综述:基于深度学习的文本分类 --《Deep Learning Based Text Classification: A Comprehensive Review》总结(一)
文章目录
-
- 综述:基于深度学习的文本分类
-
-
- 《Deep Learning Based Text Classification: A Comprehensive Review》论文总结(一)
- 总结
- 1.Introduction
-
- 文本分类任务
- 2.用于文本分类的深度学习模型
-
- 2.1 Feed-Forward Neural Networks
- 2.2 RNN-Based Models
- 2.3 CNN-Based Models
- 2.4 Capsule Neural Networks
- 2.5 Models with Attention Mechanism
- 2.6 Memory-Augmented Networks
- 2.7 Transformers
- 2.8 Graph Neural Networks
- 2.9 Siamese Neural Networks
- 2.10 Hybrid Models
- 2.11 Beyond Supervised Learning
-
- Unsupervised Learning using Autoencoders使用自动编码器的无监督学习
- Adversarial Training对抗训练
- Reinforcement Learning强化学习
-
综述:基于深度学习的文本分类
《Deep Learning Based Text Classification: A Comprehensive Review》论文总结(一)
Minaee S, Kalchbrenner N, Cambria E, et al. Deep learning based text classification: A comprehensive review[J]. arXiv preprint arXiv:2004.03705, 2020.
原文链接:https://arxiv.org/pdf/2004.03705.pdf
参考博主「一只羊呀」:Deep Learning Based Text Classification: A Comprehensive Review(部分翻译总结)的总结
总结
在这项工作中,作者
- 详细回顾了近年来开发的150多个基于深度学习的文本分类模型,并讨论了它们的技术贡献、相似性和优势。
- 总结了超过40个广泛用于文本分类的流行的数据集。
- 总结了性能评价指标,一组深度学习模型的性能进行了定量分析。
- 讨论剩下的挑战和未来的方向
1.Introduction
自动文本分类的方法可以分为三类:Rule-based methods基于规则的方法、 Machine learning (data-driven) based methods数据驱动的机器学习方法、Hybrid methods混合方法。
基于规则的方法使用一组预定义的规则将文本分类成不同的类别。例如,带有单词“football”、“basketball”或“baseball”的任何文档都被指定为“sport”标签。
这些方法需要对领域有深入的了解,并且系统很难维护。基于机器学习的方法学习使用预先标记的例子作为训练数据,可以学习文本片段和它们的标签之间的内在关联,根据过去对数据的观察进行分类。因此基于机器学习的方法可以检测数据中的隐藏模式,具有更强的可扩展性,可以应用于各种任务。这与基于规则的方法相反,基于规则的方法对于不同的任务需要不同的规则集。
混合方法,顾名思义,是将基于规则的方法和机器学习方法结合起来进行预测。
大多数经典的基于机器学习的模型遵循流行的两步程序,第一步从文档(或任何其他文本单元)中提取一些手工制作的特征,第二步将这些特征提供给分类器进行预测。一些流行的手工制作特征方法包括词袋模型bag of words (BoW)及其扩展。流行的分类算法包括朴素贝叶斯、支持向量机(SVM)、隐马尔可夫模型(HMM)、梯度增强树和随机森林。两步方法有几个局限性。例如,依赖手工制作的特性需要冗长的特性工程和分析才能获得良好的性能; 由于设计特征对领域知识的强烈依赖,使得该方法难以推广到新任务; 因为特征(或特征模板)是预先定义的, 这些模型不能充分利用大量的训练数据。
2012年,基于深度学习的模型AlexNet在ImageNet竞赛中大胜,自那以后,深度学习模型被广泛应用于计算机视觉和自然语言处理的任务中。这些模型试图学习特征表示,并以端到端的方式进行分类(或回归)。它们不仅能够发现数据中隐藏的模式,而且从一个应用程序到另一个应用程序的可转移性要大得多。这些模型正在成为近年来各种文本分类任务的主流框架。
文本分类任务
不同的文本分类任务有:情感分析sentiment analysis、新闻分类news categorization、主题分类topic analysis、问答question answering(QA)和自然语言推理Nature language inference(NLI)。
QA系统有两种类型:抽取式和生成式。抽取式给定一个问题和一组候选答案,我们需要将每个候选答案分类为正确或不正确。生成QA学习从头开始生成答案(例如使用seq2seq模型),这种本文不讨论。
NLI也被称为识别文本涵recognizing textual entailment(RTE),它预测一个文本的意义是否可以从另一个文本中推断出来。系统需要为每对文本单元分配一个标签,例如包含,矛盾和中性。 释义Paraphrasing是NLI的一种广义形式,也称为文本对比较。 任务是测量一个句子对的语义相似度,以确定一个句子是否是另一个句子的释义。
2.用于文本分类的深度学习模型
本节主要介绍
- 基于前馈网络的模型feed-forward networks,该模型将文本视为一袋单词(2.1)。
- 基于RNN的模型,该模型将文本视为单词序列,旨在捕获单词相关性和文本结构(2.2)。
- 基于CNN的模型,经过训练可以识别文本中的模式(例如关键短语)进行分类(2.3)
- 胶囊网络Capsule networks,用于解决CNN的合并操作所遭受的信息丢失问题,最近已应用于文本分类(2.4)。
- 注意机制,可以有效地识别文本中的相关单词,并已成为开发深度学习模型的有用工具(2.5)。
- 内存增强网络Memory-augmented networks,它将神经网络与外部存储器形式结合在一起,模型可以从中读取和写入数据(2.6)。
- transformers,比RNN允许更多的并行化,从而可以使用GPU群集有效地(预)训练非常大的语言模型(2.7)。
- 图神经网络,旨在捕获自然语言的内部图结构,例如句法和语义解析树(2.8)。
- Siamese Neural Networks,用于文本匹配,这是文本分类的一种特殊情况(2.9)。
- 混合模型,结合注意力,RNN,CNN等以捕获句子和文档的局部和全局特征(2.10)。
- 有监督学习之外的建模技术,包括使用自动编码器和对抗训练的无监督学习,以及强化学习(2.11)。
2.1 Feed-Forward Neural Networks
前馈神经网络是一种最简单的神经网络,各神经元分层排列。每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层.各层间没有反馈。
将文本视为一袋单词。对于每个单词,使用诸如word2vec或Glove之类的嵌入模型学习向量表示,将向量的总和或平均值作为文本的表示,将其通过一个或多个前馈层,然后使用分类器(例如逻辑回归,朴素贝叶斯或SVM)对最终层的表示进行分类。
这些模型的一个示例是深度平均网络(DAN),其体系结构如图1所示。模型旨在显式地学习文本的组成。DAN在具有较高语法差异的数据集上的表现优于语法模型。 Joulin等提出了一种简单而有效的文本分类器,称为fastText。像DAN一样,fastText将文本视为一袋单词。与DAN不同,fastText使用一袋n-gram作为附加功能来捕获本地单词顺序信息。事实证明,这在实践中非常有效,同时可以获得与显式使用单词顺序的方法相当的结果。
2.2 RNN-Based Models
基于rnn的模型将文本视为单词序列,旨在捕获单词相关性和文本结构,用于文本分类。然而,传统的RNN模型并不能很好地工作,而且常常不如前馈神经网络。在rnn的许多变体中,LSTM是最流行的体系结构,其设计目的是更好地捕捉长期依赖关系。LSTM通过引入一个记忆单元来记忆任意时间间隔内的值,以及三个门(输入门、输出门、遗忘门)来调节进出细胞的信息流,解决了普通rnn所遇到的梯度消失或爆炸问题。通过捕获更丰富的信息,如自然语言的树结构、文本中的大跨度词关系、文档主题等,改进rnn和LSTM模型用于文本分类。
Tai等人开发了一个Tree-LSTM模型,将LSTM推广到树形结构的网络类型,以学习丰富的语义表示。作者认为Tree-LSTM比链结构LSTM在NLP任务中是一个更好的模型,因为自然语言具有将单词自然地组合成短语的语法属性。他们验证了Tree-LSTM在两个任务上的有效性:情感分类和两个句子的语义关联预测。
为了对机器学习的大跨度单词关系进行建模,Cheng等人用一个存储网络代替单个存储单元来增强LSTM体系结构。 该模型在语言建模,情感分析和NLI上取得了可喜的结果。
多时间尺度LSTM (MT-LSTM)神经网络也被设计用来模拟长文本,如句子和文档,通过捕捉不同时间尺度的有价值的信息。MT-LSTM将标准LSTM模型的隐藏状态划分为几个组。每组被激活和更新在不同的时间周期。因此,MT-LSTM可以对非常长的文档进行建模。据报道,MT-LSTM在文本分类方面优于baseline。
rnn擅长捕捉词序列的局部结构,但很难记住长期依赖关系。相比之下,潜在主题模型能够捕获文档的全局语义结构,但不考虑单词排序(主题模型是以非监督学习的方式对文集的隐含语义结构进行聚类的统计模型)。Bieng等人提出了一种TopicRNN模型,综合了rnn和潜在主题模型的优点。它使用rnn捕获局部(语法)依赖关系,使用潜在主题捕获全局(语义)依赖关系。TopicRNN已被报道在情感分析方面优于RNN baseline。
其他
Recurrent neural network for text classification with multi-task learning.使用多任务学习来训练RNN,以利用来自多个相关任务的标记训练数据。
Supervised and semi-supervised text categorization using lstm for region embeddings.基于LSTM的文本区域嵌入方法。
Text classification improved by integrating bidirectional lstm with two-dimensional max pooling将双向LSTM模型与二维max pooling集成,以捕获文本特征。
Bilateral multi-perspective matching for natural language sentences“匹配聚合”框架下的双边多视角匹配模型。
A deep architecture for semantic matching with multiple positional sentence representations.使用双向LSMT模型生成的多个位置句子表示来探索语义匹配。
2.3 CNN-Based Models
rnn被训练来识别跨时间的模式,而cnn学习识别跨空间的模式。在需要理解远程语义的位置标记或QA等自然语言处理任务中,RNN可以很好地工作,而在检测局部和位置不变模式很重要的情况下,CNN可以很好地工作。
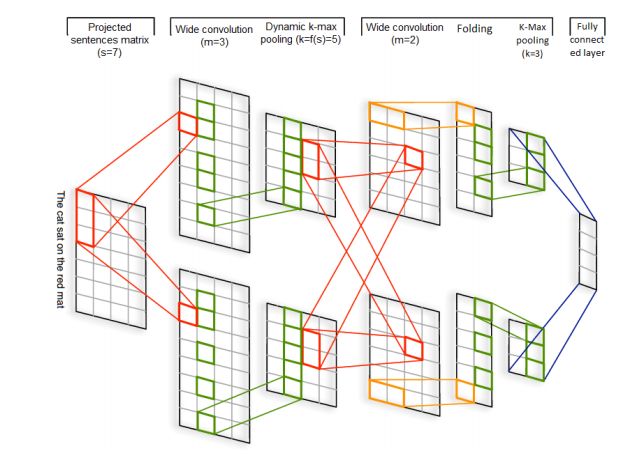
Kalchbrenner等人提出了最早的基于cnn的文本分类模型之一。这个模型使用动态k-max池化,称作动态CNN(DCNN)如图4所示,第一层DCNN通过对句子中的每个单词进行嵌入来构造一个句子矩阵。然后使用一个卷积架构,它交替使用宽卷积层和动态k-max池化给出的动态池化层,在句子上生成一个特征映射,能够明确地捕捉单词和短语的短期和长期关系。池参数k可以动态地选择,取决于句子水平的大小和卷积的层次结构。
后来,Kim提出了一种比DCNN更简单的基于cnn的文本分类模型。Kim的模型在word2vec获得的词向量上只使用了一层卷积。Kim还比较了四种不同的单词嵌入学习方法:(1)CNN-rand,在训练过程中,所有单词嵌入均被随机初始化,然后进行修改; (2)CNN静态的,在模型训练期间使用预训练的word2vec嵌入并保持固定; (3)CNN非静态的,其中word2vec嵌入在训练每个任务时进行微调; (4)CNN多通道,其中使用了两组词嵌入向量集,都使用word2vec进行了初始化,其中一个在模型训练期间进行了更新,而另一个则在固定的情况下进行了更新。
Liu等人对Kim-CNN的架构进行了两次修改.首先,采用动态最大池化方案以从文档的不同区域捕获更细粒度的特征。 其次,在pooling和输出层之间插入一个隐藏的瓶颈层,以学习紧凑的文档表示形式,减小模型大小并提高模型性能。
字符级cnn也被用于文本分类。第一个这样的模型是由Zhang等人提出的,该模型将固定大小的字符作为输入,编码为one-hot向量,通过一个深度CNN模型,该模型由六个卷积层和三个全连接的层组成,并进行池化操作。
受到VGG和ResNets的启发,Conneau等人提出了一种Very Deep CNN(VDCNN)模型用于文本处理。它直接在字符级别上运行,并且仅使用小的卷积和池化操作。这项研究表明,VDCNN的性能随深度而增加。Le等表明,当文本输入表示为字符序列时,深层模型的确优于浅层模型。但是,一个简单的浅层和广域网的性能优于带有单词输入的深层模型。Guo等研究了词嵌入的影响,并提出通过多通道CNN模型使用加权词嵌入。Zhang等研究了不同词嵌入方法和池化机制的影响,发现使用非静态word2vec和GloVe优于one-hot向量,并且最大池化始终优于其他池化方法。
还有其他基于cnn的有趣模型。
Natural language inference by tree-based convolution and heuristic matching.一种基于树的CNN来捕捉句子级语义。
Text matching as image recognition.将文本匹配作为图像识别任务,使用多层cnn识别显著的n-gram模式。
Combining knowledge with deep convolutional neural networks for short text classification.提出了一种基于cnn的模型,结合短文本的显式和隐式表示进行分类。
2.4 Capsule Neural Networks
cnn通过使用连续层的卷积和池化对图像或文本进行分类。尽管池化操作识别了显著特征并降低了卷积操作的计算复杂度,但它们丢失了关于空间关系的信息,并可能根据实体的方向或比例对其进行错误分类。为了解决池化问题,Geoffrey Hinton提出了一种新方法,称为胶囊网络。 Capsule是一组神经元,其活动矢量代表特定类型的实体的不同属性,向量的长度代表实体存在的可能性,向量的方向代表实体的属性。与CNN的最大池化(选择一些信息并丢弃其余信息)不同,胶囊使用网络中直到最后一层的所有可用信息,将底层的每个胶囊“路由”到上层的最佳父胶囊,用于分类。
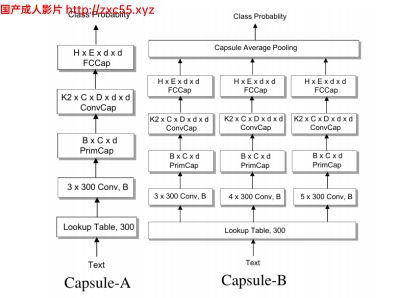
近来,胶囊网络已经被应用于文本分类,其中胶囊适于将句子或文档表示为向量。 W. Zhao等提出了一种基于CapsNets变体的文本分类模型。 该模型由四层组成:(1)n-gram卷积层,(2)胶囊层,(3)卷积胶囊层,以及(4)完全连接的胶囊层。 作者尝试了三种策略来稳定动态路由过程,以减轻包含背景信息(例如停用词或与任何文档类别无关的词)的噪声的干扰。 他们还探索了两种胶囊架构,如图所示。分别为Capsule-A和Capsule-B。 Capsule-B使用三个并行网络,并在n-gram卷积层中使用具有不同窗口大小的过滤器,以学习更全面的文本表示形式。 CapsNet-B在实验中表现更好。
2.5 Models with Attention Mechanism
注意力是由我们如何在视觉上注意图像的不同区域或在一个句子中关联单词来激发的。语言模型中的注意力可以被解释为一个重要权重的向量。为了预测句子中的一个单词,我们使用注意向量来估计它与其他单词的关联度,或者说是“注意到”,然后用注意向量加权它们的值的总和作为目标的近近值。
Z.Yang提出了一种用于文本分类的分层注意网络。该模型有两个显著的特点:(1)反映文档层次结构的层次结构;(2)在单词和句子层次上应用两个层次的注意机制,使其能够在构建文档表示时区别地关注更多和更少的重要内容。该模型在六个文本分类任务上比以前的方法有很大的优势。Zhou等将层次注意模型扩展到跨语言情感分类。在每种语言中,都使用LSTM网络对文档建模。然后,利用层次注意机制进行分类,句子级注意模型学习文档中哪些句子对判断整体情感更重要,而词级注意模式则学习每个句子中哪些词是决定性的。
Shen等提出了一种定向的自我注意网络,用于无RNN/CNN的语言理解,其中输入序列中元素之间的注意力是定向的和多维的。轻量级神经网络仅基于所提出的注意事项而无需任何RNN/CNN结构即可用于学习句子嵌入。 Liu等提出了一个带有NLI内在注意的LSTM模型。该模型使用两阶段过程对句子进行编码。首先,在词级Bi-LSTM上使用平均池化以生成第一阶段句子表示。其次,采用注意力机制来代替同一句子的平均池化,以获得更好的表示。
注意模型也广泛应用于成对排序或匹配任务。 Santos等提出了一种双向注意机制,称为注意力集中(AP),用于成对排名。 AP使合并层能够了解当前的输入对,以使来自两个输入项的信息可以直接影响彼此表示的计算。除了学习输入对的表示之外,AP联合学习该对投影段上的相似性度量,然后为每个输入导出相应的注意力向量以指导合并。 AP是独立于底层表示学习的通用框架,并且可以应用于CNN和RNN,如图8(a)所示。 Wang等将文本分类视为标签-单词匹配问题,作者介绍了一种注意力框架,该框架通过余弦相似性来度量文本序列和标签之间嵌入的兼容性,如图8(b)所示。
Semantic sentence matching with densely-connected recurrent and co-attentive information.提出了一种使用紧密连接的递归和共同注意网络的语义句子匹配方法。与DenseNet相似,该模型的每一层都使用所有先前的递归层的注意特征以及隐藏特征的级联信息。它可以保留从最底层单词嵌入层到最上层循环层的原始和共同关注特征信息。
Abcnn: Attention-based convolutional neural network for modeling sentence pairs.提出了另一种基于注意力的句子对匹配的CNN模型。他们研究了三种注意方案,以将句子之间的相互影响整合到CNN中,以便每个句子的表示都考虑其成对句子。这些相互依赖的句子对表示形式比孤立的句子表示形式更强大,这在包括答案选择,复述识别和文本蕴涵在内的多个分类任务中得到了验证。
Multiway attention networks for modeling sentence pairs.在匹配聚合框架下采用了多种注意功能来匹配句子对。
anmm: Ranking short answer texts with attention-based neural matching mode.介绍了一种基于注意力的神经匹配模型,用于对简短答案文本进行排名。他们采用价值共享加权方案代替位置共享加权方案来组合不同的匹配信号,并使用问题注意网络将问题术语重要性学习纳入其中。
A structured self-attentive sentence embedding.利用自我注意提取可解释的句子嵌入。
Densely connected cnn with multi-scale feature attention for text classification.提出了一种具有多尺度特征注意力的密集连接CNN,以产生可变的n-gram特征。
Neural attentive bag-of-entities model for text classification.使用关注神经的实体袋模型来使用知识库中的实体进行文本分类。
A decomposable attention model for natural language inference.利用注意力将问题分解为可以单独解决的子问题。
Enhancing sentence embedding with generalized pooling.探讨了增强句子嵌入的广义池化方法,并提出一种基于向量的多头注意力模型。
2.6 Memory-Augmented Networks
在编码过程中,注意力模型存储的隐藏向量可以被视为模型内部记忆的条目,而记忆增强网络将神经网络与一种外部记忆形式结合起来,模型可以从外部记忆中读取和写入。
Munkhdalai和Yu提出了一种记忆增强的神经网络,称为神经语义编码器(NSE),用于文本分类和QA。NSE配备了一个可变大小的编码存储器,随着时间的推移而演化,并通过读、写和写操作来保持对输入序列的理解。
Weston等人为综合QA任务设计了一个端到端的记忆网络,其中一系列语句(记忆条目)被提供给模型作为问题的支持事实。这个模型学习每次从记忆中检索一个条目。Sukhbaatar等人扩展了这项工作,提出了端到端记忆网络,其中记忆条目通过注意机制以一种软方式检索,从而实现了端到端训练。他们表明,通过多次测试,该模型能够检索和推理几个支持事实来回答一个特定的问题。
A. Kumar提出了一种动态记忆方法(DMN),它处理输入序列和问题,形成情景记忆,并生成相关答案。问题触发一个迭代注意过程,它允许模型将其注意条件设置为前一次迭代的输入和结果。然后,这些结果在层次递归序列模型中进行推理以生成答案。DMN是端到端训练,并获得最新的QA和POS标记结果。C. Xiong对DMN进行了详细的分析,改进了DMN的存储和输入模块。
2.7 Transformers
RNNs所面临的计算瓶颈之一是文本的顺序处理。尽管CNNs比RNNs的序列性要小,但是获取句子中单词之间关系的计算成本也随着句子长度的增加而增加,这与RNNs类似。Transformer克服了这一限制,将自我注意应用于并行计算句子中的每个单词,或记录“注意分数”,以模拟每个单词对另一个单词的影响。由于这个特性,Transformer允许比CNNs和RNNs更多的并行化,这使得在GPU集群上有效地训练大量数据的非常大的模型成为可能。
自2018年以来,我们已经看到了一系列大规模基于transformer的Pre-trained Language Models(PLM)的兴起。与基于CNN或LSTM的早期上下文嵌入模型相比,基于Transformer的PLM使用更深的网络架构,并且在大量文本上进行了预训练。这些PLM已使用特定于任务的标签进行了微调,并在许多下游NLP任务(包括文本分类)中创建了新的最新技术。尽管预训练是无监督的,但微调是有监督的学习。
PLM可以分为两类,即自回归预训练语言模型和自编码语言模型。最早的自动回归PLM之一是OpenGPT,它是一种单向模型,可以从左到右(或从右到左)逐个单词地预测文本序列,每个单词的预测取决于先前的预测。它由12个的Transformer块组成,每个层包括一个masked的多头注意模块,然后是一个层归一化和一个位置向前馈层。通过添加特定于任务的线性分类器并使用特定于任务的标签进行微调,OpenGPT可以适应下游任务,例如文本分类。
最广泛使用的自动编码预训练语言模型之一是BERT。与OpenGPT基于先前的单词预测不同,BERT使用masked语言建模任务进行训练,该任务随机屏蔽文本序列中的一些标记,然后通过对双向Transformer获得的编码向量进行调节,独立地恢复屏蔽标记。关于改进BERT的工作有很多。RoBERTa比BERT更健壮,并且使用更多的训练数据进行训练。ALBERT降低了记忆消耗,提高了BERT的训练速。 DistillBERT在预训练期间利用知识蒸馏将BERT的大小减少40%,同时保留其99%的原始能力,并使推理速度加快60%。SpanBERT扩展了BERT以更好地表示和预测文本跨度。
如前所述,OpenGPT使用从左到右的Transformer来学习文本表示以生成自然语言,而BERT使用双向Transformer来理解自然语言。有人试图将自回归和自编码预训练语言模型的优点结合起来。XLNet集成了OpenGPT等自回归模型和BERT的双向上下文建模思想。XLNet在预训练期间使用了一个置换操作,允许上下文同时包含来自左和右的token,使其成为一个广义的顺序感知自回归语言模型。这种排列是通过在Transformer中使用一个特殊的注意mask来实现的。XLNet还引入了一个双流自注意力模式,允许位置感知的单词预测。这是由于观察到单词分布因单词位置的不同而变化很大。例如,句子的开头与句子中其他位置的分布有很大的不同。
统一语言模型(UniLM)旨在解决自然语言理解和生成任务。 UniLM已使用三种类型的语言建模任务进行了预训练:单向,双向和序列到序列的预测。通过使用共享的Transformer网络并利用特定的self-attention mask来控制预测条件所处的环境,可以实现统一建模。据报道,UniLM的第二版性能大大优于以前的PLM,包括OpenGPT-2,XLNet,BERT及其变体。
Raffel等提出了一个统一的基于Transformer的框架,该框架将许多NLP问题转换为文本到文本格式。他们还进行了系统的研究,比较了数十种语言理解任务的预训练目标,体系结构,未标记的数据集,微调方法和其他因素。
2.8 Graph Neural Networks
尽管自然语言文本具有顺序性,但它们也包含内部的图形结构,如句法和语义分析树,它们定义了句子中单词之间的句法/语义关系。
为NLP开发的最早的基于图的模型之一是TextRank。作者提出将自然语言文本表示为图形(V,E),其中V表示一组节点,E表示节点之间的一组边。根据手头的应用,节点可以表示各种类型的文本单位,例如单词、搭配、整句话等。同样,边缘可以表示任何节点之间的不同类型的关系,例如词汇或语义关系、上下文重叠等。例如,用于图像处理CNN的2D卷积被普遍化为通过获取节点邻域信息的加权平均值来执行图卷积。 在各种类的GNN中,卷积GNN(例如图卷积网络(GCN)及其变体)是最受欢迎的,因为它们可以有效,方便地与其他神经网络组合。
GNNs在自然语言处理中的典型应用是文本分类。gnn利用文档或单词之间的相互关系来推断文档标签。H. Peng提出了一种基于图CNN的深度学习模型,首先将文本转换为词图,然后使用图卷积运算对词图进行卷积。实验表明,文本的词表示图具有捕获非连续语义和远距离语义的优势,CNN模型具有学习不同层次语义的优势。
H. Peng提出了一种基于层次分类感知和注意图的胶囊CNN文本分类模型。该模型的一个独特之处是使用了类标签之间的层次关系,在以前的方法中,这些关系被认为是独立的。具体来说,为了利用这种关系,作者开发了一种层次分类嵌入方法来学习它们的表示,并通过结合标签表示相似度定义了一种新的加权边缘损失。L. Yao基于单词共现和文档单词关系为语料库构建了一个单一的文本图,然后为该语料库学习了一个文本图卷积网络(Text GCN),然后在已知文档类标签的监督下,共同学习word和document的嵌入。
为大型文本语料库构建GNN的成本很高。 已经通过降低模型复杂度或改变模型训练策略来降低建模成本。 前者的一个例子是提出的简单图卷积(SGC)模型,其中深层卷积GNN通过重复删除连续层之间的非线性并将结果函数(权重矩阵)折叠为单个线性来简化。 后者的一个示例是 text-level GNN,不会为整个文本语料库构建图,而是为文本语料库上的滑动窗口定义的每个文本块生成一个图,从而减少训练期间的内存消耗。 相同的想法激发了GraphSage的发展,它是卷积GNN的批处理训练算法。
2.9 Siamese Neural Networks
Siamese neural networks(S2Nets)及其DNN变体(称为深度结构语义模型(DSSM))设计用于文本匹配。该任务是许多NLP应用程序的基础,例如查询文档排名和QA中的答案选择。 这些任务可以看作是文本分类的特殊情况。 例如,在问题文档排名中,我们希望将文档分类为与给定查询相关或不相关。
DSSM(或S2Net)由一对DNNs、f1和f2组成,它们将输入x和y映射到公共低维语义空间中的对应向量中。然后用两个向量的余弦距离来度量x和y的相似性。虽然s2net假设f1和f2共享相同的体系结构甚至相同的参数,但是在DSSMs中,f1和f2可以根据x和y的不同而具有不同的体系结构。例如,要计算图像-文本对的相似性,f1可以是深度CNN和f2是RNN或MLP。根据(x,y)的定义,这些模型可以应用于各种NLP任务。 例如,(x,y)可以是用于查询文档排名的查询文档对,也可以是QA中的问题-答案对,依此类推。 通常使用成对的秩损失来优化模型参数.
Learning Text Similarity with Siamese Recurrent Networks提出了一个相似的模型,该模型对f1和f2使用字符级Bi-LSTMs,并使用余弦函数计算相似性。
除RNNs外,s2net中还使用BOW模型和CNNs来表示句子。
Multi-perspective sentence similarity modeling with convolutional neural networks.提出了一种利用CNNs对多视角句子相似度进行建模的S2Net。
Siamese CBOW: Optimizing word embeddings for sentence representations.提出了一个连体CBOW模型,该模型通过平均句子的词嵌入来形成句子向量表示,并将句子相似度计算为句子向量之间的余弦相似度。
随着BERT成为新的最先进的句子嵌入模型,有人试图构建基于BERT的s2net,如SBERT和TwinBERT。
S2Nets和DSSM已被广泛用于质量检查。Together we stand: Siamese networks for similar question retrieval.提出了一个用于QA的Siamese CNN(SCQA),用于测量问题及其(候选)答案之间的语义相似性。 为了降低计算复杂度,SCQA使用问题-答案对的字符级表示形式。 训练SCQA的参数可以最大程度地提高问题及其相关答案之间的语义相似性。Improved representation learning for question answer matching.提出了一系列用于选择答案的 Siamese神经网络。它们是使用卷积,递归和注意神经网络处理文本的混合模型。
2.10 Hybrid Models
许多混合模型已经被开发出来,将LSTM和CNN架构结合起来,以捕获句子和文档的局部和全局特征。
Zhu等提出了一种卷积LSTM (C-LSTM)网络。C-LSTM利用一个CNN提取一组高层短语(n-gram)表示,将其输入LSTM网络获得句子表示。同样,Zhang等提出了一种用于文档建模的依赖敏感CNN (DSCNN)。DSCNN是一个层次模型,LSTM学习句子向量,这些句子向量被馈给卷积层和最大池化层,以生成文档表示。
Ensemble application of convolutional and recurrent neural networks for multi-label text categorization.通过CNN-RNN模型执行多标签文本分类,该模型能够捕获全局和局部文本语义,因此,在具有可处理的计算复杂性的同时,能够建模高阶标签相关性。
Document modeling with gated recurrent neural network for sentiment classification.使用CNN学习句子表示,使用门控RNN学习编码句子之间内在关系的文档表示。
Efficient character-level document classification by combining convolution and recurrent layers.将文档视为字符序列,而不是单词,并建议使用基于字符的卷积和递归层进行文档编码。与字级模型相比,该模型在参数较少的情况下取得了可比的性能。
Recurrent convolutional neural networks for text classification.应用了一种循环结构来捕获用于学习单词表示的远程上下文依赖。 为了减少噪音,采用了最大合并来自动选择仅对文本分类任务至关重要的显着单词。
Improving sentiment analysis via sentence type classification using bilstm-crf and cnn.观察到不同类型的句子表达情感的方式非常不同,提出了一种分治法通过句子类型分类进行情感分析。作者首先应用双lstm模型将有意见的句子分为三种类型。然后将每组句子分别输入一维CNN进行情感分类。
Hdltex: Hierarchical deep learning for text classification.提出了一种用于文本分类的分层深度学习方法(HDLTex)。HDLTex采用混合深度学习模型体系结构,包括MLP、RNN和CNN,在文档层次结构的每一层提供专门的理解。
Stochastic answer networks for machine reading comprehension.提出了一种用于机器阅读理解中的多步推理的鲁棒随机回答网络(SAN)。SAN结合了不同类型的神经网络,包括记忆网络、变换网络、双lstm、注意力和CNN。Bi-LSTM组件获取问题和段落的上下文表示。它的注意机制衍生出一个问题意识的段落表征。然后,另一个LSTM被用来为文章生成工作记忆。最后,一个基于门控循环单元(GRU)的回答模块输出预测。
一些研究致力于将 highway networks与RNN和CNN结合起来。随着深度的增加,DNN的基于梯度的训练变得更加困难。highway networks旨在减轻非常深的神经网络的训练。它们允许highway networks上的几层畅通无阻的信息流,类似于ResNet中的快捷连接。
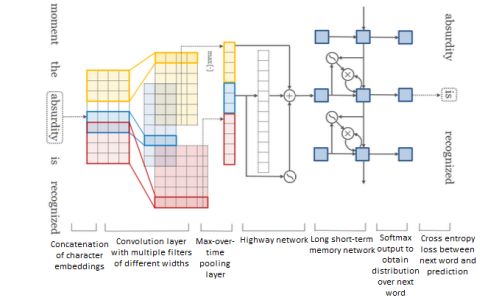
Kim等在字符上采用了带有字符的CNN和LSTM的highway networks。第一层执行字符嵌入的查找,然后进行卷积和最大池操作以获取单词的固定尺寸表示形式,并将其提供给 highway networks。 highway networks的输出用作多层LSTM的输入。最后,将仿射变换后跟一个softmax应用于LSTM的隐藏表示,以获取下一个单词的分布。其他基于 highway networks的混合模型包括循环 highway networks和带 highway networks的RNN。
2.11 Beyond Supervised Learning
Unsupervised Learning using Autoencoders使用自动编码器的无监督学习
与单词嵌入相似,句子的分布式表示也可以无监督的方式学习。 通过优化一些辅助目标,例如自动编码器的重构损失。 这种无监督学习的结果是句子编码器,它可以将具有相似语义和句法属性的句子映射到相似的固定大小矢量表示形式。 第2.7节中描述的基于transformer的PLM也是不受监督的模型,可以用作句子编码器。 本节讨论基于自动编码器及其变体的无监督模型。
Kiros提出了一种无监督学习通用句子编码器的跳跃思维模型。训练编码器-解码器模型来重建编码句子的周围句子。A.M.Dai and Q.V.Le研究了序列自动编码器在句子编码中的应用,该编码器将输入序列读入向量并再次预测输入。他们表明,在一个大的无监督语料库上进行预训练的句子编码比只进行预训练的单词嵌入产生更好的准确性。M. Zhang提出了一种平均最大注意自动编码器,该编码器利用多头自注意机制重构输入序列。在编码中使用mean-max策略,在编码过程中,对隐藏向量应用mean和max池操作来捕获输入的不同信息。
当自动编码器学习输入的压缩表示时,变分自动编码器(VAE)学习表示数据的分布,可以将其视为自动编码器的正则化版本。由于VAE学会了对数据进行建模,因此我们可以轻松地从分布中进行抽样,以生成新的输入数据样本(例如,新的句子)。Miao等将VAE框架扩展到文本,并提出了用于文档建模的神经变异文档模型(NVDM)和用于质量保证的神经答案选择模型(NASM)。NVDM使用MLP编码器将文档映射到连续的语义表示。NASM使用LSTM和潜在的随机注意机制对问题-答案对的语义建模,并预测它们的相关性。注意模型关注与问题语义紧密相关的答案短语,并通过潜在分布建模,从而使模型能够处理任务中固有的歧义。鲍曼等提出了一种基于RNN的VAE语言模型,此模型合并了整个句子的分布式潜在表示,从而可以显式地建模句子的整体属性,例如样式,主题和高级句法特征。
Adversarial Training对抗训练
对抗式训练是一种改进分类器泛化的正则化方法。它通过改进模型对对抗性例子的鲁棒性来实现这一点,而对抗性例子是通过对输入进行微小的扰动而产生的。对抗性训练需要使用标签,并应用于监督学习。虚拟对抗训练将对抗训练扩展到半监督学习。给定一个例子,该模型产生的输出分布与它在该例子的对抗性扰动下产生的输出分布相同。
Miyato等人将对抗式和虚拟对抗式训练扩展到监督和半监督文本分类任务,方法是对RNN中的词嵌入进行扰动,而不是对原始输入本身进行扰动。D. S. Sachan研究了用于半监督文本分类的LSTM模型。他们发现,对于有标签和无标签的数据,使用结合了交叉熵、对抗性和虚拟对抗性损失的混合目标函数,可以显著改善监督学习方法。P. Liu, X.将对抗训练扩展到文本分类的多任务学习框架,旨在减轻任务独立和任务依赖的潜在特征空间之间的相互干扰。
Reinforcement Learning强化学习
强化学习(Reinforcement learning, RL)是一种训练agent根据策略执行离散动作的方法,训练agent以实现奖励最大化。
Shen等人使用hard attention模型选择输入序列的关键字标记子集进行文本分类。hard attention模型可以被看作是一个agent,它采取行动决定是否选择一个token。遍历整个文本序列后,它会收到一个分类损失,可以作为训练agent的奖励。X. Liu提出了一种将文本分类建模为顺序决策过程的神经agent。受人类文本阅读认知过程的启发,智能体按顺序扫描一段文本,并在希望的时间做出分类决策。分类结果和何时进行分类都是决策过程的一部分,由经过RL训练的策略控制。Shen等人提出了多步算法机器阅读理解推理网络(ReasoNet)。ReasoNets通过多个步骤来推断查询、文档和答案之间的关系。与在推理过程中使用固定数量的步骤不同,ReasoNets引入了一个终止状态来放松对推理步骤的限制。使用RL, ReasoNets可以动态决定是在消化了中间结果后继续理解过程,还是在认为现有信息足够产生时终止阅读.Y. Li将RL、GANs和RNNs相结合,建立了一种新的类别句子生成对抗网络模型(CS-GAN),该模型能够生成扩展原始数据集的类别句子,并在有监督的训练中提高其泛化能力。T. Zhang提出了一种基于RL的文本分类学习结构化表示方法。他们提出了两个基于LSTM的模型。第一个选项只选择输入文本中与任务相关的重要单词。另一个发现句子的短语结构。使用这两个模型的结构发现被表示为由策略网络policy network引导的顺序决策过程,策略网络在每个步骤决定使用哪个模型,利用策略梯度优化策略网