FRNet代码
代码目录简简单单,令人心旷神怡。
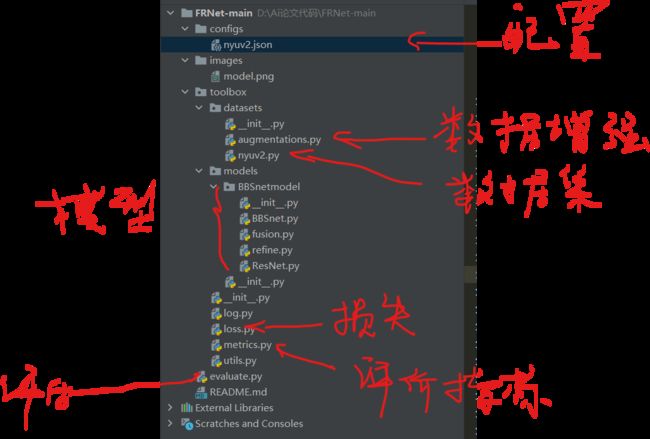
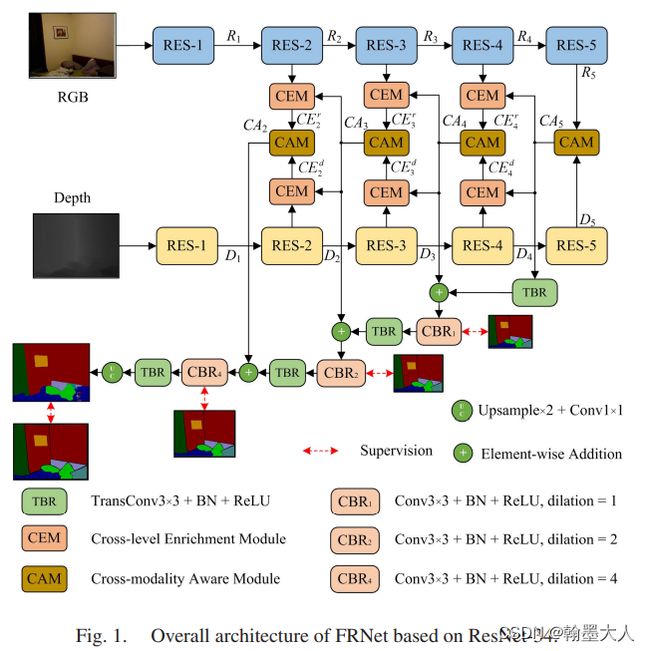
模型框架:
数据增强包括;

接着看一下数据集:
import os
from PIL import Image
import numpy as np
from sklearn.model_selection import train_test_split
import torch
import torch.utils.data as data
from torchvision import transforms
from toolbox.datasets.augmentations import Resize, Compose, ColorJitter, RandomHorizontalFlip, RandomCrop, RandomScale
from toolbox.utils import color_map
from torch import nn
from torch.autograd import Variable as V
import torch as t
class NYUv2(data.Dataset):
def __init__(self, cfg, random_state=3, mode='train',):
assert mode in ['train', 'test']
## pre-processing
self.im_to_tensor = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
self.dp_to_tensor = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.449, 0.449, 0.449], [0.226, 0.226, 0.226]),
])
self.root = cfg['root']
self.n_classes = cfg['n_classes']
scale_range = tuple(float(i) for i in cfg['scales_range'].split(' '))
crop_size = tuple(int(i) for i in cfg['crop_size'].split(' '))
self.aug = Compose([
ColorJitter(
brightness=cfg['brightness'],
contrast=cfg['contrast'],
saturation=cfg['saturation']),
RandomHorizontalFlip(cfg['p']),
RandomScale(scale_range),
RandomCrop(crop_size, pad_if_needed=True)
])
self.mode = mode
self.class_weight = np.array([4.01302219, 5.17995767, 12.47921102, 13.79726557, 18.47574439, 19.97749822,
21.10995738, 25.86733191, 27.50483598, 27.35425244, 25.12185149, 27.04617447,
30.0332327, 29.30994935, 34.72009825, 33.66136128, 34.28715586, 32.69376342,
33.71574286, 37.0865665, 39.70731054, 38.60681717, 36.37894266, 40.12142316,
39.71753044, 39.27177794, 43.44761984, 42.96761184, 43.98874667, 43.43148409,
43.29897719, 45.88895515, 44.31838311, 44.18898992, 42.93723439, 44.61617778,
47.12778303, 46.21331253, 27.69259756, 25.89111664, 15.65148615, ])
#train_test_split返回切分的数据集train/test
self.train_ids, self.test_ids = train_test_split(np.arange(1449), train_size=795, random_state=random_state)
def __len__(self):
if self.mode == 'train':
return len(self.train_ids)
else:
return len(self.test_ids)
def __getitem__(self, index):
# key=self.train_ids[index][0]
if self.mode == 'train':
image_index = self.train_ids[index]
gate_gt = torch.zeros(1)
# gate_gt[0] = key
else:
image_index = self.test_ids[index]
image_path = f'all_data/image/{image_index}.jpg'
depth_path = f'all_data/depth/{image_index}.png'
label_path = f'all_data/label/{image_index}.png'
# label_pathcxk = f'all_data/Label/{image_index}.png'
# label_path = '/home/yangenquan/PycharmProjects/NYUv2/all_data/label/75.png'
image = Image.open(os.path.join(self.root, image_path)) # RGB 0~255
depth = Image.open(os.path.join(self.root, depth_path)).convert('RGB') # 1 channel -> 3
label = Image.open(os.path.join(self.root, label_path)) # 1 channel 0~37
# labelcxk = Image.open(os.path.join(self.root, label_pathcxk))
sample = {
'image': image,
'depth': depth,
'label': label,
# 'name' : image_index
# 'labelcxk':labelcxk,
}
if self.mode == 'train': # 只对训练集增强
sample = self.aug(sample)
sample['image'] = self.im_to_tensor(sample['image'])
sample['depth'] = self.dp_to_tensor(sample['depth'])
sample['label'] = torch.from_numpy(np.asarray(sample['label'], dtype=np.int64)).long()
# sample['labelcxk'] = torch.from_numpy(np.asarray(sample['labelcxk'], dtype=np.int64)).long()
sample['label_path'] = label_path.strip().split('/')[-1] # 后期保存预测图时的文件名和label文件名一致
# sample['name'] = image_index
return sample
@property
def cmap(self):
return [(0, 0, 0),
(128, 0, 0), (0, 128, 0), (128, 128, 0),
(0, 0, 128), (128, 0, 128), (0, 128, 128), (128, 128, 128),
(64, 0, 0), (192, 0, 0), (64, 128, 0),
(192, 128, 0), (64, 0, 128), (192, 0, 128),
(64, 128, 128), (192, 128, 128), (0, 64, 0), (128, 64, 0),
(0, 192, 0), (128, 192, 0), (0, 64, 128), (128, 64, 128),
(0, 192, 128), (128, 192, 128), (64, 64, 0), (192, 64, 0),
(64, 192, 0), (192, 192, 0), (64, 64, 128), (192, 64, 128),
(64, 192, 128), (192, 192, 128), (0, 0, 64), (128, 0, 64),
(0, 128, 64), (128, 128, 64), (0, 0, 192), (128, 0, 192),
(0, 128, 192), (128, 128, 192), (64, 0, 64)] # 41
if __name__ == '__main__':
import json
path = '/home/yangenquan/PycharmProjects/第一论文模型/(60.1)mymodel8/configs/nyuv2.json'
with open(path, 'r') as fp:
cfg = json.load(fp)
dataset = NYUv2(cfg, mode='test')
print(len(dataset))
from toolbox.utils import class_to_RGB
from PIL import Image
import matplotlib.pyplot as plt
# label = '/home/yangenquan/PycharmProjects/NYUv2/all_data/label/166.png'
for i in range(len(dataset)):
sample = dataset[i]
image = sample['image']
depth = sample['depth']
label = sample['label']
name = sample['name']
image = image.numpy()
image = image.transpose((1, 2, 0))
image *= np.asarray([0.229, 0.224, 0.225])
image += np.asarray([0.485, 0.456, 0.406])
depth = depth.numpy()
depth = depth.transpose((1, 2, 0))
depth *= np.asarray([0.226, 0.226, 0.226])
depth += np.asarray([0.449, 0.449, 0.449])
# print(set(list(label)))
label = label.numpy()
# print(image)
label = class_to_RGB(label, N=41, cmap=dataset.cmap)
# print(dataset.cmap)
# plt.subplot('131') #行,列,那一幅图,如一共1*3图,该行的第一幅图
# plt.imshow(image)
# plt.subplot('132')
# plt.imshow(depth)
# plt.subplot('133')
# plt.imshow(label)
# plt.show()
label = Image.fromarray(label)
label.save(f'/home/yangenquan/PycharmProjects/NYUv2/all_data/change/label_color/{name}.png')
# break
主要看一下模型:在bbsnet文件中
import torch
import torch as t
import torch.nn as nn
from toolbox.models.BBSnetmodel.decoder import SG
from torch.autograd import Variable as V
import torchvision.models as models
from toolbox.models.BBSnetmodel.ResNet import ResNet50,ResNet34
from torch.nn import functional as F
from toolbox.models.BBSnetmodel.fusion import fusion
from toolbox.models.BBSnetmodel.refine import Refine
from toolbox.models.BBSnetmodel.SG import SG
from toolbox.models.BBSnetmodel.ASPP import ASPP
class BasicConv2d(nn.Module):
def __init__(self,in_channel,out_channel,kernel_size,stride=1,padding=0,dilation=1):
super(BasicConv2d, self).__init__()
self.conv1 = nn.Conv2d(in_channel,out_channel,kernel_size=kernel_size,stride=stride,padding=padding,dilation=dilation,bias=False)
self.bn = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU(inplace=True)
def forward(self,x):
x = self.conv1(x)
x = self.bn(x)
x = self.relu(x)
return x
class BasicConv2d_norelu(nn.Module):
def __init__(self,in_channel,out_channel,kernel_size,stride=1,padding=0,dilation=1):
super(BasicConv2d_norelu, self).__init__()
self.conv1 = nn.Conv2d(in_channel,out_channel,kernel_size=kernel_size,stride=stride,padding=padding,dilation=dilation,bias=False)
self.bn = nn.BatchNorm2d(out_channel)
# self.relu = nn.ReLU(inplace=True)
def forward(self,x):
x = self.conv1(x)
x = self.bn(x)
# x = self.relu(x)
return x
#GCM
# class GCM(nn.Module):
# def __init__(self,inchannels,outchannels):
# super(GCM, self).__init__()
# self.branches0 = nn.Sequential(
# BasicConv2d(inchannels,outchannels,kernel_size=1)
# )
# self.branches1 = nn.Sequential(
# BasicConv2d(inchannels,outchannels,kernel_size=1),
# BasicConv2d(outchannels,outchannels,kernel_size=(1,3),padding=(0,1)),
# BasicConv2d(outchannels,outchannels,kernel_size=(3,1),padding=(1,0)),
# BasicConv2d(outchannels,outchannels,kernel_size=3,padding=3,dilation=3)
# )
# self.branches2 = nn.Sequential(
# BasicConv2d(inchannels, outchannels, kernel_size=1),
# BasicConv2d(outchannels, outchannels, kernel_size=(1, 5), padding=(0, 2)),
# BasicConv2d(outchannels, outchannels, kernel_size=(5, 1), padding=(2, 0)),
# BasicConv2d(outchannels, outchannels, kernel_size=3, padding=5, dilation=5)
# )
# self.branches3 = nn.Sequential(
# BasicConv2d(inchannels, outchannels, kernel_size=1),
# BasicConv2d(outchannels, outchannels, kernel_size=(1, 7), padding=(0, 3)),
# BasicConv2d(outchannels, outchannels, kernel_size=(7, 1), padding=(3, 0)),
# BasicConv2d(outchannels, outchannels, kernel_size=3, padding=7, dilation=7)
# )
# self.conv1 = BasicConv2d(4*outchannels,outchannels,kernel_size=3,padding=1)
# self.conv2 = BasicConv2d(inchannels,outchannels,kernel_size=1)
# def forward(self,x):
# x0 = self.branches0(x)
# x1 = self.branches1(x)
# x2 = self.branches2(x)
# x3 = self.branches3(x)
# out_cat = self.conv1(torch.cat((x0,x1,x2,x3),dim=1))
# out_x = self.conv2(x)
# out = out_cat+out_x
# return out
#用rgb增强depth
# class DA(nn.Module):
# def __init__(self,inchannel,outchannel):
# super(DA, self).__init__()
# self.conv1 = BasicConv2d(in_channel=2*inchannel,out_channel=outchannel,kernel_size=3,padding=1)
# self.conv2 = nn.Conv2d(outchannel,outchannel,kernel_size=1,padding=0)
# self.bn1 = nn.BatchNorm2d(outchannel)
# def forward(self,r,d):
# combine = torch.cat((r,d),dim=1)
# combine = self.conv1(combine)
# out = combine+r
# out = self.conv2(out)
# out = self.bn1(out)
# out = out+d
# return out
class serialaspp(nn.Module):
def __init__(self,inc,outc,flag = None):
super(serialaspp, self).__init__()
# self.dconv1 = BasicConv2d_norelu(in_channel=2048,out_channel=1024,kernel_size=3,padding=1)
# self.dconv6 = BasicConv2d_norelu(in_channel=1024,out_channel=512,kernel_size=3,padding=6,dilation=6)
# self.dconv12 = BasicConv2d_norelu(in_channel=512,out_channel=256,kernel_size=3,padding=12,dilation=12)
# self.dconv18 = BasicConv2d_norelu(in_channel=256,out_channel=64,kernel_size=3,padding=18,dilation=18)
# self.dconv24 = BasicConv2d_norelu(in_channel=128,out_channel=64,kernel_size=3,padding=24,dilation=24)
self.flag = flag
self.dconv1 = BasicConv2d(in_channel=256, out_channel=256, kernel_size=3, padding=1)
self.dconv2 = BasicConv2d(in_channel=128, out_channel=128, kernel_size=3, padding=2,dilation=2)
self.dconv4 = BasicConv2d(in_channel=64, out_channel=64, kernel_size=3, padding=4,dilation=4)
# self.dconv6 = BasicConv2d_norelu(in_channel=256, out_channel=128, kernel_size=3, padding=6, dilation=6)
# self.dconv12 = BasicConv2d_norelu(in_channel=128, out_channel=64, kernel_size=3, padding=12, dilation=12)
# self.dconv18 = BasicConv2d_norelu(in_channel=64, out_channel=64, kernel_size=3, padding=18, dilation=18)
# self.conv_4 = nn.Conv2d(2 * 1024, 1024,kernel_size=3, padding=1)
# self.conv_3 = nn.Conv2d(2 * 512, 512, kernel_size=3, padding=1)
# self.conv_2 = nn.Conv2d(2 * 256, 256, kernel_size=3, padding=1)
# self.conv_4 = nn.Conv2d(2 * 256, 256, kernel_size=3, padding=1)
# self.conv_3 = nn.Conv2d(2 * 128, 128, kernel_size=3, padding=1)
# self.conv_2 = nn.Conv2d(2 * 64, 64, kernel_size=3, padding=1)
# self.conv = nn.Conv2d(64,nclass,kernel_size=3,padding=1)
# self.relu = nn.ReLU(inplace=True)
# self.upsample2 = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
# self.upsample4= nn.Upsample(scale_factor=4, mode='bilinear', align_corners=True)
# self.sig = nn.Sigmoid()
self.tconv1 = nn.ConvTranspose2d(inc, outc,kernel_size=3, stride=2, padding=1,output_padding=1, bias=False)
self.tconv_end = nn.ConvTranspose2d(outc, outc, kernel_size=3, stride=2, padding=1, output_padding=1, bias=False)
self.bn = nn.BatchNorm2d(outc)
self.relu = nn.ReLU(inplace=True)
def forward(self,x1,x2):
x2 = self.tconv1(x2)
x2 = self.bn(x2)
x2 = self.relu(x2)
# print(x1.shape)
# print(x2.shape)
out = x1+x2
if self.flag==1:
out = self.dconv1(out)
elif self.flag==2:
out = self.dconv2(out)
else:
out = self.dconv4(out)
out = self.tconv_end(out)
return out
# x5 = self.upsample2(x5)
# dout5 = self.dconv1(x5)
#
# x4 = torch.cat((x4,dout5),dim=1)
# x4 = self.conv_4(x4)
#
# x4 = self.upsample2(x4)
# dout4 = self.dconv6(x4)
#
# x3 = torch.cat((x3,dout4),dim=1)
# x3 = self.conv_3(x3)
#
# x3 = self.upsample2(x3)
# dout3 = self.dconv12(x3)
#
# x2 = torch.cat((x2,dout3),dim=1)
# x2 = self.conv_2(x2)
# dout2 = self.dconv18(x2)
#
#
# out = self.upsample4(dout2)
# out = self.conv(out)
# dout6 = self.dconv6(x)
# dout6 = x + dout6
# dout6 = self.relu(dout6)
# dout12 = self.dconv12(dout6)
# dout12 = dout6 + dout12
# dout12 = self.relu(dout12)
# dout18 = self.dconv18(dout12)
# dout18 = dout12 + dout18
# dout18 = self.relu(dout18)
# dout24 = self.dconv24(dout18)
# out = dout18 + dout24
# # out = self.relu(out)
# out = self.conv(out)
# # out = self.sig(dout24)
# return out
# BBSNet
class BBSNet(nn.Module):
def __init__(self, channel=32,n_class=None):
super(BBSNet, self).__init__()
# Backbone model
self.resnet = ResNet34('rgb') #64 64 128 256 512
self.resnet_depth = ResNet34('rgbd')
#ACM
# self.acm1 = acm(64)
# self.acm2 = acm(64)
# self.acm3 = acm(128)
# self.acm4 = acm(256)
# self.acm5 = acm(512)
#融合
self.fusions = nn.ModuleList([
fusion(64),
fusion(128),
fusion(256),
fusion(512)
])
self.refines_r_5 = nn.ModuleList([
Refine(256,512,k=2),
# Refine(128,512,k=4),
# Refine(64,512,k=8)
])
self.refines_r_4 = nn.ModuleList([
Refine(128, 256,k=2),
# Refine(64, 256,k=4)
])
self.refines_r_3 = nn.ModuleList([
Refine(64, 128,k=2),
])
self.refines_d_5 = nn.ModuleList([
Refine(256, 512,k=2),
# Refine(128, 512,k=4),
# Refine(64, 512,k=8)
])
self.refines_d_4 = nn.ModuleList([
Refine(128, 256,k=2),
# Refine(64, 256,k=4)
])
self.refines_d_3 = nn.ModuleList([
Refine(64, 128,k=2),
])
# self.conv_layer4 = BasicConv2d(2*512,512,kernel_size=3,padding=1)
# self.upsample8 = nn.Upsample(scale_factor=8, mode='bilinear', align_corners=True)
# self.upsample4 = nn.Upsample(scale_factor=4, mode='bilinear', align_corners=True)
# self.upsample2 = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
# #layer1_fusion细化conv1
# self.conv1 = nn.Conv2d(2048*2,1024,kernel_size=3,padding=1)
# self.conv2 = nn.Conv2d(1024, 512, kernel_size=3, padding=1)
# self.conv3 = nn.Conv2d(512, 256, kernel_size=3, padding=1)
# self.conv4 = nn.Conv2d(256, 64, kernel_size=3, padding=1)
#
# self.bconv5 = BasicConv2d(in_channel=2048,out_channel=1024,kernel_size=3,padding=1)
# self.bconv4 = BasicConv2d(in_channel=1024, out_channel=512, kernel_size=3, padding=1)
# self.bconv3 = BasicConv2d(in_channel=512, out_channel=256, kernel_size=3, padding=1)
# self.bconv2 = BasicConv2d(in_channel=256, out_channel=64, kernel_size=3, padding=1)
# self.bconv1 = BasicConv2d(in_channel=64, out_channel=n_class, kernel_size=3, padding=1)
#
# self.conv_end = nn.Conv2d(64,n_class,kernel_size=1,padding=0)
# self.sgs = nn.ModuleList([
# SG(256,512,flag=1,in_plane=256),
# SG(128,256,flag=2,in_plane=128),
# SG(64,128,flag=3,in_plane=64),
# SG(64,64,c=False,flag=4,in_plane=64)
# ])
# #self.aspp = ASPP(num_classes=n_class)
# #处理layer4_fusion
# self.transconv = nn.ConvTranspose2d(512, 256, kernel_size=1, padding=0)
# self.bn = nn.BatchNorm2d(256)
#
# 对每一层cat之后进行通道变换
# self.conv_aux1 = nn.Conv2d(6,3,kernel_size=1,stride=1)
# self.conv_aux2 = nn.Conv2d(64, n_class, kernel_size=1, stride=1)
# self.conv_aux3 = nn.Conv2d(64, n_class, kernel_size=1, stride=1)
# self.conv_aux4 = nn.Conv2d(64, n_class, kernel_size=1, stride=1)
# self.decoder = serialaspp(nclass=n_class)
self.decoder = nn.ModuleList([
serialaspp(512,256,flag=1),
serialaspp(256,128,flag=2),
serialaspp(128,64,flag=3)
])
self.conv_end = nn.Conv2d(64,n_class,kernel_size=1,padding=0)
self.upsample2 = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv_aux1 = nn.Conv2d(256,n_class,kernel_size=1,padding=0)
self.conv_aux2 = nn.Conv2d(128, n_class, kernel_size=1, padding=0)
self.conv_aux3 = nn.Conv2d(64, n_class, kernel_size=1, padding=0)
#加载预训练
if self.training:
self.initialize_weights()
def forward(self, x, x_depth):
x_depth = x_depth[:, :1, ...]
#conv1 64 ,1/4
x1 = self.resnet.conv1(x)
x1 = self.resnet.bn1(x1)
x1 = self.resnet.relu(x1)
x1 = self.resnet.maxpool(x1)
#h,w = x1.size()[2:]
x_depth1 = self.resnet_depth.conv1(x_depth)
x_depth1 = self.resnet_depth.bn1(x_depth1)
x_depth1 = self.resnet_depth.relu(x_depth1)
x_depth1 = self.resnet_depth.maxpool(x_depth1)
#layer1 256 1/4
x2 = self.resnet.layer1(x1)
x_depth2 = self.resnet_depth.layer1(x_depth1)
#layer2 512 1/8
x3 = self.resnet.layer2(x2)
x_depth3 = self.resnet_depth.layer2(x_depth2)
#layer3 1024 1/16
x4 = self.resnet.layer3_1(x3)
x_depth4 = self.resnet_depth.layer3_1(x_depth3)
#layer4 2048 1/32
x5 = self.resnet.layer4_1(x4)
x_depth5 = self.resnet_depth.layer4_1(x_depth4)
fuse5 = self.fusions[3](x5,x_depth5)
x4 = self.refines_r_5[0](x4,fuse5)
# x3 = self.refines_r_5[1](x3,fuse5)
# x2 = self.refines_r_5[2](x2,fuse5)
x_depth4 = self.refines_d_5[0](x_depth4,fuse5)
# x_depth3 = self.refines_d_5[1](x_depth3, fuse5)
# x_depth2 = self.refines_d_5[2](x_depth2, fuse5)
fuse4 = self.fusions[2](x4,x_depth4)
x3 = self.refines_r_4[0](x3, fuse4)
# x2 = self.refines_r_4[1](x2, fuse4)
x_depth3 = self.refines_d_4[0](x_depth3, fuse4)
# x_depth2 = self.refines_d_4[1](x_depth2, fuse4)
fuse3 = self.fusions[1](x3,x_depth3)
x2 = self.refines_r_3[0](x2,fuse3)
x_depth2 = self.refines_d_3[0](x_depth2,fuse3)
fuse2 = self.fusions[0](x2,x_depth2)
out45 = self.decoder[0](fuse4,fuse5) #256
out43 = self.decoder[1](fuse3,out45) #128
out32 = self.decoder[2](fuse2,out43) #64
out = self.upsample2(out32)
out = self.conv_end(out)
a_out1 = self.conv_aux1(out45)
a_out2 = self.conv_aux2(out43)
a_out3 = self.conv_aux3(out32)
# out = self.decoder(fuse2,fuse3,fuse4,fuse5)
if self.training:
return a_out1, a_out2, a_out3, out
else:
return out
# initialize the weights
def initialize_weights(self):
#pretrain_dict = model_zoo.load_url(model_urls['resnet50'])
res34 = models.resnet34(pretrained=True)
pretrained_dict = res34.state_dict()
all_params = {}
for k, v in self.resnet.state_dict().items():
if k in pretrained_dict.keys():
v = pretrained_dict[k]
all_params[k] = v
elif '_1' in k:
name = k.split('_1')[0] + k.split('_1')[1]
v = pretrained_dict[name]
all_params[k] = v
elif '_2' in k:
name = k.split('_2')[0] + k.split('_2')[1]
v = pretrained_dict[name]
all_params[k] = v
assert len(all_params.keys()) == len(self.resnet.state_dict().keys())
self.resnet.load_state_dict(all_params)
all_params = {}
for k, v in self.resnet_depth.state_dict().items():
if k == 'conv1.weight':
all_params[k] = torch.nn.init.normal_(v, mean=0, std=1)
elif k in pretrained_dict.keys():
v = pretrained_dict[k]
all_params[k] = v
elif '_1' in k:
name = k.split('_1')[0] + k.split('_1')[1]
v = pretrained_dict[name]
all_params[k] = v
elif '_2' in k:
name = k.split('_2')[0] + k.split('_2')[1]
v = pretrained_dict[name]
all_params[k] = v
assert len(all_params.keys()) == len(self.resnet_depth.state_dict().keys())
self.resnet_depth.load_state_dict(all_params)
if __name__ == '__main__':
x = V(t.randn(2,3,480,640))
y = V(t.randn(2,3,480,640))
net = BBSNet(n_class=41)
net1= net(x,y)
print(net1.shape)
# from torchsummary import summary
# model = BBSNet(n_class=41)
# model = model.cuda()
# summary(model, input_size=[(3, 480, 640),(3,480,640)],batch_size=6)
我们直接看forward函数:
首先就是很常规的resnet34结构:rgb和depth分别经过 卷积—>池化
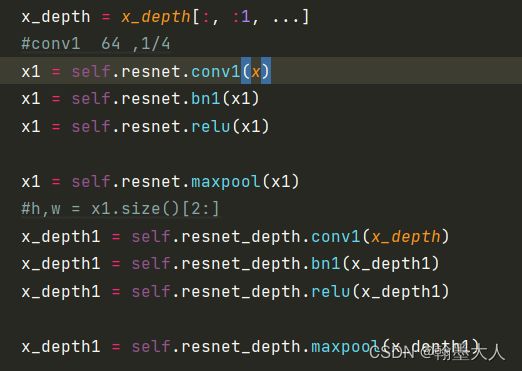
接着是resnet34的四个stage没有什么不一样的。
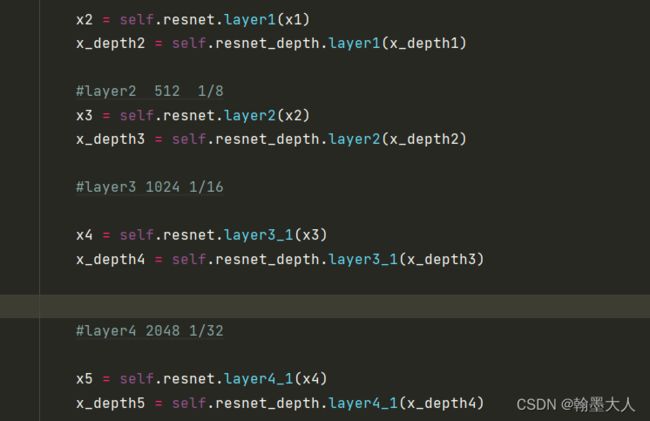
根据模型框架我们知道,RGB和Depth的最后一层输出共同进入到CAM中。
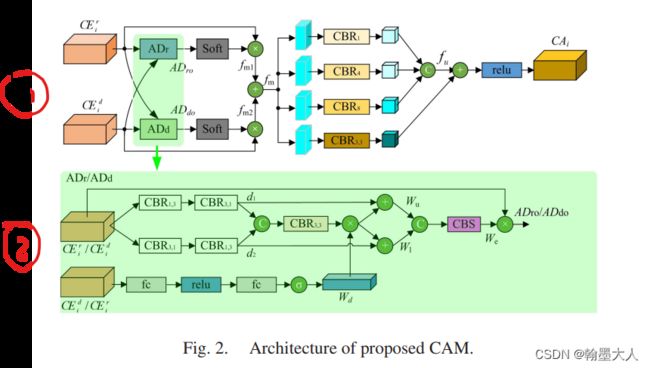
fuse5 = self.fusions[3](x5,x_depth5)

图像的维度为512,所以用第三个fusion(512)。然后我们跳到fusion里面,在fusion.py文件中;
class fusion(nn.Module):
def __init__(self,inc):
super(fusion, self).__init__()
self.ar = AR(inchannel=inc)
# self.a = acm(num_channel=inc)
# self.conv_end = BasicConv2d(in_channel=inc*2,out_channel=inc,kernel_size=3,padding=1)
self.sof = nn.Softmax(dim=1)
self.er = ER(in_channel=inc)
def forward(self,r,d):
br = self.ar(r,d)
bd = self.ar(d,r)
br = self.sof(br)
bd = self.sof(bd)
br = br*r
bd = bd*d
out = br+bd
out = self.er(out)
return out
我们再跳到AR函数中,参数为(rgb,depth):
class AR(nn.Module):
def __init__(self,inchannel):
super(AR, self).__init__()
# self.conv = BasicConv2d(in_channel = 2*inchannel,out_channel = inchannel,kernel_size=3,padding=1)
self.conv13 = BasicConv2d(in_channel=inchannel,out_channel=inchannel,kernel_size=(1,3),padding=(0,1))
self.conv31 = BasicConv2d(in_channel=inchannel, out_channel=inchannel, kernel_size=(3, 1), padding=(1, 0))
self.conv13_2 = BasicConv2d(in_channel=inchannel, out_channel=inchannel, kernel_size=(1, 3), padding=(0, 1))
self.conv31_2 = BasicConv2d(in_channel=inchannel, out_channel=inchannel, kernel_size=(3, 1),padding=(1, 0))
# self.aux_conv = nn.Conv2d(inchannel,inchannel,kernel_size=3,padding=1)
self.aux_conv = FilterLayer(inchannel,inchannel)
self.bn1 = nn.BatchNorm2d(inchannel)
self.sof = nn.Softmax(dim=1)
self.fuseconv = BasicConv2d(inchannel*2,inchannel,kernel_size=3,padding=1)
self.conv_end = nn.Conv2d(2*inchannel,inchannel,kernel_size=3,padding=1)
# self.bn2 = nn.BatchNorm2d(inchannel)
def forward(self,max,aux):
max_1 = self.conv13(max)
max_1 = self.conv31(max_1)
max_2 = self.conv31_2(max)
max_2 = self.conv13_2(max_2)
fuse_max = torch.cat((max_1, max_2), dim=1)
fuse_max = self.fuseconv(fuse_max)
aux_w = self.aux_conv(aux)
weight = aux_w*fuse_max
max_1 = weight+max_1
max_2 = weight+max_2
ar_out = torch.cat((max_1,max_2),dim=1)
ar_out = self.conv_end(ar_out)
ar_out = self.bn1(ar_out)
ar_out = self.sof(ar_out)
ar_out = ar_out*max
return ar_out
即max对应RGB,aux对应于depth:
1:max首先经过conv13,conv31,由文中知道,是一个1x3和3x1的卷积。步长为1,padding=(0,1)。对于这种长条状卷积,我们按原始的padding填充就可以,比如3x1卷积,长为3,宽为1,移动的时候我们只需要在宽的方向上填充1,图像的大小就不变,其余同理。
self.conv13 = BasicConv2d(in_channel=inchannel,out_channel=inchannel,kernel_size=(1,3),padding=(0,1))
self.conv31 = BasicConv2d(in_channel=inchannel, out_channel=inchannel, kernel_size=(3, 1), padding=(1, 0))

2:max接着另一条支路经过相同的卷积,图像大小不变。
self.conv13_2 = BasicConv2d(in_channel=inchannel, out_channel=inchannel, kernel_size=(1, 3), padding=(0, 1))
self.conv31_2 = BasicConv2d(in_channel=inchannel, out_channel=inchannel, kernel_size=(3, 1),padding=(1, 0))
3:将生成的结果按维度拼接起来,这样图像的维度就会扩大2倍:
fuse_max = torch.cat((max_1, max_2), dim=1)
4:然后经过一个3x3卷积进行融合,通道变为原始大小。
self.fuseconv = BasicConv2d(inchannel*2,inchannel,kernel_size=3,padding=1)
5:接着对depth进行处理,注意维度不会发生变换:
aux_w = self.aux_conv(aux)
self.aux_conv = FilterLayer(inchannel,inchannel)

输入的depth经过一个自适应平均池化,维度变为(b,c,1,1)然后view为(b,c)大小,再经过一个fc,即线性层,维度缩小16倍,经过relu,再经过线性层,维度变回原来大小,再经过sigmoid函数。最后view为(b,c,1,1)大小,生成的权重。
6:将生成的权重与rgb融合后的特征进行相乘。然后与进过条状卷积后图片进行相加。生成的结果再concat。
weight = aux_w*fuse_max
max_1 = weight+max_1
max_2 = weight+max_2
ar_out = torch.cat((max_1,max_2),dim=1)
7:将concat之后的特征再进行融合,凡concat必有卷积。接着进行bn和softmax。
ar_out = self.conv_end(ar_out)
ar_out = self.bn1(ar_out)
ar_out = self.sof(ar_out)
8:经过softamx生成的权重与原始的图片进行相乘。生成br。
ar_out = ar_out*max
return ar_out
9:将rgb和depth进行调换然后再执行一遍。
br = self.ar(r,d)
bd = self.ar(d,r)
10:生成的结果再进行softamx,与原始的输入相乘。再相加。对应于文中的fm。
br = br*r
bd = bd*d
out = br+bd
11:接着将fm分别进行不同膨胀率的卷积操作,然后将列表中的三个输出按维度进行拼接,经过一个卷积。原始的fm再进过一个1x1卷积,直接add起来,进过一个relu得到最终输出。即CA5。
out = self.er(out)

12:然后CA5和resnet第三个layer的rgb输出,共同输入到CEM中,depth同理。
x4 = self.refines_r_5[0](x4,fuse5)
x_depth4 = self.refines_d_5[0](x_depth4,fuse5)
self.refines_r_5 = nn.ModuleList([
Refine(256,512,k=2),
# Refine(128,512,k=4),
# Refine(64,512,k=8)
])
self.refines_d_5 = nn.ModuleList([
Refine(256, 512,k=2),
# Refine(128, 512,k=4),
# Refine(64, 512,k=8)
])
然后我们到refine.py文件中:
import torch
import torch.nn as nn
class BasicConv2d(nn.Module):
def __init__(self,in_channel,out_channel,kernel_size,stride=1,padding=0,dilation=1):
super(BasicConv2d, self).__init__()
self.conv1 = nn.Conv2d(in_channel,out_channel,kernel_size=kernel_size,stride=stride,padding=padding,dilation=dilation,bias=False)
self.bn = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU(inplace=True)
def forward(self,x):
x = self.conv1(x)
x = self.bn(x)
x = self.relu(x)
return x
class Refine(nn.Module):
def __init__(self,cur_channel,hig_channel,k):
super(Refine, self).__init__()
self.conv_t = BasicConv2d(hig_channel,cur_channel,kernel_size=3,padding=1)
self.upsample = nn.Upsample(scale_factor=k, mode='bilinear', align_corners=True)
self.corr_conv = nn.Conv2d(cur_channel,cur_channel,kernel_size=3,padding=1)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.sig = nn.Sigmoid()
def forward(self,current,higher):
higher = self.upsample(higher)
higher = self.conv_t(higher)
corr = higher-current
corr = self.corr_conv(corr)
corr = self.avgpool(corr)
corr = self.sig(corr)
corr = higher*corr
current = current+corr
return current
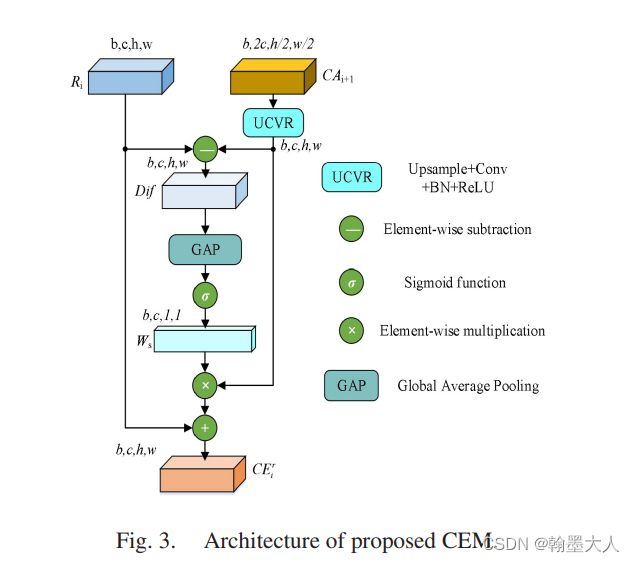
我们首先将刚才融合的fuse进行上采样,因为他是来自下一级的。然后经过一个卷积,将resnet的输出与fuse上采样的图片相减,经过一个卷积和GAP和sigmoid,与原始的fuse相乘在和resnet输出图相加。RGB这样,depth同理。
就这样不断的向前传递,即文中的FCE:
fuse5 = self.fusions[3](x5,x_depth5)
x4 = self.refines_r_5[0](x4,fuse5)
x_depth4 = self.refines_d_5[0](x_depth4,fuse5)
fuse4 = self.fusions[2](x4,x_depth4)
x3 = self.refines_r_4[0](x3, fuse4)
x_depth3 = self.refines_d_4[0](x_depth3, fuse4)
# x_depth2 = self.refines_d_4[1](x_depth2, fuse4)
fuse3 = self.fusions[1](x3,x_depth3)
x2 = self.refines_r_3[0](x2,fuse3)
x_depth2 = self.refines_d_3[0](x_depth2,fuse3)
fuse2 = self.fusions[0](x2,x_depth2)
13:decoder:调用的serialaspp函数。
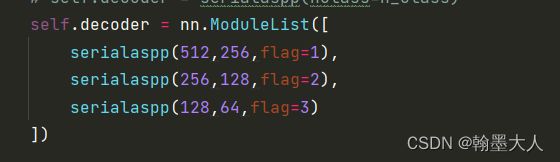
class serialaspp(nn.Module):
def __init__(self,inc,outc,flag = None):
super(serialaspp, self).__init__()
self.flag = flag
self.dconv1 = BasicConv2d(in_channel=256, out_channel=256, kernel_size=3, padding=1)
self.dconv2 = BasicConv2d(in_channel=128, out_channel=128, kernel_size=3, padding=2,dilation=2)
self.dconv4 = BasicConv2d(in_channel=64, out_channel=64, kernel_size=3, padding=4,dilation=4)
self.tconv1 = nn.ConvTranspose2d(inc, outc,kernel_size=3, stride=2, padding=1,output_padding=1, bias=False)
self.tconv_end = nn.ConvTranspose2d(outc, outc, kernel_size=3, stride=2, padding=1, output_padding=1, bias=False)
self.bn = nn.BatchNorm2d(outc)
self.relu = nn.ReLU(inplace=True)
def forward(self,x1,x2):
x2 = self.tconv1(x2)
x2 = self.bn(x2)
x2 = self.relu(x2)
# print(x1.shape)
# print(x2.shape)
out = x1+x2
if self.flag==1:
out = self.dconv1(out)
elif self.flag==2:
out = self.dconv2(out)
else:
out = self.dconv4(out)
out = self.tconv_end(out)
return out
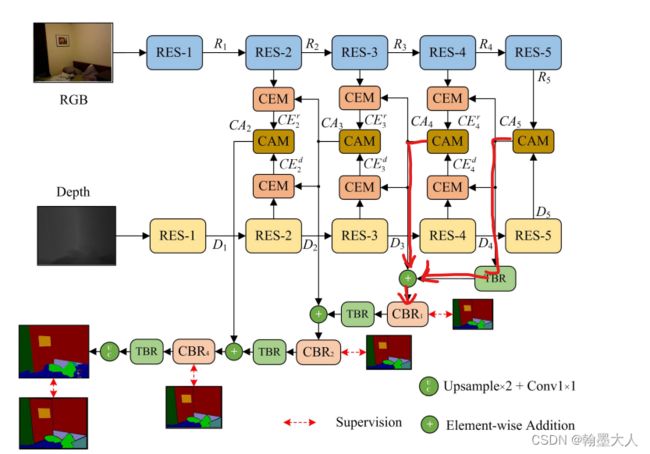
两个CAM的输出,其中尺寸小的经过转置卷积,然后和上一层的CAM进行相加,再经过一个3x3的卷积,得到最终输出。其余的同理。最后进过一个卷积,输出通道为类别个数。然后如果处于训练过程,还有三个辅助的输出用于计算深监督损失。
self.conv_end = nn.Conv2d(64,n_class,kernel_size=1,padding=0)
if self.training:
return a_out1, a_out2, a_out3, out
这样整个模型就搭建完毕。代码中没有train文件。