【机器学习】浅谈 Transformer 在 CV 中能否取代 CNN
- 原作:罗浩.ZJU
- 原文:如何看待Transformer在CV上的应用前景,未来有可能替代CNN吗? - 知乎
Transformer 的较好特性使之在 NLP 任务上取得了巨大成功。Transformer 前几年在 CV 领域主要被用于 Sequence 信息挖掘,例如一些 Video 任务中将 Transformer 接在 CNN 特征后以进行时序特征融合,当时 Transformer 还在本职范围内。不过去年的 ViT 论文扩大了 Transformer 的使用范围,但 Visual Transformer 在未来能否替代 CNN 还真不好说。
Visual Transformer 具有如下较好的特性:
- Long Range 带来的全局特性。一方面,CNN 的 Conv 算子存在感受野较局限的问题,为扩大网络的关注区域,需多层堆叠卷积-池化结构,但随之带来的问题是 “有效/真实” 感受野以某个中心为原点向外高斯衰减,因此 CNN 通常的有效 Attention 就是图中某一两个较重要的 Parts。为解决该问题,可设计用于 CNN 的 Attention Module 来得到感受野范围更大而均衡的 Attention Map,其有效性得到了很多工作的证明。另一方面,Transformer 天然自带的 Long Range 特性 (自注意力带来的全局感受野) 使得从浅层到深层特征图,都较能利用全局的有效信息,并且 Multi-Head 机制保证了网络可关注到多个 Discriminative Parts (每个 Head 都是一个独立的 Attention),这是 Transformer 与 CNN主要区别之一。
- 更好的多模态融合能力。一方面,CNN 擅长解构图像的信息,因为 CNN 卷积核卷积运算的本质就是传统数字图像处理中的滤波操作,但这也使得 CNN 不擅长融合其他模态的信息,例如文本、标签、语音、时间等。通常需要用 CNN 提取图像特征 (Feature Embedding),再用其他模型对其他信息进行 Embedding (如文本的 Token Embedding),最后在网络末端融合多模态的 Embeddings (后融合)。另一方面,Transformer 可在网络的输入端融合多模态信息 (前融合),例如,对于图像,可把对图像通过 Conv 或直接对像素操作得到的初始 Embeddings 馈入 Transformer 中,而 无需始终保持 H×W×C 的 Feature Map 结构。类似于 Position Embedding,只要能编码的信息,都可以非常轻松地利用进来。
- Multiple Tasks 能力。不少工作证明一个 Transformer 可执行很多任务,因为其 Attention 机制可让网络对不同的 Task 进行不同的学习,一个简单的用法便是加一个 Task ID 的 Embedding。
- 更好的表征能力。不少工作显示 Transformer 可在多个 CV 任务上取得 SOTA 结果。
Visual Transformer 还有几处可做得更好:
- 计算效率。毫无疑问,目前 Transformer 还无法替代 CNN 的一个重要原因就是计算效率,目前 CV 领域还是直接套用NLP 中的 Transformer 结构,而较少地对 CV 数据做专门的设计,然而图像/视频的信息量远大于文本,所以目前 Transformer 的计算开销依然很大。当然 ViT 之后,已经陆续有工作开始设计更加适配 CV 的 Transformer 结构,估计这一个领域也是目前非常火热的领域,未来应该会有不少工作出来。
- 应用适配。除基础网络结构的改进,需要推动 Transformer 在 CV 上的发展,还需要很多 CV 下游任务上的成功。这个看起来有点像把 Transformer 替换掉 CNN,在各个 CV 任务上重新做一篇以前的事。不过实际上不是替换掉 CNN Backbone 那么简单,首先 Transformer 的训练有自己的特性,得去把 Transformer 啃烂才更可能取得成功。二来要利用 Transformer 的特性对于 CV 任务进行专门的改进,让大家看到 Transformer 比 CNN 做的更好的地方。
- 硬骨头的突破。CNN 已在很多 CV 任务取得了成功,但是依然有一些任务没有完全克服,比如 Video 的一些任务,识别率还无法达到人脸、识别、检测这种精度。
总体而言,Transformer 是 NLP 给 CV 的一个输出,我们可以去学习 Transformer 的长处,至于未来是否会替换 CNN,或者Transformer 与 CNN 共存,甚至互相弥补,这个还是靠整个学界去决定。CV 的任务很多很难,无论是 CNN 还是 Transformer 都不会是 CV 的终点,保持学习、保持接纳、保持探究。
- 原作:曹越
- 原文:如何看待Transformer在CV上的应用前景,未来有可能替代CNN吗? - 知乎
在 Attention is all you need 一文出现后,就一直在思考一个问题:从建模的基本单元来看,Self-attention Module 到底在 CV 能做什么?从现在回头看,主要尝试的就是两个方向:
- 作为 Convolution 的补充。绝大多数工作基本上都是从这个角度出发的,比如 Relation Networks、Non-local Networks、DETR,以及后来的一大批改进和应用。其中一部分是从 Long-range Dependency 引入,某种程度上是在弥补 Convolution is too local;另一部分是从关系建模引入,例如建模物体之间或物体与像素之间的关系,也是在做一些 Conv 做不了的事。
- 替代 Convolution。在这个方向上尝试不多,早期有 LocalRelationNet、Stand-alone Self-attention Net。如果仅看结果,这些工作基本上已经可以做到替换掉 3x3 Conv 不掉点,但有一个通病就是速度慢,即使是写 Kernel 依然抵不过对 Conv 的强大优化,导致这一类方法在当时并没有成为主流。
到 2020 年左右,我自己其实有一种到了瓶颈期的感觉,作为 Conv 的补充好像做的差不多了,后续的工作也都大同小异,替代 Conv 因为速度的问题难以解决而遥遥无期。
没想到的是,Vision Transformer(ViT) 在 2020 年 10 月横空出世。
ViT 的出现改变了很多固有认知,我的理解主要有两点:1. Locality (局部性);2. Translation Invariance (平移不变性)。从模型本身的设计角度,ViT 并不直接具有这两个 CNN 的归纳偏置性质,但是它依然可以 Work 的很好,虽然需要大数据集。但 DeiT 通过尝试各种 Tricks 使得 ViT 可以只需要 ImageNet-1k 就可以取得非常不错的性能,使得直接上手尝试变得没那么昂贵。
其实对 ViT 的 Accuracy 我个人不是特别惊讶,一方面是因为之前在 Local Relation 那一系列已经证明了 Self-attention 有替代 Conv 的能力,另一方面是因为 19 年 ICLR 有一篇 paper 叫 BagNet,证明了直接切 Patch 过网络,在网络中间 Patch 之间没有交互,最后接一个 Pooling 再做 Classification,结果也已经不错了,在这个的基础上加上 Self-attention 效果更好是可以理解的。
我个人其实惊讶于 ViT/DeiT 的 Latency / Acc Curve,在 Local Relation Net 里速度是最大的瓶颈,为什么 ViT 可以速度这么快?仔细对比 ViT 与 Local Relation 可以发现,这里一个很大的区别是,ViT 中不同的 Query 是 Share Key Set 的,这会使得内存访问非常友好而大幅度提速。一旦解决了速度问题,Self-attention Module 在替代 Conv 的过程中就没有阻力了。
基于这些理解,我们组提出了一个通用的视觉骨干网络,Swin Transformer。
- 之前的ViT中,由于 Self-attention 是全局计算的,所以在图像分辨率较大时不太经济。由于 Locality 一直是视觉建模里非常有效的一种 Inductive Bias,所以我们将图片切分为 无重合的 Windows,然后在 Local Window 内进行 Self-attention 的计算。为了让 Windows 之间有信息交换,我们在相邻两层使用不同的 Windows 划分 (Shifted Window)。
- 图片中的物体大小不一,而 ViT 中使用固定的 Scale 进行建模或许对下游任务例如目标检测而言不是最优的。在这里我们还是 Follow 传统 CNN 构建了一个 层次化的 Transformer 模型,从 4x 逐渐降分辨率到 32x,这样也可以在任意框架中无缝替代之前的 CNN 模型。
Swin Transformer 的这些特性使其可直接用于多种视觉任务,包括图像分类 (ImageNet-1K 中取得 86.4 top-1 acc)、目标检测(COCO test-dev 58.7 box AP和51.1 mask AP) 和语义分割 (ADE20K 53.5 val mIoU,并在其公开benchmark中排名第一),其中在 COCO 目标检测与 ADE20K 语义分割中均为 SOTA。
- 原作:小小将
- 原文:如何看待Transformer在CV上的应用前景,未来有可能替代CNN吗? - 知乎
1. CNN 是通过不断地堆积卷积层来完成对图像从局部信息到全局信息的提取,不断堆积的卷积层慢慢地扩大了感受野直至覆盖整个图像。但 Transformer 并不假定从局部信息开始,而是 一开始就可以拿到全局信息,学习难度更大一些,但 Transformer 学习长依赖的能力更强。另外,从 ViT 的分析来看,前面层的 “感受野” (论文里是 Mean Attention Distance) 虽迥异但总体较小,后面层的 “感受野“ 越来越大,这说明 ViT 也学习到了和 CNN 相同的范式。没有 “受限” 的 Transformer 一旦完成好学习,势必会发挥自己这种优势。
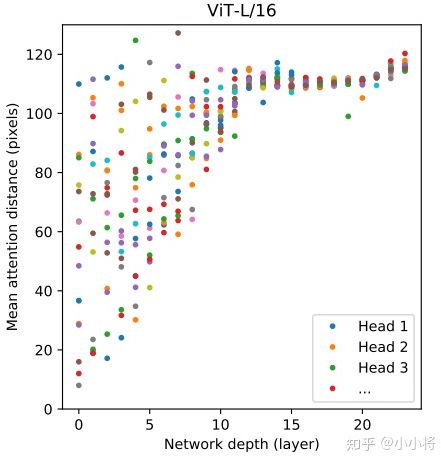
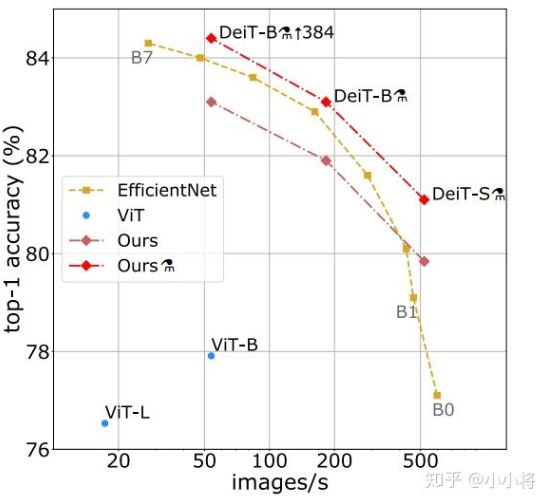
2. CNN 对图像问题有天然的 Inductive Bias,如平移不变性等以及 CNN 的仿生学特性,这让 CNN 在图像问题上更容易;相比之下,Transformer 没有这个天然优势,那么学习的难度很大,往往需要 更大的数据集 (ViT) 或 更强的数据增强 (DeiT) 来达到较好的训练效果。好在 Transformer 的迁移效果更好,大数据集上的 Pretrained 模型可以很好地迁移到小数据集上。还有一个就是 ViT 所说的,Transformer 的 Scaling 能力 很强,那么进一步 提升参数量 或许会带来更好的效果 (就像惊艳的GPT模型)。
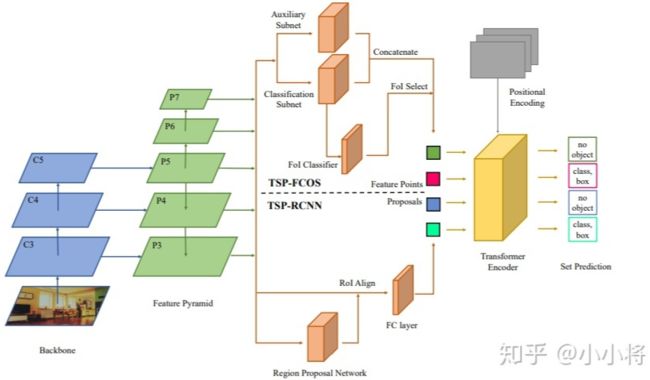
3. 目前我们还看到很大一部分工作还是把 Transformer 和现有的 CNN 工作结合在一起,如 ViT 其实也是有 Hybrid Architecture (将由 ResNet 提取的特征图馈入 ViT 而非原始图像)。而对于检测和分割这类问题,CNN 方法已经很成熟,难以用 Transformer 一下子完全替换掉。目前的工作大都是 CNN 和 Transformer 的混合体,这其中有速度和效果的双重考虑。另外,也要考虑到 如果输入较大分辨率的图像,Transformer 的计算量会很大,所以 ViT 的输入并不是 Pixel,而是小 Patch。对于 DETR,其 Transformer Encoder 的输入是 1/32 特征 都有计算量的考虑,不过这肯定是有效果的影响,所以才有后面的改进工作 Deformable DETR。短期内,CNN 和 Transformer 仍会携手同行。论文 Rethinking Transformer-based Set Prediction for Object Detection 还是把现有的 CNN 检测模型和 Transformer 思想结合在一起实现了比 DETR 更好的效果 (训练收敛速度也更快):
4. 我想到了神经网络的本质:一个复杂的非线性系统来拟合问题。无论是 CNN,RNN 或 Transformer 都是对问题一种拟合罢了,也没有孰优孰劣。就一个受限的问题来看,可能有个高低之分,但我相信随着 数据量的增加,问题的效果可能最终取决于 模型的计算量和参数,而不是模型是哪个,因为之前的工作已经证明:一个三层神经网络可以逼近任何一个非线性函数,前提是 参数足够大,而且更重要的是你找到一个 好的训练方法。