【论文笔记】An Unsupervised Style Transfer Framework for Profanity Redaction
Towards A Friendly Online Community: An Unsupervised Style Transfer Framework for Profanity Redaction

文章目录
- Towards A Friendly Online Community: An Unsupervised Style Transfer Framework for Profanity Redaction
-
- Abstract
- Main idea and Framework
-
- Problem Formulation
- Retrieve
- Generate
-
- Matching
- Filling
- Edit
- Selection
- Experimental Results
-
- Automatic Evaluations
- Human Evaluations
- Conclusion
会议:COLING2020
任务:文本解毒
Abstract
本文针对文本去毒任务,设计了一个检索-生成-编辑(Retrieve, Generate and Edit)的无监督风格迁移流水线方法,通过词限制的方式编辑冒犯性的评论,使其能够保持高流畅度和较好地保留原始语义。实验结果在人工评估上SOTA,并且是唯一一个在所有自动评估指标上都表现一致的方法。
Main idea and Framework
Problem Formulation
给定一个限制词汇表 V r V_r Vr,数据集D={( x 1 , l 1 x_1,l_1 x1,l1),( x n , l n x_n,l_n xn,ln)}, x i x_i xi表示句子, l i l_i li表示标签,当句子中存在冒犯性词 v i ( v i ∈ V r ) v_i(v_i\in{V_r}) vi(vi∈Vr)时,该标签为”offensive“,否则为”non-offensive“,对于 l i l_i li="offensive"的句子 x i x_i xi,生成不包含任何在限制词表中的冒犯性词的句子 x i ∗ x_i^* xi∗。本文的工作聚焦于亵渎性删除(Profanity removal)。

Retrieve
如图1所示,RGE框架通过检索可能的词性标注序列,作为生成候选句子和编辑模型纠正候选句子的模板。
- 对冒犯性(Offensive,O)和非冒犯性(Non-offensive,N)都进行词性标注(POS tagging),对于受限词典 V r V_r Vr中的冒犯性单词,将其词性置为[BW]。这样得到了两个语料库中每个句子的词性标注序列。
- 给定一个句子 x i x_i xi和它的词性标注序列 p i p_i pi,使用基于TF-IDF的Lucene搜索引擎来搜索N语料库中的与其相似度最高的十个POS序列集合{ p i ′ {p_i'} pi′}。
Generate
给定 x i x_i xi, p i p_i pi,{ p i ′ {p_i'} pi′}。生成模块创建一个不包含冒犯性词的候选句集合 C i C_i Ci。该模块通过将 x i x_i xi中的单词“匹配”到每个 p i p_i pi中的可能位置来生成新的句子来实现。无法匹配的位置通过预训练的语言模型进行"填充"。算法流程如下图所示。

Matching
算法解读:
- 取源词性序列 p i p_i pi和相似词性序列{ p i ′ {p_i'} pi′},取它们的词性交集,即都有的词性,记作 T s h a r e d T_{shared} Tshared;
- 对 T s h a r e d T_{shared} Tshared中的每个词性,在源句子 x i x_i xi中找到属于该词性的词;
- 把这些词分配给相似词性序列中对应该词的词性的位置,这样对于N个词和M个位置,应该有 m a x ( A N M , A M N ) max(A_N^M,A_M^N) max(ANM,AMN)种排列组合,因为N和M的大小不固定,且需要考虑位置,每个位置都需要分配一个词;
- 将匹配生成的句子加入候选句序列。
Filling
对于候选句集合 C i C_i Ci,使用预训练的RoBERTa-base模型对其中的[MASK] token进行填充。为了增强内容保留度,在每个生成句子之前插入源句子 x i x_i xi,用[SEP]进行分隔,使用RoBERTa预测的不在限制词表中的最可能的单词替换[MASK]。最后,在每个[SEP]后的无掩码的句子即生成模型的输出。
Edit
该模块用于纠正生成模块输出句子的一些问题,例如由于排列组合产生的错误的词序、由于检索产生的不良词性标注序列导致的低流畅度文本。
-
首先随机采样了60K个non-offensive句子,然后将检索和生成模块应用于它们。然后应用Retrieve得到去掉第一个检索序列的最终序列{ P i N ′ P_i^{N'} PiN′},因为它是查询序列 y i y_i yi本身;
-
然后,使用生成的候选集合 C i N C_i^N CiN作为源数据集,同时将原始non-offensive句子作为目标数据集,形成一个平行语料库,最后得到780K个句子对;
-
在平行语料库上微调T5-small,优化其重构损失,得到编辑后的候选集 C i ′ C_i' Ci′。
Selection
该模块用于从候选句子集 C i ′ C_i' Ci′中选择一个质量最高的 x i ∗ x_i^* xi∗。
- 首先删除任何存在限制词的候选句子;
- 每个生成的候选句子和源句子进行BLEU值计算和PPL计算(使用预训练的GPT-2);
- 将BLEU和PPL使用MinMaxScaler归一化到[0,1]区间,选取BLEU+PPL的和最高的句子作为最终输出的句子。
Experimental Results
作者对比了八种现存的风格迁移方法。针对一些方法存在类别不平衡问题,对非冒犯性言论数据集进行了二次抽样,使其规模从7M增大到350K。
Automatic Evaluations
- Content preservation:BLEU-self(BL),ROUGE(RG),METEOR(MT);
- Style transfer accuracy(Acc):生成的句子中不包含任何限制词的句子比例;
- Fluency:预训练的GPT-2计算PPL
- Result:
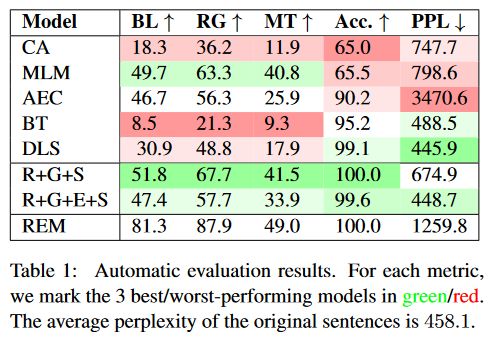
实验结果表明,本文提出的方法是唯一一个在三类指标上都表现一致的方法。其中,R+G+E+S的PPL值比R+G+S低226个点,说明利用与训练的Seq2Seq模型对生成的候选句进行修正是有效的。源数据集的PPL值为458.1。
作者在(Fighting offensive language on social media with unsupervised text style transfer.ACL 2018)该文的数据集中进行实验,对比了实验结果,超越其性能。
Human Evaluations
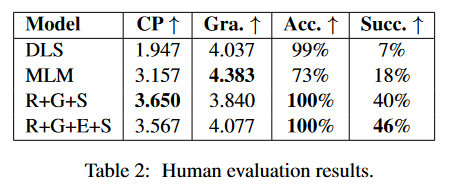
Gra表示语法正确度,Succ.表示风格迁移成功率。选取了四个表现最好的模型,从冒犯性言论中采样100条句子进行人工评估。实验结果表明,本文的模型在Succ.明显比其他模型较高。
Conclusion
这篇文章主要思路是用检索的方法来做,根据词性序列相似度计算拿到候选词性序列,然后根据词性分配候选词。对于无法分配候选词的词性会带有[MASK]标记,这时使用RoBERTa进行MASK预测。在这一整个过程中都对生成词做限制,防止冒犯性词出现。因此会造成一系列问题,比如词序错乱,句子不通顺等问题。本文缓解这类问题的方法是用T5模型训练一个Seq2Seq模型优化候选句和源句子的重构损失,以及在RoBERTa预测时插入源句子。但是,相比大规模预训练语言模型做的工作,句子的困惑度还是偏高,也可能是数据集本身PPL值就挺高,文章中有提到。