ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision内容理解
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision内容理解
- 一、Abstract
- 二、引言
- 三、背景介绍
-
- 1、目前VLP模型框架介绍
- 2、多模态交互框架
- 3、Visual Embedding 框架
- 四、VILT模型
-
- 1、模型总览
- 2、预训练计划
- 3、Whole Word Masking
- 4、Image Augmentation
- 5、模型结构图
- 五、实验
-
- 1、总览:
- 2、实施细节
- 3、VLP模型的复杂度分析
- 4、分类任务
- 5、检索任务
- 6、Ablation Study
- 7. 常规的Visualization操作
- 六、结论及展望
写在前面
这篇文章作为一系列多模态理解的第一篇,从这里记录本人研究内容相关话题,期待后来者共同学习,共同进步,也顺便作为笔记备份。
- 文章链接:ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
- 代码:https://github.com/dandelin/vilt
发表于ICML2021, v2版本更精彩一些。本人看的是第一版,且第一版代码未放出。第二版多了代码部分+region feature提取部分,推荐看一下~
2022年7月29日 更新: 今天沐神和搭档朱老师在 B 站上面讲解了这篇论文,
- 链接:https://www.bilibili.com/video/BV14r4y1j74y
一、Abstract

摘要部分首先指出:当前大多数模型极度依赖于目标检测模型提取出的Feature进行VLP建模(不得不说,类似Faster-rcnn这种框架提取出的特征确实用起来精度高了很多),同时点明
缺点一:效率/速度;当然,肯定会慢很多,毋庸置疑,因为这种方法是将提取出的特征缓存到磁盘里面,再进行VLP训练。
缺点二:由于类似RPN这种候选区域生成器,也就是文中所说的visual enconde的出现+监督训练过程中label 词汇的有限,就导致了其上界问题。
后面就是作者对自己模型ViLT的介绍了:完全去除掉conv操作,加速加速再加速。同时提及精度和某些模型相当或超过一些模型。
评语:点名缺点很正常,速度慢,但是精度高呀,你没法打败;
上界问题哪个模型都离不开image+text呀
作者提出的这个模型,咋说,速度快,确实;但这个accuracy着实拉胯,和19年的MCAN比较额。
二、引言
引言部分描述了当前VLP模型的结构以及预训练的方法:MLM,ITM;
借势引出了Visual enocde的方法,基于region(传统)或者grid(2020年整活了),这些需要conv,而作者提出conv-free的方法,在速度上更快。
最后作者提出文章的三点贡献:
1、运行速度快,参数少;
2、第一个不使用卷积就能达到相当不错的精度;
3、首次用实验表明了whole word masking and image augmentations针对下游任务的有效性。
三、背景介绍
1、目前VLP模型框架介绍
喏,就是下面这张图了点出了目前VLP的框架结构:
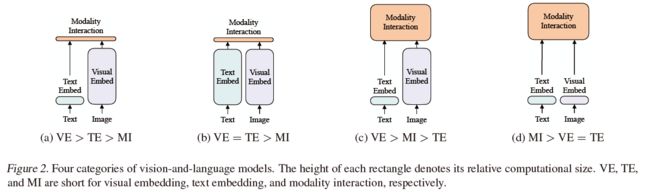
a图是19年及之前的方法,后来多模态交互部分都改成transformer了;
b图暂时还没认真看到过,因为大多数的Text Embed都是直接调用nn.embedding模块实现;
c图是目前自transformer出来之后的主流方法,精度贼高,但速度慢;
d图是目前作者提出的方法。速度快,但精度差。
但是这几种方法都没考虑transformer需要数据的问题,文章作者采用64块GPU,一个batch4096,我等一般人搞不起。
2、多模态交互框架
目前主要分为单流和双流模型,由于transformer的出现,双流模型以及快被淘汰了,主要是单流模型,作者也采用的是单流模型。
3、Visual Embedding 框架
三种:
1、基于region特征的,采用Resnet backbone提取特征,然后NMS操作,最后ROIhead;
2、基于grid特征的,类似于直接采用resnet-152这种直接提取特征的
3、基于patch特征的,将图像切成块,然后flatten,之后全连接层,变成VLP的输入。
作者采用的模型结构就是这种基于patch的。
四、VILT模型
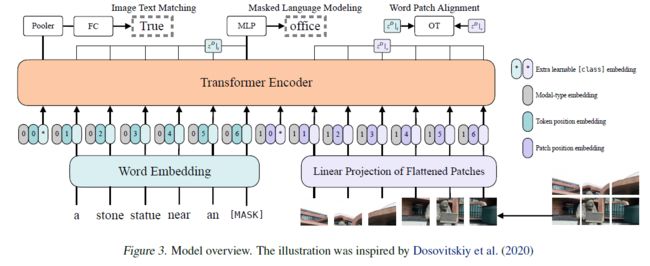
1、模型总览
这一部分作者概述了自己模型的一个流程,并用公式总结出来:

作者还提及了一些参数设置啥的,基本上和bert模型差不多,有一些区别在于LN的位置。
2、预训练计划
与bert模型类似,作者采用MLM和ITM这两种预训练方式
3、Whole Word Masking
这个是作者强调使用的另外一种,与MLM不同的是,直接MASK整个词。
4、Image Augmentation
这是作者说明的另一种图像增强方式,采用高斯模糊这种操作来增强模型的泛化能力(现在有很多文章专门在针对这个泛化搞事情了)。
5、模型结构图
五、实验
1、总览:
4个数据集:Microsoft COCO(MSCOCO), Visual Genome(VG), SBU Captions(SBU), Google Conceptual Caption
2种验证:
VQAv2+NLVR2
(MSCOCO+Flick30K)
2、实施细节
Adam+lr warmed up
图像尺寸的调整:
一般的VLP模型:800x1333,作者将其限定为384x640,产生12x20=240个patches, 另外将patches填充到length=200用于batch training.
需要注意的是相比于800x1333小了4倍。
在预训练时并未使用bert的权重,而是scratch;
迭代100K,64块V100,3天~,batch=4096,一般人哪能这么干[抠鼻]
在下游任务中训练10个epoch,batch=256/158
3、VLP模型的复杂度分析
主要强调一些参数量以及运行时间+输入bert模型的tokens长度
4、分类任务
VQAv2.0+NLVRv2
VQAv2:3129个vocabulary,仅仅采用VQAv2数据集进行微调,而其他模型有的采用了VG-QA模型
NLVR:Natural Language for Visual Reasoning
给两幅图片和一句话,判断哪个符合。
5、检索任务
MSCOCO+F30K
Image-to-text, text-to-image retrieval
6、Ablation Study
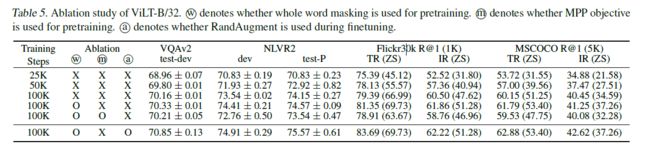
主要验证:
1、训练steps,也就是传说中的迭代次数;
越多越好
2、有无WM
有肯定好呀
3、有无MPP
没啥用
4、有无RandAugment
可以,很强
7. 常规的Visualization操作

六、结论及展望
总结一下本文说了啥,以及未来可能要干啥
离谱的是批评了搞unimodal embedders就像是在搞军备竞赛,呼吁大家不要这样干,
展望:
1、在拓展性上要增强,采用大尺度的数据集,建立ViLT的变体模型+ 大量vision-and-language datasets;
2、Mask Modeling操作
由于MPP效果不咋地,可以在这方面努力;
3、Augmentation Strategies策略
突出了高斯模糊的重要性。
推荐另一篇zhihu文章:ViLT:最简单的多模态Transformer
Ok,完美结束,吃完兰州牛肉面,晚上撸代码~