先对齐再融合,Salesforce Research提出ALBEF,用动量蒸馏进行多模态表示学习!多个下游任务性能SOTA!...
关注公众号,发现CV技术之美
▊ 写在前面
大规模的视觉和语言表征学习在各种视觉语言任务上显示出了良好的提升。现有的方法大多采用基于Transformer的多模态编码器来联合建模视觉token和单词token。由于视觉token和单词token不对齐,因此多模态编码器学习图像-文本交互具有挑战性。
在本文中,作者引入了一种对比损失,通过在跨模态注意前融合(ALBEF)来调整图像和文本表示,从而引导视觉和语言表示学习 。与大多数现有的方法不同,本文的方法不需要边界框标注或高分辨率的图像。为了改进从噪声web数据中学习,作者提出了动量蒸馏,这是一种从动量模型产生的伪目标中学习的自训练方法。
作者从互信息最大化的角度对ALBEF进行了理论分析,表明不同的训练任务可以被解释为图像-文本对生成视图的不同方式。ALBEF在多个下游的语言任务上实现了SOTA的性能。在图像-文本检索方面,ALBEF优于在相同数量级的数据集上预训练的方法。在VQA和NLVR2上,ALBEF与SOTA的技术相比,实现了2.37%和3.84%的绝对性能提升,同时推理速度更快。
▊ 1. 论文和代码地址

Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
论文:https://arxiv.org/abs/2107.07651
代码:https://github.com/salesforce/ALBEF
▊ 2. Motivation
视觉语言预训练(VLP)旨在从大规模图像文本对中学习多模态表示,从而改进下游的视觉语言(V+L)任务。大多数现有的VLP方法(如LXMERT,UNITER,OSCAR)都依赖于预训练过的目标检测器来提取基于区域的图像特征,并使用多模态编码器将图像特征与单词token进行融合。多模态编码器被训练来解决需要共同理解图像和文本的任务,如掩蔽语言建模(MLM)和图像-文本匹配(ITM)。
这个VLP框架虽然有效,但也存在几个关键的限制:
1)图像特征和词嵌入位于它们自己的空间中,这使得多模态编码器学习建模它们的交互具有挑战性;
2)目标检测器标注成本高,计算成本高,因为它在预训练需要边界框标注,在推理过程中需要高分辨率(例如600×1000)图像;
3)广泛使用的图像-文本数据集是从web中收集而来的,具有固有的噪声,现有的预训练目标如MLM可能会过度适应噪声文本,降低模型的泛化性能。
作者提出了 ALign BEfore Fuse(ALBEF) ,这是一个新的VLP框架来解决这些限制。作者首先用一个无检测器的图像编码器和一个文本编码器独立地对图像和文本进行编码。然后利用多模态编码器,通过跨模态注意,将图像特征与文本特征进行融合。作者在单模态编码器的表示上引入了一个中间的图像-文本对比(ITC)损失,它有三个目的:
1)它将图像特征和文本特征对齐,使多模态编码器更容易执行跨模态学习;
2)它改进了单模态编码器,以更好地理解图像和文本的语义;
3)它学习了一个通用的低维空间来嵌入图像和文本,这使图像-文本匹配目标能够通过对比hard negative挖掘找到信息更丰富的样本。
为了改进在噪声监督下的学习,作者提出了动量蒸馏(MoD) ,使模型能够利用一个更大的web数据集。在训练过程中,作者通过取模型参数的移动平均来保持模型的动量版本,并使用动量模型生成伪目标作为额外的监督。
对于MoD,该模型不会因为产生其他不同于web标注的合理输出而受到惩罚。作者证明,MoD不仅改进了预训练的任务,而且还改进了具有干净标注的下游任务。
此外,作者从互信息最大化的角度为ALBEF提供了理论论证。具体地说,作者证明了ITC和MLM最大化了图像-文本对不同视图之间互信息的下界,其中视图是通过从每对图像中获取部分信息而生成的。
从这个角度来看,动量蒸馏可以被解释为使用语义上相似的样本生成新的视图。因此,ALBEF学习了语义不变的视觉语言表示。
▊ 3. 方法
3.1 Model Architecture

如上图所示,ALBEF包含一个图像编码器、一个文本编码器和一个多模态编码器。作者使用一个12层的视觉Transformer ViT-B/16作为图像编码器,并使用在ImageNet-1k上预训练的权重来初始化它。一个输入图像I被编码到一个嵌入序列中:,其中是[CLS] token的嵌入。
作者对文本编码器和多模态编码器都使用了一个6层的Transformer。文本编码器使用BERT base模型的前6层进行初始化,多模态编码器使用BERT Base模型的最后6层进行初始化。文本编码器将输入文本T转换为嵌入序列,并输入多模态编码器。通过在多模态编码器的每一层进行交叉注意力,将图像特征与文本特征融合。
3.2 Pre-training Objectives
作者对ALBEF进行了三个目标的预训练:单模态编码器上的图像-文本对比学习(ITC) 、掩蔽语言建模(MLM) 和多模态编码器上的图像-文本匹配(ITM) 。作者通过在线对比 hard negative挖掘来改进ITM。
Image-Text Contrastive Learning
图像-文本对比学习的目的是在融合预训练更好的单模态表示。它学习了一个相似性函数,使匹配的图像-文本对具有更高的相似性得分。和是将[CLS]嵌入映射到标准化的低维(256d)表示的线性变换。
受MoCo的启发,作者维护了两个队列来存储动量单模态编码器的最新的M个图像-文本表示。动量编码器的归一化特征记为和。作者定义了和。
对于每个图像和文本,作者计算softmax归一化的图像到文本和文本到图像的相似度如下:
其中,τ是一个可学习的温度参数。设和表示ground truth的one-hot形式相似性,其中负对的概率为0,正对的概率为1。图像文本对比损失定义为p和y之间的交叉熵H:
Masked Language Modeling
Masked Language Modeling 同时利用图像和上下文文本来预测mask词。作者以15%的概率随机mask输入token,并用特殊token [MASK]替换它们。设表示mask文本,表示模型对mask token的预测概率。MLM使交叉熵损失最小化:
其中是一个one-hot形式的词汇分布,ground truth token的概率为1。
Image-Text Matching
图像-文本匹配可以预测一对图像和文本是正的(匹配)还是负的(不匹配)。作者使用多模态编码器的输出嵌入的[CLS] token作为图像-文本对的联合表示,并附加一个全连接(FC)层,然后是softmax来预测一个两类概率。
其中,是一个表示ground truth标签的二维one-hot向量。
作者提出了一种基于零计算开销的ITM任务进行 hard negatives采样的策略。如果负的图像-文本对共享相似的语义,但细粒度细节不同,那么它们是很难的。作者利用对比相似性来寻找batch内的 hard negatives。
对于一个batch中的每一幅图像,作者按照对比相似性分布从同一batch中抽取一个负文本,其中与图像更相似的文本有更高的机会被采样。同样地,作者还为每个文本采样一个hard negative图像。
ALBEF的完整的预训练目标是:
3.3 Momentum Distillation
用于预训练的图像-文本对大多是从网络中收集起来的,而且它们往往会有噪声。正样本对通常是弱相关的:文本可能包含与图像无关的单词,或者图像可能包含文本中没有描述的实体 。
对于ITC学习,图像的负样本文本也可能与图像的内容相匹配。对于MLM,可能存在其他与描述图像相同(或更好)的标注不同的词。然而,ITC和MLM的one-hot标签会惩罚所有负标签预测,不管它们的正确性如何。
为了解决这个问题,作者提出从动量模型生成的伪目标中学习。动量模型是一个连续发展的教师模型,它由单模态和多模态编码器的指数移动平均版本组成。
在训练过程中,训练基础模型,使其预测与动量模型的预测相匹配。具体来说,对于ITC,作者首先使用动量单模态编码器的特征计算图像-文本相似性,如和。因此,的损失函数为:
同样,对于MLM,设表示动量模型对mask token的预测概率,损失为:

在上图中,作者展示了来自伪目标的前5个候选对象的示例,它们有效地捕获了图像的相关单词/文本。
此外,作者还将MoD应用于下游任务。每个任务的最终损失是原始任务的损失和模型的预测和伪目标之间的kl散度的加权组合。为简单起见,作者为所有预训练和下游任务设置了权重α=0.4。
3.4 Pre-training Datasets
与UNITER相同,作者使用两个web数据集(Conceptual Captions,SBU Captions)和两个域内数据集(COCO和VisualGenome)构建了预训练数据。图像总数为4.0M,图像-文本对数为5.1M。
为了证明本文的方法可以用更大规模的web数据进行扩展,作者还包括了噪声更大的 Conceptual12M数据集,将图像总数增加到14.1M。
▊ 4. Mutual Information Maximization
在本节中,作者提供了解释ALBEF的另一个视角,并表明它最大化了图像-文本对的不同“视图”之间的互信息(MI)的下界。ITC、MLM和MoD可以被解释为生成视图的不同方式。
形式上,将两个随机变量a和b定义为一个数据点的两个不同视图。在自监督学习中,a和b是同一图像的两个扩充。在视觉语言表示学习中,可以认为a和b是捕获其语义的图像-文本对的不同变体。
我们的目标是学习对视图的变化保持不变的表示。这可以通过最大化a和b之间的MI来实现。在实践中,可以通过最小化InfoNCE损失来最大化MI(a,b)的下界,其定义为:
其中s(a,b)是一个评分函数(例如,两个表示之间的点积),包含从提出分布中提取的正样本b和负样本。
基于one-hot标签的ITC损失可以重写为:
最小化可以看作是最大化InfoNCE的对称版本。因此,ITC将这两种单独的模态(即I和T)视为图像-文本对的两个视图,并训练单模态编码器,以最大化正对的图像和文本视图之间的MI。
同理,可以将MLM解释为最大化mask单词token与其上下文(即图像+mask文本)之间的MI。具体来说,基于one-hot标签的MLM损失可以表示为:
其中是一个在多模态编码器的输出层的查找函数,它将一个词token y映射一个向量,V是完整的词汇集。是一个函数,它返回对应于mask上下文的多模态编码器的最终隐藏状态。
因此,MLM认为一个图像-文本对的两个视图是:1,一个随机选择的单词token;2,图像+与该mask单词的上下文文本。
ITC和MLM都通过模态分离或单词mask,从图像-文本对中获取部分信息来生成视图。本文的动量蒸馏可以被认为是从整个proposal分布中产生的替代视图。以为例,最小化相当于最小化以下目标:
它最大限度地提高了与图像I共享相似语义的文本的,因为这些文本将有更大的。类似地,也最大化了与T相似的图像的。
因此,本文的动量蒸馏可以被认为是对原始视图执行数据增强 。动量模型生成一组原始图像-文本对中没有的不同视图,并鼓励基本模型学习捕获视图不变语义信息的表示。
▊ 5.实验
5.1. Evaluation on the Proposed Methods

上表显示了本文方法的不同变体的下游任务的性能。与baseline预训练任务(MLM+ITM)相比,添加ITC大大提高了预训练模型的性能。所提出的 hard negative挖掘通过寻找信息更丰富的训练样本来改进ITM。添加动量蒸馏可以改进ITC(第4行)、MLM(第5行)和所有下游任务(第6行)的学习能力。
5.2. Evaluation on Image-Text Retrieval
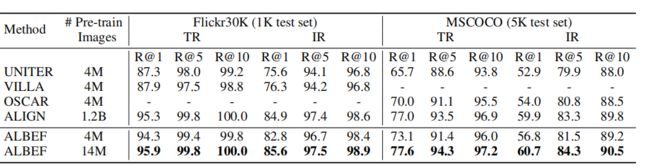
上表展示了图文检索fine-tuning的实验结果。

上表展示了图文检索Zero-shot的实验结果。
5.3. Evaluation on VQA, NLVR, and VE

上表展示了本文方法和其他方法在其他下游任务上的实验结果对比。
5.4. Weakly-supervised Visual Grounding

上表展示了本文方法弱监督visual grounding的结果。

上图展示了在多模态编码器的第三层的交叉注意图上的Grad-CAM可视化。

上图展示了在VQA模型的多模态编码器的交叉注意图上的Grad-CAM可视化。

上图展示了与单个单词对应的交叉注意图上的Grad-CAM可视化。
5.5. Ablation Study

上表研究了不同的设计选择对图像-文本检索的影响。

表7研究了文本赋值(TA)预训练和参数共享对NLVR2的影响。
▊ 6. 总结
本文提出了一种新的视觉语言表示学习框架ALBEF。ALBEF首先对齐单模态图像表示和文本表示,然后将它们与多模态编码器融合。作者通过理论和实验验证了提出的图像文本对比学习和动量蒸馏的有效性。与现有的方法相比,ALBEF在多个下游V+L任务上提供了更好的性能和更快的推理速度。
虽然本文在视觉语言表示学习方面显示了很好的结果,但在实践中部署它之前,对数据和模型进行额外的分析是必要的,因为网络数据可能包含意想不到的私人信息、不合适的图像或有害的文本,而且只优化准确性可能会产生不必要的社会影响。
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
欢迎加入「计算机视觉」交流群备注:CV
