape)
y = y + epsilon
if add_outlier: # 生成额外的异常点
outlier_num = int(len(y)*outlier_ratio)
if outlier_num != 0:
# 使用torch.randint生成服从均匀分布的、范围在[0, len(y))的随机Tensor
outlier_idx = torch.randint(len(y),size = [outlier_num])
y[outlier_idx] = y[outlier_idx] * 5
return X, y
利用上面的生成样本函数,生成 150 个带噪音的样本,其中 100 个训练样本,50 个测试样本,并打印出训练数据的可视化分布。
from matplotlib import pyplot as plt # matplotlib 是 Python 的绘图库
func = linear_func
interval = (-10,10)
train_num = 100 # 训练样本数目
test_num = 50 # 测试样本数目
noise = 2
X_train, y_train = create_toy_data(func=func, interval=interval, sample_num=train_num, noise = noise, add_outlier = False)
X_test, y_test = create_toy_data(func=func, interval=interval, sample_num=test_num, noise = noise, add_outlier = False)
X_train_large, y_train_large = create_toy_data(func=func, interval=interval, sample_num=5000, noise = noise, add_outlier = False)
# torch.linspace返回一个Tensor,Tensor的值为在区间start和stop上均匀间隔的num个值,输出Tensor的长度为num
X_underlying = torch.linspace(interval[0],interval[1],train_num)
y_underlying = linear_func(X_underlying)
# 绘制数据
plt.scatter(X_train, y_train, marker='*', facecolor="none", edgecolor='#e4007f', s=50, label="train data")
plt.scatter(X_test, y_test, marker='h',facecolor="none", edgecolor='#00FF7F', s=50, label="test data")
plt.plot(X_underlying, y_underlying, c='#000000', label=r"underlying distribution")
plt.legend(fontsize='x-large') # 给图像加图例
plt.savefig('ml-vis.pdf') # 保存图像到PDF文件中
plt.show() 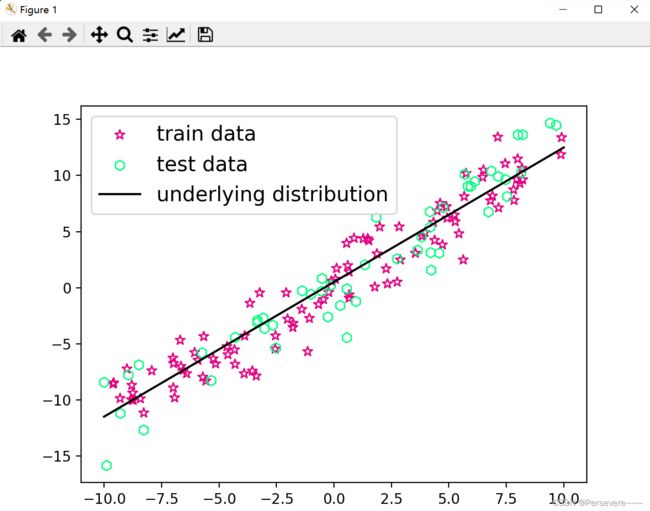
题外话:
飞桨中的源代码很好看,颜色好看,图案也好看。第一次知道绘图的时候除了用圆圈标记,还能用小星星,是我孤陋寡闻了。去查了查,才发现Matplotlib库里有很多功能,不愧是Python 最著名的绘图库。
2.2.2 模型构建
import torch
torch.seed() # 设置随机种子
class Op(object): #代码来自nndl.op
def __init__(self):
pass
def __call__(self, inputs):
return self.forward(inputs)
def forward(self, inputs):
raise NotImplementedError
def backward(self, inputs):
raise NotImplementedError
# 线性算子
class Linear(Op):
def __init__(self, input_size):
"""
输入:
- input_size:模型要处理的数据特征向量长度
"""
self.input_size = input_size
# 模型参数
self.params = {}
self.params['w'] = torch.randn(size=[self.input_size, 1], dtype=torch.float32)
self.params['b'] = torch.zeros(size=[1], dtype=torch.float32)
def __call__(self, X):
return self.forward(X)
# 前向函数
def forward(self, X):
"""
输入:
- X: tensor, shape=[N,D]
注意这里的X矩阵是由N个x向量的转置拼接成的,与原教材行向量表示方式不一致
输出:
- y_pred: tensor, shape=[N]
"""
N, D = X.shape
if self.input_size == 0:
return torch.full(shape=[N, 1], fill_value=self.params['b'])
assert D == self.input_size # 输入数据维度合法性验证
# 使用torch.matmul计算两个tensor的乘积
y_pred = torch.matmul(X, self.params['w']) + self.params['b']
return y_pred
# 注意这里我们为了和后面章节统一,这里的X矩阵是由N个x向量的转置拼接成的,与原教材行向量表示方式不一致
input_size = 3
N = 2
X = torch.randn(N,input_size) # 生成2个维度为3的数据
model = Linear(input_size)
y_pred = model(X)
print("y_pred:", y_pred) # 输出结果的个数也是2个

2.2.3 损失函数
回归任务中常用的评估指标是均方误差
均方误差(mean-square error, MSE)是反映估计量与被估计量之间差异程度的一种度量。
import torch
def mean_squared_error(y_true, y_pred):
"""
输入:
- y_true: tensor,样本真实标签
- y_pred: tensor, 样本预测标签
输出:
- error: float,误差值
"""
assert y_true.shape[0] == y_pred.shape[0]
# torch.square计算输入的平方值
# torch.mean沿 axis 计算 x 的平均值,默认axis是None,则对输入的全部元素计算平均值。
error = torch.mean(torch.square(y_true - y_pred))
return error
# 构造一个简单的样例进行测试:[N,1], N=2
y_true = torch.tensor([[-0.2], [4.9]], dtype=torch.float32)
y_pred = torch.tensor([[1.3], [2.5]], dtype=torch.float32)
error = mean_squared_error(y_true=y_true, y_pred=y_pred).item()
print("error:", error)

【注意:代码实现中没有除2】思考:没有除2合理么?谈谈自己的看法,写到实验报告。
答:合理。公式中有除以二,代码中没有并不影响最后的结果。在计算过程中有求偏导这一步,除以2是为了方便计算。
2.2.4 模型优化
经验风险 ( Empirical Risk ),即在训练集上的平均损失。
def optimizer_lsm(model, X, y, reg_lambda=0):
'''
输入:
- model: 模型
- X: tensor, 特征数据,shape=[N,D]
- y: tensor,标签数据,shape=[N]
- reg_lambda: float, 正则化系数,默认为0
输出:
- model: 优化好的模型
'''
N, D = X.shape
# 对输入特征数据所有特征向量求平均
x_bar_tran = torch.mean(X,0).T
# 求标签的均值,shape=[1]
y_bar = torch.mean(y)
# torch.subtract通过广播的方式实现矩阵减向量
x_sub = torch.subtract(X, x_bar_tran)
# 使用torch.all判断输入tensor是否全0
if torch.all(x_sub == 0):
model.params['b'] = y_bar
model.params['w'] = torch.zeros([D])
return model
# torch.inverse求方阵的逆
tmp = torch.inverse(torch.matmul(x_sub.T, x_sub) +
reg_lambda * torch.eye(D))
w = torch.matmul(torch.matmul(tmp, x_sub.T), (y - y_bar))
b = y_bar - torch.matmul(x_bar_tran, w)
model.params['b'] = b
model.params['w'] = torch.squeeze(w, -1)
return model
思考1. 为什么省略了不影响效果?
答: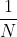 是一个常数,省略常数并不会影响效果。
是一个常数,省略常数并不会影响效果。
思考 2. 什么是最小二乘法 ( Least Square Method , LSM )
答:
最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差(真实目标对象与拟合目标对象的差)的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。
- 最小二乘法还可用于曲线拟合。对于平面中的这n个点,可以使用无数条曲线来拟合。要求样本回归函数尽可能好地拟合这组值。综合起来看,这条直线处于样本数据的中心位置最合理。
- 选择最佳拟合曲线的标准可以确定为:使总的拟合误差(即总残差)达到最小
最小二乘法也是一种优化方法,求得目标函数的最优值。并且也可以用于曲线拟合,来解决回归问题。回归学习最常用的损失函数是平方损失函数,在此情况下,回归问题可以著名的最小二乘法来解决。
简而言之,最小二乘法同梯度下降类似,都是一种求解无约束最优化问题的常用方法,并且也可以用于曲线拟合,来解决回归问题。
————————————————
原文链接:https://blog.csdn.net/W1995S/article/details/118153146
2.2.5 模型训练
在准备了数据、模型、损失函数和参数学习的实现之后,开始模型的训练。
在回归任务中,模型的评价指标和损失函数一致,都为均方误差。
通过上文实现的线性回归类来拟合训练数据,并输出模型在训练集上的损失。
input_size = 1
model = Linear(input_size)
model = optimizer_lsm(model,X_train.reshape([-1,1]),y_train.reshape([-1,1]))
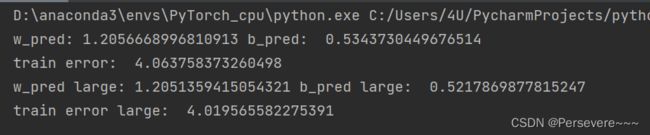
print("w_pred:", model.params['w'].item(), "b_pred: ", model.params['b'].item())
y_train_pred = model(X_train.reshape([-1,1])).squeeze()
train_error = mean_squared_error(y_true=y_train, y_pred=y_train_pred).item()
print("train error: ", train_error)

model_large = Linear(input_size)
model_large = optimizer_lsm(model_large,X_train_large.reshape([-1,1]),y_train_large.reshape([-1,1]))
print("w_pred large:",model_large.params['w'].item(), "b_pred large: ", model_large.params['b'].item())
y_train_pred_large = model_large(X_train_large.reshape([-1,1])).squeeze()
train_error_large = mean_squared_error(y_true=y_train_large, y_pred=y_train_pred_large).item()
print("train error large: ",train_error_large)

从输出结果看,预测结果与真实值w=1.2,b=0.5有一定的差距。
2.2.6 模型评估
用训练好的模型预测一下测试集的标签,并计算在测试集上的损失。
y_test_pred = model(X_test.reshape([-1,1])).squeeze()
test_error = mean_squared_error(y_true=y_test, y_pred=y_test_pred).item()
print("test error: ",test_error)
y_test_pred_large = model_large(X_test.reshape([-1,1])).squeeze()
test_error_large = mean_squared_error(y_true=y_test, y_pred=y_test_pred_large).item()
print("test error large: ",test_error_large)
2.2.7 样本数量 & 正则化系数
(1) 调整训练数据的样本数量,由 100 调整到 5000,观察对模型性能的影响。
(2) 调整正则化系数,观察对模型性能的影响。
2.3 多项式回归
2.3.1 数据集构建
构建训练和测试数据,其中:
训练数样本 15 个,测试样本 10 个,高斯噪声标准差为 0.1,自变量范围为 (0,1)。
假设要拟合的非线性函数为一个缩放后的sin函数。
import torch
import math
# sin函数: sin(2 * pi * x)
def sin(x):
y = torch.sin(2 * math.pi * x)
return y
这里仍然使用前面定义的create_toy_data函数来构建训练和测试数据,其中训练数样本 15 个,测试样本 10 个,高斯噪声标准差为 0.1,自变量范围为 (0,1)。
from matplotlib import pyplot as plt # matplotlib 是 Python 的绘图库
def create_toy_data(func, interval, sample_num, noise=0.0, add_outlier=False, outlier_ratio=0.001):
"""
根据给定的函数,生成样本
输入:
- func:函数
- interval: x的取值范围
- sample_num: 样本数目
- noise: 噪声均方差
- add_outlier:是否生成异常值
- outlier_ratio:异常值占比
输出:
- X: 特征数据,shape=[n_samples,1]
- y: 标签数据,shape=[n_samples,1]
"""
# 均匀采样
# 使用torch.rand在生成sample_num个随机数
X = torch.rand(size=[sample_num]) * (interval[1] - interval[0]) + interval[0]
y = func(X)
# 生成高斯分布的标签噪声
# 使用torch.normal生成0均值,noise标准差的数据
epsilon = torch.normal(0, noise, y.shape)
y = y + epsilon
if add_outlier: # 生成额外的异常点
outlier_num = int(len(y) * outlier_ratio)
if outlier_num != 0:
# 使用paddle.randint生成服从均匀分布的、范围在[0, len(y))的随机Tensor
outlier_idx = torch.randint(len(y), size=[outlier_num])
y[outlier_idx] = y[outlier_idx] * 5
return X, y
# 生成数据
func = sin
interval = (0, 1)
train_num = 15
test_num = 10
noise = 0.5 # 0.1
X_train, y_train = create_toy_data(func=func, interval=interval, sample_num=train_num, noise=noise)
X_test, y_test = create_toy_data(func=func, interval=interval, sample_num=test_num, noise=noise)
X_underlying = torch.linspace(interval[0], interval[1], 100)
y_underlying = sin(X_underlying)
# 绘制图像
plt.rcParams['figure.figsize'] = (8.0, 6.0)
plt.scatter(X_train, y_train,marker='v', facecolor="none", edgecolor='#e4007f', s=50, label="train data")
plt.scatter(X_test, y_test,marker='P', facecolor="none", edgecolor="b", s=50, label="test data")
plt.plot(X_underlying, y_underlying, c='#000000', label=r"$\sin(2\pi x)$")
plt.legend(fontsize='x-large')
plt.savefig('ml-vis2.pdf')
plt.show()

2.3.2 模型构建
套用求解线性回归参数的方法来求解多项式回归参数。
# 多项式转换
def polynomial_basis_function(x, degree=2):
"""
输入:
- x: tensor, 输入的数据,shape=[N,1]
- degree: int, 多项式的阶数
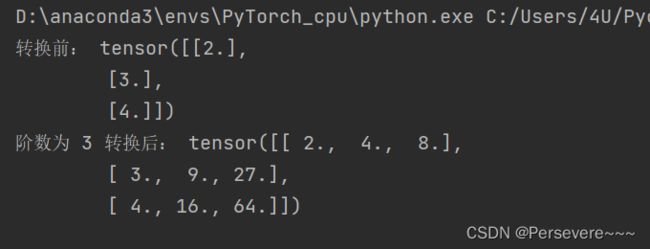
example Input: [[2], [3], [4]], degree=2
example Output: [[2^1, 2^2], [3^1, 3^2], [4^1, 4^2]]
注意:本案例中,在degree>=1时不生成全为1的一列数据;degree为0时生成形状与输入相同,全1的Tensor
输出:
- x_result: tensor
"""
if degree == 0:
# x = torch.ones(x.shape)
# x = x.to(torch.float32)
# return x
return torch.ones(x.shape)
x_tmp = x
x_result = x_tmp
for i in range(2, degree + 1):
x_tmp = torch.multiply(x_tmp, x) # 逐元素相乘
x_result = torch.concat((x_result, x_tmp), dim=-1)
return x_result
# 简单测试
data = [[2], [3], [4]]
X = torch.tensor(data=data)
X = X.to(torch.float32)
degree = 3
transformed_X = polynomial_basis_function(X, degree=degree)
print("转换前:", X)
print("阶数为", degree, "转换后:", transformed_X)
2.3.3 模型训练
对于多项式回归,我们可以同样使用前面线性回归中定义的LinearRegression算子、训练函数train、均方误差函数mean_squared_error。
plt.rcParams['figure.figsize'] = (12.0, 8.0)
for i, degree in enumerate([0, 1, 3, 8]): # []中为多项式的阶数
model = Linear(degree)
X_train_transformed = polynomial_basis_function(X_train.reshape([-1, 1]), degree)
X_underlying_transformed = polynomial_basis_function(X_underlying.reshape([-1, 1]), degree)
model = optimizer_lsm(model, X_train_transformed, y_train.reshape([-1, 1])) # 拟合得到参数
y_underlying_pred = model(X_underlying_transformed).squeeze()
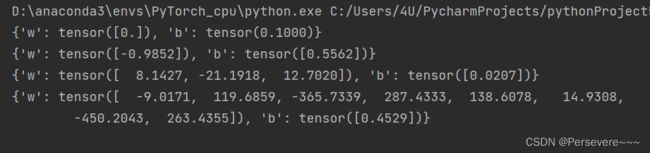
print(model.params)
# 绘制图像
plt.subplot(2, 2, i + 1)
plt.scatter(X_train, y_train, facecolor="none", edgecolor='#e4007f', s=50, label="train data")
plt.plot(X_underlying, y_underlying, c='#000000', label=r"$\sin(2\pi x)$")
plt.plot(X_underlying, y_underlying_pred, c='#f19ec2', label="predicted function")
plt.ylim(-2, 1.5)
plt.annotate("M={}".format(degree), xy=(0.95, -1.4))
# plt.legend(bbox_to_anchor=(1.05, 0.64), loc=2, borderaxespad=0.)
plt.legend(loc='lower left', fontsize='x-large')
plt.savefig('ml-vis3.pdf')
plt.show()
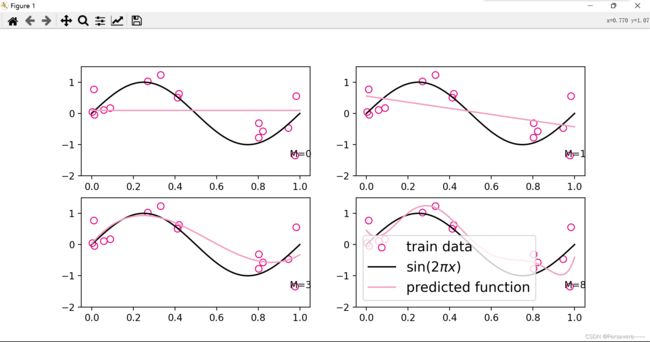
观察可视化结果,红色的曲线表示不同阶多项式分布拟合数据的结果:
- 当 M=0M=0M=0 或 M=1M=1M=1 时,拟合曲线较简单,模型欠拟合;
- 当 M=8M=8M=8 时,拟合曲线较复杂,模型过拟合;
- 当 M=3M=3M=3 时,模型拟合最为合理。
2.3.4 模型评估
通过均方误差来衡量训练误差、测试误差以及在没有噪音的加入下sin函数值与多项式回归值之间的误差,更加真实地反映拟合结果。多项式分布阶数从0到8进行遍历。
对于模型过拟合的情况,可以引入正则化方法,通过向误差函数中添加一个惩罚项来避免系数倾向于较大的取值。
# 训练误差和测试误差
training_errors = []
test_errors = []
distribution_errors = []
# 遍历多项式阶数
for i in range(9):
model = Linear(i)
X_train_transformed = polynomial_basis_function(X_train.reshape([-1, 1]), i)
X_test_transformed = polynomial_basis_function(X_test.reshape([-1, 1]), i)
X_underlying_transformed = polynomial_basis_function(X_underlying.reshape([-1, 1]), i)
optimizer_lsm(model, X_train_transformed, y_train.reshape([-1, 1]))
y_train_pred = model(X_train_transformed).squeeze()
y_test_pred = model(X_test_transformed).squeeze()
y_underlying_pred = model(X_underlying_transformed).squeeze()
train_mse = mean_squared_error(y_true=y_train, y_pred=y_train_pred).item()
training_errors.append(train_mse)
test_mse = mean_squared_error(y_true=y_test, y_pred=y_test_pred).item()
test_errors.append(test_mse)
# distribution_mse = mean_squared_error(y_true=y_underlying, y_pred=y_underlying_pred).item()
# distribution_errors.append(distribution_mse)
print("train errors: \n", training_errors)
print("test errors: \n", test_errors)
# print ("distribution errors: \n", distribution_errors)
# 绘制图片
plt.rcParams['figure.figsize'] = (8.0, 6.0)
plt.plot(training_errors, '-.', mfc="none", mec='#e4007f', ms=10, c='#e4007f', label="Training")
plt.plot(test_errors, '--', mfc="none", mec='#f19ec2', ms=10, c='#f19ec2', label="Test")
# plt.plot(distribution_errors, '-', mfc="none", mec="#3D3D3F", ms=10, c="#3D3D3F", label="Distribution")
plt.legend(fontsize='x-large')
plt.xlabel("degree")
plt.ylabel("MSE")
plt.savefig('ml-mse-error.pdf')
plt.show()
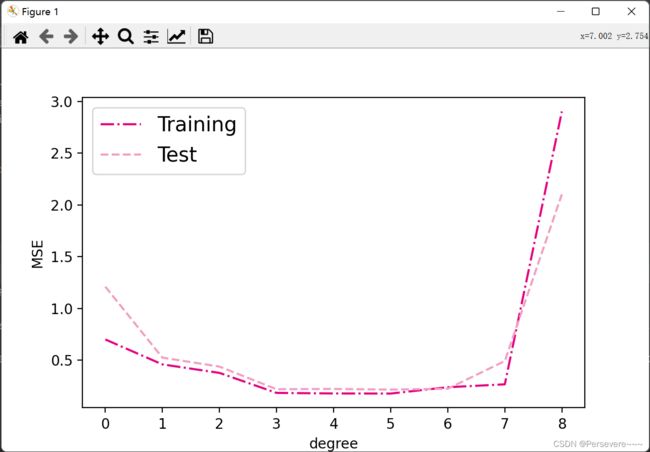
train errors:
[0.7006273865699768, 0.459964781999588, 0.37801748514175415, 0.18488360941410065, 0.1794089674949646, 0.17847533524036407, 0.23975566029548645, 0.26745325326919556, 2.901869535446167]
test errors:
[1.2100856304168701, 0.5253490805625916, 0.4387543797492981, 0.2201036661863327, 0.22330334782600403, 0.2164992392063141, 0.2250174731016159, 0.4922424852848053, 2.102128505706787]
观察可视化结果:
- 当阶数较低的时候,模型的表示能力有限,训练误差和测试误差都很高,代表模型欠拟合;
- 当阶数较高的时候,模型表示能力强,但将训练数据中的噪声也作为特征进行学习,一般情况下训练误差继续降低而测试误差显著升高,代表模型过拟合。
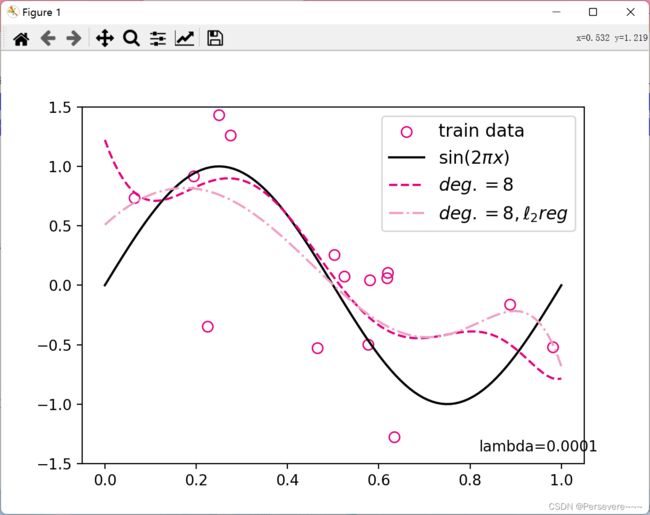
对于模型过拟合的情况,可以引入正则化方法,通过向误差函数中添加一个惩罚项来避免系数倾向于较大的取值。下面加入 正则化项,查看拟合结果。
正则化项,查看拟合结果。
degree = 8 # 多项式阶数
reg_lambda = 0.0001 # 正则化系数
X_train_transformed = polynomial_basis_function(X_train.reshape([-1,1]), degree)
X_test_transformed = polynomial_basis_function(X_test.reshape([-1,1]), degree)
X_underlying_transformed = polynomial_basis_function(X_underlying.reshape([-1,1]), degree)
model = Linear(degree)
optimizer_lsm(model,X_train_transformed,y_train.reshape([-1,1]))
y_test_pred=model(X_test_transformed).squeeze()
y_underlying_pred=model(X_underlying_transformed).squeeze()
model_reg = Linear(degree)
optimizer_lsm(model_reg,X_train_transformed,y_train.reshape([-1,1]),reg_lambda=reg_lambda)
y_test_pred_reg=model_reg(X_test_transformed).squeeze()
y_underlying_pred_reg=model_reg(X_underlying_transformed).squeeze()
mse = mean_squared_error(y_true = y_test, y_pred = y_test_pred).item()
print("mse:",mse)
mes_reg = mean_squared_error(y_true = y_test, y_pred = y_test_pred_reg).item()
print("mse_with_l2_reg:",mes_reg)
# 绘制图像
plt.scatter(X_train, y_train, facecolor="none", edgecolor="#e4007f", s=50, label="train data")
plt.plot(X_underlying, y_underlying, c='#000000', label=r"$\sin(2\pi x)$")
plt.plot(X_underlying, y_underlying_pred, c='#e4007f', linestyle="--", label="$deg. = 8$")
plt.plot(X_underlying, y_underlying_pred_reg, c='#f19ec2', linestyle="-.", label="$deg. = 8, \ell_2 reg$")
plt.ylim(-1.5, 1.5)
plt.annotate("lambda={}".format(reg_lambda), xy=(0.82, -1.4))
plt.legend(fontsize='large')
plt.savefig('ml-vis4.pdf')
plt.show()

2.4 Runner类介绍
机器学习方法流程包括数据集构建、模型构建、损失函数定义、优化器、模型训练、模型评价、模型预测等环节。
为了更方便地将上述环节规范化,我们将机器学习模型的基本要素封装成一个Runner类。
除上述提到的要素外,再加上模型保存、模型加载等功能。
Runner类的成员函数定义如下:
__init__函数:实例化Runner类,需要传入模型、损失函数、优化器和评价指标等;
train函数:模型训练,指定模型训练需要的训练集和验证集;
evaluate函数:通过对训练好的模型进行评价,在验证集或测试集上查看模型训练效果;
predict函数:选取一条数据对训练好的模型进行预测;
save_model函数:模型在训练过程和训练结束后需要进行保存;
load_model函数:调用加载之前保存的模型。
class Runner(object):
def __init__(self, model, optimizer, loss_fn, metric):
self.model = model # 模型
self.optimizer = optimizer # 优化器
self.loss_fn = loss_fn # 损失函数
self.metric = metric # 评估指标
# 模型训练
def train(self, train_dataset, dev_dataset=None, **kwargs):
pass
# 模型评价
def evaluate(self, data_set, **kwargs):
pass
# 模型预测
def predict(self, x, **kwargs):
pass
# 模型保存
def save_model(self, save_path):
pass
# 模型加载
def load_model(self, model_path):
pass
2.5 基于线性回归的波士顿房价预测
使用线性回归来对马萨诸塞州波士顿郊区的房屋进行预测。
实验流程主要包含如下5个步骤:
数据处理:包括数据清洗(缺失值和异常值处理)、数据集划分,以便数据可以被模型正常读取,并具有良好的泛化性;
模型构建:定义线性回归模型类;
训练配置:训练相关的一些配置,如:优化算法、评价指标等;
组装训练框架Runner:Runner用于管理模型训练和测试过程;
模型训练和测试:利用Runner进行模型训练和测试。
2.5.1 数据处理
2.5.1.1 数据集介绍
●波士顿房价预测数据集
●506条样本数据,12种可能影响房价的因素和该类房屋价格中位数
import torch
import pandas as pd # 开源数据分析和操作工具
# 利用pandas加载波士顿房价的数据集
data=pd.read_csv("boston_house_prices.csv")
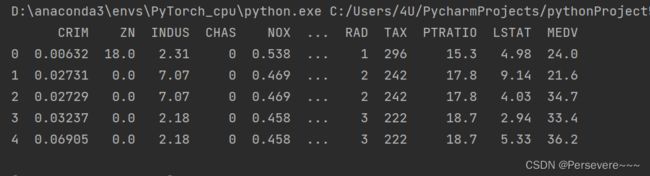
# 预览前5行数据
print(data.head())
2.5.1.2 数据清洗
●缺失值分析
●异常值处理
通过isna()方法判断数据中各元素是否缺失,然后通过sum()方法统计每个字段缺失情况,代码实现如下:
# 查看各字段缺失值统计情况
print(data.isna().sum())
从输出结果看,波士顿房价预测数据集中不存在缺失值的情况。
通过箱线图显示数据分布:
from matplotlib import pyplot as plt # matplotlib 是 Python 的绘图库
# 箱线图查看异常值分布
def boxplot(data, fig_name):
# 绘制每个属性的箱线图
data_col = list(data.columns)
# 连续画几个图片
plt.figure(figsize=(5, 5), dpi=300)
# 子图调整
plt.subplots_adjust(wspace=0.6)
# 每个特征画一个箱线图
for i, col_name in enumerate(data_col):
plt.subplot(3, 5, i + 1)
# 画箱线图
plt.boxplot(data[col_name],
showmeans=True,
meanprops={"markersize": 1, "marker": "D", "markeredgecolor": '#f19ec2'}, # 均值的属性
medianprops={"color": '#e4007f'}, # 中位数线的属性
whiskerprops={"color": '#e4007f', "linewidth": 0.4, 'linestyle': "--"},
flierprops={"markersize": 0.4},
)
# 图名
plt.title(col_name, fontdict={"size": 5}, pad=2)
# y方向刻度
plt.yticks(fontsize=4, rotation=90)
plt.tick_params(pad=0.5)
# x方向刻度
plt.xticks([])
plt.savefig('ml-vis5.pdf')
plt.show()
boxplot(data,'ml-vis5.pdf')

使用四分位值筛选出箱线图中分布的异常值,并将这些数据视为噪声,其将被临界值取代
最大估计值 = 上四分位 + 1.5 ∗ (上四分位 − 下四分位)
最小估计值 = 下四分位 − 1.5 ∗ (上四分位 − 下四分位)
# 四分位处理异常值
num_features=data.select_dtypes(exclude=['object','bool']).columns.tolist()
for feature in num_features:
if feature =='CHAS':
continue
Q1 = data[feature].quantile(q=0.25) # 下四分位
Q3 = data[feature].quantile(q=0.75) # 上四分位
IQR = Q3-Q1
top = Q3+1.5*IQR # 最大估计值
bot = Q1-1.5*IQR # 最小估计值
values=data[feature].values
values[values > top] = top # 临界值取代噪声
values[values < bot] = bot # 临界值取代噪声
data[feature] = values.astype(data[feature].dtypes)
# 再次查看箱线图,异常值已被临界值替换(数据量较多或本身异常值较少时,箱线图展示会不容易体现出来)
boxplot(data, 'ml-vis6.pdf')

对比图
题外话:有点像找不同:)
2.5.1.3 数据集划分
●训练集和测试集
import torch
torch.seed()
# 划分训练集和测试集
def train_test_split(X, y, train_percent=0.8):
n = len(X)
shuffled_indices = torch.randperm(n) # 返回一个数值在0到n-1、随机排列的1-D Tensor
train_set_size = int(n * train_percent)
train_indices = shuffled_indices[:train_set_size]
test_indices = shuffled_indices[train_set_size:]
X = X.values
y = y.values
X_train = X[train_indices]
y_train = y[train_indices]
X_test = X[test_indices]
y_test = y[test_indices]
return X_train, X_test, y_train, y_test
X = data.drop(['MEDV'], axis=1) #MEDV代表房价
y = data['MEDV']
X_train, X_test, y_train, y_test = train_test_split(X, y) # X_train每一行是个样本,shape[N,D]
2.5.1.4 特征工程
●消除量纲对特征的影响,对数据特征进行归一化处理,缩放到[0,1]
X_train = torch.tensor(X_train,dtype=torch.float32)
X_test = torch.tensor(X_test,dtype=torch.float32)
y_train = torch.tensor(y_train,dtype=torch.float32)
y_test = torch.tensor(y_test,dtype=torch.float32)
X_min = torch.min(X_train)
X_max = torch.max(X_train)
X_train = (X_train-X_min)/(X_max-X_min)
X_test = (X_test-X_min)/(X_max-X_min)
# 训练集构造
train_dataset=(X_train,y_train)
# 测试集构造
test_dataset=(X_test,y_test)
2.5.2 模型构建
torch.seed() # 设置随机种子
# 线性回归模型,基于最小二乘法实现
class Linear(object):
def __init__(self, input_size):
"""
输入:
- input_size:模型要处理的数据特征向量长度
"""
self.input_size = input_size
# 模型参数
self.params = {}
self.params['w'] = torch.randn(size=[self.input_size, 1], dtype=torch.float32)
self.params['b'] = torch.zeros(size=[1], dtype=torch.float32)
def __call__(self, X):
return self.forward(X)
# 前向函数
def forward(self, X):
"""
输入:
- X: tensor, shape=[N,D]
注意这里的X矩阵是由N个x向量的转置拼接成的,与原教材行向量表示方式不一致
输出:
- y_pred: tensor, shape=[N]
"""
N, D = X.shape
if self.input_size == 0:
return torch.full(shape=[N, 1], fill_value=self.params['b'])
assert D == self.input_size # 输入数据维度合法性验证
# 使用torch.matmul计算两个tensor的乘积
y_pred = torch.matmul(X, self.params['w']) + self.params['b']
return y_pred
实例化一个线性回归模型,特征维度为 12:
# 模型实例化
input_size = 12
model=Linear(input_size)
2.5.3 完善Runner类
模型定义好后,围绕模型需要配置损失函数、优化器、评估、测试等信息,以及模型相关的一些其他信息(如模型存储路径等)。
在本章中使用的Runner类为V1版本。其中训练过程通过直接求解解析解的方式得到模型参数,没有模型优化及计算损失函数过程,模型训练结束后保存模型参数。
训练配置中定义:
- 训练环境,如GPU还是CPU,本案例不涉及;
- 优化器,本案例不涉及;
- 损失函数,本案例通过平方损失函数得到模型参数的解析解;
- 评估指标,本案例利用MSE评估模型效果。
在测试集上使用MSE对模型性能进行评估。
import torch.nn as nn
mse_loss = nn.MSELoss()
具体实现如下:
import os
from nndl.opitimizer import optimizer_lsm
class Runner(object):
def __init__(self, model, optimizer, loss_fn, metric):
# 优化器和损失函数为None,不再关注
# 模型
self.model = model
# 评估指标
self.metric = metric
# 优化器
self.optimizer = optimizer
def train(self, dataset, reg_lambda, model_dir):
X, y = dataset
self.optimizer(self.model, X, y, reg_lambda)
# 保存模型
self.save_model(model_dir)
def evaluate(self, dataset, **kwargs):
X, y = dataset
y_pred = self.model(X)
result = self.metric(y_pred, y)
return result
def predict(self, X, **kwargs):
return self.model(X)
def save_model(self, model_dir):
if not os.path.exists(model_dir):
os.makedirs(model_dir)
params_saved_path = os.path.join(model_dir, 'params.pdtensor')
torch.save(model.params, params_saved_path)
def load_model(self, model_dir):
params_saved_path = os.path.join(model_dir, 'params.pdtensor')
self.model.params = torch.load(params_saved_path)
optimizer = optimizer_lsm
# 实例化Runner
runner = Runner(model, optimizer=optimizer, loss_fn=None, metric=mse_loss)
2.5.4 模型训练
在组装完成Runner之后,我们将开始进行模型训练、评估和测试。首先,我们先实例化Runner,然后开始进行装配训练环境,接下来就可以开始训练,代码如下:
# 模型保存到文件夹中
saved_dir = 'pythonPoject5'
# 启动训练
runner.train(train_dataset, reg_lambda=0, model_dir=saved_dir)
打印出训练得到的权重:
columns_list = data.columns.to_list()
weights = runner.model.params['w'].tolist()
b = runner.model.params['b'].item()
for i in range(len(weights)):
print(columns_list[i],"weight:",weights[i])
print("b:",b)

从输出结果看,CRIM、PTRATIO等的权重为负数,表示人均犯罪率与房价呈负相关,学生与教师比例越大,房价越低。
2.5.5 模型测试
加载训练好的模型参数,在测试集上得到模型的MSE指标。
# 加载模型权重
runner.load_model(saved_dir)
mse = runner.evaluate(test_dataset)
print('MSE:', mse.item())

2.5.6 模型预测
使用Runner中load_model函数加载保存好的模型,使用predict进行模型预测,代码如下:
runner.load_model(saved_dir)
pred = runner.predict(X_test[:1])
print("真实房价:",y_test[:1].item())
print("预测的房价:",pred.item())

问题1:使用类实现机器学习模型的基本要素有什么优点?
答:简单好用,易于理解,容易实现,无需估计参数,无需训练,准确度高,既可以用来做分类也可以用来做回归,用起来很方便。
问题2:算子op、优化器opitimizer放在单独的文件中,主程序在使用时调用该文件。这样做有什么优点?
答:调用起来很方便,快捷简单,可以简化主程序,使主程序看起来更舒服。
问题3:线性回归通常使用平方损失函数,能否使用交叉熵损失函数?为什么?
答:从平方损失函数运用到多分类场景下,可知平方损失函数对每一个输出结果都十分看重,而交叉熵损失函数只对正确分类的结果看重。交叉熵损失函数只和分类正确的预测结果有关。而平方损失函数还和错误的分类有关,该损失函数除了让正确分类尽量变大,还会让错误分类都变得更加平均,但实际中后面的这个调整使没必要的。但是对于回归问题这样的考虑就显得重要了,因而回归问题上使用交叉熵并不适合。
http://t.csdn.cn/9dZbm  http://t.csdn.cn/9dZbm
http://t.csdn.cn/9dZbm
(这篇文章写的很详细)
记录一下:
本次实验是以飞桨中的内容为模板,使用pytorch实现的。飞桨中写的很完整很详细,很系统,一步步引导着我们学习,是非常好的学习资料了。
而在写实验报告的过程中,老师也留下了一些问题,通过这些问题引导我们进行思考,带着问题去学习,能更好的理解,印象也会更深刻。
本次实验对自己来说还是有难度的,需要继续努力,多花些时间去学习理解并掌握。
参考内容&代码来源:飞桨;
http://t.csdn.cn/UJ8r4http://t.csdn.cn/UJ8r4