b站弹幕 so文件解析/逆序列化
写在前面:
下文全部使用**代替b 站,由于csdn现在版权的问题,本文只介绍对so文件的逆序列化(反正怎么获取文件网上很多文章)

如图,抓包得到的是乱码,实际上这不是加密,是使用protobuf序列化后的文件
本人找了很多网站,只在知乎看到一个逆序列化的回答,其他的都是从乱码中匹配内容
https://zhuanlan.zhihu.com/p/392931611但是这个回答比较简洁,对于不了解protobuf的人可能摸不着风,本人也没接触过protobuf,但是通过一段时间的查找资料了解了一二,故写下这一篇相对详细一点的博客方便其他不懂protobuf的人学习
爬**
1.什么是protobuf?
protobuf(protocol buffer) 是谷歌内部的混合语言数据标准。通过将结构化的数据进行序列化(串行化),用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
python(pip)可通过以下命令直接安装
pip install protobuf在使用时这样导包
import google.protobuf
具体的就不说了,想详细了解的可以直接搜,网上有很多相关教程
2.怎么进行逆序列化
你需要知道**弹幕的proto定义,再使用protoc进行编译,获得一个.py文件,接下来就可以使用文件里面的方法反序列化了
关于大概的方法,下面这个网站有介绍,下文是详细步骤bilibili-API-collect · GitHub
https://github.com/SocialSisterYi/bilibili-API-collect/blob/bb437d2012e6291b38c78d42755db9d836d4975f/danmaku/danmaku_proto.md
关于**的弹幕定义,这里推荐一个项目(跟上面那个是一个项目)
GitHub - SocialSisterYi/bilibili-API-collect: 哔哩哔哩-API收集整理【不断更新中....】
这个项目收集了**的大部分api ,并且还有人维护,简直小白福音啊
**的弹幕proto定义在这里:https://github.com/SocialSisterYi/bilibili-API-collect/blob/bb437d2012e6291b38c78d42755db9d836d4975f/grpc_api/bilibili/community/service/dm/v1/dm.protohttps://github.com/SocialSisterYi/bilibili-API-collect/blob/bb437d2012e6291b38c78d42755db9d836d4975f/grpc_api/bilibili/community/service/dm/v1/dm.proto
接下来推荐一个在线proto编译网站
Protobuf Code Generator and Parser | protobufnet | Marc Gravellhttps://protogen.marcgravell.com/#
将**的proto定义复制到该网站,选择语言为Python,点击Generate后右边得到的就是我们想要的

直接复制右边的代码,在自己的项目里面创建一个py文件,粘贴即可
注意:你创建的文件名必须以_pb2.py结尾!!!!(这里我叫做bili_pb2.py)

接下来就是在你需要进行逆序列化的文件里面这么写
import bili_pb2
from google.protobuf import text_format
# 肯定是先导包,下面这个不是必需的,作用在后文会介绍
my_seg = bili_pb2.DmSegMobileReply()
my_seg.ParseFromString(DATA)
# DATA是二进制数据
# 比如你可以这么写
# DATA = resp.content
# 或者这么写
# with open('./test.so','rb') as f:
# DATA = f.read()
# 理论上此时文件已经被逆序列化了,你可以通过 print(my_seg.elems)来得到逆序列化后的数据注意:此时my_seg.elems是一个列表,包含各个弹幕的信息
这是一个示例数据:

对于里面的各参数的作用这个网站有解答:
bilibili-API-collect/danmaku_proto.md at bb437d2012e6291b38c78d42755db9d836d4975f · SocialSisterYi/bilibili-API-collect · GitHub
很重要的问题!!!
上述代码理论上已经能让你得到数据了,但是有个问题,就是如果弹幕内容是中文时,返回的数据是编码后的,下图我的字幕内容是 “中文测试” ,但是图中并不是汉字
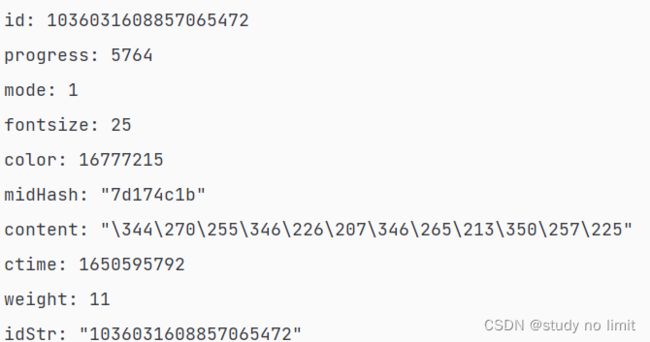
此时,我们可以使用以下代码来实现自动转化为中文:
import bili_pb2
from google.protobuf import text_format
# 肯定是先导包,下面这个不是必需的,作用在后文会介绍
my_seg = bili_pb2.DmSegMobileReply()
my_seg.ParseFromString(DATA)
# DATA是二进制数据
# 比如你可以这么写
# DATA = resp.content
# 或者这么写
# with open('./test.so','rb') as f:
# DATA = f.read()
# 理论上此时文件已经被逆序列化了,你可以通过 print(my_seg.elems)来得到逆序列化后的数据
###############################上次的代码##########################
# 新的代码
for j in my_seg.elems:
parse_data = text_format.MessageToString(j, as_utf8=True)
# 此时的parse_data可以直接print了
# text_format.MessageToString只能处理一个数据,而my_seg.elems返回的是数据列表这样就能得到我们想要的数据了:

写在最后:
关于弹幕数据的一些坑:不是每个弹幕返回的数据都有progress这个参数,在使用正则匹配的时候注意点,容易被坑
还要再次感谢知乎的那篇文章,逆序列化的代码参考了他的代码
b站弹幕 Protobuf 格式解析 - 知乎