数据挖掘——数据采集和数据清洗
数据采集和数据清洗
- 一、数据清洗
-
- 1.数据去重
-
- (一)相关知识
-
- 1> pandas读取csv文件-read_csv()
- 2> pandas的去重函数-drop_duplicates()
- (二)本关任务
- (三)参考代码
- 2.处理空值
-
- (一)相关知识
-
- 1> DataFrame中空值的表示
- 2> 查找空值及计算空值的个数
- 3> 处理空值-fillna
- (二)本关任务
- (三)参考代码
- 二、数据采集实战
-
- 1. 单网页爬取
-
- (一)相关知识
-
- 1> 爬虫简介
- 2> 网络爬虫
- 3> 网络爬虫:载入
- 4> 网络爬虫:动态载入
- 5> 网络爬虫:解析
- (二)本关任务
- (三)参考代码
- 2.网页爬取策略
-
- (一)相关知识
-
- 1> 深度优先爬虫(一路到底)
- 2> 广度优先爬虫(逐层爬取)
- (二)本关任务
- (三)参考代码
- 3.爬取与反爬取
-
- (一)相关知识
-
- 1>常见反爬手段:
- 2> 应对措施:
- (二)本关任务
- (三)参考代码
- 4.爬取与反爬取进阶
-
- (一)相关知识
- (二)本关任务
- (三)参考代码
一、数据清洗
1.数据去重
(一)相关知识
1> pandas读取csv文件-read_csv()
CSV为简单的文本格式文件,每行为一条用逗号分隔的数据。Excel保存文件时可以选择csv格式;在记事本里输入内容,保存时使用.csv扩展名,也能生成CSV文件。
只要能阅读文本文件的编辑器,就能打开CSV文件,也可以用Excel把它作为电子表格打开。现在,我们要用pandas中的read_csv函数读取csv文件中的数据。这个函数有很多参数,在本关卡和接下来的关卡中,我们将逐个介绍其中几个常用的参数。
在本关卡中,我们只需要将CSV文件的文件名作为参数即可。
import pandas as pd
a=pd.read_csv('示例数据.csv')
#此时,a就存储了示例数据.csv文件中的数据
print(a)
# 输出结果如下:
# 1 2
# 0 3 4
# 1 5 6
# 2 1 3
# 3 1 2
# 4 4 2
2> pandas的去重函数-drop_duplicates()
pandas中的drop_duplicates()函数是对DataFrame格式的数据,可以去掉特定列的重复行。
drop_duplicates()有以下参数:
subset=
用于指定需要去重的列。默认为所有列。
keep:{‘first’, ‘last’, False}. default 'first’
删除重复项时是否保留其中第一次/最后一次出现的项。keep=False时不保留重复项;默认保留第一次出现的项。
inplace: boolean, default False
是否保留被修改的数据副本。默认不保留副本。
示例代码1
result_1=a.drop_duplicates()
# 删除a中a、b列均重复的数据;保留第一次出现的重复数据;保留副本
print(result_1)
# 输出结果如下:
# a b
# 0 3 4
# 1 5 6
# 2 3 1
# 3 1 2
# 4 4 2
示例代码2
result_2=a.drop_duplicates(subset='b', inplace=True)
# 删除a中b列重复的数据;保留第一次出现的重复数据;不保留副本
print(result_2)
# 输出结果为None.因为直接在a上修改,不再将修改结果传递给result_2
print(a)
# 输出结果如下:
# a b
# 0 3 4
# 1 5 6
# 2 3 1
# 3 1 2
(二)本关任务
利用pandas将‘basketball.csv’中的数据导入名为dataset的DataFrame对象中,并使用drop_duplicates()函数对dataset中的Date列进行去重,不保留副本。将去重结果dealed和dataset返回。
(三)参考代码
import pandas as pd
def duplicate():
'''
返回值:
dealed: 对dataset的Date列进行去重后的DataFrame类型数据,不保留副本
dataset: 初始读入的basketball.csv的数据
'''
# 请在此添加代码 完成本关任务
# ********** Begin *********#
dataset = pd.read_csv('basketball.csv')
dealed = dataset.drop_duplicates(subset='Date')
# ********** End **********#
# 返回dealed,dataset
return dealed, dataset
2.处理空值
(一)相关知识
1> DataFrame中空值的表示
Pandas通常把空值表示为 NaN,以上一关卡中的basketball.csv为例,当中的OT?字段和Notes字段中就有许多空值。我们可以取出数据的前五行的OT?字段看一下DataFrame中空值的表示。
import pandas as pd
dataset=pd.read_csv('basketball.csv')
print(dataset["OT?"].ix[:5])
# 输出结果为:
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
5 NaN
Name: OT?, dtype: object
在数据挖掘过程中,模型通常不能直接接收NaN数据。这就需要我们对空值进行处理。在处理空值之前,要先能找出空值的个数和位置。
2> 查找空值及计算空值的个数
Pandas中查找数据表中空值的函数有两个,一个是函数isnull,如果是空值就显示True。另一个函数notnull正好相反,如果是空值就显示False。
分别利用这两个函数来找出basketball.csv数据中OT?字段和Notes字段中的个数。下面的一段程序是对isnull函数的使用示例。
print(dataset[:5].isnull())
# 输出结果为:
Date Score Type Visitor Team VisitorPts Home Team HomePts OT? Notes
0 False False False False False False True True
1 False False False False False False True True
2 False False False False False False True True
3 False False False False False False True True
4 False False False False False False True True
从输出的结果上来看,前五行数据只有OT?和Notes字段值是空值,其他均为非空。notnull函数的使用同理,只是输出的结果与isnull函数相反。
接下来我们可能还需要计算数据中空值的个数。为了解决这个问题,我们可以使用value_counts函数。这个函数的使用示例见下:
result=dataset['OT?'].isnull()
#将dataset的OT?字段的空值与否情况传给result
print(result.value_counts())
# 输出结果为:
True 1151
False 79
Name: OT?, dtype: int64
由输出结果可以看出dataset中的OT?字段有1151个空值和79个非空值。
3> 处理空值-fillna
fillna()函数可以将空值位置填充任意指定的值。
下面这段代码将OT?字段中的空值赋值为’0OT’,将Notes字段中的空值赋值为’Nowhere’.
dataset=dataset['OT?'].fillna('0OT')
dataset=dataset['Notes'].fillna('Nowhere')
#在处理空值之后,我们可以打印出前五行数据,看看原先是'NaN'的位置现在的值是什么
print(dataset.ix[:5])
# 输出结果为:
Date Score Type Visitor Team VisitorPts \
0 Tue Oct 29 2013 Box Score Orlando Magic 87
1 Tue Oct 29 2013 Box Score Los Angeles Clippers 103
2 Tue Oct 29 2013 Box Score Chicago Bulls 95
3 Wed Oct 30 2013 Box Score Brooklyn Nets 94
4 Wed Oct 30 2013 Box Score Atlanta Hawks 109
Home Team HomePts OT? Notes
0 Indiana Pacers 97 0OT Nowhere
1 Los Angeles Lakers 116 0OT Nowhere
2 Miami Heat 107 0OT Nowhere
3 Cleveland Cavaliers 98 0OT Nowhere
4 Dallas Mavericks 118 0OT Nowhere
(二)本关任务
在本关卡中,我们为你提供了一个鸢尾花的数据集。数据集总共有五个字段,分别是:
- sepal.length
- sepal.width
- petal.length
- petal.width
- variety
除了variety字段内容是字符串外,其他字段的内容均是浮点数。你要完成的任务包括:
- 找出每项字段中各有多少空值,并按上文给出的字段顺序打印出来。
- 前四项字段的空值,各用该空值所在列的均值填充。
- 第五项字段的空值,统一填充为’Unknown’.
- 处理均值后的数据命名为dealed_data,并返回
注:pandas中均值的计算可以使用means()函数。
示例:data[‘a’].means()的结果就是a字段的均值。
(三)参考代码
import pandas as pd
dataset = pd.read_csv('iris.csv')
def count_nan(dataset):
'''
返回值:
[n1,n2,n3,n4,n5]
分别代表dataset的五列各有多少空值
'''
# 请在此添加代码 完成本关任务
# ********** Begin *********#
[n1, n2, n3, n4, n5] = dataset.isnull().sum()
# ********** End **********#
# 返回[n1,n2,n3,n4,n5]
return [n1, n2, n3, n4, n5]
def deal_nan(dataset):
'''
返回值:
dataset:按要求处理过、已经没有空值的数据
'''
# 请在此添加代码 完成本关任务
# ********** Begin *********#
dataset['sepal.length'] = dataset['sepal.length'].fillna(
dataset['sepal.length'].mean())
dataset['sepal.width'] = dataset['sepal.width'].fillna(
dataset['sepal.width'].mean())
dataset['petal.length'] = dataset['petal.length'].fillna(
dataset['petal.length'].mean())
dataset['petal.width'] = dataset['petal.width'].fillna(
dataset['petal.width'].mean())
dataset['variety'] = dataset['variety'].fillna('Unknown')
# ********** End **********#
# 返回dataset
return dataset
二、数据采集实战
1. 单网页爬取
(一)相关知识
为了完成本关任务,需要具备几个基本的技能。首先需要对 Python 语言具有一定的掌握。了解其中的 urllib 库, re 库, random 库。其中,rrllib 库主要实现对网页的爬取。re 库实现数据的正则化表达。random 库实现数据的随机生成。
1> 爬虫简介
网络爬虫是一种按照一定规则自动抓取互联网信息的程序或者脚本。爬虫的行为过程可以划分为三个部分:
- 载入;
- 解析;
- 存储。
2> 网络爬虫
在利用 Python 进行数据爬取的过程中,我们首先需要了解爬虫的基本技能树,包括:静态网页采集、动态网页采集、爬虫框架设计以及数据存储。
- 在静态网页的取得过程中,需要涉及正则化规则和一些 Python 库。比如 requests 和 beautifulSoup(bs4);
- 在进行动态网页爬取的过程中,需要解决验证码自动识别的问题;
- 在进行爬虫框架设计的过程中,需要掌握 pyspider 和 scrapy ;
- 在进行数据存储的过程中,需要掌握 CSV、EXCEL、TXT 等格式文件和 MongDB等数据库的相关操作。

3> 网络爬虫:载入
载入就是将目标网站数据下载到本地,主要步骤如下:
-
1.网站数据主要依托于网页 (html) 展示;
-
2.爬虫程序向服务器发送网络请求,从而获取相应的网页;
- 网站常用网络协议: http,https,ftp;
- 数据常用请求方式:get,post;
- get :参数常放置在 URL 中,如: http://www.adc.com?p=1&q=2&r=3 , 问号后为参数;
- post :参数常放置在一个表单(报文头( header ))中。
实际操作:抓取一个静态网页步骤
- 1.确定 URL;
- 2.确定请求的方式以及相关参数;
- 3.用浏览器或者抓包工具 URL 发送参数;
- 4.即可收到网页返回的结果。
4> 网络爬虫:动态载入
部分页面的数据是动态加载的,比如 Ajax 异步请求,网页中的部分数据需要浏览器渲染或者用户的某些点击、下拉的操作触发才能获得的即 Ajax 异步请求。
面对动态加载的页面时,我们可以借助抓包工具,分析某次操作所触发的请求,通过代码实现相应请求利用智能化的工具:selenium + webdriver。
5> 网络爬虫:解析
在载入的结果中抽取特定的数据,载入的结果主要分成三类:html、json、xml 。
-
html: beautifulSoup、xpath 等;
-
json: json 、 demjson 等;
-
xml: xml 、 libxml2 等。
(二)本关任务
请仔细阅读代码,结合相关知识,在 Begin-End 区域内进行代码补充,编写一个爬虫,爬取 www.jd.com 网的 title ,具体要求如下:
-
获取 www.jd.com 的页面 html 代码并保存在 ./step1/京东.html;

-
使用正则提取 title;
-
将 title 的内容保存为 csv 文件,位置为 ./step1/csv_file.csv。
(三)参考代码
import urllib.request
import csv
import re
# 打开京东www.jd.com,读取并爬到内存中,解码, 并赋值给data
# 将data保存到本地
# ********** Begin ********** #
data = urllib.request.urlopen("https://www.jd.com").read().decode("utf-8", "ignore")
with open("./step1/京东.html", 'a') as f:
f.write(data)
# ********** End ********** #
# 使用正则提取title
# 保存数据到csv文件中
# ********** Begin ********** #
pattern = "(.*?) "
title = re.compile(pattern, re.S).findall(data)
with open("./step1/csv_file.csv", 'a') as f:
f_csv = csv.writer(f)
f_csv.writerow(title)
# ********** End ********** #
2.网页爬取策略
(一)相关知识
主要介绍两种爬虫爬取策略:1. 深度优先爬虫; 2. 广度优先爬虫。
1> 深度优先爬虫(一路到底)
在一个网页中,当一个超链被选择后,被链接的网页将执行深度优先搜索,即在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索沿着网页上的超链走到不能再深入为止,然后返回到某一个网页,再继续选择该网页中的其他超链。当不再有其他超链可选择时,说明搜索已经结束。
示例:
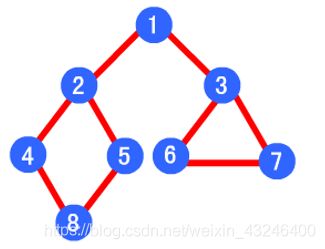
爬取顺序为:1->2->4->8->5->3->6->7
2> 广度优先爬虫(逐层爬取)
广度优先爬虫过程就是从一系列的种子节点开始,把这些网页中的“子节点” 提取出来,放入队列中依次进行抓取,被处理过的链接需要放入一张表中。每次新处理一个链接之前,需要查看这个链接是否已经存在于表中。如果存在,证明链接已经处理过, 跳过,不做处理,否则进行下一步处理。
示例:

爬取顺序为:1->2->3->4->5->6->7->8
(二)本关任务
请仔细阅读代码,结合相关知识,在 Begin-End 区域内进行代码补充,编写一个爬虫实现深度优先爬虫,爬取的网站为 www.baidu.com。
(三)参考代码
'''
' @author:ljq
' @date:2021/04/12
' @description
'
'''
from bs4 import BeautifulSoup
import requests
import re
class linkQuence:
def __init__(self):
# 已访问的url集合
self.visted = []
# 待访问的url集合
self.unVisited = []
# 获取访问过的url队列
def getVisitedUrl(self):
return self.visted
# 获取未访问的url队列
def getUnvisitedUrl(self):
return self.unVisited
# 添加到访问过得url队列中
def addVisitedUrl(self, url):
self.visted.append(url)
# 移除访问过得url
def removeVisitedUrl(self, url):
self.visted.remove(url)
# 未访问过得url出队列
def unVisitedUrlDeQuence(self):
try:
return self.unVisited.pop()
except:
return None
# 保证每个url只被访问一次
def addUnvisitedUrl(self, url):
if url != "" and url not in self.visted and url not in self.unVisited:
self.unVisited.insert(0, url)
# 获得已访问的url数目
def getVisitedUrlCount(self):
return len(self.visted)
# 获得未访问的url数目
def getUnvistedUrlCount(self):
return len(self.unVisited)
# 判断未访问的url队列是否为空
def unVisitedUrlsEnmpy(self):
return len(self.unVisited) == 0
class MyCrawler:
def __init__(self, seeds):
# 初始化当前抓取的深度
self.current_deepth = 1
# 使用种子初始化url队列
self.linkQuence = linkQuence()
if isinstance(seeds, str):
self.linkQuence.addUnvisitedUrl(seeds)
if isinstance(seeds, list):
for i in seeds:
self.linkQuence.addUnvisitedUrl(i)
print("Add the seeds url %s to the unvisited url list" %
str(self.linkQuence.unVisited))
################ BEGIN ##################
# 抓取过程主函数(方法一)
def crawling(self, seeds, crawl_deepth):
# 循环条件:抓取深度不超过crawl_deepth
while self.current_deepth <= crawl_deepth:
# 循环条件:待抓取的链接不空
while not self.linkQuence.unVisitedUrlsEnmpy():
# 队头url出队列
visitUrl = self.linkQuence.unVisitedUrlDeQuence()
print("Pop out one url \"%s\" from unvisited url list" % visitUrl)
if visitUrl is None or visitUrl == "":
continue
# 获取超链接
links = self.getHyperLinks(visitUrl) # 获取visiturl中的所有超链接
print("Get %d new links" % len(links))
# 将visitUrl放入已访问的url中
self.linkQuence.addVisitedUrl(visitUrl)
print("Visited url count: " +
str(self.linkQuence.getVisitedUrlCount()))
print("Visited deepth: " + str(self.current_deepth))
# 未访问的url入列 也就是visiturl网页中的所有超链接links
for link in links:
self.linkQuence.addUnvisitedUrl(link)
print("%d unvisited links:" %
len(self.linkQuence.getUnvisitedUrl()))
self.current_deepth += 1
# 抓取过程主函数(方法二)
def crawling(self, seeds, crawl_deepth):
print('''
Pop out one url "http://baozhang.baidu.com/guarantee/" from unvisited url list
Get 0 new links
Visited url count: 12
Visited deepth: 3
Pop out one url "http://ir.baidu.com/phoenix.zhtml?c=188488&p=irol-irhome" from unvisited url list
Get 19 new links
Visited url count: 13
Visited deepth: 3
19 unvisited links:
''')
# 获取源码中得超链接
def getHyperLinks(self, url):
links = []
data = self.getPageSource(url) # 获取url网页源码
soup = BeautifulSoup(data, 'html.parser')
a = soup.findAll("a", {"href": re.compile('^http|^/')})
for i in a:
if i["href"].find("http://") != -1:
links.append(i["href"])
return links
# 获取网页源码
def getPageSource(self, url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ''
############### END ###############
def main(seeds, crawl_deepth):
craw = MyCrawler(seeds)
craw.crawling(seeds, crawl_deepth)
# 爬取百度超链接,深度为3
if __name__ == '__main__':
main("http://www.baidu.com", 3)
3.爬取与反爬取
(一)相关知识
随着网络爬虫对目标网站访问频率的加大,网站也会禁止爬虫程序访问。
1>常见反爬手段:
- 出现用户登录界面,需要验证码;
- 禁止某个固定用户帐号或 ip 一段时间内访问网站;
- 直接返回错误的无用数据。
2> 应对措施:
- 优化爬虫程序,尽量减少访问次数,尽量不抓取重复内容;
- 使用多个 cookie (网站用来识别用户的手段,每个用户登录会生成一个 cookie );
- 使用多个 ip (可以用代理实现)。
(二)本关任务
本关任务:编写一个爬虫,实现对http://121.40.96.250:9999/webdemo/page/1/12/749 该网址所有信息的爬取,并将结果保存在 step3/result.txt 中。
(三)参考代码
import urllib.request
def spider():
# 任意改一个可以爬取的网页即可
url = "https://www.qiushibaike.com/text/page/"
# ********** Begin **********#
# 构建opener
opener = urllib.request.build_opener()
# User-Agent设置成浏览器的值
User_Agent = (
'User-agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)')
# 将UA添加到headers中
opener.addheaders = [User_Agent]
urllib.request.install_opener(opener)
data = urllib.request.urlopen(url).read().decode("utf-8", "ignore")
with open('step3/result.txt', 'a') as fp:
fp.write(data)
# ********** End **********#
return data
4.爬取与反爬取进阶
(一)相关知识
在反爬机制中,许多网站会通过 ip 以及请求头来限制你的访问,在不影响网站正常运作的情况下,我们可以使用 ip 代理池以及随机请求头来伪装自己的爬虫,其中需要用到的就是 python 的 random 模块。
(二)本关任务
使用随机请求头爬取 www.qiushibaike.com/text/ 前两页的段子内容,并保存在 ./step4/content.txt 中。
(三)参考代码
import urllib.request
import re
import random
# 请求头
uapools = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
]
def UA():
#********** Begin **********#
# 使用随机请求头
opener = urllib.request.build_opener()
thisua = random.choice(uapools)
ua = ("User-Agent", thisua)
opener.addheaders = [ua]
urllib.request.install_opener(opener)
# print("当前使用UA:"+str(thisua))
#********** End **********#
def main(page): # page为页号,int类型
#********** Begin **********#
for i in range(0, page):
UA()
# 此处需加https,否则报错“ValueError: unknown url type”
thisurl = "https://www.qiushibaike.com/text/page/"+str(i+1)
data = urllib.request.urlopen(thisurl).read().decode("utf-8", "ignore")
with open('./step4/content.txt', 'a') as fp:
fp.write(data)
#********** End **********#
@date: 2021.04.12
@author: zkinglin
(完)