Alexnet详解以及tesnsorflow实现alexnet;什么是alexnet alexnet能做什么;alexnet教程
一、over roll archi
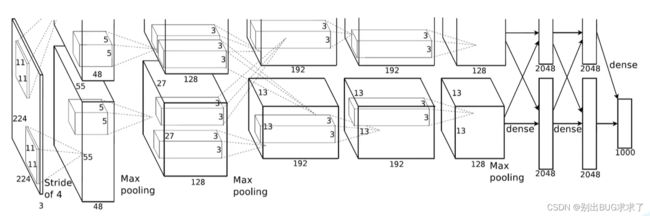
Alexnet——2012年——标志性网络
该网络的亮点在于:
(1)首次利用GPU进行网络加速训练。
(2)使用了ReLU激活函数,而不是传统的Sigmoid激活函数以及Tanh激活函数。(smoid求导比较麻烦而且当网路比较深的时候会出现梯度消失)
(3)使用了LRN局部响应归一化。
(4)在全连接层的前两层中使用了Dropout随机失活神经元操作,以减少过拟合。
dropout解释:使用dropout后,在每一层中随机失活一些神经元——减少训练参数从而减少over fitting

二、结构详解
1. Conv1
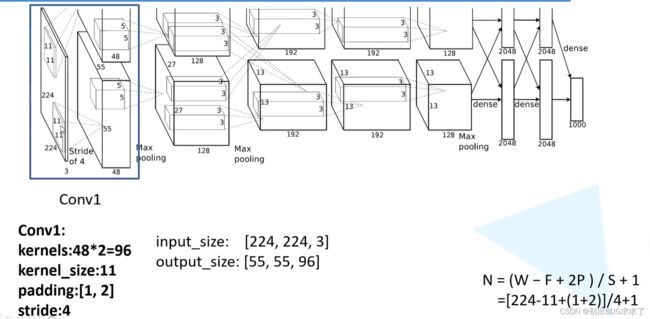
2. Maxpool1

3. Conv2

4. Maxpool2

5. Conv3

6. Conv4

7. Conv5

8. Maxpool3

9. FC1
描述一下: 这里使用4096个神经元,对256个大小为66特征图,进行一个全链接,也就是将66大小的特征图,进行卷积变为一个特征点,然后对于4096个神经元中的一个点,是由256个特征图中某些个特征图卷积之后得到的特征点乘以相应的权重之后,再加上一个偏置得到. 再进行一个dropout随机从4096个节点中丢掉一些节点信息(也就是值清0),然后就得到新的4096个神经元.

10. FC2
和fc1类似.
11. FC3

采用的是1000个神经元,然后对fc7中4096个神经元进行全链接,然后会通过高斯过滤器,得到1000个float型的值,也就是我们所看到的预测的可能性,
如果是训练模型的话,会通过标签label进行对比误差,然后求解出残差,再通过链式求导法则,将残差通过求解偏导数逐步向上传递,并将权重进行推倒更改,类似与BP网络思虑,然后会逐层逐层的调整权重以及偏置.
10. summary


三、tensorflow实现
model:
tensorflow实现:
import tensorflow as tf
def alexnet(x, keep_prob, num_classes):
# conv1
with tf.name_scope('conv1') as scope:
kernel = tf.Variable(tf.truncated_normal([11, 11, 3, 96], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(x, kernel, [1, 4, 4, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[96], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope)
# lrn1
with tf.name_scope('lrn1') as scope:
lrn1 = tf.nn.local_response_normalization(conv1,
alpha=1e-4,
beta=0.75,
depth_radius=2,
bias=2.0)
# pool1
with tf.name_scope('pool1') as scope:
pool1 = tf.nn.max_pool(lrn1,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID')
# conv2
with tf.name_scope('conv2') as scope:
pool1_groups = tf.split(axis=3, value = pool1, num_or_size_splits = 2)
kernel = tf.Variable(tf.truncated_normal([5, 5, 48, 256], dtype=tf.float32,
stddev=1e-1), name='weights')
kernel_groups = tf.split(axis=3, value = kernel, num_or_size_splits = 2)
conv_up = tf.nn.conv2d(pool1_groups[0], kernel_groups[0], [1,1,1,1], padding='SAME')
conv_down = tf.nn.conv2d(pool1_groups[1], kernel_groups[1], [1,1,1,1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
biases_groups = tf.split(axis=0, value=biases, num_or_size_splits=2)
bias_up = tf.nn.bias_add(conv_up, biases_groups[0])
bias_down = tf.nn.bias_add(conv_down, biases_groups[1])
bias = tf.concat(axis=3, values=[bias_up, bias_down])
conv2 = tf.nn.relu(bias, name=scope)
# lrn2
with tf.name_scope('lrn2') as scope:
lrn2 = tf.nn.local_response_normalization(conv2,
alpha=1e-4,
beta=0.75,
depth_radius=2,
bias=2.0)
# pool2
with tf.name_scope('pool2') as scope:
pool2 = tf.nn.max_pool(lrn2,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID')
# conv3
with tf.name_scope('conv3') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 384],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool2, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[384], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv3 = tf.nn.relu(bias, name=scope)
# conv4
with tf.name_scope('conv4') as scope:
conv3_groups = tf.split(axis=3, value=conv3, num_or_size_splits=2)
kernel = tf.Variable(tf.truncated_normal([3, 3, 192, 384],
dtype=tf.float32,
stddev=1e-1), name='weights')
kernel_groups = tf.split(axis=3, value=kernel, num_or_size_splits=2)
conv_up = tf.nn.conv2d(conv3_groups[0], kernel_groups[0], [1, 1, 1, 1], padding='SAME')
conv_down = tf.nn.conv2d(conv3_groups[1], kernel_groups[1], [1,1,1,1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[384], dtype=tf.float32),
trainable=True, name='biases')
biases_groups = tf.split(axis=0, value=biases, num_or_size_splits=2)
bias_up = tf.nn.bias_add(conv_up, biases_groups[0])
bias_down = tf.nn.bias_add(conv_down, biases_groups[1])
bias = tf.concat(axis=3, values=[bias_up,bias_down])
conv4 = tf.nn.relu(bias, name=scope)
# conv5
with tf.name_scope('conv5') as scope:
conv4_groups = tf.split(axis=3, value=conv4, num_or_size_splits=2)
kernel = tf.Variable(tf.truncated_normal([3, 3, 192, 256],
dtype=tf.float32,
stddev=1e-1), name='weights')
kernel_groups = tf.split(axis=3, value=kernel, num_or_size_splits=2)
conv_up = tf.nn.conv2d(conv4_groups[0], kernel_groups[0], [1, 1, 1, 1], padding='SAME')
conv_down = tf.nn.conv2d(conv4_groups[1], kernel_groups[1], [1,1,1,1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
biases_groups = tf.split(axis=0, value=biases, num_or_size_splits=2)
bias_up = tf.nn.bias_add(conv_up, biases_groups[0])
bias_down = tf.nn.bias_add(conv_down, biases_groups[1])
bias = tf.concat(axis=3, values=[bias_up,bias_down])
conv5 = tf.nn.relu(bias, name=scope)
# pool5
with tf.name_scope('pool5') as scope:
pool5 = tf.nn.max_pool(conv5,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',)
# flattened6
with tf.name_scope('flattened6') as scope:
flattened = tf.reshape(pool5, shape=[-1, 6*6*256])
# fc6
with tf.name_scope('fc6') as scope:
weights = tf.Variable(tf.truncated_normal([6*6*256, 4096],
dtype=tf.float32,
stddev=1e-1), name='weights')
biases = tf.Variable(tf.constant(0.0, shape=[4096], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.xw_plus_b(flattened, weights, biases)
fc6 = tf.nn.relu(bias)
# dropout6
with tf.name_scope('dropout6') as scope:
dropout6 = tf.nn.dropout(fc6, keep_prob)
# fc7
with tf.name_scope('fc7') as scope:
weights = tf.Variable(tf.truncated_normal([4096,4096],
dtype=tf.float32,
stddev=1e-1), name='weights')
biases = tf.Variable(tf.constant(0.0, shape=[4096], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.xw_plus_b(dropout6, weights, biases)
fc7 = tf.nn.relu(bias)
# dropout7
with tf.name_scope('dropout7') as scope:
dropout7 = tf.nn.dropout(fc7, keep_prob)
# fc8
with tf.name_scope('fc8') as scope:
weights = tf.Variable(tf.truncated_normal([4096, num_classes],
dtype=tf.float32,
stddev=1e-1), name='weights')
biases = tf.Variable(tf.constant(0.0, shape=[num_classes], dtype=tf.float32),
trainable=True, name='biases')
fc8 = tf.nn.xw_plus_b(dropout7, weights, biases)
return fc8
keras实现:(v1是是使用keras function api的方法搭建、v2是subclasses也就是子类的方法搭建-类似pytorch)
from tensorflow.keras import layers, models, Model, Sequential
def AlexNet_v1(im_height=224, im_width=224, num_classes=1000):
# tensorflow中的tensor通道排序是NHWC
input_image = layers.Input(shape=(im_height, im_width, 3), dtype="float32") # output(None, 224, 224, 3)
x = layers.ZeroPadding2D(((1, 2), (1, 2)))(input_image) # output(None, 227, 227, 3)
x = layers.Conv2D(48, kernel_size=11, strides=4, activation="relu")(x) # output(None, 55, 55, 48)
x = layers.MaxPool2D(pool_size=3, strides=2)(x) # output(None, 27, 27, 48)
x = layers.Conv2D(128, kernel_size=5, padding="same", activation="relu")(x) # output(None, 27, 27, 128)
x = layers.MaxPool2D(pool_size=3, strides=2)(x) # output(None, 13, 13, 128)
x = layers.Conv2D(192, kernel_size=3, padding="same", activation="relu")(x) # output(None, 13, 13, 192)
x = layers.Conv2D(192, kernel_size=3, padding="same", activation="relu")(x) # output(None, 13, 13, 192)
x = layers.Conv2D(128, kernel_size=3, padding="same", activation="relu")(x) # output(None, 13, 13, 128)
x = layers.MaxPool2D(pool_size=3, strides=2)(x) # output(None, 6, 6, 128)
x = layers.Flatten()(x) # output(None, 6*6*128)
x = layers.Dropout(0.2)(x)
x = layers.Dense(2048, activation="relu")(x) # output(None, 2048)
x = layers.Dropout(0.2)(x)
x = layers.Dense(2048, activation="relu")(x) # output(None, 2048)
x = layers.Dense(num_classes)(x) # output(None, 5)
predict = layers.Softmax()(x)
model = models.Model(inputs=input_image, outputs=predict)
return model
class AlexNet_v2(Model):
def __init__(self, num_classes=1000):
super(AlexNet_v2, self).__init__()
self.features = Sequential([
layers.ZeroPadding2D(((1, 2), (1, 2))), # output(None, 227, 227, 3)
layers.Conv2D(48, kernel_size=11, strides=4, activation="relu"), # output(None, 55, 55, 48)
layers.MaxPool2D(pool_size=3, strides=2), # output(None, 27, 27, 48)
layers.Conv2D(128, kernel_size=5, padding="same", activation="relu"), # output(None, 27, 27, 128)
layers.MaxPool2D(pool_size=3, strides=2), # output(None, 13, 13, 128)
layers.Conv2D(192, kernel_size=3, padding="same", activation="relu"), # output(None, 13, 13, 192)
layers.Conv2D(192, kernel_size=3, padding="same", activation="relu"), # output(None, 13, 13, 192)
layers.Conv2D(128, kernel_size=3, padding="same", activation="relu"), # output(None, 13, 13, 128)
layers.MaxPool2D(pool_size=3, strides=2)]) # output(None, 6, 6, 128)
self.flatten = layers.Flatten()
self.classifier = Sequential([
layers.Dropout(0.2),
layers.Dense(1024, activation="relu"), # output(None, 2048)
layers.Dropout(0.2),
layers.Dense(128, activation="relu"), # output(None, 2048)
layers.Dense(num_classes), # output(None, 5)
layers.Softmax()
])
def call(self, inputs, **kwargs):
x = self.features(inputs)
x = self.flatten(x)
x = self.classifier(x)
return x
————————————————————————————————————————————————————————————————————————-
pytorch实现-reference:
https://github.com/dansuh17/alexnet-pytorch
https://github.com/sloth2012/AlexNet