李宏毅ML作业笔记4: RNN文本情感分类
更新中...
目录
任务介绍
文本情感分类
句子喂入RNN的方式
半监督
data格式
代码思路
加载数据集
正确个数计算
word embedding
数据预处理
RNN模型构建
RNN模型训练
改进尝试
报告题目
1. 描述RNN
RNN 的模型架構
word embedding 方法
訓練過程 (learning curve)
準確率
2. 比较 BOW + DNN 与 RNN
RNN
BOW
本文所写代码在kaggle公开
RNN: https://www.kaggle.com/laugoon/hw4-emotion-classification
BOW+DNN: https://www.kaggle.com/laugoon/bow-cnn
任务介绍
使用 RNN 實作, 不能使用額外 data (禁止使用其他 corpus 或 pretrained model).
文本情感分类
Text Sentiment Classification/Emotion Classification
数据为Twitter 上收集到的推文.
labeled data每則推文都會被標注為正面或負面.
1正面:
![]()
0负面:
![]()
| labeled training data :20萬 unlabeled training data :120萬 testing data :20萬(10 萬 public,10 萬 private) |
RNN模型:

句子喂入RNN的方式
1. 建立字典,字典內含有每一個字所對應到的index(维度)
| 1 |
2 |
3 |
4 |
| I |
have |
a |
pen |
2. 句子每个字用向量(Word Embedding)代表.
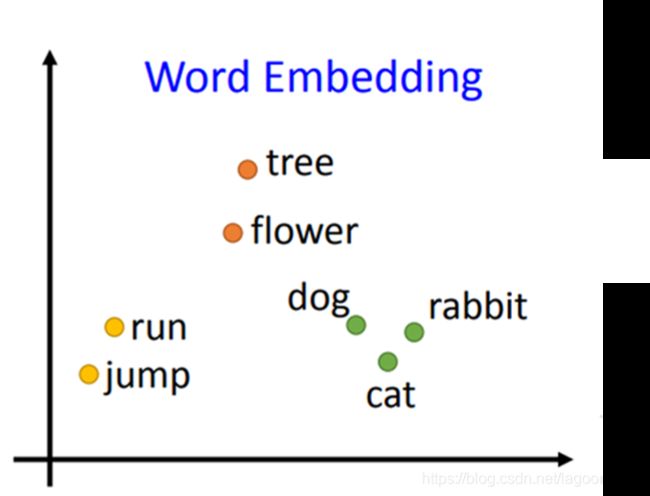
得到word embedding的常用方法: skip-gram, CBOW等. (这些方法也可以用套件, 不用自己手刻)
3. 将句子喂入RNN, 或bag of words (BOW), 得到代表句子的向量h.
embedding也可以和模型其他部分一起训练(设fix embedding参数).

Bag of Words (BOW) 方法表示句子.
不考虑语法, 词的顺序. 不需要RNN, 喂入DNN就可以算.
如:
| 句子 |
John likes to watch movies. Mary likes movies too. |
| BOW |
[1, 2, 1, 1, 2, 0, 0, 0, 1, 1] |
其中likes, movies出现两次, 则代表这两个词的维度处为2.

半监督
利用 unlabeled data. 常用Self-Training:
用训练好的模型对unlabeled data做标记, 再加入训练集.
可以调整阈值, 取比较有信心的data, 如:
pos_threshold = 0.8, 则prediction > 0.8时标1.
data格式
| labeled data |
label +++$+++ text |
| unlabeled data |
text 每一行一个句子 |
| 預測結果 |
id, label |
kaggle评估指标为正确率
代码思路
NLP任务語句分類(文本分類)
給定一個語句,判斷他其情绪(負面標 1,正面標 0)
这一部分的代码跨度比较大, 我看的是gensim官方文档, 翻译+笔记整理:
https://blog.csdn.net/lagoon_lala/article/details/119574087
也可参考pytorch官方教程:
https://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html
加载数据集
文件位置
| /kaggle/input/ml2020spring-hw4/testing_data.txt /kaggle/input/ml2020spring-hw4/training_nolabel.txt /kaggle/input/ml2020spring-hw4/training_label.txt |
1. training_label.txt:有 label 的训练集(句子与标记 0 or 1,+++$+++ 是分隔符號)
e.g., 1 +++$+++ are wtf ... awww thanks !
2. training_nolabel.txt:沒有 label 的训练集(只有句子),用來做半监督学习
e.g.: hates being this burnt !! ouch
3. testing_data.txt:要判斷 testing data 裡面的句子是 0 or 1
测试集的数据从第二行开始
id,text
0,my dog ate our dinner . no , seriously ... he ate it .
有标签训练集:
读取训练集时的样本结构
![]()
二维数组lines根据'\n'分行.
| 第0行 |
样本 |
'\n' |
| 第1行 |
样本 |
'\n' |
每一行line中根据空格分词
| 第0列 |
第1列 |
剩余列 |
||
| label |
' ' |
'+++$+++' |
' ' |
句子 |
读取代码:
| with open(path, 'r') as f: lines = f.readlines() lines = [line.strip('\n').split(' ') for line in lines] x = [line[2:] for line in lines] y = [line[0] for line in lines] |
| train_x, y = load_training_data('/kaggle/input/ml2020spring-hw4/training_label.txt') |
无标签训练集(分行与有标签数据相同, 分列无标签列以及分隔符+++$+++, 不用处理, 只需空格分词):
| lines = f.readlines() x = [line.strip('\n').split(' ') for line in lines] |
| train_x_no_label = load_training_data('/kaggle/input/ml2020spring-hw4/training_nolabel.txt') |
测试集:
| 第0列 |
第1列 |
||
| 第0行 |
'id' |
',' |
' text ' |
| 第1行 |
序号 |
',' |
文本 |
读取代码
| lines = f.readlines() X = ["".join(line.strip('\n').split(",")[1:]).strip() for line in lines[1:]] X = [sen.split(' ') for sen in X] |
| test_x = load_testing_data('/kaggle/input/ml2020spring-hw4/testing_data.txt') |
正确个数计算
预测正确样本个数计算, 最后正确率为correct*100/batch_size
| outputs[outputs>=0.5] = 1 # 大於等於 0.5 為正面 outputs[outputs<0.5] = 0 # 小於 0.5 為負面 correct = torch.sum(torch.eq(outputs, labels)).item() |
item将只有一个元素的tensor转换成python的scalars
word embedding
利用word2vec训练词向量
(此处使用__name__是为了迁移到notebook外模块, 不影响执行)
word2vec.Word2Vec中size参数主要是用来向量的维度, 换成了vector_size. iter迭代次数,换成了epochs. 新版本的API改名了, 要注意修改.
| model = word2vec.Word2Vec(x, vector_size=250, window=5, min_count=5, workers=12, epochs=10, sg=1) |
| model = train_word2vec(train_x + test_x) model.save(os.path.join(path_prefix, 'w2v_all.model')) |
若下标读取, 需使用wv, 参考:
https://stackoverflow.com/questions/67687962/typeerror-word2vec-object-is-not-subscriptable
数据预处理
Data Preprocess
读入Word2Vec模型:
| self.embedding = Word2Vec.load(self.w2v_path) self.embedding_dim = self.embedding.vector_size |
特殊词"
"
| vector = torch.empty(1, self.embedding_dim)#empty()返回一个包含未初始化数据的张量 torch.nn.init.uniform_(vector)#从均匀分布U(a, b)中生成值,填充输入的向量 self.word2idx[word] = len(self.word2idx)#word2idx,每个单词一个索引序号 self.idx2word.append(word) self.embedding_matrix = torch.cat([self.embedding_matrix, vector], 0)# 拼接两个张量 |
其中self.word2idx[word]的索引设为最后一个接上(值为字典全长)
torch.cat张量拼接concatenate. 例:
| A tensor([[ 1., 1., 1.], [ 1., 1., 1.]]) B tensor([[ 2., 2., 2.], [ 2., 2., 2.], [ 2., 2., 2.], [ 2., 2., 2.]]) |
| torch.cat((A,B),0)#按维数0(行)拼接 tensor([[ 1., 1., 1.], [ 1., 1., 1.], [ 2., 2., 2.], [ 2., 2., 2.], [ 2., 2., 2.], [ 2., 2., 2.]]) |
获取训练好的word embedding
make_embedding方法中, 注意vocab 属性不能用了
| self.embedding.wv.vocab |
| The vocab attribute was removed from KeyedVector in Gensim 4.0.0 Use KeyedVector's .key_to_index dict, .index_to_key list, and methods .get_vecattr(key, attr) and .set_vecattr(key, attr, new_val) instead. |
使用方法如:
| rock_idx = model.wv.vocab["rock"].index # rock_cnt = model.wv.vocab["rock"].count # vocab_len = len(model.wv.vocab) # rock_idx = model.wv.key_to_index["rock"] words = list(model.wv.index_to_key) rock_cnt = model.wv.get_vecattr("rock", "count") # vocab_len = len(model.wv) # |
embedding用法也改变了
| self.embedding_matrix.append(self.embedding[word]) |
| 'Word2Vec' object is not subscriptable |
改成:
| self.embedding_matrix.append(self.embedding.wv[word]) |
制作 word2idx 的 dictionary, embedding矩阵:
即填充初始化中的几个属性
self.w2v_path = w2v_path
self.idx2word = []
self.word2idx = {}
self.embedding_matrix = []
| for i, word in enumerate(self.embedding.wv.key_to_index): print('get words #{}'.format(i+1), end='\r') self.word2idx[word] = len(self.word2idx) self.idx2word.append(word) self.embedding_matrix.append(self.embedding.wv[word]) |
参考https://blog.csdn.net/lagoon_lala/article/details/119574087
查看词汇表(序号, 单词):
| for index, word in enumerate(model.wv.index_to_key): if index == 10: break print(f"word #{index}/{len(model.wv.index_to_key)} is {word}") |
使用模型:
| vec_king = model.wv['king'] |
其中, model.wv是获取词向量 (训练一个完整的模型,然后访问它的model.wv属性). 该内容在keyedvectors介绍.
统一句子长度
过长则截取前面, 过短则补充
| if len(sentence) > self.sen_len: sentence = sentence[:self.sen_len] else: pad_len = self.sen_len - len(sentence) for _ in range(pad_len): sentence.append(self.word2idx[" |
词转换成索引
没有出现过的单词就用
| for word in sen: if (word in self.word2idx.keys()): sentence_idx.append(self.word2idx[word]) else: sentence_idx.append(self.word2idx[" |
执行预处理
| preprocess = Preprocess(train_x, sen_len, w2v_path=w2v_path) embedding = preprocess.make_embedding(load=True) train_x = preprocess.sentence_word2idx() y = preprocess.labels_to_tensor(y) |
RNN模型构建
1. 句子输入LSTM中,得输出向量
2. 输出向量丢到分类器classifier中,进行二元分类。
embedding layer
| self.embedding = torch.nn.Embedding(embedding.size(0),embedding.size(1)) self.embedding.weight = torch.nn.Parameter(embedding) |
其中torch.nn.Embedding输入为一个编号列表,输出为对应的符号嵌入向量列表.
参考: https://www.jianshu.com/p/63e7acc5e890
| torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None) |
其中参数num_embeddings为词典的大小(有多少个词); embedding_dim为嵌入向量的维度,即用多少维来表示一个符号.
搭建LSTM
| self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=num_layers, batch_first=True) |
| model = LSTM_Net(embedding, embedding_dim=250, hidden_dim=150, num_layers=1, dropout=0.5, fix_embedding=fix_embedding) |
其中参数
input_size 输入数据的特征维数,通常就是embedding_dim(词向量的维度)
hidden_size LSTM中隐层的维度
num_layers 循环神经网络的层数
batch_first通常输入的数据shape=(batch_size,seq_length,embedding_dim),而batch_first默认是False,此时送进LSTM之前需要将batch_size与seq_length这两个维度调换
用DNN分类
| self.classifier = nn.Sequential( nn.Dropout(dropout), nn.Linear(hidden_dim, 1), nn.Sigmoid() ) |
RNN模型训练
求参数总数目
| total = sum(p.numel() for p in model.parameters()) |
其中numel()函数:返回数组中元素的个数
parameters()是Pytorch中返回模型中的参数个数
定义训练的损失函数, 优化器:
| criterion = nn.BCELoss() # 定義損失函數,二元交叉熵 binary cross entropy loss optimizer = optim.Adam(model.parameters(), lr=lr) # 將模型的參數給优化器 optimizer,並給予適當的学习率lr |
迭代训练
model模式的设置位置:
可以在epoch循环体内部, train循环前设置model模式.
助教参考代码在epoch外部设置train后, validation前改为eval, validation后立马改回train也是可以的.
| optimizer.zero_grad() # 由於 loss.backward() 的 gradient 會累加,所以每次餵完一個 batch 後需要歸零 outputs = model(inputs) # 將 input 餵給模型 outputs = outputs.squeeze() # 去掉最外面的 dimension,好讓 outputs 可以餵進 riterioncriterion() loss = criterion(outputs, labels) # 計算此時模型的 training loss loss.backward() # 算 loss 的 gradient optimizer.step() # 更新訓練模型的參數 |
其中torch.squeeze()对数据的维度进行压缩,去掉维数为1的的维度.
验证集model.eval()其他类似.
测试集预测
| outputs = model(inputs) outputs = outputs.squeeze() outputs[outputs>=0.5] = 1 # 大於等於 0.5 為正面 outputs[outputs<0.5] = 0 # 小於 0.5 為負面 ret_output += outputs.int().tolist() |
| outputs = testing(batch_size, test_loader, model, device) |
分割测试集/训练集样本:
| # 训练集中分一部分作为验证集 # X_train, X_val, y_train, y_val = train_x[:180000], train_x[180000:], y[:180000], y[180000:] X_train, X_val, y_train, y_val = train_test_split(train_x, y, test_size = 0.1, random_state = 1, stratify = y) print('Train | Len:{} \nValid | Len:{}'.format(len(y_train), len(y_val))) |
改进尝试
这段是因为之前self.word2idx[word]计算代码写错, 导致模型效果不好的debug过程, 上文已经修改. 如无特殊需要, 无需观看.
1.word embedding参数workers=12改1 X
num_workers调整为0不使用多线程X没效果
2. 参考百度NLP情感分析X无果
3. 修改model.train()位置X无果
4. 修改word2vec模型形状
| model = word2vec.Word2Vec(x, vector_size=250, window=5, min_count=5, workers=12, epochs=10, sg=1) |
改为
| model = word2vec.Word2Vec(x, vector_size=256, window=5, min_count=5, workers=12, epochs=10, sg=1) |
LSTM形状改为
| model = LSTM_Net(embedding, embedding_dim=256, hidden_dim=128, num_layers=1, dropout=0.5, fix_embedding=fix_embedding) |
担心梯度消失, 打印梯度
在backward()后面加
| for name,param in my_cnn.named_parameters(): print('层:',name,param.size()) print('权值梯度',param.grad) print('权值',param) |
| for param in model.parameters(): print('权值梯度',param.grad) |
参考:
https://blog.csdn.net/a1367666195/article/details/105629526?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_title~default-0.control&spm=1001.2101.3001.4242
梯度均为e^(-4)以下, 考虑出现梯度消失.
调整学习率
原lr=0.001, 效果不好
lr=0.01:
学习率改完还不如之前了
loss在0.69徘徊, 准确率50以下
lr=0.0001:
Loss:0.69317 Acc: 49.786
lr=1.0
梯度全部变为0
训练集验证集Loss都很低,并且趋于不变,同时两者精确度也不高, 考虑是搭建的网络没有学习到任何东西,是网络搭建有问题,并不是过拟合或者欠拟合
训练集上loss不下降的问题:
参考:
https://blog.ailemon.net/2019/02/26/solution-to-loss-doesnt-drop-in-nn-train/
1.模型结构和特征工程存在问题
2.权重初始化方案有问题
pytorch初始化w, b方法:
RNN的weight和bias封装在parameters中,且需要对weight和bias分开初始化,否则报错
| self.rnn = nn.LSTM(input_size=embedding_size, hidden_size=128, num_layers=1, bidirectional=False) for name, param in self.rnn.named_parameters(): if name.startswith("weight"): nn.init.xavier_normal_(param) else: nn.init.zeros_(param) |
采用正交初始化
| torch.nn.init.orthogonal_(tensor, gain=1) |
| for name, param in self.lstm.named_parameters(): if name.startswith("weight"): # nn.init.xavier_normal_(param) nn.init.orthogonal_(param, gain=1) else: nn.init.zeros_(param) |
没有效果
3.正则化过度
L1 L2和Dropout是防止过拟合用的. 一般在刚开始是不需要加正则化的,过拟合后,再根据训练情况进行调整.
不用dropout
| model = LSTM_Net(embedding, embedding_dim=256, hidden_dim=128, num_layers=1, dropout=0, fix_embedding=fix_embedding) |
4.选择合适的激活函数、损失函数
使用全连接层来分类的情况下,才会使用softmax这种激活函数
对于一些分类任务,通常使用交叉熵损失函数,回归任务使用均方误差
5.选择合适的优化器和学习速率
神经网络的优化器选取一般选取Adam,但是在有些情况下Adam难以训练,这时候需要使用如SGD之类的其他优化器
优化器改为SGD
| optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9) optimizer = optim.Adam([var1, var2], lr = 0.0001) |
| optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.9) |
7.模型训练遇到瓶颈
这里的瓶颈一般包括:梯度消失、大量神经元失活、梯度爆炸和弥散、学习率过大或过小等。
梯度消失时,模型的loss难以下降,就像走在高原上,几乎任何地方都是高海拔,可以通过梯度的检验来验证模型当前所处的状态。有时梯度的更新和反向传播代码存在bug时,也会有这样的问题。
检查梯度更新, 反向传播代码
| loss.backward() # 算 loss 的 gradient optimizer.step() # 更新訓練模型的參數 |
没发现什么问题
8.batch size过大
过大时,模型前期由于梯度的平均,导致收敛速度过慢。一般batch size 的大小常常选取为32,或者16,有些任务下比如NLP中,可以选取8作为一批数据的个数。
修改batch_size128->32
9.数据集未打乱
不打乱数据集的话,会导致网络在学习过程中产生一定的偏见问题。比如张三和李四常常出现在同一批数据中,那么结果就是,神经网络看见了张三就会“想起”李四
10.数据集有问题
噪声过多, 类别不平衡
检查数据集路径, 对比kaggle数据集和colab数据集
11.未进行归一化
未进行归一化会导致尺度的不平衡
12. 是不是我处理Gensim版本冲突的时候改的不对? 能不能找到官方的改法?
打印Gensim相关模型数据
(打印输出确实是个倒逼review的好方法, 看到很多细节)
语料库上训练一个模型(模型的主要部分是model.wv,代表词向量)后:
| model = gensim.models.Word2Vec(sentences=sentences) |
可查看词汇表(序号, 单词):
| for index, word in enumerate(model.wv.index_to_key): if index == 10: break print(f"word #{index}/{len(model.wv.index_to_key)} is {word}") |
| word #0/24694 is i word #1/24694 is . word #2/24694 is ' word #3/24694 is to word #4/24694 is the word #5/24694 is ! word #6/24694 is a word #7/24694 is my word #8/24694 is and word #9/24694 is it |
修改预处理处读取w2v模型地址
| def __init__(self, sentences, sen_len, w2v_path="w2v.model") |
查看读取出来的模型, 并根据模型维度调整之后模型形状:
| def get_w2v_model(self): # 把之前訓練好的 word to vec 模型讀進來 self.embedding = Word2Vec.load(self.w2v_path) self.embedding_dim = self.embedding.vector_size#获取Word2Vec模型中的参数 向量长度, 方便之后定义 #查看词汇表(序号, 单词) for index, word in enumerate(self.embedding.wv.index_to_key): if index == 10: break print(f"word #{index}/{len(self.embedding.wv.index_to_key)} is {word}") print(f"embedding_dim is {self.embedding_dim}") |
| word #0/24694 is i word #1/24694 is . word #2/24694 is ' word #3/24694 is to word #4/24694 is the word #5/24694 is ! word #6/24694 is a word #7/24694 is my word #8/24694 is and word #9/24694 is it embedding_dim is 256 |
make_embedding中,制作word2idx 的 dictionary时, 循环内容由key_to_index改为index_to_key.
打印制作过程:

word2idx 的 dictionary有问题.
gensim老版本len(self.word2idx), 和新版本len(self.embedding.wv.index_to_key)得到结果可能不同.
报错:
| print(f"idx2word {self.word2idx[word]} is {self.idx2word[self.word2idx[word]]}") |
| list index out of range |
word2idx的计算出错, 改回:
| self.word2idx[word] = len(self.word2idx) |
改bug成功了, 精确度能达到70多了:
| [ Epoch1: 5625/5625 ] loss:0.701 acc:50.000 Train | Loss:0.69115 Acc: 52.466 Valid | Loss:0.69051 Acc: 52.595 saving model with acc 52.595 ----------------------------------------------- [ Epoch2: 5625/5625 ] loss:0.682 acc:53.125 Train | Loss:0.68887 Acc: 53.261 Valid | Loss:0.68286 Acc: 55.570 saving model with acc 55.570 ----------------------------------------------- [ Epoch3: 5625/5625 ] loss:0.476 acc:84.375 Train | Loss:0.56269 Acc: 70.421 Valid | Loss:0.52849 Acc: 74.075 saving model with acc 74.075 ----------------------------------------------- [ Epoch4: 5625/5625 ] loss:0.405 acc:81.250 Train | Loss:0.49013 Acc: 76.378 Valid | Loss:0.47930 Acc: 76.930 saving model with acc 76.930 ----------------------------------------------- [ Epoch5: 5625/5625 ] loss:0.526 acc:68.750 Train | Loss:0.48032 Acc: 76.845 Valid | Loss:0.47555 Acc: 76.790 ---------------------------------------------- |
现在再将原来的参数, 优化器等修改一一改回, 达到80%了
| [ Epoch1: 5625/5625 ] loss:0.542 acc:75.000 Train | Loss:0.48432 Acc: 76.333 Valid | Loss:0.44062 Acc: 79.185 saving model with acc 79.185 ----------------------------------------------- [ Epoch2: 5625/5625 ] loss:0.507 acc:71.875 Train | Loss:0.43515 Acc: 79.754 Valid | Loss:0.43679 Acc: 79.130 ----------------------------------------------- [ Epoch3: 5625/5625 ] loss:0.516 acc:65.625 Train | Loss:0.41661 Acc: 80.883 Valid | Loss:0.42773 Acc: 79.945 saving model with acc 79.945 ----------------------------------------------- [ Epoch4: 5625/5625 ] loss:0.332 acc:75.000 Train | Loss:0.40043 Acc: 81.709 Valid | Loss:0.42307 Acc: 80.325 saving model with acc 80.325 ----------------------------------------------- [ Epoch5: 5625/5625 ] loss:0.436 acc:75.000 Train | Loss:0.38367 Acc: 82.561 Valid | Loss:0.42402 Acc: 80.230 |
kaggle私有测试集上的得分也有0.80405了.

不过看起来主要是第一轮训练的效果提高多, 后面几轮的提高都非常轻微.
报告题目
1. 描述RNN
(1%) 請說明你實作的 RNN 的模型架構、word embedding 方法、訓練過程 (learning curve) 和準確率為何?
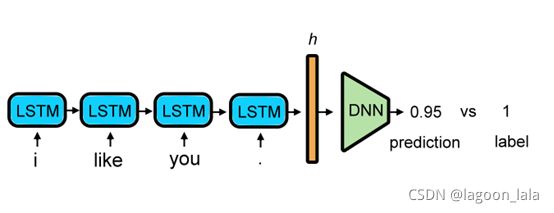
RNN 的模型架構
参考助教图:
RNN的表示方式参考:
https://blog.csdn.net/qq_28437273/article/details/79632170
RNN的表示有两种不同的绘图方式。一是计算图,二是展开计算图.
图中,只包含了输入与隐藏状态,不包含输出。回路图中的黑色方块表示单个时间步的延迟

不同的RNN结构类型:

该任务属于多对一: 给定文字描述,输出打分.
首先是一层embedding 层:
| self.embedding = torch.nn.Embedding(embedding.size(0),embedding.size(1)) |
embedding层形状:
输入词典的大小尺寸num_embeddings= embedding.size(0),
嵌入向量的维度,即用多少维来表示一个符号embedding_dim= embedding.size(1)
通过LSTM_NET传入的参数观察embedding层形状
| class LSTM_Net(nn.Module): def __init__(self, embedding, embedding_dim, hidden_dim, num_layers, dropout=0.5, fix_embedding=True): |
| model = LSTM_Net(embedding, embedding_dim=256, hidden_dim=128, num_layers=1, dropout=0.5, fix_embedding=fix_embedding) |
然后是lstm层
| self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=num_layers, batch_first=True) |
lstm层形状:
参考:
https://zhuanlan.zhihu.com/p/41261640
参数列表
input_size= embedding_dim:x的特征维度
hidden_size= hidden_dim:隐藏层的特征维度
num_layers=num_layers:lstm隐层的层数,默认为1
bias:False则bih=0和bhh=0. 默认为True
batch_first=True:True则输入输出的数据格式为 (batch, seq, feature)
dropout:除最后一层,每一层的输出都进行dropout,默认为: 0
bidirectional:True则为双向lstm默认为False
输入:input, (h0, c0)
输出:output, (hn,cn)
输出数据格式:
output(seq_len, batch, hidden_size * num_directions)
其中num_directions不是双向, 就为1.
hidden_size * num_directions=128
接着二元分类器全连接层分类:
| self.classifier = nn.Sequential( nn.Dropout(dropout), nn.Linear(hidden_dim, 1), nn.Sigmoid() ) |
全连接层nn.Linear
形状: 输入 hidden_dim=128, 输出 1.
in_features指的是输入张量的大小,即输入的[batch_size, size]中的size。
out_features指的是输出张量的大小,即输出的二维张量的形状为[batch_size,output_size],当然,它也代表了该全连接层的神经元个数。
从输入输出的张量的shape角度来理解,相当于一个输入为[batch_size, in_features]的张量变换成了[batch_size, out_features]的输出张量。
参考:
https://blog.csdn.net/qq_42079689/article/details/102873766
查看模型形状:
| print(f" embedding层: 输入 {embedding.size(0)}, 输出 {embedding.size(1)}\n lstm层: 输入 embedding_dim=256, 隐藏层的特征维度 hidden_dim=128, lstm隐层的层数num_layers=1, 输出 hidden_dim * num_directions=128*1\n 全连接层: 输入 hidden_dim=128, 输出 1\n") |
| embedding层: 输入 24696, 输出 256 lstm层: 输入 embedding_dim=256, 隐藏层的特征维度 hidden_dim=128, lstm隐层的层数num_layers=1, 输出 hidden_dim * num_directions=128*1 全连接层: 输入 hidden_dim=128, 输出 1 |
该RNN架构如下:

word embedding 方法
词嵌入(Word Embedding),包括count-based和prediction-based两种方法.
此处使用的为Gensim中word2vec. word2vec的两种版本: CBOW(Continuous bag of word model)和Skip-gram都属于Prediction-based变形.
count-based有BOW.
訓練過程 (learning curve)
绘制学习曲线(learning curve).
参考莫烦教程中的绘制学习曲线部分:
https://mofanpy.com/tutorials/machine-learning/sklearn/cross-validation2/
学习曲线还是很重要的, 按张老师的话来说:" 实验结果取收敛后均值, 均值不变才是收敛,缓慢下降不是收敛, 训练时要展示loss图,才知道什么时候收敛"
sklearn.learning_curve 中的 learning curve 可以很直观的看出我们的 model 学习的进度, 对比发现有没有 overfitting 的问题.
所需模块:
| from sklearn.learning_curve import learning_curve #学习曲线模块 import matplotlib.pyplot as plt #可视化模块 import numpy as np |
教程中使用的损失函数为平均方差scoring='mean_squared_error'
模型为支持向量分类器Support Vector Classifier
样本由小到大分成5轮检视学习曲线(10%, 25%, 50%, 75%, 100%)
| train_sizes, train_loss, test_loss = learning_curve( SVC(gamma=0.001), X, y, cv=10, scoring='mean_squared_error', train_sizes=[0.1, 0.25, 0.5, 0.75, 1]) |
对每一轮的MSE再平均
| #平均每一轮所得到的平均方差(共5轮,分别为样本10%、25%、50%、75%、100%) train_loss_mean = -np.mean(train_loss, axis=1) test_loss_mean = -np.mean(test_loss, axis=1) |
作图:
| plt.plot(train_sizes, train_loss_mean, 'o-', color="r", label="Training") plt.plot(train_sizes, test_loss_mean, 'o-', color="g", label="Cross-validation") plt.xlabel("Training examples") plt.ylabel("Loss") plt.legend(loc="best") plt.show() |
其中plt.plot前两个参数分别是横轴(训练样本比例), 和纵轴(loss)
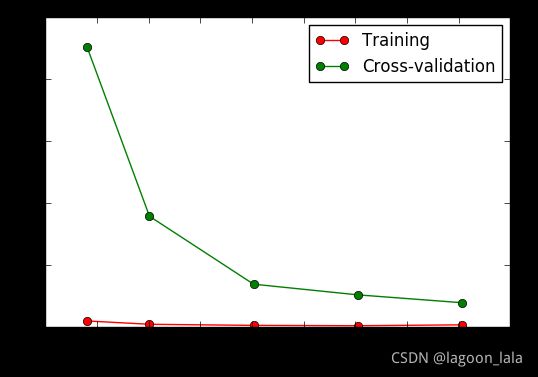
也就是说, 学习曲线是绘制一个折线图, 横轴是学习进度, 纵轴是loss.
其中, sklearn中的学习曲线是确定交叉验证的针对不同训练集大小的训练和测试分数.
参考李宏毅课上的学习曲线图片:
(纵轴是total loss,横轴是epoch的数目,你会希望说:随着epoch的数目越来越多,随着参数不断的update,loss会慢慢的下降最后趋向收敛。
但是不幸的是你在训练Recurrent Neural Network的时候,你有时候会看到绿色这条线。如果你是第一次trai Recurrent Neural Network,你看到绿色这条learning curve非常剧烈的抖动)

此处是使用epoch作为横轴.
matplotlib的使用如:
| import matplotlib.pyplot as plt x=[3,4,5] # [列表] y=[2,3,2] # x,y元素个数N应相同 plt.plot(x,y) plt.show() |
已有的epoch与losss关系如下:
| [ Epoch1: 5625/5625 ] loss:0.541 acc:71.875 Train | Loss:0.49558 Acc: 75.166 Valid | Loss:0.44780 Acc: 78.615 saving model with acc 78.615 ----------------------------------------------- [ Epoch2: 5625/5625 ] loss:0.331 acc:84.375 Train | Loss:0.43703 Acc: 79.678 Valid | Loss:0.43286 Acc: 79.650 saving model with acc 79.650 ----------------------------------------------- [ Epoch3: 5625/5625 ] loss:0.327 acc:87.500 Train | Loss:0.41816 Acc: 80.686 Valid | Loss:0.42060 Acc: 80.230 saving model with acc 80.230 ----------------------------------------------- [ Epoch4: 5625/5625 ] loss:0.402 acc:78.125 Train | Loss:0.40211 Acc: 81.727 Valid | Loss:0.41942 Acc: 80.495 saving model with acc 80.495 ----------------------------------------------- [ Epoch5: 5625/5625 ] loss:0.373 acc:87.500 Train | Loss:0.38429 Acc: 82.522 Valid | Loss:0.42131 Acc: 80.520 saving model with acc 80.520 |
所以, 现在需要将epoch num和Train loss, Valid loss分别保存在3个数组, 用matplotlib画图.
| epoch_num=range(1,6)#1,2,3,4,5 train_loss=[] valid_loss=[] |
| train_loss.append(total_loss/t_batch) valid_loss.append(total_loss/v_batch) |
作图:
| import matplotlib.pyplot as plt plt.plot(epoch_num, train_loss, 'o-', color="r", label="Training") plt.plot(epoch_num, valid_loss, 'o-', color="g", label="Validation") plt.xlabel("Epoch") plt.ylabel("Loss") plt.legend(loc="best") plt.show() |
所得学习曲线为:
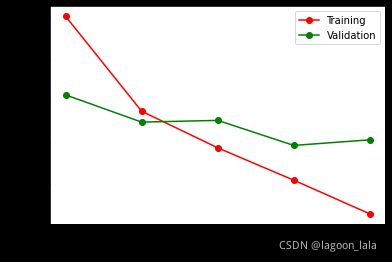
準確率
五轮训练后, 得到的准确率约80.520%
2. 比较 BOW + DNN 与 RNN
(2%) 請比較 BOW + DNN 與 RNN 兩種不同 model 對於 "today is a good day, but it is hot" 與 "today is hot, but it is a good day" 這兩句的分數 (過 softmax 後的數值),並討論造成差異的原因。
RNN
先计算两句话在RNN中的分数:
1. 造这两句话为测试数据集:
| eg_test = "id,text\n0,today is a good day, but it is hot\n1,today is hot, but it is a good day" fh = open('eg_test.txt', 'w', encoding='utf-8') fh.write(eg_test) fh.close() |
2. 使用模型进行预测
原预测时加载测试集为:
| test_loader = torch.utils.data.DataLoader(dataset = test_dataset, batch_size = batch_size, shuffle = False, num_workers = 8) |
| test_dataset = TwitterDataset(X=test_x, y=None) |
| test_x = load_testing_data(testing_data) |
| testing_data = os.path.join(path_prefix, '/kaggle/input/ml2020spring-hw4/testing_data.txt') |
改为:
| eg_data=os.path.join(path_prefix, 'eg_test.txt') eg_x = load_testing_data(eg_data) eg_preprocess = Preprocess(eg_x, sen_len, w2v_path=w2v_path) eg_embedding = eg_preprocess.make_embedding(load=True)#是在此处转化为张量的 eg_x = eg_preprocess.sentence_word2idx() eg_dataset=TwitterDataset(X=eg_x, y=None) eg_loader = torch.utils.data.DataLoader(dataset = eg_dataset, batch_size = batch_size, shuffle = False, num_workers = 1) eg_outputs = testing(batch_size, eg_loader, model, device) print("eg_outputs:\n",eg_outputs) |
由于需要的是对句子评分而不是分类, 还需要修改评估函数
| def eg_testing(batch_size, test_loader, model, device): model.eval() ret_output = [] with torch.no_grad(): for i, inputs in enumerate(test_loader): # if(i<1): # print("inputs type:",type(inputs)) inputs = inputs.to(device, dtype=torch.long) outputs = model(inputs) outputs = outputs.squeeze() # outputs[outputs>=0.5] = 1 # 大於等於 0.5 為正面 # outputs[outputs<0.5] = 0 # 小於 0.5 為負面 ret_output += outputs.tolist()
return ret_output |
最后得到两个句子评分:
| [0.3618888258934021, 0.9540349245071411] |
调bug过程(上方已改, 此段不必看)
报错
| 13 for i, inputs in enumerate(test_loader): ---> 14 inputs = inputs.to(device, dtype=torch.long) AttributeError: 'list' object has no attribute 'to' |
查看inputs类型:
| for i, inputs in enumerate(test_loader): if(i<1): print("inputs type:",type(inputs)) |
| inputs type: |
正确的类型应该是:
处理过程中还缺了:
| preprocess = Preprocess(test_x, sen_len, w2v_path=w2v_path) embedding = preprocess.make_embedding(load=True)#是在此处转化为张量的 test_x = preprocess.sentence_word2idx() |
BOW
Word2Vec是对词袋bag-of-words的改进
词袋模型将document转换为整数向量(词典中单词总个数).
词袋模型缺点
1. 丢失词序信息
解决方案: bag of n-grams长度为 n 的词短语, 捕获局部词序. 存在数据稀疏性和高维数的问题.
2. 不学习单词内涵
向量距离无法体现含义差异.
实现基于BOW的模型结构:
句子向量表示: 將每個句子傳換成跟字典一樣維度的向量,並計算字典中每個字出現在句子的個數, 计数放在该维度上.
接着是全连接的DNN分类,再经过sigmoid输出.
题中给出的两个句子, 所用单词相同, 次序不同, 导致了不同的语义情绪. 用该句比较BOW和RNN.
所以第一步做字典还是需要的.( 取训练集中出现次数较多的字做字典. 使用大数据集构建字典和DNN模型, 等预测的时候再用测试集的两个小数据,)
第二步, 根据字典将句子用数字表示的过程不同(用BOW)
3.4步用不着
(3. embedding layer将字转换成向量作为RNN input.
4. 经过LSTM的Hidden laye)
最后第5步DNN和sigmoid获得预测值的步骤一样
句子向量表示
BOW使用可参照Gensim文档的语料库流一节:
https://blog.csdn.net/lagoon_lala/article/details/119574087
gensim中的doc2bow即词袋模型(bag-of-words model): 向量对应该document包含字典中每个词的计数(frequency counts), 向量长度=字典中元素个数
假设文档存储在磁盘上的文件中,每行一个document。Gensim 只要求一个语料库一次只能返回一个document向量(暂时共用RNN已有的迭代器, 不修改)
通过所接DNN判断该获得怎样的输入
| from smart_open import open #显式打开remote files class MyCorpus: def __iter__(self): for line in open('https://raw.githubusercontent.com/RaRe-Technologies/gensim/develop/docs/notebooks/datasets/mycorpus.txt'): # 每行放一个document, 空格分词 yield dictionary.doc2bow(line.lower().split()) |
| def load_training_data(path='training_label.txt'): |
创建语料库对象
| corpus_memory_friendly = MyCorpus() # 这次不是同时加载corpus中所有document # print(corpus_memory_friendly) # 对象不能直接打印 for vector in corpus_memory_friendly: # 一次加载一个document向量 print(vector) |
语料库流构建字典
| # 预处理获得token构建字典 dictionary = corpora.Dictionary(line.lower().split() for line in open('https://raw.githubusercontent.com/RaRe-Technologies/gensim/develop/docs/notebooks/datasets/mycorpus.txt')) |
删除停用词
| #搜集停用词id stop_ids = [ dictionary.token2id[stopword] for stopword in stoplist if stopword in dictionary.token2id ] #dictionary.token2id为token:id键值对 #stop_ids #搜集只出现一次的词id once_ids = [tokenid for tokenid, docfreq in dictionary.dfs.items() if docfreq == 1] dictionary.filter_tokens(stop_ids + once_ids) # 删除这两种id的token dictionary.compactify() # 重新编排ID, 空位则前挪 print(dictionary) |
字典构建完成
保存语料库
| corpus = [[(1, 0.5)], []] # 语料库包含两个document, 其中一个空document, 哎, 就是玩儿 corpora.MmCorpus.serialize('/tmp/corpus.mm', corpus)# 保存为Market Matrix格式 |
从 Matrix Market 文件迭代加载语料库
| corpus = corpora.MmCorpus('/tmp/corpus.mm') |
Corpus不能直接打印, 是流(streams)对象. 查看内容方式
| # 整个加载进内存 print(list(corpus)) # list() 转换任何序列sequence->list |
| # streaming interface for doc in corpus: print(doc) |
共同加载到内存的方法
| documents = [ "Human machine interface for lab abc computer applications", "A survey of user opinion of computer system response time", "The EPS user interface management system", "System and human system engineering testing of EPS", "Relation of user perceived response time to error measurement", "The generation of random binary unordered trees", "The intersection graph of paths in trees", "Graph minors IV Widths of trees and well quasi ordering", "Graph minors A survey", ] |
对document做分词预处理.
| from pprint import pprint # pretty-printer from collections import defaultdict # remove common words and tokenize stoplist = set('for a of the and to in'.split()) texts = [ [word for word in document.lower().split() if word not in stoplist] for document in documents ] # remove words that appear only once frequency = defaultdict(int) for text in texts: for token in text: frequency[token] += 1 texts = [ [token for token in text if frequency[token] > 1] for text in texts ] pprint(texts) |
| [['human', 'interface', 'computer'], ['survey', 'user', 'computer', 'system', 'response', 'time'], ['eps', 'user', 'interface', 'system'], ['system', 'human', 'system', 'eps'], ['user', 'response', 'time'], ['trees'], ['graph', 'trees'], ['graph', 'minors', 'trees'], ['graph', 'minors', 'survey']] |
文档转换为向量, 其中问题和 id 之间的映射称为字典:
| from gensim import corpora dictionary = corpora.Dictionary(texts) dictionary.save('/tmp/deerwester.dict') # store the dictionary, for future reference print(dictionary) |
| Dictionary(12 unique tokens: ['computer', 'human', 'interface', 'response', 'survey']...) |
为出现在gensim.corpora.dictionary.Dictionary该类的语料库中的所有单词分配了一个唯一的整数 id.
查看单词与其 id 之间的映射:
| print(dictionary.token2id) |
| {'computer': 0, 'human': 1, 'interface': 2, 'response': 3, 'survey': 4, 'system': 5, 'time': 6, 'user': 7, 'eps': 8, 'trees': 9, 'graph': 10, 'minors': 11} |
标记化文档实际转换为向量
| new_doc = "Human computer interaction" new_vec = dictionary.doc2bow(new_doc.lower().split()) print(new_vec) # the word "interaction" does not appear in the dictionary and is ignored |
| [(0, 1), (1, 1)] |
转换后的稀疏向量
| corpus = [dictionary.doc2bow(text) for text in texts] corpora.MmCorpus.serialize('/tmp/deerwester.mm', corpus) # store to disk, for later use print(corpus) |
| [[(0, 1), (1, 1), (2, 1)], [(0, 1), (3, 1), (4, 1), (5, 1), (6, 1), (7, 1)], [(2, 1), (5, 1), (7, 1), (8, 1)], [(1, 1), (5, 2), (8, 1)], [(3, 1), (6, 1), (7, 1)], [(9, 1)], [(9, 1), (10, 1)], [(9, 1), (10, 1), (11, 1)], [(4, 1), (10, 1), (11, 1)]] |
对照word2vec的向量表示, 唯一需要控制变量的是分词预处理处可能存在的不同:
DNN分类
| #题目2-cell-DNN模型 import torch from torch import nn class DNN_Net(nn.Module): # def __init__(self, hidden_dim, dropout=0.5): def __init__(self, hidden_dim=24696):#hidden_dim维度参照RNN输入embedding层之前的字典维数 super(DNN_Net, self).__init__() self.hidden_dim = hidden_dim # self.dropout = dropout #分类器二元分类 # self.classifier = nn.Sequential( nn.Dropout(dropout), # nn.Linear(hidden_dim, 1), # nn.Sigmoid() ) self.classifier = nn.Sequential( nn.Linear(hidden_dim, 128), nn.ReLU(), nn.Linear(128, 64), nn.ReLU(), nn.Linear(64, 1) nn.Sigmoid() ) def forward(self, inputs): x = self.classifier(inputs) return x |
训练
定义训练函数dnn_training(batch_size, n_epoch, lr, model_dir, train, valid, model, device)
修改模型储存地址
| torch.save(model, "{}/dnn.model".format(model_dir)) |
调用训练函数(数据从train_loader中喂入, 模型保存在model_dir)
| dnn_model = DNN_Net(hidden_dim=24696) |
| dnn_training(batch_size, epoch, lr, model_dir, bow_train_loader, bow_val_loader, dnn_model, device) |
train_loader使用的数据集由dataset确定
| bow_train_loader = torch.utils.data.DataLoader(dataset = bow_train_dataset, batch_size = batch_size, shuffle = True, num_workers = 8) bow_val_loader = torch.utils.data.DataLoader(dataset = bow_val_dataset, batch_size = batch_size, shuffle = False, num_workers = 8) |
| bow_X_train, bow_X_val, bow_y_train, bow_y_val = train_test_split(bow_train_x, bow_y, test_size = 0.1, random_state = 1, stratify = y) print('Train | Len:{} \nValid | Len:{}'.format(len(y_train), len(y_val))) bow_train_dataset = TwitterDataset(X=bow_X_train, y=bow_y_train) bow_val_dataset = TwitterDataset(X=bow_X_val, y=bow_y_val) |
bow_train_x, bow_y读取
| print("loading bow data ...") # 读取'training_label.txt' 跟 'training_nolabel.txt' bow_train_x, bow_y = load_training_data(train_with_label) # train_x_no_label = load_training_data(train_no_label) # input, labels 做預處理 bow_preprocess = Preprocess(bow_train_x, sen_len, w2v_path=w2v_path) # embedding = preprocess.make_embedding(load=True) # bow_train_x = preprocess.sentence_word2idx() bow_y = bow_preprocess.labels_to_tensor(bow_y) |
数据预处理(load_training_data中已经做了空格分词)
建立字典
| from gensim import corpora dictionary = corpora.Dictionary(bow_train_x) dictionary.save('deerwester.dict') # store the dictionary, for future reference print(dictionary.token2id) |
建立词袋
| bow_train_x_vec = dictionary.doc2bow(bow_train_x) |
转换为张量
| bow_train_x_vec = torch.tensor(bow_train_x_vec) |
测试
转为词袋向量喂入testing
| bow_eg_x=load_testing_data(eg_data) bow_eg_x_vec = dictionary.doc2bow(bow_eg_x) bow_eg_x_vec = torch.tensor(bow_eg_x_vec) |
eg_testing
| bow_outputs = eg_testing(batch_size, bow_eg_loader, dnn_model, device) print("bow_outputs:\n",bow_outputs) |
| bow_eg_loader= torch.utils.data.DataLoader(dataset = bow_eg_dataset, batch_size = batch_size, shuffle = False, num_workers = 1) |
| bow_eg_dataset=TwitterDataset(X=bow_eg_x_vec, y=None) |
调试
1.在使用dictionary.doc2bow时遇到报错:
| need a bytes-like object, list found |
参考: https://stackoverflow.com/questions/68039391/when-creating-a-gensim-vocabulary-why-did-i-get-decoding-to-str-need-a-bytes-l
期望输入gensim.corpora.Dictionary应该是字符串列表的列表, 如
| [ ['clone', 'mammoth', 'scienc', 'extinct', 'fiction', 'book', 'biologist', 'beth', '...'], ['saint', 'eutrop', 'former', 'commun', 'charent', 'depart', 'southwestern', 'franc', '...'] ] |
打印输入数据对照一下:
| print('bow_train_x:',bow_train_x) |
| bow_train_x: [['are', 'wtf', '...', 'awww', 'thanks', '!'], ['leavingg', 'to', 'wait', 'for', 'kaysie', 'to', 'arrive', 'myspacin', 'itt', 'for', 'now', 'ilmmthek', '.!'], ['i', 'wish', 'i', 'could', 'go', 'and', 'see', 'duffy', 'when', 'she', 'comes', 'to', 'mamaia', 'romania', '.'], |
看起来是字符串列表啊.
参考: https://github.com/RaRe-Technologies/gensim/issues/1507
dictionary.doc2bow as input expects only one list of tokens (not a generator of sentences)
fit dictionary first and after it, apply doc2bow to each sentence
所以不能全部扔进去, 应该遍历转换
| corpus = [dictionary.doc2bow(text) for text in texts] |
| bow_corpus = [dictionary.doc2bow(text) for text in bow_train_x] bow_corpus = torch.tensor(bow_corpus) bow_X_train, bow_X_val, bow_y_train, bow_y_val = train_test_split(bow_corpus, bow_y, test_size = 0.1, random_state = 1, stratify = y) |
2. torch.tensor输入的列表必须长度相同. 报错
| expected sequence of length 6 at dim 1 (got 11) |
神经网络对于输入的维度不一致的处理:
一般网络对输入尺寸有固定的要求。这是为什么呢?因为网络的结构和参数决定了需要固定
解决方法有两个途径:
一是从数据进行操作,数据对齐,这个其实在图片识别上面很常见,就是把图片resize成目标大小。
把输出给处理一下变为固定长度然后再送去全连接中(全局池化和图像金字塔可以实现)
所以还是老老实实预处理吧
建字典后加入
| dct.add_documents([["cat", "say", "meow"], ["dog"]]) |
| dictionary.add_documents([[' |
将document(单词列表)转换为id列表
| dct.doc2idx(["a", "a", "c", "not_in_dictionary", "c"]) |
| print(" |
统一语料库长度
| bow_preprocess = Preprocess(bow_corpus, sen_len) bow_corpus = bow_preprocess.pad_bow_sequence() |
报错还没改变, 考虑原先调用该函数时, 是类内部其他函数调用. 此时直接从外部调用, 出现问题.
参考原调用函数的过程, 先遍历sentences列表中每一个sen, 对单个sen做pad, 再用sentence_list = []接收, 最后对sentence_list 做转换为tensor的操作再返回.
| def sentence_word2idx(self): # 把句子裡面的字轉成相對應的 index sentence_list = [] for i, sen in enumerate(self.sentences): print('sentence count #{}'.format(i+1), end='\r') sentence_idx = [] for word in sen: if (word in self.word2idx.keys()): sentence_idx.append(self.word2idx[word]) else: sentence_idx.append(self.word2idx[" # 將每個句子變成一樣的長度 sentence_idx = self.pad_sequence(sentence_idx) sentence_list.append(sentence_idx) return torch.LongTensor(sentence_list) |
而这个函数接收返回值时是直接接收的函数内部定义变量:
| train_x = preprocess.sentence_word2idx() |
重点关注sentences遍历, 重新拼接的操作, pad过程修改为
| bow_sentence_list = [] for i, sen in enumerate(bow_corpus): print('sentence count #{}'.format(i+1), end='\r') # sentence_idx = [] # for word in sen: # if (word in self.word2idx.keys()): # sentence_idx.append(self.word2idx[word]) # else: # sentence_idx.append(self.word2idx[" # 將每個句子變成一樣的長度 sen = bow_preprocess.pad_bow_sequence(sen) # sentence_idx = self.pad_sequence(sentence_idx) bow_sentence_list.append(sen) # bow_corpus = bow_preprocess.pad_bow_sequence(bow_corpus) bow_corpus = torch.tensor(bow_sentence_list) |
打印查看pad前后语料库列表的变化
看起来是稀疏了
| 0 [(0, 1), (1, 1), (2, 1), (3, 1), (4, 1), (5, 1), 82945, 82945, 82945, 82945, 82945, 82945, 82945, 82945, 82945, 82945, 82945, 82945, 82945, 82945] 1 [(6, 1), (7, 1), (8, 2), (9, 1), (10, 1), (11, 1), (12, 1), (13, 1), (14, 1), (15, 2), (16, 1), 82945, 82945, 82945, 82945, 82945, 82945, 82945, 82945, 82945] 2 [(15, 1), (17, 1), (18, 1), (19, 1), (20, 1), (21, 1), (22, 1), (23, 2), (24, 1), (25, 1), (26, 1), (27, 1), (28, 1), (29, 1), 82945, 82945, 82945, 82945, 82945, 82945] 3 [(0, 1), (8, 1), (16, 1), (23, 2), (30, 1), (31, 1), (32, 1), (33, 1), (34, 1), (35, 1), (36, 1), (37, 1), (38, 1), 82945, 82945, 82945, 82945, 82945, 82945, 82945] 4 [(0, 1), (1, 1), (17, 2), (18, 1), (29, 1), (39, 1), (40, 1), (41, 1), (42, 1), (43, 1), (44, 1), (45, 1), (46, 1), (47, 1), (48, 1), (49, 1), (50, 1), (51, 1), (52, 1), (53, 1)] 5 [(8, 1), (17, 2), (23, 2), (33, 2), (55, 1), (56, 1), (57, 1), (58, 2), (59, 1), (60, 1), (61, 1), (62, 1), (63, 1), (64, 1), (65, 2), (66, 1), (67, 1), (68, 1), (69, 1), (70, 1)] 6 [(14, 1), (65, 1), (72, 1), (73, 1), (74, 1), (75, 1), (76, 1), (77, 1), (78, 1), (79, 1), (80, 1), (81, 1), (82, 1), (83, 1), (84, 1), (85, 1), (86, 1), 82945, 82945, 82945] 7 [(0, 1), (23, 1), (35, 1), (52, 1), (54, 1), (87, 1), (88, 1), (89, 1), (90, 1), (91, 1), (92, 1), (93, 1), (94, 1), (95, 1), 82945, 82945, 82945, 82945, 82945, 82945] 8 [(0, 1), (1, 1), (46, 1), (65, 1), (67, 1), (78, 1), (80, 1), (96, 1), (97, 1), (98, 1), (99, 1), (100, 1), (101, 1), (102, 1), (103, 1), (104, 1), (105, 1), (106, 1), (107, 1), 82945] 9 [(0, 1), (30, 2), (91, 1), (95, 1), (108, 1), (109, 1), (110, 1), (111, 1), (112, 1), (113, 1), 82945, 82945, 82945, 82945, 82945, 82945, 82945, 82945, 82945, 82945] |
那就先不加pad, 把元组列表->稀疏矩阵转成普通矩阵
稀疏矩阵转成普通矩阵todense()参考:
https://blog.csdn.net/littlehaes/article/details/103523512
| import scipy.sparse as sp import numpy as np b = sp.coo_matrix(arg1=(a[:, 2], (a[:, 0], a[:, 1])), shape=(7,7), dtype=np.float32) c = b.todense() print(c) |
元组列表转稀疏矩阵参考:
https://www.5axxw.com/questions/content/hxsv9z
https://www.pythonf.cn/read/64772
| import numpy as np import sys np.set_printoptions(threshold=sys.maxsize) dim_x = 200 dim_y = 150 data = [(18, 53), (42, 78), (132, 38)] a = np.zeros((dim_x, dim_y), dtype = int) for el in data: if el[0] < dim_x and el[1] < dim_y: a[el[0], el[1]] = 1
print(a) |
| def tuple2array(data): dim_x = 2000#原字典维度82947 dim_y = 1 # a = np.zeros((dim_x, dim_y), dtype = int) a = np.zeros((dim_y, dim_x), dtype = int) for i, el in enumerate(data): # 每个样本转换时都打印太长了 # for el in data: # if(i<10): # print("el:",el) if(el[0] < dim_x): a[dim_y-1, el[0]] = el[1] return a |
| bow_sentence_list = [] for i, sen in enumerate(bow_corpus): print('sentence count #{}'.format(i+1), end='\r') # 將每個句子展开成正常矩阵 arr_sen=tuple2array(sen) bow_sentence_list.append(arr_sen) print('bow_sentence_list:') for i, sen in enumerate(bow_sentence_list): if(i<10): print(i, sen) bow_corpus = torch.tensor(np.array(bow_sentence_list)) |
报错申请内存超过限制了, 可能这个数组太大.
allocate more memory than is available
元组列表转稀疏矩阵参考2:
https://www.cnpython.com/qa/194643
| i, j, data = zip(*((i, t[0], t[1]) for i, row in enumerate(alist) for t in row)) coo_matrix((data, (i, j)), shape=(2, 4)) |
从(列,值)元组列表中创建位置和值的dict,然后使用dok_matrix来构造稀疏矩阵
| >>> from scipy.sparse import dok_matrix >>> S = dok_matrix((m,n), dtype=int) |
元组转矩阵参考3:
https://www.icode9.com/content-1-418753.html
| np.array([[tup[1] for tup in lst] for lst in list1]) |
| A = [] for i in range(len(list1)): A.append(np.array([v for k,v in list1[i]])) A = np.array(A) |
embedding的话也是输入维度大输出小, 还是要建立大的.
考虑预处理时删去出现次数过少的词.
删除停用词
| #搜集停用词id stop_ids = [ dictionary.token2id[stopword] for stopword in stoplist if stopword in dictionary.token2id ] #dictionary.token2id为token:id键值对 #stop_ids #搜集只出现一次的词id once_ids = [tokenid for tokenid, docfreq in dictionary.dfs.items() if docfreq == 1] dictionary.filter_tokens(stop_ids + once_ids) # 删除这两种id的token dictionary.compactify() # 重新编排ID, 空位则前挪 print(dictionary) |
去掉出现5次以下的还有16322个词
BOW分类参考教程:
https://pytorch.org/tutorials/beginner/nlp/deep_learning_tutorial.html
教程中也用的one-hot编码
BOW是word embedding中的一种, 维数灾难问题解决参考:
https://www.cnblogs.com/kjkj/p/9824419.html
共现矩阵Cocurrence matrix没找到代码
考虑torch.nn.Embedding, 参考:
https://www.jianshu.com/p/63e7acc5e890
| torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None) |
Embedding是一个简单的存储固定大小的词典的嵌入向量的查找表,意思就是说,给一个编号,嵌入层就能返回这个编号对应的嵌入向量,嵌入向量反映了各个编号代表的符号之间的语义关系。
输入为一个编号列表,输出为对应的符号嵌入向量列表
参数解释:
| num_embeddings (python:int) – 词典的大小尺寸,比如总共出现5000个词,那就输入5000。此时index为(0-4999) embedding_dim (python:int) – 嵌入向量的维度,即用多少维来表示一个符号。 padding_idx (python:int, optional) – 填充id,比如,输入长度为100,但是每次的句子长度并不一样,后面就需要用统一的数字填充,而这里就是指定这个数字,这样,网络在遇到填充id时,就不会计算其与其它符号的相关性。(初始化为0) max_norm (python:float, optional) – 最大范数,如果嵌入向量的范数超过了这个界限,就要进行再归一化。 norm_type (python:float, optional) – 指定利用什么范数计算,并用于对比max_norm,默认为2范数。 scale_grad_by_freq (boolean, optional) – 根据单词在mini-batch中出现的频率,对梯度进行放缩。默认为False. sparse (bool, optional) – 若为True,则与权重矩阵相关的梯度转变为稀疏张量。 |
torch.nn包下的Embedding,作为训练的一层,随模型训练得到适合的词向量
注意
nn.embedding的输入只能是编号,不能是隐藏变量,比如one-hot,或者其它,这种情况,可以自己建一个自定义维度的线性网络层,参数训练可以单独训练或者跟随整个网络一起训练(看实验需要)
如果你指定了padding_idx,注意这个padding_idx也是在num_embeddings尺寸内的,比如符号总共有500个,指定了padding_idx,那么num_embeddings应该为501
embedding_dim的选择要注意,根据自己的符号数量,举个例子,如果你的词典尺寸是1024,那么极限压缩(用二进制表示)也需要10维,再考虑词性之间的相关性,怎么也要在15-20维左右,虽然embedding是用来降维的,但是>- 也要注意这种极限维度,结合实际情况,合理定义
按上述所说这个embedding是需要训练的, 还是没有解决在数据喂入前维数灾难的问题.
RNN迭代器这里获取词袋之前也用了. 批训练也是训练集全部完备再分批.
词袋模型降维的常规操作:首先将词袋中的所有词按照频率从高到低排序然后在某处截断(前2000).参考:
https://aistudio.baidu.com/aistudio/projectdetail/514326
对词频排序, 使用sorted函数对元组排序, 参考:
https://blog.csdn.net/qq_24076135/article/details/78550898
默认情况下sort和sorted函数接收的参数是元组时,它将会先按元组的第一个元素进行排序再按第二个元素进行排序. 要看第二个元素需要lambda返回一个自定义tuple
| data = [(1, 'B'), (1, 'A'), (2, 'A'), (0, 'B'), (0, 'a')] #将x[1].lower()作为返回元组里的第一个元素,按照sorted的排序规律,就会先按字母排序,再按数字排序了 result = sorted(data,key=lambda x:(x[1].lower(),x[0])) print(data) #结果为 [(1, 'B'), (1, 'A'), (2, 'A'), (0, 'B'), (0, 'a')] print(result) #结果为 [(0, 'a'), (1, 'A'), (2, 'A'), (0, 'B'), (1, 'B')] |
| sorted_words= sorted(dictionary.dfs.items(), key=lambda x:(x[1],x[0])) most_words=sorted_words[:1998] rarely_words=sorted_words[1998:] print("most_word_fre:",most_words[0],most_words[100]) rarely_ids = [tokenid for tokenid, docfreq in rarely_words] dictionary.add_documents([[' |
打印变量有
| most_word_fre: (10, 2) (3267, 2) Dictionary(2000 unique tokens: ['myspacin', 'mwhaha', 'gana', 'hawa', 'penicillin']...) |
报错
| Found input variables with inconsistent numbers of samples: [400000000, 200000] |
| bow_X_train, bow_X_val, bow_y_train, bow_y_val = train_test_split(bow_corpus, bow_y, test_size = 0.1, random_state = 1, stratify = y) |
一般原因, XY长度不一致
参考: https://blog.csdn.net/qq_30602869/article/details/101440602
.size()查看bow_corpus, bow_y形状
dnn在train时报错"addmm_cuda" not implemented for 'Long'参考:
https://discuss.pytorch.org/t/runtimeerror-log-cuda-not-implemented-for-long/78003
expects the model output and target to have the same shape and as FloatTensors.
I guess you are passing the same targets from the nn.CrossEntropyLoss to the new criterion, which will yield this error.
参考: https://blog.csdn.net/songchunxiao1991/article/details/83544578
使用torch.LongTensor, torch.FolatTensor类型
bow_corpus改成longtensor
| bow_corpus = torch.LongTensor(np.array(bow_sentence_list)) |
array, CPU tensor, GPU tensor类型转换参考:
https://www.cnblogs.com/kk17/p/10246133.html
https://www.cnblogs.com/sbj123456789/p/10839020.html
https://pytorch.org/docs/stable/tensors.html
tensor .to()函数参考:
https://blog.csdn.net/m0_46653437/article/details/112727204
train和eval, testing修改input类型
| inputs = inputs.to(device, dtype=torch.float) |
训练中途报错超过内存限制, 把BOW模型从RNN模型分开成两个notebook单独训练.
终于训练起来了
读取测试小例时出现报错:
| bow_eg_x_vec = dictionary.doc2bow(bow_eg_x) |
| decoding to str: need a bytes-like object, list found |
参考之前的修改方式 遍历
| corpus = [dictionary.doc2bow(text) for text in texts] |
| bow_eg_x_vec = [dictionary.doc2bow(text) for text in bow_eg_x] |
报错:
| mat1 dim 1 must match mat2 dim 0 |
| eg_testing中 outputs = model(inputs) |
考虑是没有对测试数据预处理, 打印看看形状.
对照之前喂入数据过程
| print("loading bow data ...") # 读取'training_label.txt' 跟 'training_nolabel.txt' bow_train_x, bow_y = load_training_data(train_with_label) bow_corpus = [dictionary.doc2bow(text) for text in bow_train_x] # input, labels 做預處理 bow_preprocess = Preprocess(bow_corpus, sen_len) #元组列表转稀疏矩阵 def tuple2array(data): dim_x = 2000#原字典维度82947 dim_y = 1 a = np.zeros((dim_y, dim_x), dtype = int) for i, el in enumerate(data): if(el[0] < dim_x): a[dim_y-1, el[0]] = el[1] return a bow_sentence_list = [] for i, sen in enumerate(bow_corpus): print('sentence count #{}'.format(i+1), end='\r') # 將每個句子展开成正常矩阵 arr_sen=tuple2array(sen) bow_sentence_list.append(arr_sen) print('bow_sentence_list:') for i, sen in enumerate(bow_sentence_list): if(i<2): print(i, sen) bow_corpus = torch.tensor(np.array(bow_sentence_list)) bow_y = bow_preprocess.labels_to_tensor(bow_y) dnn_model = DNN_Net(hidden_dim=2000) dnn_model = dnn_model.to(device) # print('bow_corpus:', bow_corpus.size(),'\nbow_y:',bow_y.size()) bow_X_train, bow_X_val, bow_y_train, bow_y_val = train_test_split(bow_corpus, bow_y, test_size = 0.1, random_state = 1, stratify = y) print('Train | Len:{} \nValid | Len:{}'.format(len(bow_y_train), len(bow_y_val))) bow_train_dataset = TwitterDataset(X=bow_X_train, y=bow_y_train) bow_val_dataset = TwitterDataset(X=bow_X_val, y=bow_y_val) bow_train_loader = torch.utils.data.DataLoader(dataset = bow_train_dataset, batch_size = batch_size, shuffle = True, num_workers = 8) bow_val_loader = torch.utils.data.DataLoader(dataset = bow_val_dataset, batch_size = batch_size, shuffle = False, num_workers = 8) dnn_training(batch_size, epoch, lr, model_dir, bow_train_loader, bow_val_loader, dnn_model, device) |
| bow_eg_x=load_testing_data(eg_data) # bow_eg_x_vec = dictionary.doc2bow(bow_eg_x) bow_eg_x_vec = [dictionary.doc2bow(text) for text in bow_eg_x] bow_eg_list = [] for i, sen in enumerate(bow_eg_x_vec): print('sentence count #{}'.format(i+1), end='\r') # 將每個句子展开成正常矩阵 arr_sen=tuple2array(sen) bow_eg_list.append(arr_sen) print('bow_eg_list:',bow_eg_list) bow_eg_x_vec = torch.tensor(np.array(bow_eg_list)) # eg_dataset=TwitterDataset(X=eg_x, y=None) bow_eg_dataset=TwitterDataset(X=bow_eg_x_vec, y=None) |
运行完成啦, 让我们看一下DNN结果
DNN的正确率和随机猜测差不多, 50.015, 得到两个句子的正面概率均为:
| bow_outputs: [0.4979850649833679, 0.4979850649833679] |
word embedding+RNN两个句子得分不同, 但BOW+DNN一样, 造成差异的原因:
词袋模型将document转换为整数向量(词典中单词总个数), 丢失词序信息, 题中给出的两个句子, 所用单词相同, 次序不同, 导致了不同的语义情绪.