文本纠错--CRASpell模型
文本纠错–CRASpell模型
CRASpell: A Contextual Typo Robust Approach to Improve Chinese Spelling Correction 这篇论文是发表于22年ACL,在Chinese spelling correction (CSC)任务上是SOTA。基于bert预训练模型的CSC的模型有两个极限:
(1) 在多错误文本上模型效果不好,通常在拼写错误的文本,拼写错误字符至少出现1次,这会带来噪声,这种噪声文本导致多错字文本的性能下降。
(2) 由于bert掩码任务,这些模型过度校正偏向于高频词的有用表达词。
CRASpell模型每一个训练样本构建一个有噪声的样本,correct 模型基于原始训练数据和噪声样本输出更相似的输出,为了解决过度校正问题,结合了复制机制来使得我们的模型在错误校正和输入字符根据给定上下文都有效时选择输入字符。
文章地址为:文章
代码地址为:code
模型
任务描述
中文拼写纠错的目的是检测和纠正文本中的拼写错误。通常表述为 X = { x 1 , x 2 , … , x n } \Large\boldsymbol{X} = \{x_{1}, x_{2}, \dots, x_{n}\} X={x1,x2,…,xn}是长度为 n n n的包含拼写错误的文本, Y = { y 1 , y 2 , … , y n } \Large\boldsymbol{Y} = \{y_{1}, y_{2}, \dots, y_{n}\} Y={y1,y2,…,yn}是长度为 n n n的正确文本,模型输入 X \Large\boldsymbol{X} X生成正确的文本 Y \Large\boldsymbol{Y} Y.
CRASpell 模型

左边是Correction模型,右边是Noise模型,下面详细介绍模型。
(1) Correction Module
给定输入文本 X = { x 1 , x 2 , … , x n } \Large\boldsymbol{X} = \{x_{1}, x_{2}, \dots, x_{n}\} X={x1,x2,…,xn}得到embedding 向量 E = { e 1 , e 2 , … , e n } \Large\boldsymbol{E} = \{e_{1}, e_{2}, \dots, e_{n}\} E={e1,e2,…,en},其中每一个字符 x i x_{i} xi对应的embedding向量记为 e i e_{i} ei,将 E \Large\boldsymbol{E} E输入到Transformer Encoder中得到hidden state matrix H = { h 1 , h 2 , … , h n } \Large\boldsymbol{H} = \{h_{1}, h_{2}, \dots, h_{n}\} H={h1,h2,…,hn},其中 h i ∈ R 768 h_{i}\in\Large\boldsymbol{R}^{768} hi∈R768是字符 x i x_{i} xi经过Transformer Encoder得到特征。
(2) Generative Distribution
X = { x 1 , x 2 , … , x n } \Large\boldsymbol{X} = \{x_{1}, x_{2}, \dots, x_{n}\} X={x1,x2,…,xn}经过Transformer Encoder得到特征向量 H = { h 1 , h 2 , … , h n } \Large\boldsymbol{H} = \{h_{1}, h_{2}, \dots, h_{n}\} H={h1,h2,…,hn},经过一个前向线性层和一个softmax层得到每个一字符token的生成概率,公式如下:
p g = s o f t m a x ( W g h i + b g ) p_{g} = softmax(W_{g}h_{i} + b_{g}) pg=softmax(Wghi+bg)
其中 W g ∈ R n v × 768 W_{g}\in \Large\boldsymbol{R}^{n_{v}\times768} Wg∈Rnv×768, b g ∈ R 768 b_{g}\in \Large\boldsymbol{R}^{768} bg∈R768, n v n_{v} nv是预训练模型词表的大小。
(3) Copy Distribution
x i x_{i} xi的copy distribution p c ∈ { 0 , 1 } n v p_{c} \in \{0,1\}^{n_{v}} pc∈{0,1}nv是 x i x_{i} xi在字典中的 i d x ( x i ) idx(x_{i}) idx(xi)的one-hot 表示,具体表示如下:

(4) Copy Probability
Copy Probability是模型图中的Copy Block中的输出$\omega \in\Large\boldsymbol{R}$,即transformers encoder 得到的隐藏层特征向量$h_{i}$经过两个前向线性层和一个layer normalization得到$\omega$,具体公式如下:
h c = W c h f l n ( h i ) + b c h h c ′ = f l n ( f a c t ( h c ) ) ω = S i g m o i d ( W c h c ′ ) h_{c} = W_{ch}f_{ln}(h_{i}) + b_{ch} \\ h_{c}^{'} = f_{ln}(f_{act}(h_{c})) \\ \omega = Sigmoid(W_{c}h_{c}^{'}) hc=Wchfln(hi)+bchhc′=fln(fact(hc))ω=Sigmoid(Wchc′)
其中 W c h ∈ R 768 × d c W_{ch}\in\Large\boldsymbol{R}^{768\times d_{c}} Wch∈R768×dc, b c h ∈ R d c b_{ch} \in \Large\boldsymbol{R}^{d_{c}} bch∈Rdc, W c ∈ R d c × 1 W_{c}\in\Large\boldsymbol{R}^{d_{c}\times 1} Wc∈Rdc×1, f l n f_{ln} fln是layer normalization, f a c t f_{act} fact是激活函数,在代码使用的激活函数为glue.详细见代码
Copy Block输出概率 p p p结合了生成Generative Distribution p g p_{g} pg和Copy Distribution p c p_{c} pc
p = ω × p c + ( 1 − ω ) × p g p = \omega\times p_{c} + (1 - \omega)\times p_{g} p=ω×pc+(1−ω)×pg
与之前CSC模型的不同之处在于,CRASpell模型在模型最终生成输出考虑了Copy Probability p c p_{c} pc,使得模型在输入字符有效但不是最适合 BERT 时有更多机会选择输入字符,避免过度矫正。
(5) Noise Modeling Module
Noise Modeling Module通过校正模型为原始上下文和噪声上下文产生相似的分布来解决上下文错字干扰问题。 如上面模型图的右侧,Noise Modeling Module 大致分为下面几个过程:
a. 根据输入样本 X \Large\boldsymbol{X} X生成噪声上下文 X ~ \Large\widetilde{\boldsymbol{X}} X
b. 将噪声上下文 X ~ \Large\widetilde{\boldsymbol{X}} X 作为输入得到Transformer Encoder得到隐藏特征向量 H ~ \widetilde{\boldsymbol{H}} H
c. 根据隐藏特征向量 H ~ \widetilde{\boldsymbol{H}} H 生成生成分布 p g ~ \widetilde{p_{g}} pg
d. 生成分布与校正模型生成的分布相似。生成分布与校正模型生成的分布相似这个是通过minimizing the bidirectional Kullback-
Leibler divergence体现,具体公式如下:
L K L = 1 2 ( D K L ( p g ∥ p g ~ ) + D K L ( p g ~ ∥ p g ) ) \mathcal{L}_{KL} = \frac{1}{2}(\mathcal{D}_{KL}(p_{g}\Vert\widetilde{p_{g}}) + \mathcal{D}_{KL}(\widetilde{p_{g}}\Vert p_{g})) LKL=21(DKL(pg∥pg )+DKL(pg ∥pg))
备注:Noise Modeling Module仅在训练过程中出现,模型推理只使用校正网络
Noisy Block
下面介绍数据添加噪声数据。通过替换原始训练样本的字符来生成噪声样本。在替换字符的过程中只替换拼写错误字符上下文附近 d t d_{t} dt个词,如果训练样本没有拼写错误,该样本不进行替换生成噪声样本。如下图所示:
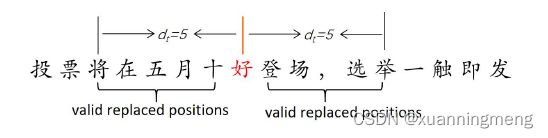
d t d_{t} dt选择实验结果

我们根据公开可用的混淆集将每个选择的位置替换为相似的字符。 具体来说,我们选取位置处的词进行替换
(i) 70% 的替换随机选择语音相似字符
(ii) 15% 的替换随机选择字形相似字符
(iii) 15% 的替换从词汇表中的随机选择。
作者提供了相同拼音汉字,字形相似以及拼音相近字这三个文件,按照上述方式从这三个文件中数据进行替换。代码如下:
def do_mask(self, input_sample, target_indice):
masked_sample = input_sample
method = self.get_mask_method()
for pos in target_indice:
if method == 'pinyin':
new_c = self.same_py_confusion.get_confusion_item_by_ids(input_sample[pos])
if new_c is not None:
masked_sample[pos] = new_c
elif method == 'jinyin':
new_c = self.simi_py_confusion.get_confusion_item_by_ids(input_sample[pos])
if new_c is not None:
masked_sample[pos] = new_c
elif method == 'stroke':
new_c = self.sk_confusion.get_confusion_item_by_ids(input_sample[pos])
if new_c is not None:
masked_sample[pos] = new_c
elif method == 'random':
new_c = self.all_token_ids[random.randint(0, self.n_all_token_ids)]
if new_c is not None:
masked_sample[pos] = new_c
return masked_sample
这里替换后是得到的tokenizer后的结果,并不是得到一个汉字字符。
Loss
给定训练样本 ( X , Y ) (\Large\boldsymbol{X}, \Large\boldsymbol{Y}) (X,Y), X \Large\boldsymbol{X} X是输入错误样本, Y \Large\boldsymbol{Y} Y是校正正确样本,每一个校正正确样本 Y i \Large\boldsymbol{Y_{i}} Yi的loss为
L c i = − log ( p ( Y i ∣ X ) ) \mathcal{L}_{c}^{i} = -\log(p(\Large\boldsymbol{Y_{i}}|\Large\boldsymbol{X})) Lci=−log(p(Yi∣X))
其中 p p p为
p = ω × p c + ( 1 − ω ) × p g p = \omega\times p_{c} + (1 - \omega)\times p_{g} p=ω×pc+(1−ω)×pg
详细见上面介绍。
模型loss为 L \mathcal{L} L
L i = ( 1 − α i ) L c i + α i L K L i \mathcal{L}^{i} = (1 - \alpha_{i})\mathcal{L}_{c}^{i} + \alpha_{i} \mathcal{L}_{KL}^{i} Li=(1−αi)Lci+αiLKLi
其中 α i \alpha_{i} αi

其中 α \alpha α是 L c \mathcal{L}_{c} Lc和 L K L \mathcal{L}_{KL} LKL的权衡因子。构建的噪声样本本身不会参与训练过程,而只会作为上下文参与。这个策略旨在确保构造的噪声数据不会改变训练语料中正负样本的比例。
实验结果
CRASpell模型实验结果
论文中使用的是拼写错误预训练模型得到的实验结果

笔者最近加载torch版的chinese-roberta-wwm-ext模型得到的结果如下:
sighan15 test data result
token num: gold_n:694, pred_n:783, right_n:586
token check: p=0.748, r=0.844, f=0.793
token correction-1: p=0.954, r=0.805, f=0.873
token correction-2: p=0.714, r=0.805, f=0.757
precision:0.7484026201754532, recall:0.8443791867735061, f1_score:0.7934992640496943
绝对准确率为0.7372。