数据挖掘:数据清洗——数据不平衡处理
数据挖掘:数据清洗——数据不平衡处理
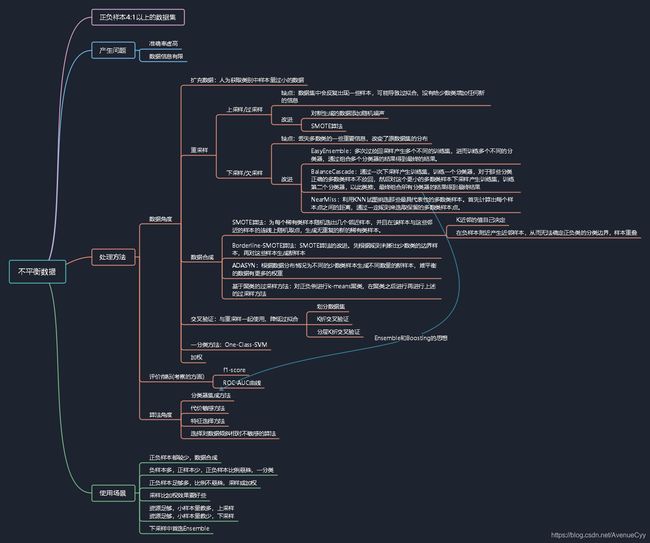
一、什么是数据不平衡?
不平衡数据集指的是数据集各个类别的样本数目相差巨大,也叫数据倾斜。以二分类问题为例,即正类的样本数量远大于负类的样本数量。严格地讲,任何数据集上都有数据不平衡现象,一点的差异不会引起太多的影响,我们只关注那些分布差别比较悬殊的。
关于分布悬殊:如果类别不平衡比例超过4:1,那么其分类器会大大地因为数据不平衡性而无法满足分类要求的。因此在构建分类模型之前,需要对分类不均衡性问题进行处理。
不平衡数据的学习即需要在分布不均匀的数据集中学习到有用的信息。
二、不平衡数据例子
① 在二分类问题中,训练集中class 1的样本数比上class 2的样本数的比值为60:1。使用逻辑回归进行分类,最后结果是其忽略了class 2,将所有的训练样本都分类为class 1。
② 在三分类问题中,三个类别分别为A,B,C,训练集中A类的样本占70%,B类的样本占25%,C类的样本占5%。最后我的分类器对类A的样本过拟合了,而对其它两个类别的样本欠拟合。
生活中的案例:不平衡数据的场景出现在互联网应用的方方面面,如搜索引擎的点击预测(点击的网页往往占据很小的比例)、电子商务领域的商品推荐(推荐的商品被购买的比例很低)、信用卡欺诈检测(欺诈交易的应该是很少部分,即绝大部分交易是正常的,只有极少部分的交易属于欺诈交易)、网络攻击识别、癌症检测等等。
三、不平衡数据产生的问题
- 准确率虚高:不平衡的数据集上做训练和测试,其得到的准确率是虚高的。比如在不平衡数据中,正负样本的比例为9:1时,当它的精度为90%时,模型预测倾向于把样本分类为多数类。导致训练效率低下。
- 数据信息有限:少数类所包含的信息就会很有限,从而难以确定少数类数据的分布,即在其内部难以发现规律,进而造成少数类的识别率低
四、不平衡数据的处理方法
不平衡数据的处理主要可从三个方面进行考虑:
①数据角度:改变训练集样本分布 ,降低不平衡程度 。主要方法为采样,分为欠采样和过采样以及对应的一些改进方法。从数据角度出发的不平衡数据集的处理方法对应的python库是imblearn。另外可以将不平衡数据集的问题考虑为一分类(One Class Learning)或者异常检测(Novelty Detection)问题,代表的算法有One-class SVM。
②评价指标:不单单看Accuracy,从多角度对数据进行评价,如f1,AUC等。是一种可对不平衡数据考察的方面,不能解决数据不平衡问题。
③算法角度:适当地修改算法使之适应不平衡分类问题。考虑不同误分类情况代价的差异性对算法进行优化,主要是基于代价敏感学习算法(Cost-Sensitive Learning),代表的算法有adacost。
4.1 数据角度
4.1.1 扩充数据
人为获取类别中样本量过小的数据,更多的数据往往能得到更多的分布信息。
4.1.2 重采样
重采样方法是通过**增加稀有类训练样本数的上采样 (up-sampling)和减少大类样本数的下采样(down-samplings)**使不平衡的样本分布变得比较平衡,从而提高分类器对稀有类的识别率 。
4.1.2.1 上采样/过采样
上采样:从少数类的样本中进行随机采样来增加新的样本,改变训练数据的分布来消除或减小数据的不平衡。
from imblearn.over_sampling import RandomOverSampler
ros=RandomOverSampler(random_state=0) #采用随机过采样(上采样)
x_resample,y_resample=ros.fit_sample(trainset,labels)
缺点:数据集中会反复出现一些样本,可能导致过拟合,没有给少数类增加任何新的信息。
改进:
- 上采样会把小众样本复制多份,一个点会在高维空间中反复出现,这会导致一个问题,那就是运气好就能分对很多点,否则分错很多点。为了解决这一问题,可以在每次生成新数据点时,添加随机噪声经验表明这种做法非常有效。
- 较高级的上采样方法则采用一些启发式技巧 , 有选择地复制稀有类样本 , 或者生成新的稀有类样本。SMOTE算法是一种简单有效的上采样方法,该方法首先为每个稀有类样本随机选出几个邻近样本,并且在该样本与这些邻近的样本的连线上随机取点,生成无重复的新的稀有类样本。
4.1.2.2 下采样/欠采样
下采样:通过舍弃部分大类样本的方法 , 降低不平衡程度 。
缺点:丢失多数类的一些重要信息,不能够充分利用已有的信息。另外可能增大模型的偏差,因为放大或者缩小某些样本的影响相当于改变了原数据集的分布。
改进:
- 对不同的类别也要采取不同的采样比例,但一般不会是1:1,因为与现实情况相差甚远,压缩大类的数据是个不错的选择。
- 采用更好的EasyEnsemble,BalanceCascade,NearMiss算法。
from imblearn.under_sampling import RandomUnderSampler
#通过设置RandomUnderSampler中的replacement=True参数, 可以实现自助法(boostrap)抽样
#通过设置RandomUnderSampler中的rratio参数,可以设置数据采样比例
rus=RandomUnderSampler(ratio=0.4,random_state=0,replacement=True) #采用随机欠采样(下采样)
x_resample,y_resample=rus.fit_sample(trainset,labels)
4.1.3 数据合成——上采样方法的改进
相对于采样随机的方法进行过采样, 还有两种比较流行的过采样的改进方式:
(1)、Synthetic Minority Oversampling Technique(SMOTE)
(2)、Adaptive Synthetic (ADASYN)
(3)、基于聚类的过采样方法
4.1.3.1 SMOTE算法
SMOTE全称是Synthetic Minority Oversampling Technique,即合成少数类过采样技术,SMOTE算法的基本思想是对少数类样本进行分析,并根据少数类样本人工合成新样本添加到数据集中,算法流程如下。
- 对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集Smin中所有样本的距离,得到其k近邻。
- 根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为x^。
- 对于每一个随机选出的近邻x^,分别与原样本按照如下的公式构建新的样本。
xnew=x+rand(0,1)∗(x^−x)
局限性:
- 在近邻选择时,存在一定的盲目性。在算法执行过程中,需要确定K值,即选择几个近邻样本,这个需要根据具体的实验数据和实验人自己解决。
- 该算法无法克服非平衡数据集的数据分布问题,容易产生分布边缘化的问题。由于负类样本的分布决定了其可选择的近邻,如果一个负类样本处在负类样本的边缘,则由此负类样本和近邻样本产生的样本也会处在边缘,从而无法确定正负类的分类边界,样本重叠。

from imblearn.over_sampling import SMOTE
X_resampled_smote, y_resampled_smote = SMOTE().fit_sample(X, y)
4.1.3.2 Borderline-SMOTE算法
Borderline-SMOTE与原始SMOTE不同的地方在于,原始的SMOTE是对所有少数类样本生成新样本。而改进的方法则是先根据规则判断出少数类的边界样本,再对这些样本生成新样本。
判断边界的一个简单的规则为:K近邻中有一半以上多数类样本的少数类为边界样本。直观地讲,只为那些周围大部分是多数类样本的少数类样本生成新样本。
假设a为少数类中的一个样本,此时少数类的样本分为三类,如下图所示:
(i) 噪音样本(noise), 该少数类的所有最近邻样本都来自于不同于样本a的其他类别:
(ii) 危险样本(in danger), 至少一半的最近邻样本来自于同一类(不同于a的类别);
(iii) 安全样本(safe), 所有的最近邻样本都来自于同一个类。
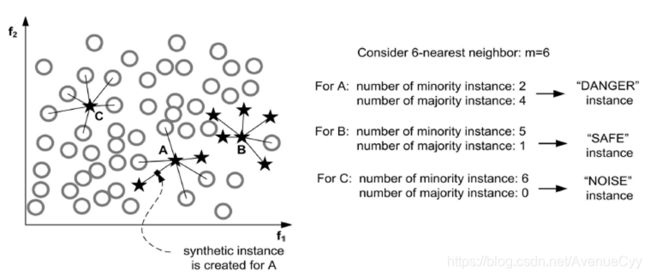
相对于基本的SMOTE算法, 关注的是所有的少数类样本, 这些情况可能会导致产生次优的决策函数, 因此SMOTE就产生了一些变体: 这些方法关注在最优化决策函数边界的一些少数类样本, 然后在最近邻类的相反方向生成样本.
SMOTE函数中的kind参数控制了选择哪种变体, (i) borderline1, (ii) borderline2, (iii) svm:
borderline1:最近邻中的随机样本与该少数类样本a来自于不同的类;
borderline2:最近邻中的随机样本可以是属于任何一个类的样本;
svm:使用支持向量机分类器产生支持向量然后再生成新的少数类样本。
具体实现如下:
from imblearn.under_sampling import ClusterCentroids
cc = ClusterCentroids(random_state=0)
X_resampled, y_resampled = cc.fit_sample(X, y)
4.1.3.3 ADASYN
ADASYN根据数据分布情况为不同的少数类样本生成不同数量的新样本,为样本较少的类生成合成数据。基本思想是根据平衡程度的不同,对不同的少数类的样本使用加权分布。其中,更难平衡的少数类样本比那些更容易学习的少数类的样本要产生更多的合成数据(为每个少数类样本x计算分布比例)。因此,ADASYN方法通过以下两种方式改善了数据分布的学习:
(1)减少由于类别不平衡带来的偏差;
(2)自适应地将分类决策边界转移到困难的例子。
from imblearn.over_sampling import ADASYN
X_resampled_adasyn, y_resampled_adasyn = ADASYN().fit_sample(X, y)
4.1.3.4 基于聚类的过采样方法
以二分类为例,该方法是首先分别对正负例进行聚类,在聚类之后进行再进行上述的过采样方法。例如:有一个二分类数据集,其正负类比例为:1000:50。
- 首先通过k-means算法对正负类分别聚类,得到正类:600,300,100;负类:30,20。
- 然后使用过采样的方法分别对所有类别进行过采样得到正类:600,600,600;对于负类的上采样个数为:(600+600+600)/2 = 900,即负类为:900,900。最终得到的数据集为正类1800,负类1800。
基于聚类的过采样方法的优点是不仅可以解决类间不平衡问题,而且还能解决类内部不平衡问题。
4.1.4 下采样方法的改进
随机欠采样的问题主要是信息丢失,为了解决信息丢失的问题提出了以下几种改进的方式:
4.1.4.1 EasyEnsemble
EasyEnsemble,利用模型融合的方法(Ensemble):多次过采样(放回采样,这样产生的训练集才相互独立)产生多个不同的训练集,进而训练多个不同的分类器,通过组合多个分类器的结果得到最终的结果。
简单的最佳实践是建立n个模型,每个模型使用少数类的所有样本和多数类的n个不同样本。假设二分类数据集的正负类比例为50000:1000,最后要得到10个模型,那么将保留负类的1000个样本,并随机采样得到10000个正类样本。然后,将10000个样本成10份,每一份与负类样本组合得到新的子训练集,训练10个不同的模型。拆分正类样本。
from imblearn.ensemble import EasyEnsemble
ee = EasyEnsemble(random_state=0, n_subsets=10)
X_resampled, y_resampled = ee.fit_sample(X, y)
4.1.4.2 BalanceCascade
BalanceCascade,利用增量训练的思想(Boosting)。先通过一次下采样产生训练集,训练一个分类器,对于那些分类正确的多数类样本不放回,然后对这个更小的多数类样本下采样产生训练集,训练第二个分类器,以此类推,最终组合所有分类器的结果得到最终结果。
from imblearn.ensemble import BalanceCascade
from sklearn.linear_model import LogisticRegression
bc = BalanceCascade(random_state=0,
estimator=LogisticRegression(random_state=0),
n_max_subset=4)
X_resampled, y_resampled = bc.fit_sample(X, y)
4.1.4.3 NearMiss
NearMiss,利用KNN试图挑选那些最具代表性的多数类样本。首先计算出每个样本点之间的距离,通过一定规则来选取保留的多数类样本点。因此该方法的计算量通常很大。
from imblearn.under_sampling import NearMiss
nm1 = NearMiss(random_state=0, version=1)
X_resampled_nm1, y_resampled = nm1.fit_sample(X, y)
4.1.5 交叉验证
4.1.5.1 划分数据集
划分数据仅将其随机划分,效果 有很大的随机性,无法保证数据划分后,解决了数据不平衡问题。
from collections import Counter
from sklearn.model_selection import train_test_split #数据集划分
#参数test_size表示数据集和测试集的划分比例
x_train,x_test,y_train,y_test = train_test_split(datasets,labels,test_size=0.1,random_state=0)
4.1.5.2 K折交叉验证
在k折交叉验证中,我们不重复地随机将训练数据集划分为k个,其中k-1个用于模型的训练,剩余的1个用于测试。重复此过程k次,每次实验都从K个部分中选择一个不同的部分作为测试数据,剩余的数据作为训练数据进行实验,最后把得到的K个实验结果平均,就得到了k个模型及对模型性能的评价。
k折交叉验证的一个特例就是留一(leave-one-out,LOO)交叉验证法。在LOO中,我们将数据子集划分的数量等同于样本数(k=n),这样每次只有一个样本用于测试。当数据集非常小时,建议使用此方法进行验证。
注意:使用过采样方法来解决不平衡问题时应适当地应用交叉验证。这是因为过采样会观察到罕见的样本,并根据分布函数应用自举生成新的随机数据,如果在过采样之后应用交叉验证,那么我们所做的就是将我们的模型过拟合于一个特定的人工引导结果。这就是为什么在过度采样数据之前应该始终进行交叉验证,就像实现特征选择一样。只有重复采样数据可以将随机性引入到数据集中,以确保不会出现过拟合问题。
比直接划分数据效果要好,降低了随机性。但没有考虑到数据类别的问题。
from sklearn.model_selection import KFold #交叉验证
import numpy as np
kf=KFold(n_splits=10)
for train_index,test_index in kf.split(datasets,labels):
x_train = np.array(datasets)[train_index]
y_train = np.array(datasets)[train_index]
x_test = np.array(datasets)[test_index]
y_test = np.array(labels)[test_index]
4.1.5.3 分层k折交叉验证
分层k折交叉验证对标准k折交叉验证做了稍许改进,它可以获得偏差和方差都较低的评估结果,特别是类别比例相差较大时。在分层交叉验证中,类别比例在每个分块中得以保持,这使得每个分块中的类别比例与训练数据集的整体比例一致。但仍然是处于非平衡数据的状态。
from sklearn.model_selection import StratifiedKFold #分层k折交叉验证
import numpy as np
kf = StratifiedKFold(n_splits=10, shuffle=True)
for train_index, test_index in kf.split(datasets, labels):
x_train = np.array(datasets)[train_index]
y_train = np.array(datasets)[train_index]
x_test = np.array(datasets)[test_index]
y_test = np.array(labels)[test_index]
4.1.6 一分类方法
对于二分类问题,如果正负样本分布比例极不平衡,我们可以换一个完全不同的角度来看待问题:把它看做一分类(One Class Learning)或异常检测(Novelty Detection)问题。这类方法的重点不在于捕捉类间的差别,而是为其中一类进行建模,经典的工作包括One-class SVM等,如下图所示:
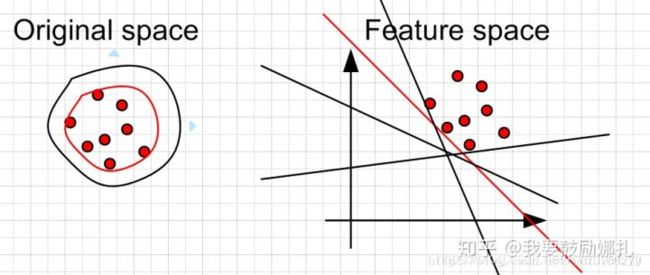
One Class SVM 是指你的训练数据只有一类正(或者负)样本的数据, 而没有另外的一类。在这时,你需要学习的实际上你训练数据的边界。而这时不能使用最大化软边缘了,因为你没有两类的数据。 所以,假设最好的边缘要远离特征空间中的原点。左边是在原始空间中的边界,可以看到有很多的边界都符合要求,但是比较靠谱的是找一个比较紧的边界(红色的)。这个目标转换到特征空间就是找一个离原点比较远的边界,同样是红色的直线。当然这些约束条件都是人为加上去的,你可以按照你自己的需要采取相应的约束条件。比如让你data 的中心离原点最远。
说明:对于正负样本极不均匀的问题,使用异常检测,或者一分类问题,也是一个思路。
4.1.7 加权
除了采样和生成新数据等方法,我们还可以通过加权的方式来解决数据不平衡问题,即对不同类别分错的代价不同,如下图:
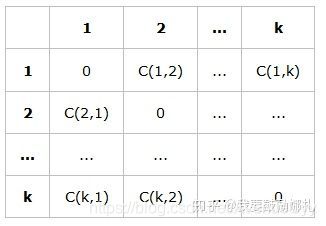
横向是真实分类情况,纵向是预测分类情况,C(i,j)是把真实类别为j的样本预测为i时的损失,我们需要根据实际情况来设定它的值。
这种方法的难点在于设置合理的权重,实际应用中一般让各个分类间的加权损失值近似相等。当然这并不是通用法则,还是需要具体问题具体分析。
4.2 小结
方法选择:解决数据不平衡问题的方法有很多,上面只是一些最常用的方法,而最常用的方法也有这么多种,如何根据实际问题选择合适的方法呢?接下来谈谈一些我的经验。
- 在正负样本都非常之少的情况下,应该采用数据合成的方式,例如SMOTE算法和Borderline-SMOTE算法;
- 在负样本足够多,正样本非常之少且比例及其悬殊的情况下,应该考虑一分类方法;
- 在正负样本都足够多且比例不是特别悬殊的情况下,应该考虑采样或者加权的方法。
- 采样和加权在数学上是等价的,但实际应用中效果却有差别。尤其是采样了诸如Random Forest等分类方法,训练过程会对训练集进行随机采样。在这种情况下,如果计算资源允许上采样往往要比加权好一些。
- 另外,虽然上采样和下采样都可以使数据集变得平衡,并且在数据足够多的情况下等价,但两者也是有区别的。实际应用中,我的经验是如果计算资源足够且小众类样本足够多的情况下使用上采样,否则使用下采样,因为上采样会增加训练集的大小进而增加训练时间,同时小的训练集非常容易产生过拟合。
- 对于下采样,如果计算资源相对较多且有良好的并行环境,应该选择Ensemble方法。
注意:在选择采样法事需要注意一个问题,如果你的实际数据是数据不平衡的,在训练模型时发现效果不好,于是采取了采样法平衡的数据的比例再来进行训练,然后去测试数据上预测,这个时候算法的效果是否会有偏差呢?此时你的训练样本的分布与测试样本的分布已经发生了改变,这样做反而会产生不好的效果。在实际情况中,我们尽可能的需要保持训练和测试的样本的概率分布是一致的,如果测试样本的分布是不平衡的,那么训练样本尽可能与测试样本的分布保持一致,哪怕拿到手的是已经清洗和做过预处理后的平衡的数据。
4.2评价指标
在数据平衡的分类问题中,分类器好坏的评估指标常用准确率,但是对于数据不平衡的分类问题,准确率不再是恰当的评估指标。所以针对不平衡数据分类问题,常用f1-score、ROC-AUC曲线。
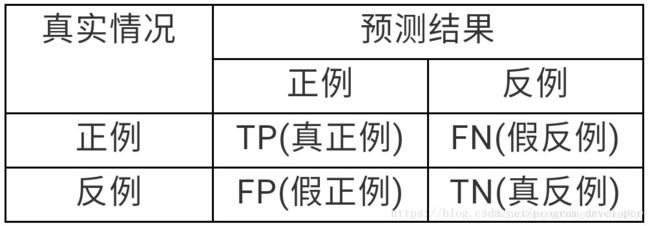
f1-score计算公式:
TP:将正类预测为正类
FN:将正类预测为负类
FP:将负类预测为正类
TN:将负类预测为负类

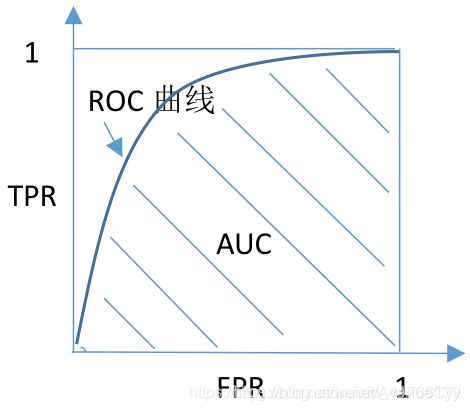
ROC-AUC曲线:
ROC曲线的x轴是FPR(假阳性率)、y轴是TPR(真阳性率、召回率)
AUC是ROC曲线与x轴所围成的面积

关于分类评估指标的具体描述,会在以后的总结文章中提到。
4.2.1 谨慎选择AUC作为评价指标:
对于数据极端不平衡时,可以观察观察不同算法在同一份数据下的训练结果的precision和recall,这样做有两个好处,
- 可以了解不同算法对于数据的敏感程度,
- 可以明确采取哪种评价指标更合适。
针对机器学习中的数据不平衡问题,建议更多PR(Precision-Recall曲线),而非ROC曲线,具体原因画图即可得知,如果采用ROC曲线来作为评价指标,很容易因为AUC值高而忽略实际对少两样本的效果其实并不理想的情况。
4.2.2 不要只看Accuracy:
Accuracy可以说是最模糊的一个指标了,因为这个指标高可能压根就不能代表业务的效果好,在实际生产中,我们可能更关注precision/recall/mAP等具体的指标,具体侧重那个指标,得结合实际情况看。
4.3算法角度
4.3.1 分类器集成方法
首先从多数类中独立随机抽取出若干子集,将每个子集与少数类数据联合起来训练生成多个基分类器,再加权组成新的分类器,如加法模型、Adaboost、随机森林等。
将boosting算法与 SMOTE算法结合成SMOTEBoost算法 , 该算法每次迭代使用SMOTE生成新的样本 ,取代原有 AdaBoost算法中对样本权值的调整, 使得Boosting算法专注于正类中的难分样本。
4.3.2 代价敏感方法
在大部分不平衡分类问题中 , 稀有类是分类的重点 .在这种情况下 , 正确识别出稀有类的样本比识 别大类的样本更有价值 .反过来说 , 错分稀有类的样 本需要付出更大的代价 .代价敏感学习赋予各个类别不同的错分代价 , 它能很好地解决不平衡分类 问题 .以两类问题为例 , 假设正类是稀有类 , 并具有 更高的错分代价 , 则分类器在训练时 , 会对错分正类 样本做更大的惩罚 , 迫使最终分类器对正类样本有更高的识别率 .如Metacost和Adacost等算法。
代价敏感学习能有效地提高稀有类的识别率 . 但问题是 , 一方面 , 在多数情况下 , 真实的错分代价 很难被准确地估计.另一方面,虽然许多分类器 可以直接引入代价敏感学习机制 , 如支持向量机和 决策树 , 但是也有一些分类器不能直接使用代价敏感学习 , 只能通过调整正负样本比例或者决策阈值间接的实现代价敏感学习,这样不能保证代价敏感学习的效果。
4.3.3 特征选择方法
特征选择方法对于不平衡分类问题同样具有重要意义 .样本数量分布很不平衡时,特征的分布同样会不平衡.尤其在文本分类问题中,在大类中经常出现的特征,也许在稀有类中根本不出现 .因此 ,根据不平衡分类问题的特点 , 选取最具有区分能力的特征 ,有利于提高稀有类的识别率 .
4.3.4 选择对数据倾斜相对不敏感的算法。
如树模型等。
五、参考文献
https://blog.csdn.net/asialee_bird/article/details/83714612
https://blog.csdn.net/heyongluoyao8/article/details/49408131
https://zhuanlan.zhihu.com/p/88107139
https://blog.csdn.net/Polaris47/article/details/89361043
https://blog.csdn.net/shine19930820/article/details/54143241
https://www.cnblogs.com/kamekin/p/9824294.html
https://www.jianshu.com/p/f170d72f6fb6
https://blog.csdn.net/lujiandong1/article/details/52658675
https://www.cnblogs.com/charlotte77/p/10455900.html
https://blog.csdn.net/guhongpiaoyi/article/details/73693868
Imblearn包的使用