Towards Real-Time Multi-Object Tracking
作者分别是来自清华大学和澳大利亚国立大学
Abstract
现代多目标跟踪(MOT)系统通常遵循基于检测的跟踪模式。它具有1)用于目标定位的检测模型,以及2)用于数据关联的外观嵌入模型。分别执行这两个模型可能会导致效率问题,因为运行时间只是这两个步骤的总和,而没有研究它们之间可以共享的潜在结构。现有的实时MOT研究多集中在关联步骤上,本质上属于实时关联方法,而非实时MOT系统。在本文中,我们提出了一个MOT系统,该系统允许在一个共享模型中学习目标检测和表观嵌入。具体来说,我们将外观嵌入模型合并到单镜头探测器中,这样模型就可以同时进行输出检测和相应的嵌入。因此,该系统被表述为一个多任务学习问题:有多个目标,即锚点分类、边界盒回归、嵌入学习;单个损失会自动计算。据我们所知,这项工作报告了第一个(接近)实时MOT系统,根据输入分辨率,其运行速度为18.8到24.1 FPS。与此同时,它的跟踪精度可与包含分离检测和嵌入(SDE)学习(64.4% MOTA v.s. 66.1% MOTA on MOT-16挑战赛)的最先进的跟踪器相媲美。
Introduction
多目标跟踪(MOT)旨在预测视频序列中多个目标的轨迹,它的关键应用意义从自动驾驶到智能视频分析。
解决这个问题的主要策略是:(米兰等,2016年;Yu et al. 2016;Choi(2015)将MOT分解为两个步骤:1)检测步骤,在检测步骤中,对单个视频帧中的目标进行定位;2)关联步骤,将检测到的目标分配并连接到现有的轨迹。这意味着该系统至少需要两个计算密集型组件:一个检测器和一个嵌入(re-ID)模型。为了方便起见,我们将这些方法称为分离检测和嵌入(SDE)方法。因此,总的推断时间大致是两个组件的总和,并将随着目标数量的增加而增加。SDE方法的特点给实时MOT系统的构建带来了严峻的挑战,这是实践中的必然要求。
为了节省计算量,一个可行的方法是将检测器和嵌入模型集成到一个网络中。因此,这两个任务可以共享相同的低层特性集,并且避免了重新计算。联合检测器和嵌入学习的一种选择是采用Faster R-CNN框架(Ren等人,2015),这是一种两阶段检测器。具体来说,第一阶段是区域提案网络(RPN),与Faster R-CNN保持相同,并输出检测到的边界框。 第二阶段,Fast R-CNN(Girshick 2015),可以通过用度量学习监督替代分类监督来转换为嵌入学习模型(Xiao等人2017; Voigtlaender等人2019)。尽管节省了一些计算量,但由于采用了两级设计,这种方法的速度仍然有限,通常运行速度低于10帧/秒(FPS),远远达不到实时要求。而且,第二阶段的运行时间也会随着目标数量的增加而增加,就像SDE方法一样。
本文主要研究如何提高MOT系统的效率。我们介绍了一种早期尝试,它可以在单一深度网络中共同学习检测器和嵌入模型(JDE)。也就是说,所提出的JDE使用单个网络来同时输出检测结果和检测到的box的相应外观嵌入。相比之下,SDE方法和两阶段方法分别由重新采样的像素(包围框)和特征映射来表征。边界框和特征映射都被输入到一个单独的re-ID模型中进行外观特征提取。图1简要说明了SDE方法、两阶段方法和建议的JDE之间的区别。图1简要说明了SDE方法、两阶段方法和建议的JDE之间的区别。我们的方法几乎是实时的,但几乎与SDE方法一样准确。 例如,我们在MOT-16测试仪上获得了18.8 FPS的运行时间,MOTA = 64.4%。 相比之下,在MOT-16测试仪上,Faster R-CNN + QAN嵌入仅以<6 FPS进行,MOTA = 66.1%。
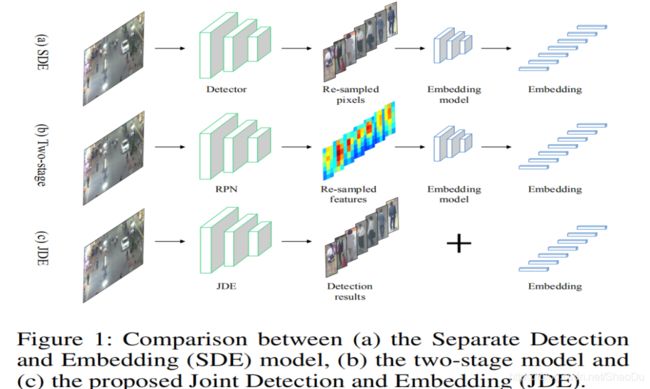
图1:(a)单独检测与嵌入(SDE)模型、(b)两阶段模型与©联合检测与嵌入(JDE)模型的比较
为了构建一个高效、准确的联合学习框架,我们探索并精心设计了以下几个基本方面:训练数据、网络架构、学习目标、优化策略和验证指标。首先,我们收集了六个公开的行人检测和人员搜索数据集,形成一个统一的大规模多标签数据集。在这个统一的数据集中,所有行人边界框都被标记,行人标识的一部分也被标记。其次,我们选择特征金字塔网络(FPN) (Lin et al. 2017)作为我们的基础架构,讨论网络学习哪种类型的损失函数是最好的嵌入。然后,我们将训练过程建模为一个包含锚分类、盒回归和嵌入学习的多任务学习问题。为了平衡每个单独任务的重要性,我们使用任务依赖的不确定性(Kendall、Gal和Cipolla 2018)来动态加权异构损失。最后,我们采用以下评估指标。 平均精度(AP)用于评估检测器的性能。 采用某种误报率(FAR)的取回率True接受率(TAR)来评估嵌入的质量。总体MOT准确性由CLEAR指标(Bernardin和Stiefelhagen 2008)评估,尤其是MOTA指标。 本文还为联合学习检测和嵌入任务提供了一系列新的设置和基线,我们认为这将有助于对实时MOT的研究。
我们的工作成果总结如下:
介绍了一种用于联合检测和嵌入学习的单镜头框架JDE。作为一个在线MOT系统,它运行(接近)实时,并与分离检测+嵌入(SDE)的最先进的方法相媲美的准确性。
我们从训练数据、网络架构、学习目标和优化策略等多个方面对如何构建这样一个联合学习框架进行了深入的分析和实验。
在相同训练数据下的实验结果表明,所提出的JDE算法具有较强的SDE模型组合能力,达到了最快的速度。
在MOT-16上的实验表明,考虑到训练数据量、准确性和速度,我们的方法优于最先进的MOT系统。
Related Work
近年来多目标跟踪的研究进展主要有以下几个方面:
1. 将关联问题建模为图上某种形式的优化问题(Wen et al. 2014;Zamir, Dehghan, and Shah 2012;Kim等人,2015)。
2. 努力用端到端神经网络对关联过程建模(Sun et al. 2019;(Zhu et al. 2018)
3.除了通过检测跟踪之外,它还寻求新的跟踪范式(Bergmann、Meinhardt和LealTaixe 2019)。
其中,前两类是过去十年中最普遍的MOT解决方案。在这些检测跟踪方法中,检测结果和外观嵌入作为输入,唯一需要解决的问题是数据关联。虽然有一些方法宣称能够达到实时速度,但是排除了检测器的运行时间和外观特征提取,使得整个系统距离宣称还有一定的距离。相反,在本文中,我们考虑的是整个MOT系统的运行时间,而不仅仅是关联步骤。实现整个系统的效率更具有实际意义。
第三类尝试探索新颖的MOT范例,例如,通过预测空间偏移量(Bergmann、Meinhardt和Leal-Taixe 2019)将单个目标跟踪器合并到检测器中。这些方法因其简单而吸引人,但除非引入额外的嵌入模型,否则跟踪精度不能令人满意。因此,性能和速度之间的平衡仍然需要改进。
我们的方法还与人员搜索任务有关,该任务旨在从大量数据库框架中定位和识别查询人员。 该任务的一些解决方案是共同学习人体检测器和嵌入模型(Xiao等人2017)。 尽管如此,MOT和人员搜索系统之间的主要区别在于MOT对运行时的要求更加严格,因此不能直接借用人员搜索方法。
另一条相关的工作线是用于人体姿态估计的联想嵌入(Newell, Huang, and Deng 2017)和检测(Law and Deng 2018)。一个低维的密集矢量地图命名为联想嵌入学会了分组人的关节或方框角落。然而,关联只适用于单个图像,而在MOT中,需要跨帧关联,这就要求嵌入更有鉴别性。
Joint Learning of Detection and Embedding Problem Settings(检测和嵌入问题设置的联合学习)
JDE的目标是在一次向前传递中同时输出目标的位置和外观嵌入。形式上,假设我们有一个训练数据集{I, B, y}Ni=1。其中I∈Rc×h×w表示一个图像帧,B∈Rk×4表示该帧中k个目标的边界框标注。y∈Zk表示部分注释的标识标签,其中-1表示没有标识标签的目标。JDE旨在输出预测的边界框Bˆ∈Rkˆ×4 和外观嵌入Fˆ∈Rkˆ×D, D是嵌入的维数。应满足下列目标。
B ∗尽可能接近B。
…
第一个目标要求模型准确地检测目标。第二个目标要求外观嵌入具有以下特性。同一恒等式在连续帧中的观测距离应小于不同恒等式之间的距离。距离度量d(·)可以是欧氏距离,也可以是余弦距离。从技术上讲,如果两个目标都满足,即使是一个简单的关联策略,例如匈牙利算法,也会产生良好的跟踪结果。
Architecture Overview(结构概述)
我们采用了特征金字塔网络(FPN)的架构(Lin et al. 2017)。FPN从多个尺度进行预测,从而在目标尺度变化较大的情况下改善行人检测。图2简要地显示了JDE中使用的神经体系结构。输入视频帧首先通过主干网络进行前向遍历,得到三个尺度的特征图,分别为1/32、1 /16和1/8的下采样率。然后,对最小尺度的特征图(也就是语义上最强的特征)进行向上采样,并通过跳跃连接与第二小尺度的特征图融合,其他尺度也是如此。最后,在三种尺度的融合特征图上添加预测头。一个预测头由多个堆叠的卷积层组成,输出一个大小为6A + D×H×W的稠密预测图,其中A为分配给该尺度的锚模板数量,D为嵌入的维数。
稠密预测图分为三个部分(任务):
1) size为2A×H×W的box分类结果;
2)大小为4A×H×W的box回归系数;
3)尺寸为D×H×W的密集地图。
在下面的部分中,我们将详细介绍如何训练这些任务。
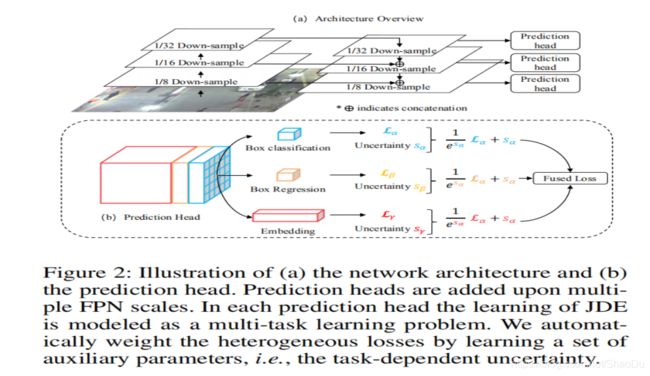
图2:(a)网络体系结构和(b)预测头的示意图。 在多个FPN刻度上添加了预测头。 在每个预测头中,JDE的学习都被建模为多任务学习问题。 我们通过学习一组辅助参数(即与任务有关的不确定性)来自动加权异构损失。
Learning to Detect(学习检测)
一般来说,检测分支类似于标准RPN (Ren等人,2015),但有两个修改。首先,我们根据数字、比例和长宽比重新设计锚点,以适应目标,即在我们这里是行人。基于共同先验,所有锚点的高宽比设置为1:3。锚模板数量设置为12个,每个尺度A = 4,锚的尺度(宽度)范围为11≈8×21/2到512 = 8×2 12/2。其次,我们注意到为用于前景/背景分配的双阈值选择合适的值是很重要的。通过可视化,我们确定IOU>0.5 w.r.t的ground truth近似地保证了前景,这与通用对象检测中的常见设置是一致的。另一方面,那些IOU<0.4 w.r.t的盒子在我们的案例中应该作为背景,而不是一般情况下使用的0.3。我们的初步实验表明,这些阈值可以有效地抑制假警报,而假警报通常发生在严重闭塞的情况下。
检测的学习目标具有两个损失函数,即前景/背景分类损失Lα和边界框回归损失Lβ。 Lα被公式化为交叉熵损失,Lβ被公式化为平滑L1损失。回归目标的编码方式与(Ren et al.2015)相同。
Learning Appearance Embeddings(学习嵌入的外观)
第二个目标是一个度量学习问题,即学习一个嵌入空间,其中相同身份的实例彼此接近,而不同身份的实例相距很远。为了实现这一目标,有效的解决方案是使用三重态损耗(Schroff,Kalenichenko和Philbin 2015)。在以前的MOT工作中也使用了三重态损失(Voigtlaender等人2019)。一般,我们使用三联体损失:…。为了方便起见,忽略了边距项。三连体损耗的天真公式有几个挑战。第一个是训练集的巨大采样空间。在这项工作中,我们通过查看一个小批处理来解决这个问题,并挖掘所有的负样本和最困难的正样本,这样,
 …
…
第二个挑战是三重态损失的训练可能是不稳定的,收敛可能是缓慢的。为了稳定训练过程,加快收敛速度,(Sohn 2016)提出了对三重态损耗的平滑上界进行优化,
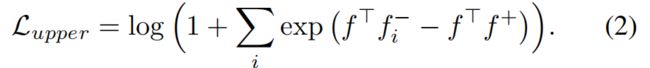
注意,三重态损耗的光滑上界也可以写成,
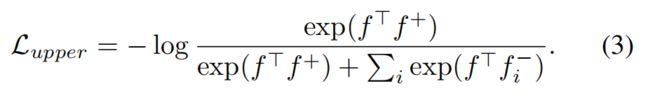
它类似于交叉熵损失的公式,

其中,我们将正类别(锚实例所属的类别)的类权重表示为g +,将负类的权重表示为gi-。Lupper和LCE之间的主要区别是双重的。 首先,交叉熵损失采用可学习的逐级权重作为立场类的代理,而不是直接使用实例的嵌入。其次,所有的负类都参与了LCE中的损失计算,从而将锚实例从嵌入空间中的所有负类中拉出。相反,在Lupper中,锚实例只从抽样的负实例中拖出。
根据以上分析,我们推测我们的情况下三种损耗的表现应该是LCE > Lupper > Ltriplet。实验部分的实验结果证实了这一点。因此,我们选择熵损失为目标嵌入学习(以下简称Lγ)。
具体来说,如果将锚框标记为前景,则从密集的嵌入映射中提取相应的嵌入向量。将提取出的嵌入项输入共享的全连通层中,输出类间的对数,然后对对数应用交叉熵损失。通过这种方式,来自多个尺度的嵌入共享相同的空间,并且多尺度的关联是可行的。计算嵌入损失时,将忽略带有标签l1的嵌入,即带有框注释但没有标识注释的前景。
Automatic Loss Balancing(自动损失平衡)
JDE中每个预测头的学习目标可以建模为多任务学习问题。 联合目标可以写成每个标尺和每个组成部分的加权加权线性损失总和,

其中M是预测头的数量,wij,i = 1,…,M,j =α,β,γ是损失权重。 确定损失权重的简单方法如下所述。
1)让wiα= wiβ,建议在现有对象检测工作(任et al . 2015年)
2)…
3)寻找剩下的两个独立的损失权重以获得最佳性能。
使用这种策略搜索损失权重可以在几次尝试中产生良好的结果。然而,搜索空间的减少也对损失权值带来了很大的限制,从而导致损失权值可能远远不是最优的。相反,我们采用(Kendall, Gal,和Cipolla 2018)中提出的利用任务独立不确定性的概念来自动学习损失权重的方案。形式上,具有自动损失平衡的学习目标为:
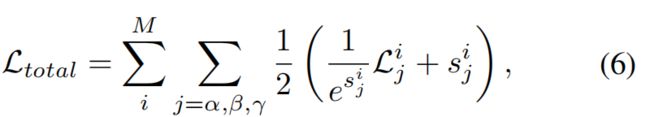
其中sij是每个个体损失的任务相关的不确定性,并被建模为可学习的参数。我们建议读者参考(Kendall、Gal和Cipolla 2018)以获得更详细的推导和讨论。
Online Association(线性组合)
虽然关联算法不是本文的重点,但在这里我们介绍一种简单而快速的在线关联策略来与JDE协同工作。
对于给定的视频,JDE模型处理每一帧并输出包围框和相应的外观嵌入。因此,我们计算了观察值的嵌入和先前已有的轨迹池的嵌入之间的亲和矩阵。使用匈牙利算法将观测值分配给小径。卡尔曼滤波器用于平滑轨迹并预测当前帧中先前轨迹的位置。如果所分配的观测值在空间上与预测位置相距太远,则该分配将被拒绝。 然后,对Tracklet的嵌入进行如下更新,
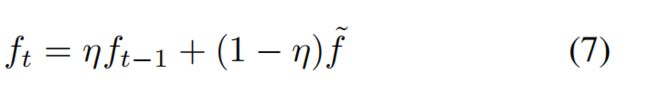
其中〜f表示所分配观察值的嵌入,而ft表示在时间t处的小轨迹的嵌入。 η是用于平滑的动量项,我们将η= 0.9。 如果没有任何观察值分配给Tracklet,则将该Tracklet标记为丢失。如果丢失时间大于给定阈值,则标记为已丢失的跟踪将从当前跟踪池中删除,或者在分配步骤中重新找到。
Experiments
数据集和评估指标
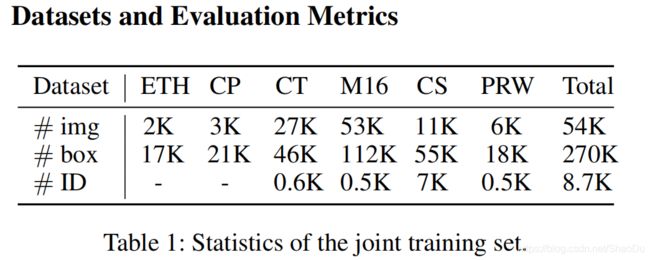
表1:联合训练集统计
在小型数据集上执行实验可能会导致偏差的结果,而将相同算法应用于大规模数据集时,结论可能不成立。因此,我们构建了一个大规模的训练集,将行人检测、MOT和人员搜索6个公共数据集放在一起。这些数据集可以分为两种类型:仅包含边界框注释的数据集,以及同时具有边界框和身份注释的数据集。第一类包括ETH数据集(Ess et al。2008)和CityPersons(CP)数据集(Zhang,Benenson和Schiele 2017)。 第二类包括CalTech(CT)数据集(Dollar等人2009),MOT-16(M16)数据集(Milan´等人2016),CUHK-SYSU(CS)数据集(Xiao等人2017)和PRW 数据集(Zheng et al.2017)。收集所有这些数据集的训练子集以形成联合训练集,并排除ETH数据集中与MOT-16测试集重叠的视频以进行公平评估。 表1显示了联合训练集的统计数据。
为了进行验证/评估,需要评估性能的三个方面:检测准确性,嵌入的判别能力以及整个MOT系统的跟踪性能。为了评估检测的准确性,我们在Caltech验证集上以0.5的IOU阈值计算平均精度(AP)。为了评估外观嵌入,我们在Caltech数据集、CUHK-SYSU数据集和PRW数据集的验证集上提取所有地面真值框的嵌入,在这些实例中应用1:N检索,并以错误接受率0.1报告真实的正确率(TPR@FAR=0.1)。为了评估整个MOT系统的跟踪精度,我们采用CLEAR度量(Bernardin和Stiefelhagen 2008),特别是最适合人类感知的MOTA度量。在验证中,我们使用带有重复序列的MOT-15训练集,并删除训练集。在测试期间,我们使用MOT-16测试集与现有方法进行比较。
Implementation Details(实现细节)
我们使用DarkNet-53 (Redmon和Farhadi 2018)作为JDE的骨干网络。该网络经过30个epoch的标准SGD训练。初始化学习速率为10×2,在第15个epoch和第23个epoch降低0.1。几种数据增强技术(例如随机旋转,随机缩放和颜色抖动)可用于减少过度拟合。最后,将增强图像调整为固定分辨率。 如果未指定,则输入分辨率为1088×608。
实验结果
外观嵌入学习的三种损失函数的比较。我们首先比较了外观嵌入训练的判别能力与交叉损耗,三重损耗及其上界的变化,在前一节描述。对于使用Ltriplet和Lupper训练的模型,对B / 2对时间连续帧进行采样以形成大小为B的小批量。这确保了始终存在正样本。对于使用LCE训练的模型,此采样策略不是必需的,并且可以对图像进行随机采样以形成小批量。 表2列出了三种损失函数的比较。

表2:比较不同的嵌入损失和损失加权策略。 TPR是嵌入验证集上TPR@FAR=0.1的缩写,并且ID表示跟踪验证集上ID切换的时间。 ↓表示越小越好; ↑表示越大越好。 在每一列中,最好的结果以粗体显示,次优的结果以下划线显示。
不出所料,LCE优于Ltriplet和Lupper。 令人惊讶的是,性能差距很大(+ 46.0 / + 43.9 TAR@FAR=0.1)。性能差距较大的可能原因是,交叉熵损失要求一个实例与其正类别之间的相似度高于此实例与所有负类别之间的相似度。这一目标比仅在取样的小批中施加约束的三重损失族更严格。考虑到其有效性和简单性,我们使用交叉熵损失来嵌入学习。
不同损失加权策略的比较 损失加权策略对于学习JDE的良好联合表示至关重要。本文采用了三种损失加权策略。 第一种是损失归一化方法(称为“损失范数”),其中,损失以其移动平均幅度的倒数加权。第二个是(Sener and Koltun 2018)中提出的“ MGDA-UB”算法,最后一个是上一节中介绍的权重不确定性策略。此外,我们有两个基准。 第一种训练所有具有相同损失权重的任务,称为“统一”。第二种方法称为“ App.Opt”,通过在上一节所述的两个独立变量假设下进行搜索,使用了一组近似的最佳损失权重。表2总结了这些策略的比较。这里有两个观察结果。
首先,统一基线产生较差的检测结果,因此跟踪精度不好。 这是因为嵌入损失的规模比其他两个损失要大得多,并且在训练过程中占主导地位。一旦我们设置了适当的损失权重以使所有任务以类似的速度学习(如“ App.Opt”基准),则检测任务和嵌入任务都会产生良好的性能。
其次,结果表明,“Loss规范”策略优于“统一”基线,但不如“ App.Opt”基线。MGDA-UB算法尽管在理论上是最合理的方法,但在我们的案例中却失败了,因为它为嵌入损失分配了太大的权重,因此其性能类似于均匀基准。优于App.Opt基准的唯一方法是不确定性权重策略。 在图3中,我们使用不确定性方法可视化了损失曲线和学习的权重。我们观察到,尽管损失权重被统一初始化,但是不确定性方法迅速将嵌入损失的权重减小到10-1左右,而其他两项任务的损失权重则提高到102。这与我们的App.Opt基准中的最佳权重(64:0.1)大致相符,但是由于损失权重是自动学习的,因此“不确定性”策略可提高跟踪精度。

图3:训练过程中不确定策略中损失权重(左)和损失(右)的变化。三种比例尺的轮廓被显示。请注意损失权重和损失都是对数刻度的。不确定性策略自动学习合理的权值损失,有利于多任务学习过程。
与SDE方法的比较 为了证明JDE相对于单独检测和嵌入(SDE)方法的优越性,我们实现了几个最先进的检测器和人员身份模型,并比较了它们与JDE在跟踪精度(MOTA)和运行时(FPS)方面的组合。检测器包括以ResNet-50和ResNet-101(He等人2016)为骨干的JDE,以ResNet-50和ResNet-101为骨干的Faster R-CNN(Ren等人2015)和Cascade R-CNN( Cai和Vasconcelos 2018)以ResNet-50和ResNet-101为骨干。人员重新识别模型包括IDE(Zheng,Yang和Haupt mann 2016),Triplet(Hermans,Beyer和Leibe 2017)和PCB(Sun等人2018)。在关联步骤中,我们对所有SDE模型使用上一节中介绍的相同的在线关联方法。 为了公平比较,这些SDE模型使用的训练数据与JDE相同。
在图4中,我们根据以上检测器和人员re-id模型的SDE组合的运行时(每幅图像的帧数)绘制MOTA度量。所有模型的运行时测试在一个单一的Nvidia泰坦xp GPU。图4(a)显示了在MOT-15列车组上的比较,其中行人密度较低。 相反,图4(b)显示了包含高密度人群的视频序列的比较(来自CVPR19 MOT挑战数据的CVPR19-01)。 可以得出几个观察结果。

图4:比较JDE和各种SDE组合的跟踪精度(MOTA)和速度(FPS)。 (a)显示在行人密度低的情况下的比较(MOT-15火车),而(b)显示在拥挤的情况下的比较(MOT-CVPR19-01)。 不同的颜色表示不同的嵌入模型,不同的形状表示不同的检测器。 我们清楚地观察到,提出的JDE方法(JDE嵌入+ JDE-DN53)具有最佳的时间精度折衷。 最佳观看颜色。
首先,提出的JDE运行速度非常快,同时产生了具有竞争力的跟踪精度,从而在精度和速度之间达到了最佳平衡。具体来说,具有DarkNet-53的JDE(JDE-DN53)的运行速度为22 FPS,产生的跟踪精度几乎与Cascade RCNN检测器与ResNet-101(Cascade-R101)+ PCB嵌入的组合一样好,而后者仅以 约6 FPS。
其次,JDE的跟踪精度非常接近JDE + IDE,JDE + Triplet和JDE + PCB的组合(请参见图4中的十字标记)。 这表明共同学习的嵌入几乎与单独学习的嵌入一样有区别。
最后,通过比较图4(a)和(b)中相同模型的运行时间,可以观察到,在拥挤的情况下,所有SDE模型的速度都会明显下降。这是因为嵌入模型的运行时间随着检测到的目标数量的增加而增加。这个缺点在JDE中不存在,因为嵌入是与检测结果一起计算的。因此,通常情况下的JDE与拥挤情况下的运行时差异要小得多(参见红色标记)。实际上,JDE的速度下降是由于关联步骤中增加的时间,这与目标数量正相关。
与最先进的MOT系统进行比较 由于我们使用其他数据而不是MOT-16训练集来训练JDE,因此我们在MOT-16基准测试的“私有数据”协议下比较JDE。比较了私有协议下的最新在线MOT方法,包括DeepSORT 2(Wojke,Bewley和Paulus 2017),RAR16wVGG(Fang等人2018),TAP(Zhou等人2018),CNNMTT( Mahmoudi,Ahadi和Rahmati(2019)和POI(Yu等人,2016)。所有这些方法都使用相同的检测器,即以VGG-16为骨干的Faster-RCNN,在大型私人行人检测数据集上进行训练。 这些方法之间的主要区别在于它们的嵌入模型和关联策略。例如,DeepSORT 2采用广域网(WRN(Zagoruyko和Komodakis 2016)作为嵌入模型,并使用MARS(Zheng et al。2016)数据集来训练外观嵌入,RAR16withVGG,TAP,CNNMTT和POI使用Incep 嵌入模型(Szegedy等人2015),Mask-RCNN(He等人2017),5层CNN和QAN(Liu,Yan和Ouyang 2017)作为嵌入模型。这些嵌入模型的训练数据也互不相同。 为了进行清楚的比较,我们在表3中列出了所有这些方法的检测器,嵌入模型和训练数据的数量。还介绍了精度和速度指标。

表3:与MOT-16基准测试中私有数据协议下最先进的在线MOT系统进行比较。使用清晰的度量来评估性能,并使用三个度量来评估运行时:检测器每秒帧数(FPSD)、关联步骤每秒帧数(FPSA)和整个系统每秒帧数(FPS)。显示预估的时间。我们清楚地观察到我们的方法具有最佳的效率和相当的准确性。
考虑到总体跟踪精度,例如MOTA度量,JDE通常是可比较的。 我们的结果比DeepSort 2高3.0%,比POI低1.7%。就运行速度而言,直接比较这些方法是不可行的,因为它们的运行时并未全部报告。因此,我们重新实现了基于VGG-16的Faster R-CNN检测器,并对其运行速度进行基准测试,然后针对这些方法估算整个MOT系统的运行速度上限。请注意,对于某些方法,未考虑嵌入模型的运行时,因此速度上限远远不够严格。即使在这样宽松的上限下,拟议的JDE的运行速度也要比现有方法快至少2到3倍,在接近1088×608的图像分辨率下达到接近实时的速度,即18.8 FPS。当我们将输入帧下采样到864×408的较低分辨率时,JDE的运行时间可以进一步提高到24.1 FPS,而性能只有很小的下降(∆ = -2.6%MOTA)。
分析和讨论 可能会注意到,与现有方法相比,JDE的IDF1得分更低,ID切换更多。 首先,我们怀疑原因是共同学习的嵌入可能比单独学习的嵌入弱。但是,当我们用共同学习的嵌入替换共同学习的嵌入时,IDF1分数和ID切换的数量几乎保持不变。 最终,我们发现,主要原因是当多个行人相互重叠时,检测不准确。 图5显示了这种JDE失败案例。这样不准确的盒子会引入很多ID切换,不幸的是,这种ID切换经常出现在轨迹的中间,因此IDF1得分较低。 在我们未来的工作中,当行人重叠很大时,如何改进JDE以做出更准确的盒子预测仍有待解决。

结论
在本文中,我们介绍了MDE系统JDE,该系统允许在共享模型中学习目标检测和外观特征。我们的设计显着减少了MOT系统的运行时间,从而可以(接近)实时速度运行。同时,我们系统的跟踪精度可与最新的在线MOT方法相媲美。此外,我们在建立这样的联合学习框架方面提供了有关良好实践和见解的详尽分析,讨论和实验。 将来,我们将更深入地研究时间准确性的权衡问题。